








1.平台无关性
(1)为什么要先编译成java字节码再解析成机器码
a.准备工作:每次执行都需要各种检查。
因为编译的过程本来就是在进行编译以及检查的过程,如果直接对java代码解析成机器码,岂不是每次解析的时候都需要进行检查,何不提前检查好了,再进行解析
b.兼容性:也可以将别的语言解析成字节码
比如Clojure,Groovy, JRuby, Jython , Scala等他们最终会 通过不同的编译器(java是javac编译器)编译成 .class字节码在虚拟机进行运行
(2)JVM如何加载.class文件
java虚拟机:
a.JVM内存结构模型
JVM是内存中的虚拟机,可以理解为,JVM的存储就是内存,我们所有写的常量,变量,方法都在内存中
JVM架构:
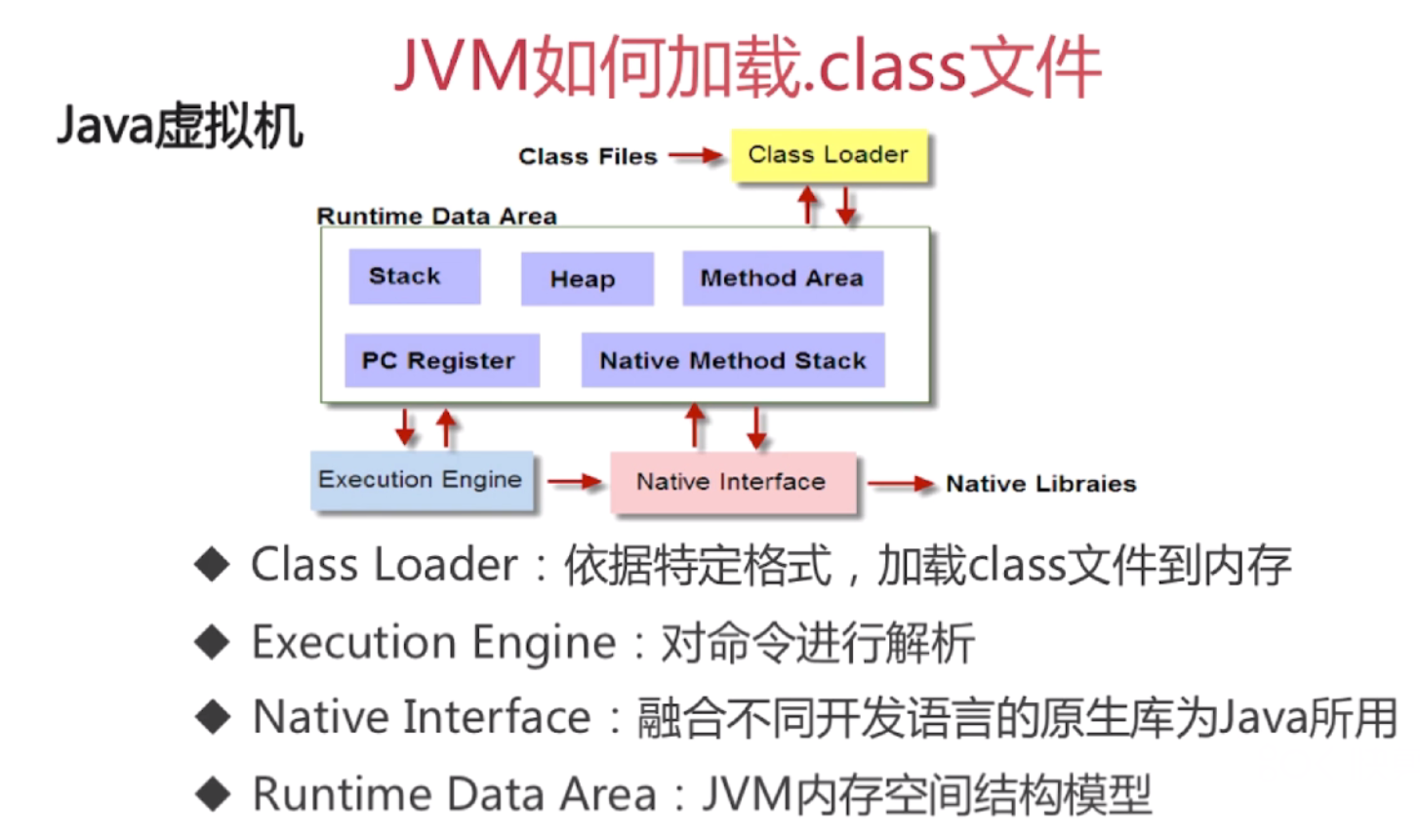
ClassLoader(类加载器): 依据特定的格式,加载class文件到内存
