







前言
本文是该专栏的第2篇,后面会持续分享Python办公自动化干货知识,记得关注。
有时在工作上,我们需要将大批量的pdf文件转换成word文档,有没有什么方法可以直接快速完成呢?不着急,关注小编,小编带你轻松解决。
项目需求
假设现在有个需求,一个文件夹下面有几百个pdf文件,如下:
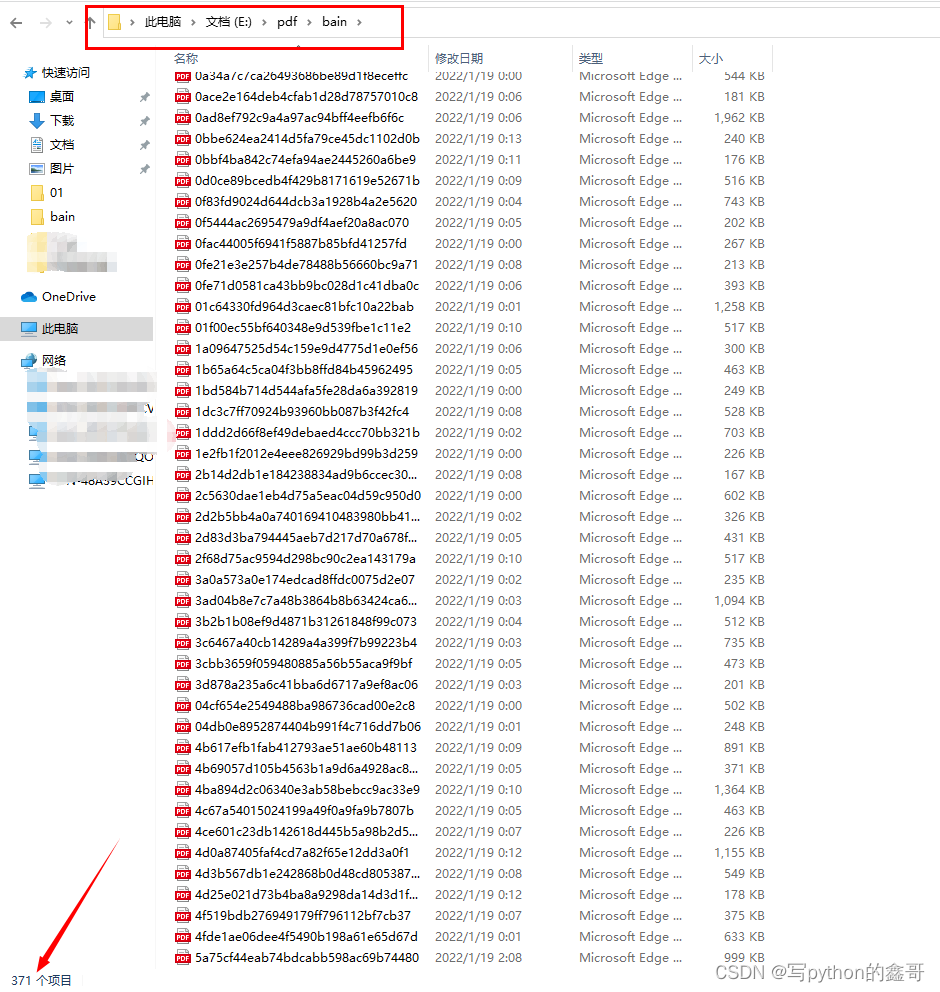
现在需要快速的将它们全部转换成word文档。
项目实现
import os
from pdf2docx import Converter
import time
import PyPDF2
'''
脚本实现:将PDF文件转Word
'''
def pdf_word():
file_path = r'E:\pdf\bain'
# 创建一个对应新文件夹,用于后期存放word文件
new_file = os.makedirs(file_path + '\\docx')
new_file_path = r'E:\pdf\bain\docx'
# 拿到目标文件夹下面的所有pdf
for root, dirs, files in os.walk(file_path):
'''
root:路径
dirs:目录
files:文件
'''
for f in files:
suff_name = os.path.splitext(f)[1] # 判断文件名后缀是否为pdf
if suff_name != '.pdf':
pass
else:
file_name = os.path.splitext(f)[0] # 获取文件名
target_pdf_name = file_path + '\\' + f # 目标pdf 文件路径
word_name = new_file_path + '\\' + file_name + '.docx' # 转换的word文件
print(word_name)
try:
PyPDF2.PdfFileReader(open(target_pdf_name, "rb")) # 检验pdf文件是否可以正常打开
cv = Converter(target_pdf_name)
cv.convert(word_name)
cv.close()
except PyPDF2.utils.PdfReadError:
print(target_pdf_name, "Invalid PDF file")
except OSError:
print("Not PDF file")
else:
pass
if __name__ == '__main__':
start = time.time()
pdf_word()
end = time.time()
print('task is over: %.2f' % (end-start))
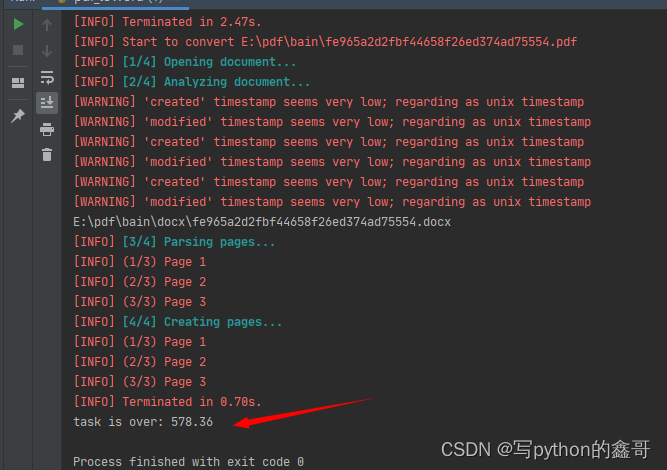
代码成功运行,显示如下说明word文档就自动的保存在对应的文件夹中了

