







ByteToMessageDecoder

这是一个入栈处理器,可以将一个流式的字节码转换为bytebuf或者其他的消息格式。上图实例就是从一个输入的bytebuf中读取所有的字节并重新创建一个新的bytebuf

一般情况下,这种处理器应该放在pipeline的前边,例如 DelimiterBasedFrameDecoder, FixedLengthFrameDecoder, LengthFieldBasedFrameDecoder, or LineBasedFrameDecoder. 要是自己定义解码器的时候实现了ByteToMessageDecoder那么要注意确保有足够的可读入的字节数,否则要继续等待,不要修改bytebuf的readindex。
可以使用绝对位置来获取 ByteBuf.getInt(int). in.getInt(in.readerIndex())
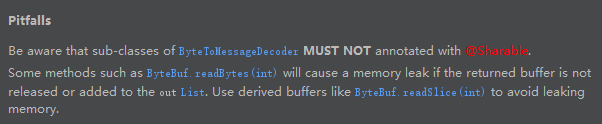
子类不要标注 @Sharable
如果使用ByteBuf.readBytes(int)的时候返回的buffer没有被释放掉或者被添加到out list中将会引起内存泄漏。可以使用ByteBuf.readSlice(int) 来避免
ReplayingDecoder

ByteToMessageDecoder的一个变形,是在阻塞io中的一个非阻塞解码实现
与ByteToMessageDecoder最大不同的是在你使用 decode() 和 decodeLast()的时候就像所有需要读取的字节都已经准备好了,不需要再检查所需的字节数够不够了。例如:


实现原理:如果buffer里要是没有足够的字节数那么就会抛出一个error给ReplayingDecoder,并且重置原来的readindex,如果有新的字节流入到buffer中,那么就会重新调用这个方法。
每次抛出的error是被缓存起来的,不是每次都会创建而浪费性能的,

限制:一些buffer其他的操作会被限制(例如会引起内存泄漏的方法),如果网络慢或者消息的格式比较复杂那么性能就不会太好,因为他会一次又一次的解析相同的部分,在解析一个消息的时候decode方法可能会被调用多次。
例如:

正确做法:

就是每次先将list清空,否则内部元素可能会多。

如何提高性能:使用enum来提高性能。

枚举中不同的值代表了不同的状态

通过ctx来动态改变pipeline中的handler















 1157
1157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