Runtime Data Area(运行数据区域):JVM内存空间结构模型
Execution Engine (执行引擎):对命令进行解析(解释器,对命令进行解析,能不能运行需要他来负责)
Native Interface(本机接口):融合不同开发语言的原生库为java所用,使用Class.forName()方法中的forName0()方法进行其他语言的类库的调用,返回值是native
类从编译到执行的过程(java从源码到运行共有三个阶段)
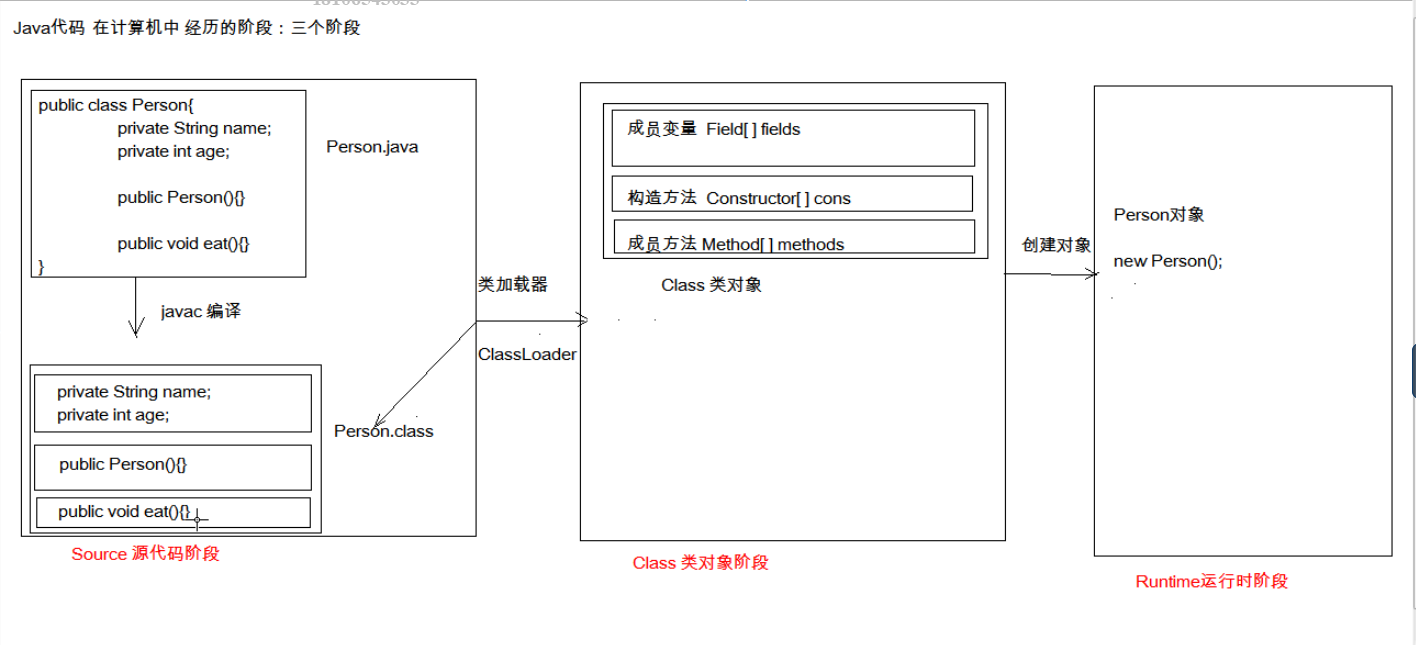
编译器将*.java源文件编译为*.class字节码文件Source源码阶段
ClassLoader将字节码转换为JVM中的Class<对象名>对象(实质是byte数组)Class类对象阶段
JVM利用Class<对象名>对象实例化 * 对象加载到内存Runtime运行时阶段
ClassLoader
作用:
ClassLoader负责通过将Class文件的二进制数据流(使用io流进行读取的)装载进系统,然后交给java虚拟机进行连接,初始化操作(从系统外获取Class的二进制数据流)
种类:(Alibaba Dragonwell 是一款免费的 OpenJDK 发行版)
BootStrapClassLoader :C++编写,加载核心库java.*http://hg.openjdk.java.net/jdk8u/jdk8u/jdk==>browse==>src==>share==>native==>java.lang
ExtClassLoader :java编写,加载扩展库javax.* System.out.println(System.getProperty("java.ext.dirs"));
AppClassLoader :java编写,加载程序所在目录System.out.println(System.getProperty("java.class.path"));
自定义ClassLoader
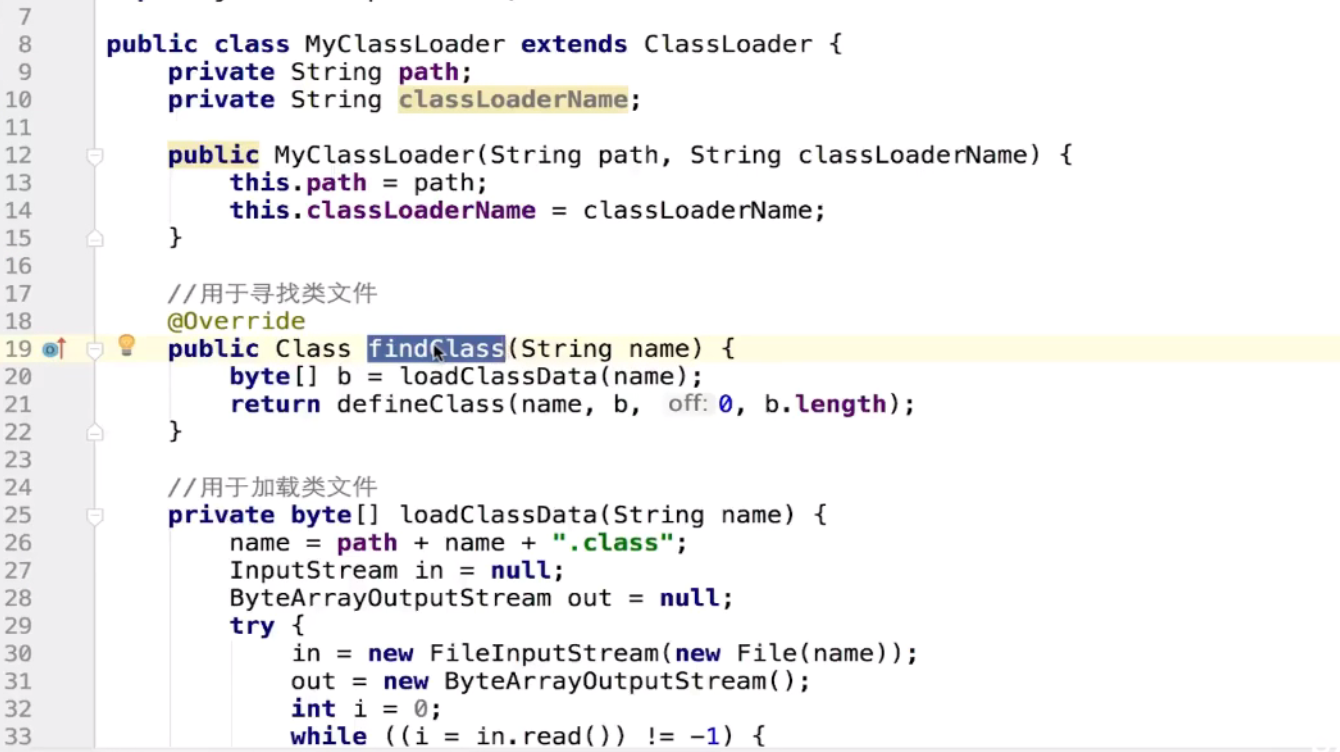
