







1.什么是ElasticSearch(以下简称ES)
Elasticsearch 是什么? | Elastic![]() https://www.elastic.co/cn/what-is/elasticsearch
https://www.elastic.co/cn/what-is/elasticsearch
简单来说,我们的目标是帮助每个人更快地找到所需内容,从需要通过内网获取文档的员工,到在网上购物寻找适合自己鞋子的客户。但从更技术的角度来说,大致描述如下:
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是一套适用于数据采集、扩充、存储、分析和可视化的免费开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
好吧,上面说的其实还不够简单,总的来说,首先ES是一款搜索引擎,其次它还可以存储数据。就是这么简单。
1.1ES和关系型数据库对照

2.特点
既然当下大多数企业都选用ES作为搜索引擎,那么它必然是有很多优点的。我们来看一看ES拥有什么其他中间件或者数据库所没有的特点。通过对官网介绍的解读:Elasticsearch is a real-time, distributed storage, search, and analytics engine 我们不难发现以下四个特点
- 分布式
- 实时
- 搜索
- 分析
2.1分布式
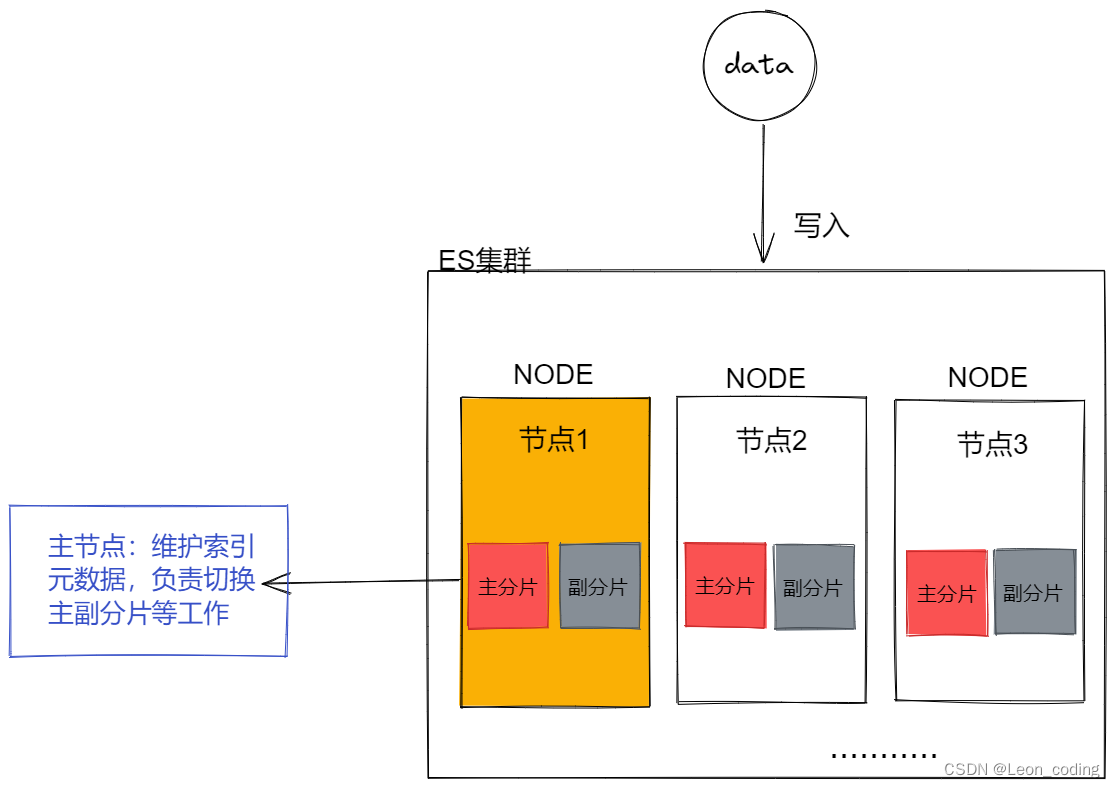
一个Elasticsearch集群会有多个Elasticsearch节点,所谓节点实际上就是运行着Elasticsearch的进程。
在这些节点中会有一个Master Node作为主节点,它主要负责维护索引元数据、负责切换主分片和副本分片,如果主节点挂了,会选举出一个新的主节点。从上面对照表我们也已经得知,Elasticsearch最外层的是Index(相当于数据库 表的概念);一个Index的数据我们可以分发到不同的Node上进行存储,这个操作就叫做分片。
比如现在我集群里边有3个节点,我现在有一个Index,想将这个Index在3个节点上存储,那我们可以设置为3个分片。这3个分片的数据合起来就是Index的完整数据。从这个角度来讲,ES分布存储的特点就很清晰了。
分片带来的好处,其实和我们熟知的服务器分布式集群带来的好处近乎相同。
1.分摊存储数据的任务,每个节点存一部分不会导致一个节点存太多而瘫痪。
2.多个分片,读写可以并发执行,吞吐量高,效率高。
