







举个例子
我们考虑如下的这个结构体:
struct ALIGN {
char a;
int b;
char c;
};如果某个机器的整型值长度为4个字节,并且它的起始存储位置必须能够被4整除,那么这个结构体在内存中的存储将如下图所示:
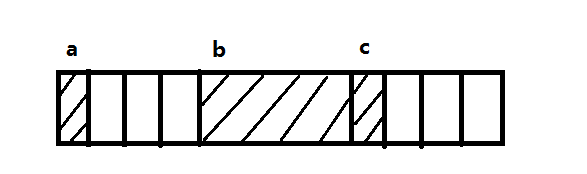
说明:系统禁止编译器在一个结构体的起始位置跳过几个字节来满足边界的对齐要求,因此所有结构体的起始存储位置必须是结构体中边界要求最严格的数据类型所要求的位置。因此,成员a(最左边那个方框)必须存储于一个能够被4整除的地址。结构的下一个成员是一个整型值,所以它必须跳过3个字节到达合适的边界才能存储。在整型值之后是最后一个字符。
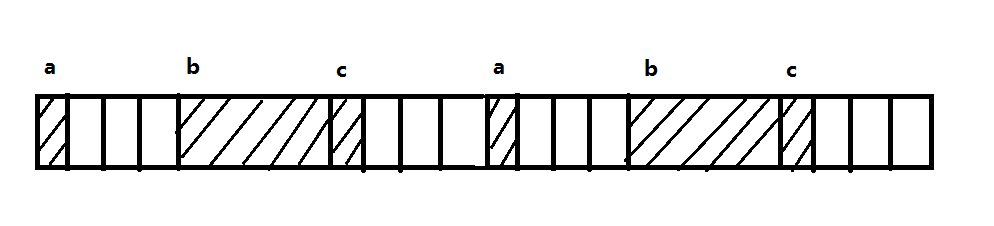
如果声明了相同类型的第二个变量,它的起始存储位置也必须满足4这个边界,所以第一个结构体的后面还要再跳过3个字节才能存储第二个结构体。因此,每个结构体将占据12个字节的内存空间,但实际只使用了其中的6个,这个利用率可不是很出色。
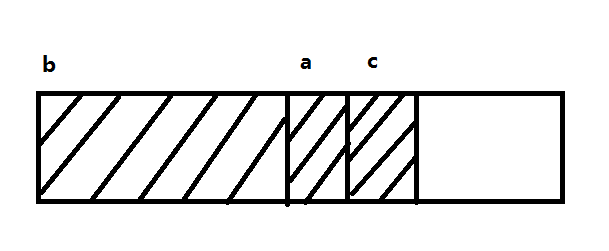
我们可以在声明中对结构体的成员列表重新排列,让那些对边界要求最严格的成员首先出现,对边界要求最弱的成员最后出现。这种做法可以最大限度地减少因边界对齐而带来的空间损失。例如:
struct ALIGN2 {
int b;
char a;
char c;
};它所包含的成员和前面那个结构体一样,但它只占用8个字节的空间,节省了三分之一。两个字符可以紧挨着存储,所以只有结构体最后面需要跳过的两个字节被浪费。
有时,我们有充分的理由,决定不对结构体的成员进行重新排列以减少因对齐带来的空间损失,例如:我们可能想把相关的结构体成员存储在一起,提高程序的可维护性和可读性。但是,如果不存在这样的理由,结构体的成员应该根据它们的边界需要进行重新排列,减少因边界对齐而造成的内存损失。
当程序将创建几百个甚至几千个结构体时,减少内存浪费的要求就比程序的可读性更为急迫。在这种情况下,在声明中增加注释可能避免可读性方面的损失。
sizeof操作符可以得出一个结构体的整体长度,包括因边界对齐而跳过的那些字节。如果你必须确定结构体中某个成员的实际位置,应该考虑边界对齐因素,可以使用offsetof宏:
#include <stddef.h>
// 得到指定成员开始存储的位置距离结构体开始存储的位置偏移了几个字节
size_t offsetof( structName, memberName );
例如,拿之前声明的结构体举例:
offsetof( struct ALIGN, b )的返回值为4。结构体数据成员对齐的意义
许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的起始地址的值是某个数k的倍数,这就是所谓的内存对齐,而这个k则被称为该数据类型的对齐模数(alignment modulus)。这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。
比如这么一种处理器,它每次读写内存的时候都从某个8的倍数的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,那么读或写一个double类型数据就只需要一次内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐要求的8字节内存块上。
参考资料:
1.Kenneth A. Reek.C和指针.北京:人民邮电出版社,2008
2.http://www.cnblogs.com/motadou/archive/2009/01/17/1558438.html















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