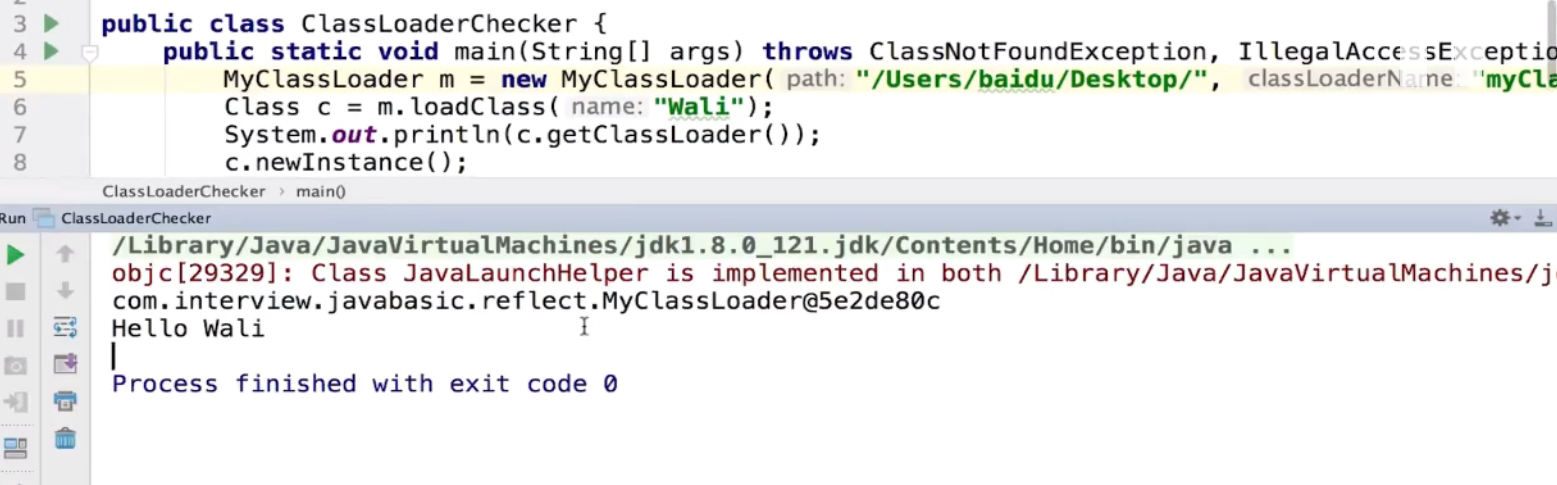
双亲委派机制:
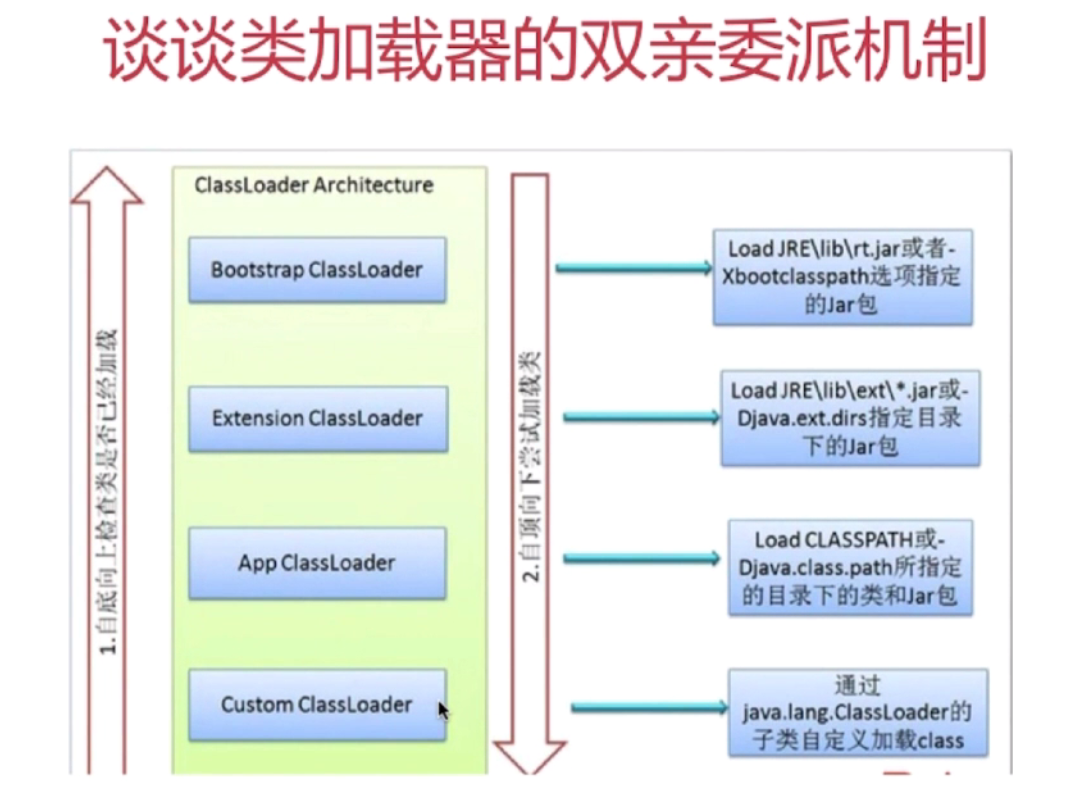
1.自下向上*检查*类是否已经加载自定义ClassLoader==》AppClassLoader==》ExtClassLoader ==》BootStrapClassLoader
2.自上向下尝试*加载*类BootStrapClassLoader (jre/lib/rt.jar)==》ExtClassLoader(jre/lib/ext/*.jar) ==》AppClassLoader(classpath目录)==》自定义ClassLoader
小编总结:双亲委派机制:检查类是否加载的时候,顺序是自下而上的。如果是加载类的时候,顺序是自上而下的
有资料或文档需求的可以私信我哦(发送“资料”二字即可)
为什么要使用双亲委派机制:
1.避免多份同样字节码的加载(使用委托机制逐层去父类查找是否加载)
