






数据分析综合案例:
数据分析流程
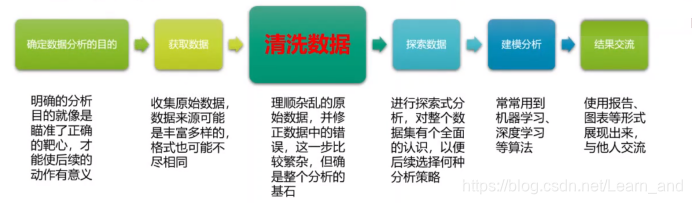
什么是数据清洗?
简单来说,数据清洗就是把“脏数据”变为“干净的数据”。数据清洗虽然很繁琐,但也很重要。
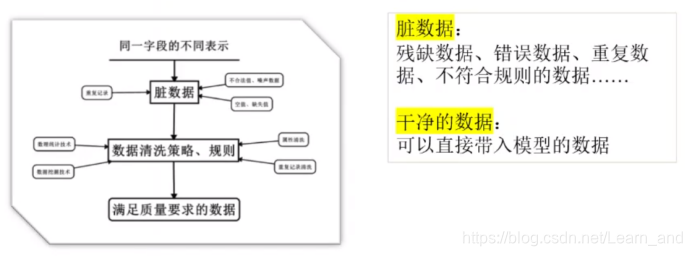
数据清洗流程:
数据的读写、数据的探索与描述、数据简单处理、重复值的处理、缺失值的处理、异常值的处理、文本字符串的处理、时间格式序列的处理。
注意:重复值的处理、缺失值的处理、异常值的处理、文本字符串的处理、时间格式序列的处理,这几个顺序可根据实际情况调整顺序。
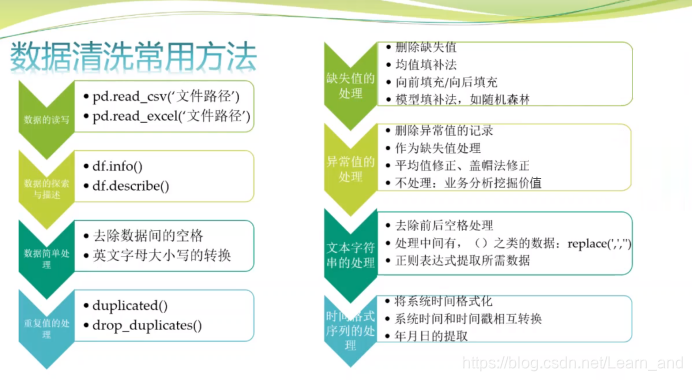
【向前填充】就是使用缺失值前面的数据进行填充,同理,【向后填充】就是使用缺失值后面的数据进行填充,这种方法处理缺失值是非常适用于时间序列的数据。
代码:
导入相关包:
- 提示:%matplotlib inline表示当输入plt.plot(x,y_1)后,不必再输入plt.show(),图像将自动显示出来。
数据如下:
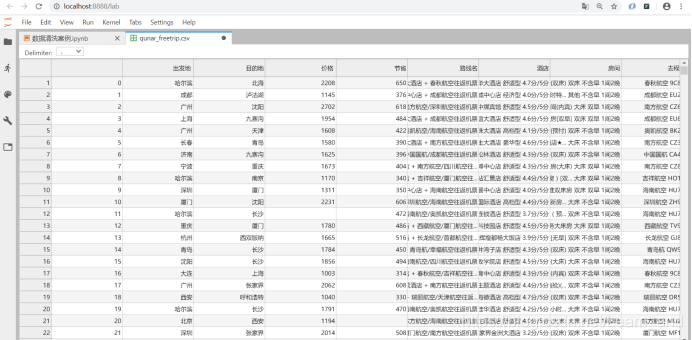
读取数据集:

- 提示:index_col表示csv文件中的第0列作为数据集的行索引,index_col=0,直接将第一列作为索引,不额外添加列,也就是将csv文件中的第0列不作为数据而是认为是索引。
初步探索数据:
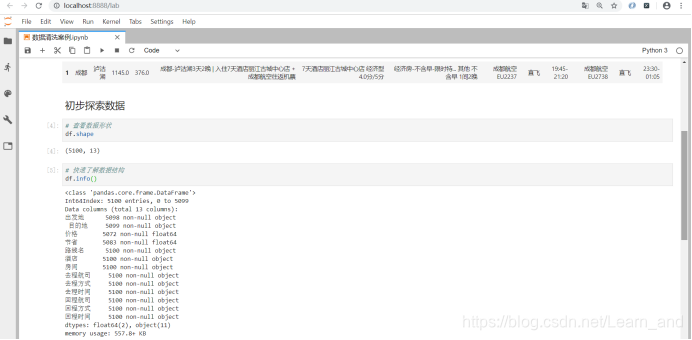
- 提示:有的字段不够5100,那就表示这些字段是有缺失值的,目的地字段名中有空格。