之后,我们再看需要对应文件里面会生成一个新的文件夹如下:
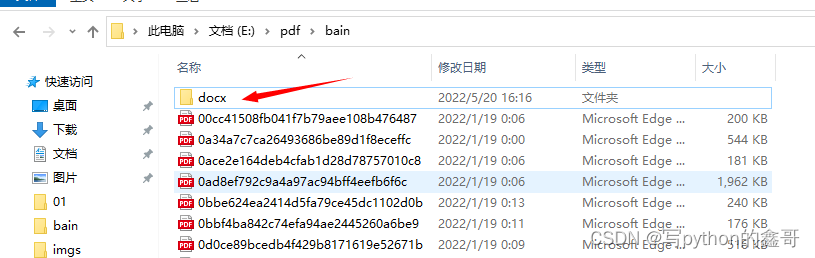
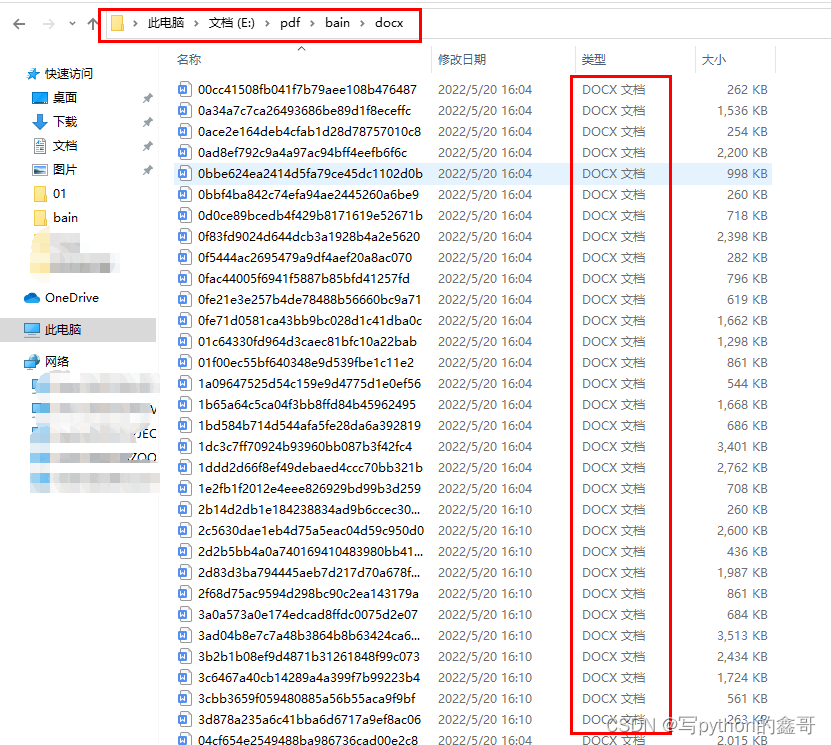 可能你会有疑问,371个pdf文件批量转成word花了多长时间呢,看下面的运行结果就知道,Python有多方便了。
可能你会有疑问,371个pdf文件批量转成word花了多长时间呢,看下面的运行结果就知道,Python有多方便了。
如果还想了解Python办公自动化的更多知识,后面我会持续分享,记得收藏并点赞,后面的python干货在等着你。
如果喜欢本文或者本文对你有帮助的话,记得收藏并点个赞,有问题和需求欢迎留言私信。
















 1919
1919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