类的加载方式:(了解)
隐式加载:new (隐式调用类加载器将类加载带JVM)
显式加载:loadClass,forName等
loadClass和forName的区别:(了解)
Classloder.loadClass得到的class是没有链接的JDBCUtils.class.getClassLoader()//getResourceAsStream("druid.properties")
Class.forName得到的class是已经初始化完成的Class.forName("cn.itcast.utils.JDBCUtils")
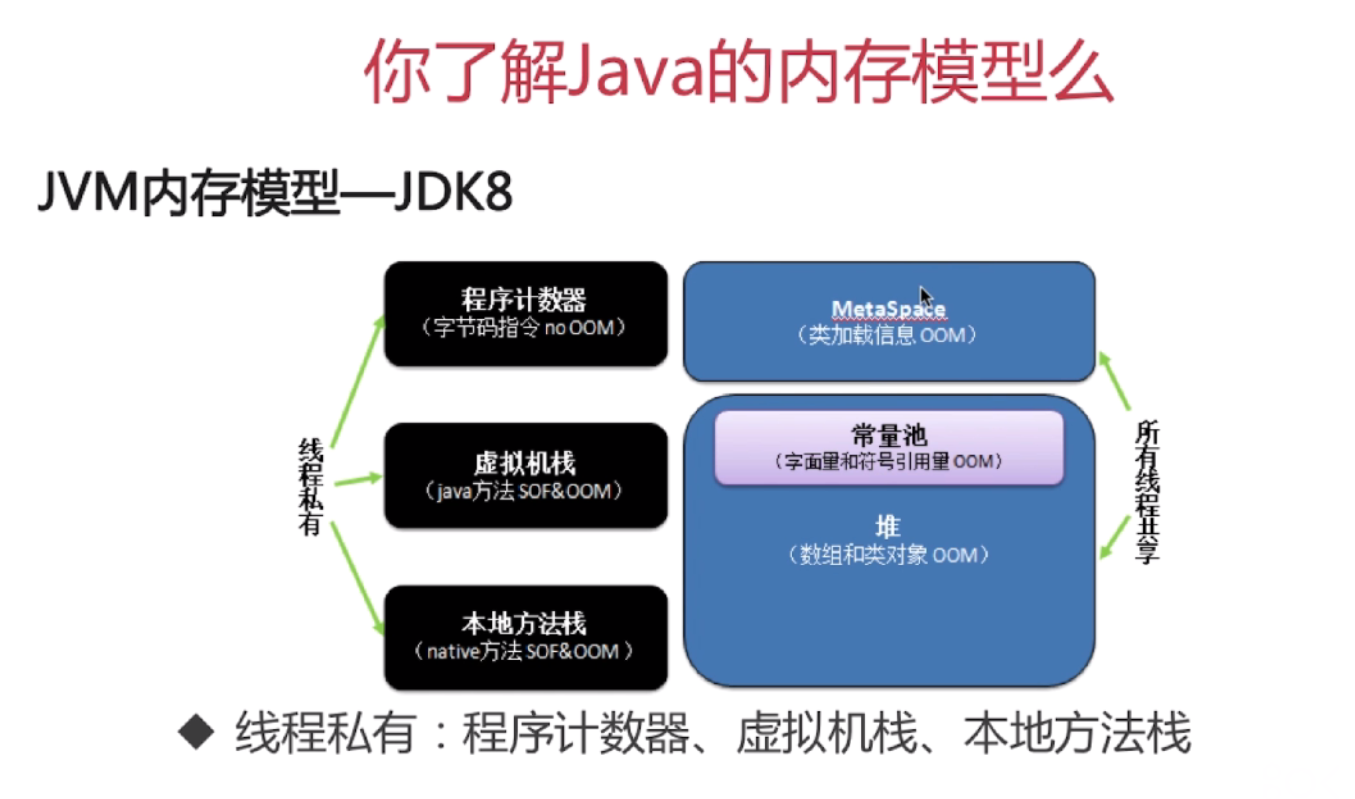
JVM内存模型-JDK8:
1.程序计数器:
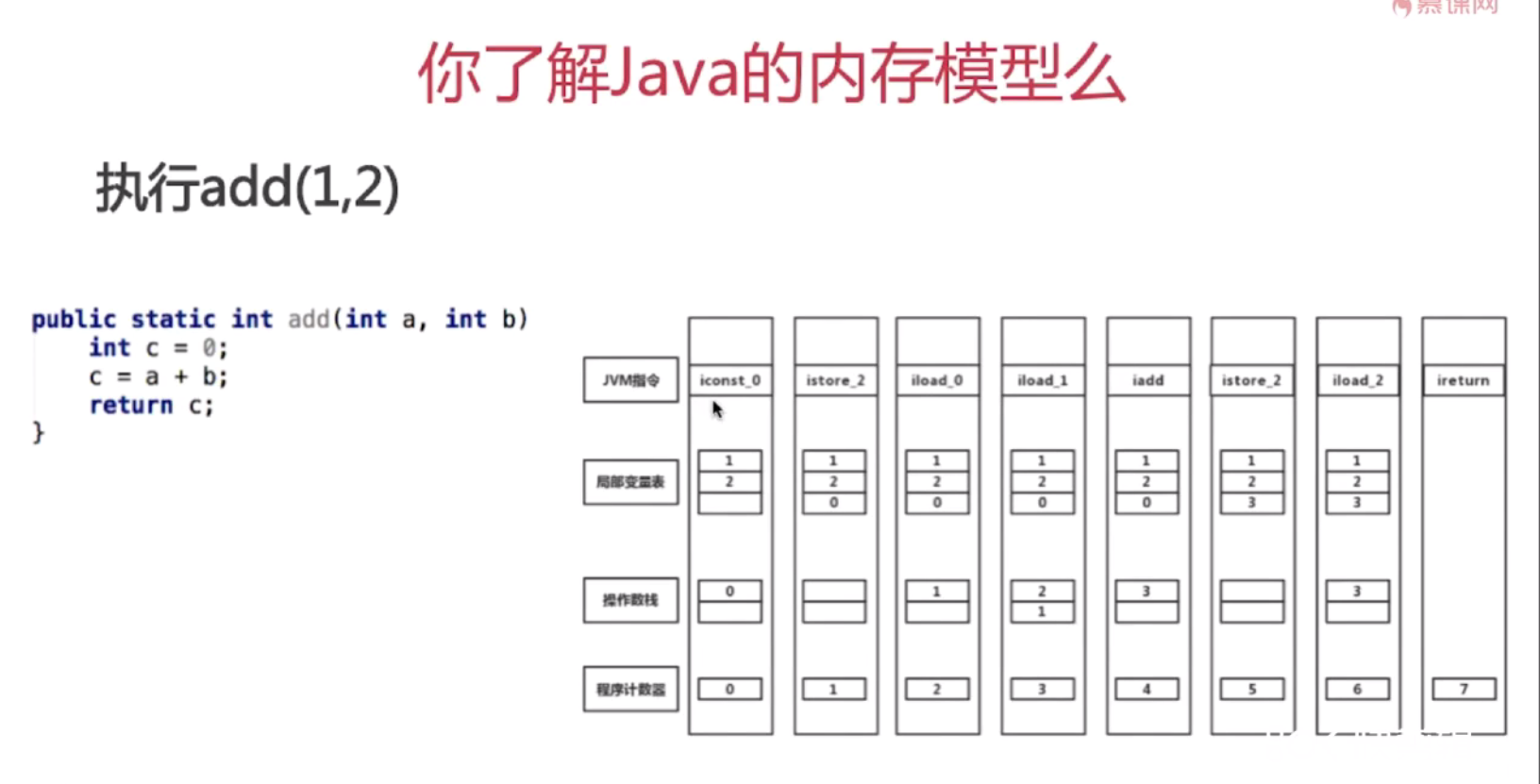
作用:
1.当前线程所执行的字节码行号指示器(逻辑)
2.改变计数器的值来选取下一条需要执行的字节码指令
3.和线程是一对一的关系,即线程私有
4.对java方法技术,如果是Native方法,则计数器值为Undefined
5.不会发生内存泄漏
干什么用的:循环,跳转,异常处理,线程恢复 都是【程序计数器】通过【改变计数器的值】来实现的,命令指向的作用。
2.java堆(Heap):
对象实例分配区域
GC管理的主要区域
3.java虚拟机栈:
1.java方法执行的内存模型,每个方法运行的时候都会创建一个栈帧【一个栈帧就相当于一个方法执行的时候,存在栈里面的状态】
2.包含多个栈帧,栈帧用来存储(局部变量表【局部变量存储的地方】,操作栈【进行运算的地方】,动态连接?????,返回地址)方法调用结束时,帧才会被销毁
局部变量表:包含方法执行过程中的所有变量
操作数栈:入栈,出栈,复制,交换,产生消费变量
递归为什么会引发java.lang.stackoverflowerror异常?
递归过深,栈帧数超出虚拟栈深度,方法调用层次过多
java.lang.OutOfMemoryError异常?
