







基本架构
Postgrest是Supabase软件架构中的核心组件,是Supabase采用的所有开源组件中历史最悠久的一个,2014年就发布了第一个版本,到今天已经有9年的历史了。在Supabase出现之前,Postgrest已经被广泛应用于各种场景,是一个非常便捷的PostgreSQL应用开发中间件。
Postgrest架构非常简洁,全部使用Haskell开发,采用Haskell的Warp作为HTTP Server,Haskell的Hasql作为数据库连接池。除了深度依赖PostgreSQL数据库外,没有引入其他外部依赖,一个单体应用就可以完成部署。Postgrest是无状态的,因此支持增加更多的节点来实现横向扩展。
下面是Postgrest的架构图:
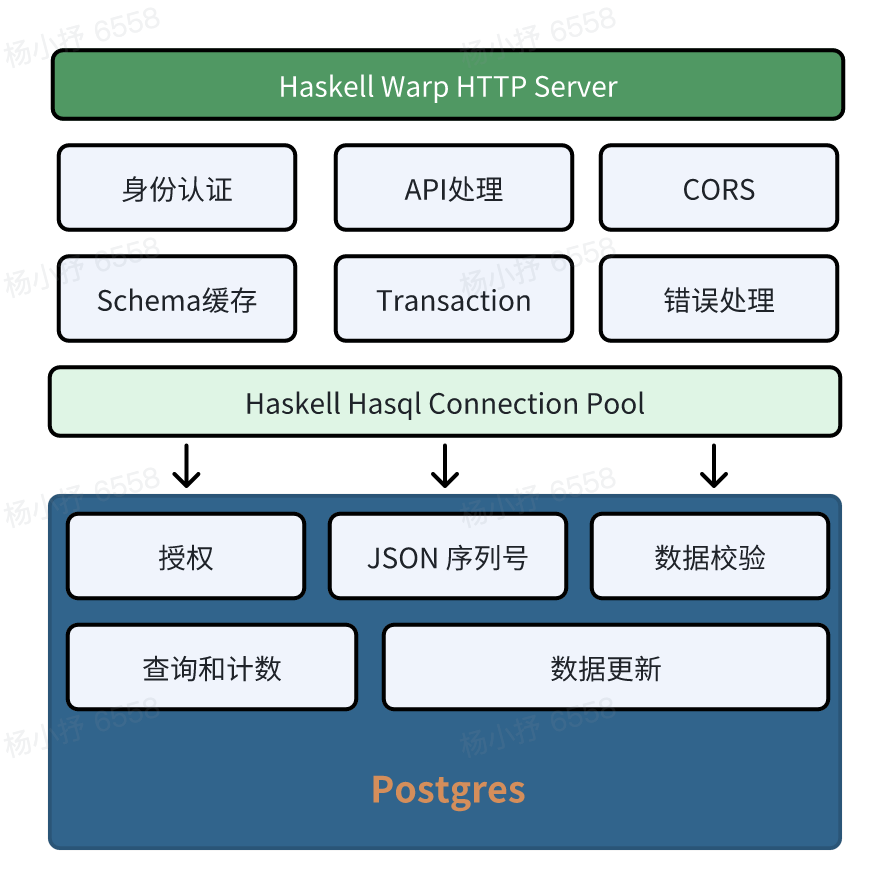
Postgrest是用Haskell编写的,是比较冷门的编程语言,这也是目前制约Postgrest发展的最主要的因素,要找到合适的维护人员比较困难。甚至因为这个原因,出现了一个使用Golang开发的prest(https://github.com/prest/prest)项目。
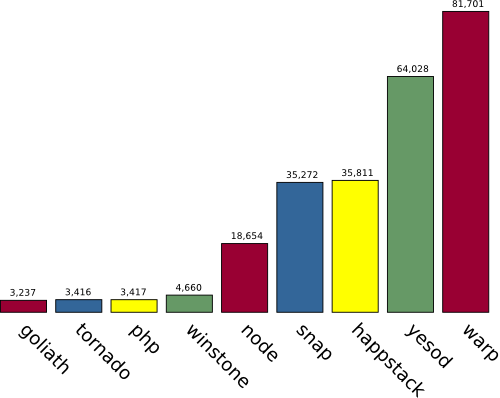
Postgrest使用Haskell的Warp作为其HTTP Server,Warp是一个高性能的web server,这里有一个很古老的性能对比文章(https://www.yesodweb.com/blog/2011/03/preliminary-warp-cross-language-benchmarks),展示了Warp在相同硬件下处理http请求的性能对比,从数值上来看,还是非常厉害的:
Hasql是Haskell的数据库连接池。众所周知,到目前为止(Postgres 16),PostgreSQL的连接是多进程模型,每个数据库连接都会启动一个pg进程,消耗一定数量的CPU和内存资源,因此PostgreSQL的连接数通常都是需要进行限制的。对于高并发的Web应用场景,就需要采用数据库连接池的方案,来复用数据库连接。
PostgREST核心解决哪些问题
对于大多数Web应用程序,通常就是前端 + 后端 + 数据库的模式,而后端的主要工作就是对数据库进行CRUD,久而久之,开发者就不禁会想,对于这种业务场景,能不能直接在前端对数据库进行CRUD操作呢?这就是PostgREST的核心出发点。为了解决这个核心需求,衍生出来的一些其他的基本需求,包括用户认证授权、高并发等,因此PostgREST提供了如下一些内置的能力:
-
用户认证授权
-
API
-
事务
-
连接池
-
错误处理
-
Schema缓存
在【原理篇】Supabase 权限模型 Part2中,我们已经对PostgREST的认证鉴权机制进行了详细的解析,这里就不再赘述,如果你还没有看过,强烈建议了解一下。接下来我们重点介绍一下PostgREST的API实现机制,以及事务、schema缓存等的工作原理。
PostgREST API基本原理
一个简单的示例
Web开发者都知道,一个简单的REST API通常是这样的:
GET /items/1
上面这个REST API的含义是要获取id=1的 item,后端接收到该请求后会转换成如下SQL语句,然后到数据库中查找相应的数据返回给前端:
SELECT * FROM items WHERE id=1
PostgREST研究了SQL语句的基本模式,并试图将其转换成HTTP语法,为了以通用的方式解决上述REST API的需求,PostgREST以如下形式来解决该问题。我们看下同样的接口需求,在PostgREST中是如何实现的:
GET /items?select=*&id=1
上面这个API转换成SQL语句也是 SELECT * FROM items WHERE id=1,可以看到该API接口基本上能自解释,也就是只要稍微了解PostgREST的接口模式,并熟悉SQL,就能很快写出满足任意场景需求的接口调用。
一个略微复杂的例子
我们再看一个例子,要实现如下SQL:
SELECT id, name FROM items WHERE id > 10 ORDER BY name
PostgREST API的写法如下:
GET /items?select=id,name&id=gt.10&order=name
这个例子引入了两个新的操作符大于号:gt,排序:order,并且指定了要查询的字段:id,name
如何实现多表关联查询
我们看一个典型的例子:
select items.id, items.name, subitems.id, subitems.name from items
join subitems on item.id = subitems.item_id
上面这个关联查询使用PostgREST接口写法如下:
GET /items?select=id,name,subitems(id,name)
可以看到,上面的接口非常简洁,并且可读性非常好:id,name,subitems(id,name)分别表达了要从头items和subitems表中查询的字段。不过这里隐藏了一个基本的设计机制。从上面的REST API中,我们明显发现一个问题,join条件并没有出现在API接口中。
PostgREST在这里有一个设计约束:要想实现多表关联,表与表之间需要至少建立一条外键关联约束,以上面items和subitems表为例,就需要为subitems的item_id字段创建外键约束,指向items表的id字段。
如何调用Postgres中的函数(存储过程)
函数和存储过程是PostgREST使用过程中非常重要的工具,甚至有些用户将view(视图)和function(函数)当成PostgREST的最佳实践来使用。视图用以屏蔽业务表的字段设计,只将前端需要的数据返回, 函数则用来处理一些不方便在客户端编写的、数据敏感的业务逻辑。
那么当我们编写完PostgreSQL的函数后,如何通过REST API进行调用呢。PostgREST提供了rpc接口,我们以一个例子来介绍一下rpc接口的工作机制。
下面是一个简单的SQL编写的函数,实现两个整数相加:
CREATE FUNCTION add_them(a integer, b integer)
RETURNS integer AS $$
SELECT a + b;
$$ LANGUAGE SQL IMMUTABLE;
由于该方法不会修改数据库中的值,可以使用GET方法,对应的REST API接口调用方法:
GET /rpc/add_them?a=1&b=2
也可以使用POST方法,通过JSON将参数传递给函数:
POST /rpc/add_them
{ "a": 1, "b": 2 }
如果SQL编写的函数参数本身就是JSON格式,该如何调用呢,下面将add_them函数改写一下:
CREATE FUNCTION add_them(param json)
RETURNS integer AS $$
SELECT (param->>'a')::int * (param->>'b')::int
$$ LANGUAGE SQL IMMUTABLE;
对应的REST接口调用方法:
POST /rpc/add_them
Prefer: params=single-object
{ "a": 1, "b": 2 }
这里唯一多出来的是Prefer: params=single-object,需要在HTTP请求的header中增加该请求头。
Schema缓存
PostgREST为了实现上述API的能力,需要先把用户定义的所有表信息加载到内存中,并识别表与表之间的关联关系,这些关系是基于开发者定义的外键来构建的。通过构建表之间的关联关系,才能正确执行相应的join操作。
应用开发过程中,开发者修改表结构或者增加新的表定义是非常普遍的操作。为了能实时了解最新的数据库表结构情况,PostgREST利用了pg的Listen/Notify机制,监听用户的DDL操作。当有任何影响元数据准确性的操作发生时,PostgREST会立即重新加载schema信息。
事务
首先,PostgREST无法支持在客户端开启事务并执行多次API调用。这是目前PostgREST的一个短板。
PostgREST的每个API请求会开启一个事务,也就是说用户的一次API调用,PostgREST保证是原子的,要么全部数据更新成功,要么保持原样,不会因为API调用失败导致数据出现中间状态。
JSON数据处理
PostgREST提供REST API接口,其返回给客户端的结果是JSON格式的。不同于大多数web服务程序的做法,PostgREST完全依赖pg的能力来完成JSON返回结果的构建。什么意思呢?
我们仍旧以items表为例,目前items表里面的数据如下,有3条:
postgres=# select * from items;
id | name
----+----------
1 | zhangsan
2 | lisi
3 | wangwu
需求是查询id > 1的所有items并以列表形式返回对应的JSON数据,期望结果数据如下:
[
{"id":2,"name":"lisi"},
{"id":3,"name":"wangwu"}
]
我们知道,用户可以调用如下接口来获取数据:
GET /items?select=id,name&id=gt.1
该接口对应的SQL语句为:
SELECT id, name FROM items WHERE id > 1
那么如何在查询数据的同时,直接从数据库中得到最终需要的JSON数据呢,写法如下:
WITH essence AS (
SELECT id, name FROM items WHERE id > 1 ORDER BY name
)
SELECT
coalesce(
array_to_json(array_agg(row_to_json(response))),
'[]'
)::character varying AS BODY
FROM (SELECT * FROM essence) response
上面的语句执行结果为:
postgres-# FROM (SELECT * FROM essence) response;
body
---------------------------------------------------
[{"id":2,"name":"lisi"},{"id":3,"name":"wangwu"}]
(1 row)
PostgREST拿到结果后,不需要做任何处理,直接将body字段的值返回给客户端即可。
这就是PostgREST REST API的全部魔法了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