2.每个分片都有一个副本分片,存储在不同的节点。数据写入的时候是写到主分片,副本分片会复制主分片的数据,读取的时候主分片和副本分片都可以读,如果某个节点挂了,主节点MasterNode就会把对应的副本分片提拔为主分片,这样即便节点挂了,数据也不会丢失。实现了高可用。
2.2实时
如果我们严谨一点的讲,ES是近乎实时的。我们先来梳理一下ES数据写入的过程。
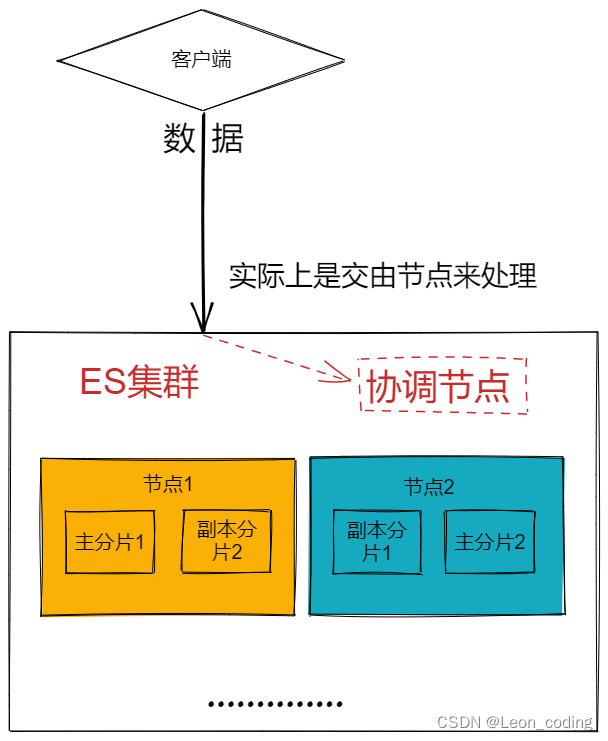
客户端写入一条数据,到Elasticsearch集群里边就是由节点来处理这次请求,每个节点都可以称之为协调节点,协调节点作为es节点中的一个节点,默认情况下es集群中所有的节点都能当协调节点,主要作用于请求转发,请求响应处理等轻量级操作。比如节点1接收到了请求,但发现这个请求的数据应该是由节点2处理(因为主分片在节点2上,注意这里是写操作),所以会把请求转发到节点2上。 协调节点会通过hash算法来计算对应的数据在哪个主分片,然后路由到对应的节点。当对应节点收到这条数据之后,会通过以下几步来完成写操作:
1.将数据写到内存缓存区
2.然后将数据写到translog缓存区
3.每隔1s数据从buffer中refresh到FileSystemCache中,生成segment文件,一旦生成segment文件,就能通过索引查询到了,一个index就是由若干个segment组成的
4.refresh完,memory buffer就清空了。
5.每隔5s中,translog 从buffer flush到磁盘中
6.定期/定量从FileSystemCache中,结合translog内容flush index到磁盘中。
2.3搜索
ES的搜索速度之所以快,是因为其倒排索引的结构。这一结构的设计可以允许十分快速地进行全文本搜索。倒排索引会列出在所有文档中出现的每个特有词汇,并且可以找到包含每个词汇的全部文档。倒排索引的底层实现是基于:FST(Finite State Transducer)数据结构。lucene从4+版本后开始大量使用的数据结构是FST。FST有两个优点:
1、 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
2、 查询速度快。O(len(str))的查询时间复杂度。
2.4分析
聚合分析数据
















 1737
1737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