虚拟机栈开启过多,线程开启太多,导致内存不足以创建新的虚拟机栈
扩展:方法结束,栈帧会自动释放,栈的内存,不需要GC去回收
(jstack命令可以生成虚拟机当前时刻的线程快照,可以定位线程出现长时间停顿的原因,如线程间死锁,死循环,请求外部资源长时间的等待)
jmap
本地方法栈:
与虚拟机栈相似,只要作用于标注了native的方法
4.方法区:
方法区里面存储了类信息、静态变量、即时编译器编译后的代码(比如spring 使用IOC或者AOP创建bean时,或者使用cglib,反射的形式动态生成class信息等)等。
JDK1.7及以后,JVM已经将运行时常量池从方法区中移了出来,放到堆中
元空间(MetaSpace):【方法区的实现,可以理解为方法区是规定放什么东西,元空间是真正存放方法区规定东西的内存】
永久代:是HotSpot(虚拟机)的一种具体实现,实际指的就是方法区
元空间与永久代(PermGen)的区别
元空间使用本地内存,永久代使用的是JVM内存
元空间相比永久代的优势
1.字符串常量池存在永久代中,容易出现性能问题和内存溢出
2.类和方法的信息大小难易确定,给永久代的大小指定带来困难
3.永久代会为GC带来不必要的复杂性【不懂】
4.方便HotSpot与其他JVM如Jrockit的集成
扩展:
JVM三大性能调优参数 -Xms -Xmx -Xss的含义
命令演示:java -Xms128m -Xmx128m -Xss256k -jar ****.jar
-Xss:规定了每个线程虚拟机栈的大小,一般来说256k足够,此配置会影响此进程中并发线程数的大小
-Xms:堆的初始值 (如果堆的大小超出初始值的容量怎么办,会扩容到-Xmx配置的堆的内存最大值)
-Xmx:堆能达到的最大值,一般来说我们的初始值和最大值设置一样,以避免每次垃圾回收完成后JVM重新分配内存
java内存模型中堆和栈---内存分配策略(了解)
静态存储:编译时就能确定每个对象目标在运行时的存储空间需求