- 提示:显示数值型数据的描述统计,文本类型的数据它就默认不管了。
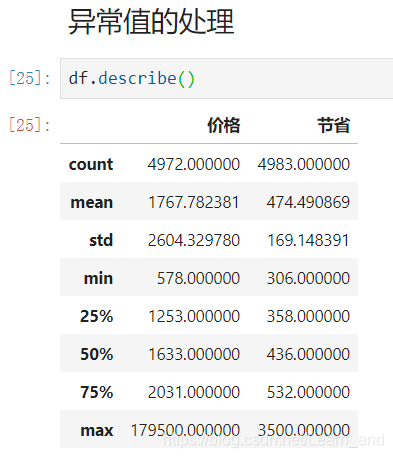
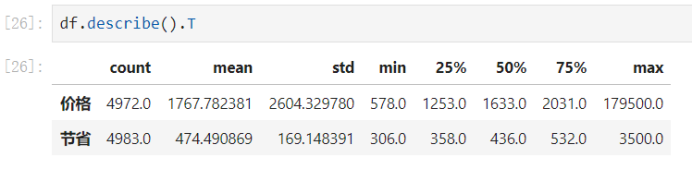
count统计的是个数,mean表示平均值,std表示标准差,min表示最小值,25%表示整个数据的前4分之一位的数据是多少,50%表示整个数据的中位的数据是多少,75%表示整个数据中的4分之3位的数据是多少,max表示最大值。
- 提示:通过这些信息我们总结出:数据是有缺失值和异常值的。
缺失值通过info()和count()总结出来的。
异常值通过75%的max之间的差距过大。
简单的数据处理:
显示所有的列名:也就是显示列索引。
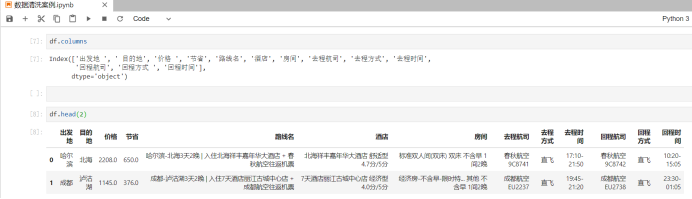

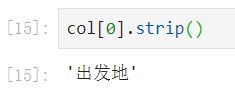
- 后来发现价格的后面还有一个空格:
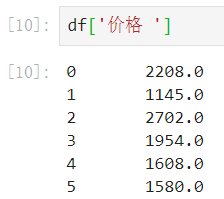


strip()方法可以去除字符串两边空格。


重复值的处理:


- 重复值:这两条记录中所有的数据都相等才叫做重复值,比如每一条记录都有13列,那这两条数据中的13个数据都要相等才认为是重复的数据。

- 提示:值为True的位置为重复值所在的位置。
查看重复值的数据:
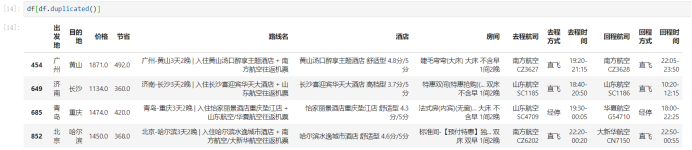
统计重复数据的个数:
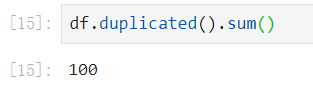
- 也就是有100个重复的数据。
删除重复值drop_duplicates():

- inplace=True表示在原始的数据集上进行删除,否则不会对原始数据进行修改,而是有返回值,需要接收这个返回值,添加上这个参数以后就没有返回值了。
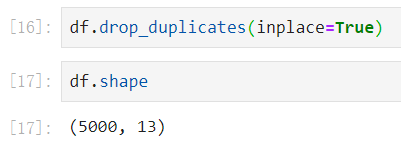


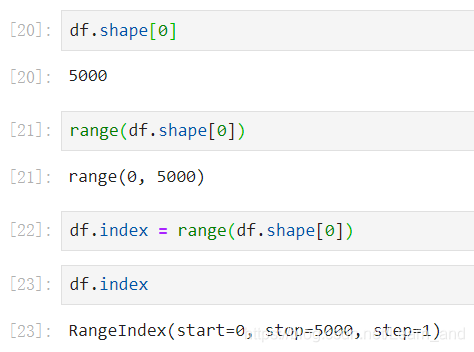
- 提示:删除了重复值数据以后,我们发现总共有5000行,那是最后一些数据的行索引有的还是超过5000的,图中的5099索引。
删除重复值后重新设置索引:

总结:这就是重复值的处理。
异常值的处理:
- 提示:填补缺失值的时候是不希望异常值作为填补的依据,所以要先处理异常值的存在。
- 用【三倍标准差】来进行衡量是否为异常值,大于三倍标准差的为异常值:标准偏差简称标准差,std()方法是用来计算标准偏差的函数。
先来找出【价格】字段的异常值:
- mean()方法是求平均值,std()方法是求标准差。
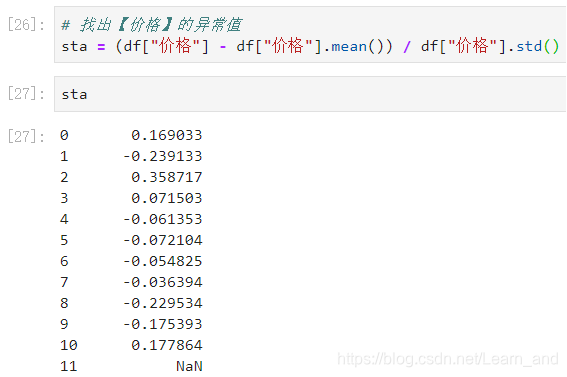
- abs()方法是取绝对值,[:10]表示前10个,表示只观察前10个数据。
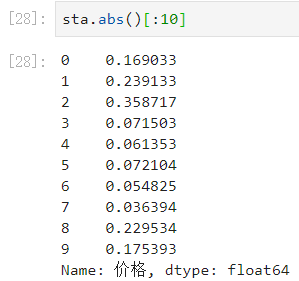
- 大于3倍标准差的为True,否则是False。
- 查看具体的异常信息:

分析异常原因:
上面这个旅游线路的价格我们发现是有异常,天价的旅游线路啊,找出来以后,我们就要分析了,是人为录入的问题?还是什么别的原因?
- 提示:一会再来处理异常的字段值。
再来找出【节省】字段的异常值:
价格字段的值是没有优惠前的价格,所以,我们认为节省字段的最大值应该与价格相等或是比价格字段的值要小,是不能比价格还要大的。
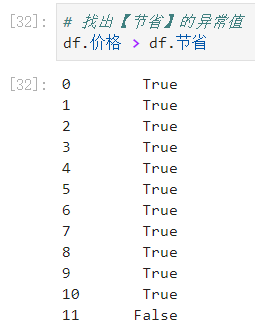
- 上面我们发现11的节省字段值比价格字段的值要大,那我们就找到了异常。
统计节省字段异常值的数量:
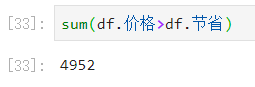
- 上面是统计的价格比节省大的记录数,总共有4952条,总共是5000条记录,那还差48条记录,这48条记录中有可能都是异常,也有可能有的是异常有的是缺失值,也有可能是价格等于节省。
- 所以,最直观的查法:节省比价格还要大的记录:

异常值处理的思想:

将找到的异常值拼接起来进行处理:

拿到这些异常值的索引:
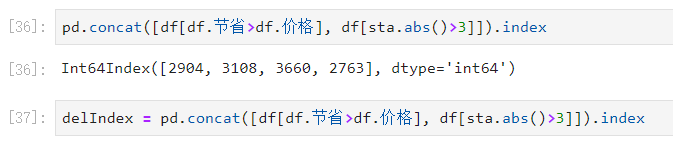
最后,删除这些异常值:
drop()方法在进行删除数据的时候,需要传递的是数据的行索引值。
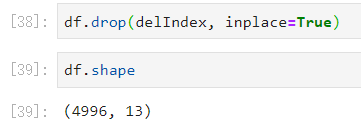
上面我们发现已经删除了那4条异常的值了。
需要向上面那样,再来重新的设置一下索引值:

缺失值的处理:

查看缺失值:
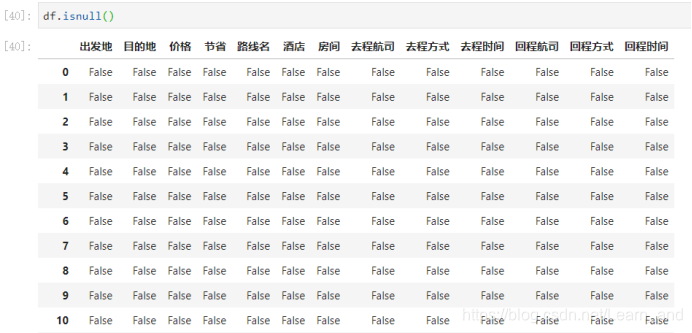
上面这个方法是用来判断每一个数据是不是缺失值。那数据太多了,我们可以使用下面的方法进行统计出来:出发地有2个缺失值,目的地有1个缺失值,价格有28个缺失值…

- 先来:查看具体的【出发地】的缺失值数据:

但是通过路线名字段的值我们可以知道是从【大连】到【烟台】,另一个是从【济南】到【西安】。
处理【出发地】缺失值:



查看是否处理成功:
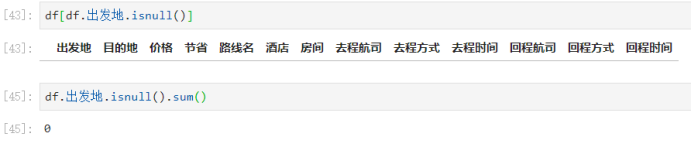
- 这样就解决了。
再来:查看具体的【目的地】的缺失值数据:



处理【目的地】的缺失值:

查看是否处理成功:

再来:处理价格的缺失值。
提示:价格的缺失值使用均值来进行填充。
先来求出价格的平均值:
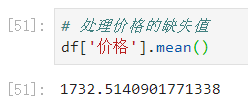
再来对价格的平均值进行四舍五入:
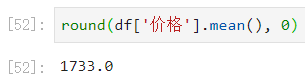
最后对价格缺失值进行处理:

再来:处理节省的缺失值:

最后,再来确认一下:

(这一步看机器学习算法中需不需要)处理文本型数据:
如果我们想要在一系列文本提取信息,可以使用正则表达式,正则表达式通过被用来检索某个规则的文件。

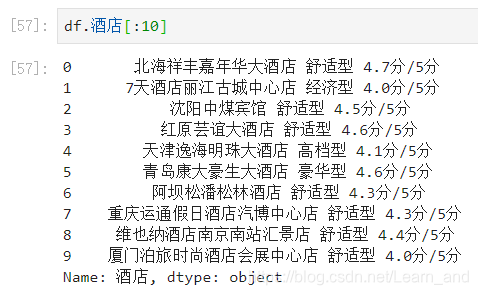
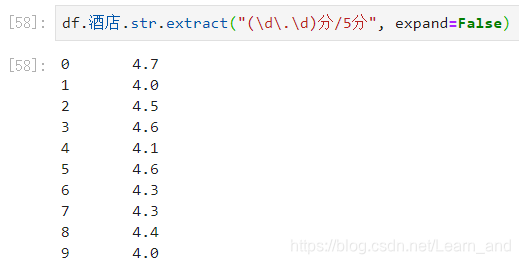
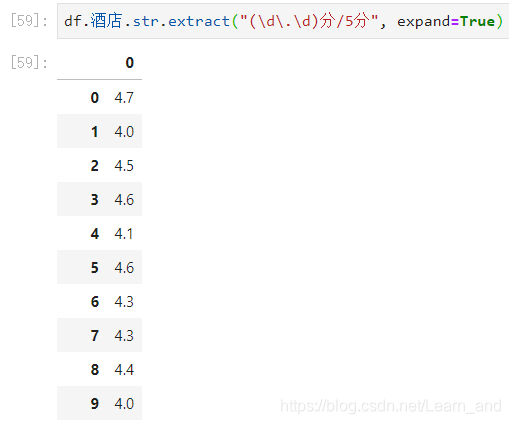
提取酒店评分:
expand参数的值为false表示是一个Series类型,如果是True表示是一个Dataframe类型的。
再来:人为的为数据添加一个字段:


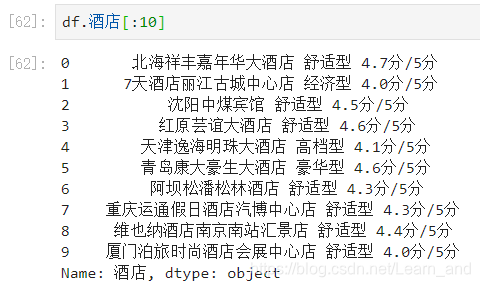
提取酒店等级:

再来:人为的为数据添加一个字段:


下面是显示第14行的所有列信息:

提取酒店天数:


- 数据分析就是一个想像的工作性质…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