栈式存储:(动态存储)数据区需求,在编译时未知,运行时模块入口前确定
堆式存储:编译时或运行时,模块入口都无法确定,动态分配
java内存模型中堆和栈的联系:
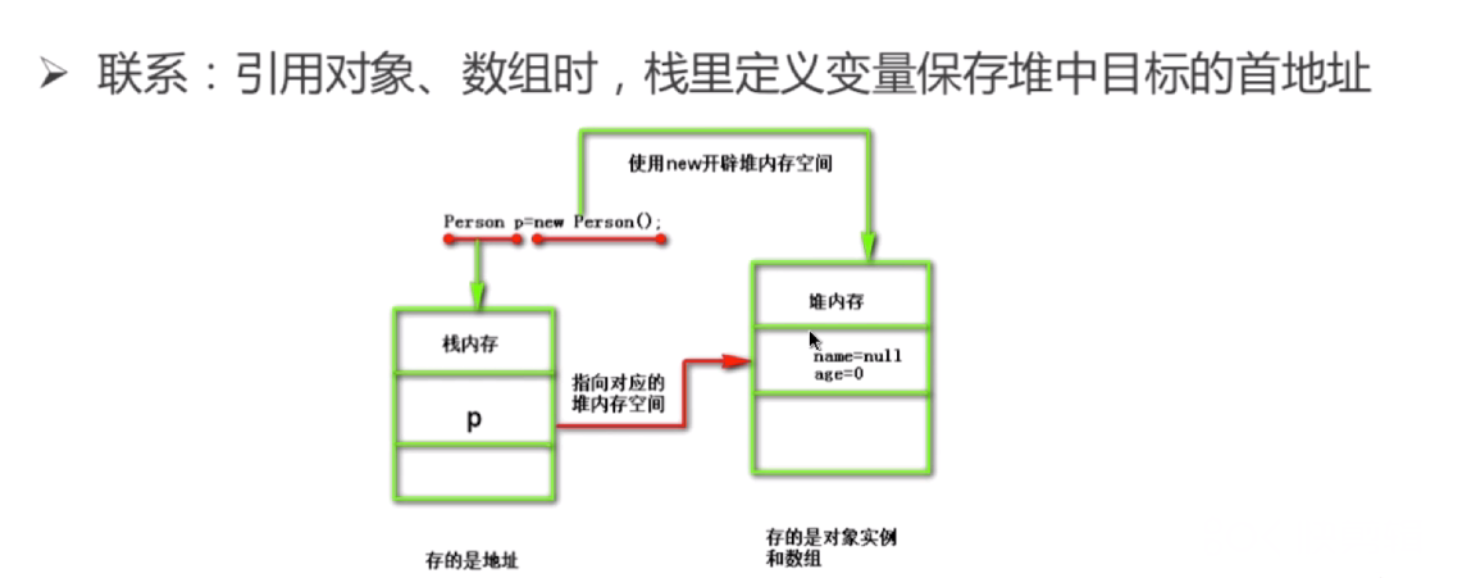
引用对象、数组时,栈里定义变量保存堆中目标的首地址
java内存模型中堆和栈的区别【重点】:
管理方式:栈自动释放,堆需要GC进行垃圾回收
空间大小:栈比堆小
碎片相关:栈产生的碎片远小于堆(内存不能及时释放产生的碎片,因为GC不是实时的)
分配方式:栈支持静态和动态分配,而堆仅支持动态分配
效率:栈的效率比堆高
2.GC【Garbage Collection】
对象被判定为垃圾的标准,没有被其他对象引用的情况下
怎么判定是否为垃圾的算法
a.引用计数算法(了解)
通过判断对象的引用数量来决定对象是否可以被回收
每个对象实例都有一个引用计数器,被引用则+1,完成引用则-1
任何引用计数为0的对象实例可以被当做垃圾收集
优点:执行效率高,程序执行受影响小
缺点:无法检测出循环引用的情况,导致内存泄漏
b.可达性分析算法(我们现在使用的是这个算法)
通过判断对象的引用链(GC Root)是否可达,来决定对象是否可以被回收
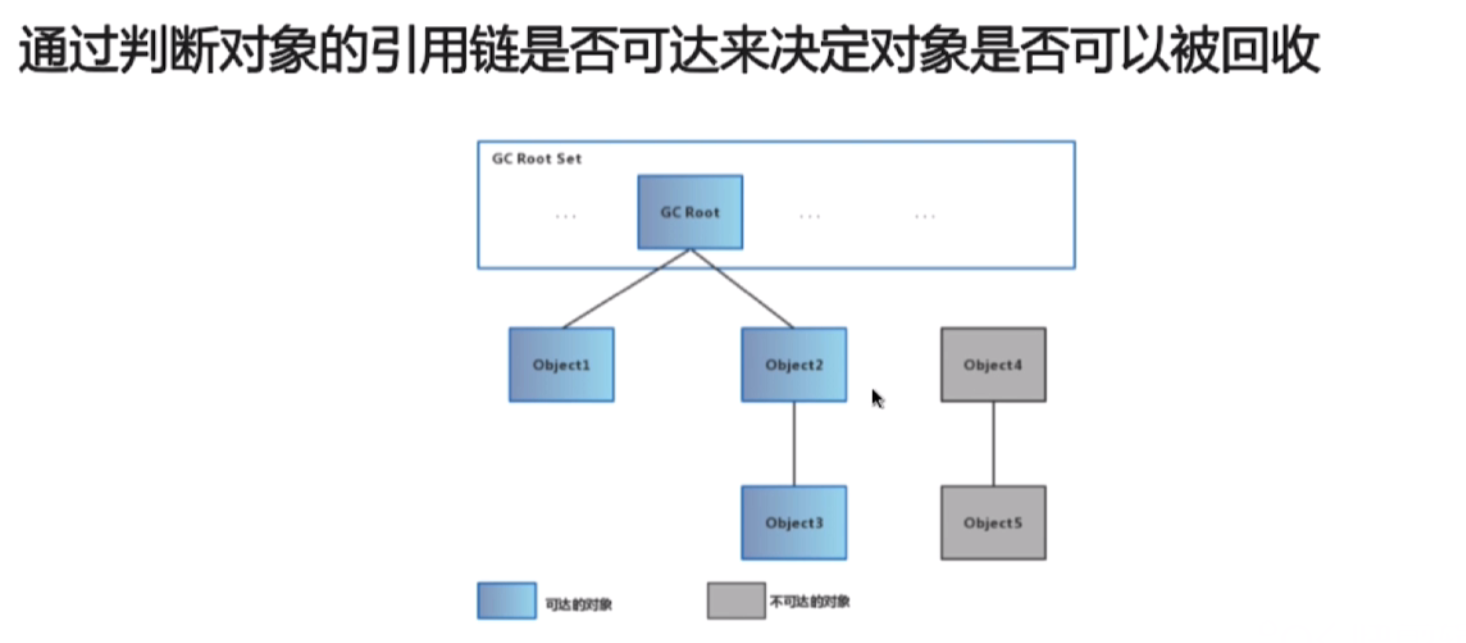
如果GC Root判断对象是可达对象,就会将此对象标记为蓝色
如果GC Root判断对象是不可达对象,就会将此对象标记为灰色,标记为灰色的对象就会被GC回收
哪些对象可以作为GC Root对象
1.栈中引用的局部变量【方法里面的对象】【方法执行会被引用】
2.方法区中类【静态】属性引用的对象【类中的对象】【类加载会被引用】
3.方法区中常量引用的对象【常量】【类加载会被引用】
4.本地方法栈中JNI(即一般说的Native方法)引用的对象【native方法的引用】















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









