







网上搜索得知内联表查询一般的执行过程是:
1、执行FROM语句
2、执行ON过滤
3、添加外部行
4、执行where条件过滤
5、执行group by分组语句
6、执行having
7、select列表
8、执行distinct去重复数据
9、执行order by字句
10、执行limit字句
(1) from < left_table>
(3) < join_type> join < right_table>
(2) on < join_condition>
(4) where < where_condition>
(5) group by < group_by_list>
(6) with {cube | rollup}
(7) having < having_condition>
(8) select
(9) distinct (11) < top_specification> < select_list>
(10) order by < order_by_list>
标准的 sql 的解析顺序为: (1).from 子句 组装来自不同数据源的数据
(2).where 子句 基于指定的条件对记录进行筛选
(3).group by 子句 将数据划分为多个分组
(4).使用聚合函数进行计算
(5).使用 having 子句筛选分组
(6).计算所有的表达式
(7).使用 order by 对结果集进行排序
1.from:对from子句中前两个表执行笛卡尔积 生成虚拟表vt1
2.on:对vt1表应用on筛选器 只有满足 < join_condition> 为真的行才被插入vt2
3.outer(join):如果指定了outer join 保留表(preserved table)中未找到的行将行作为外部行添加到vt2 生成t3
如果from包含两个以上表 则对上一个联结生成的结果表和下一个表重复执行步骤1和步骤3 直接结束
4.where:对vt3应用where筛选器 只有使 < where_condition> 为true的行才被插入vt4
5.group by:按group by子句中的列列表 对vt4中的行分组 生成vt5
6.cube|rollup:把超组(supergroups)插入vt6 生成vt6
7.having:对vt6应用having筛选器 只有使 < having_condition> 为true的组才插入vt7
8.select:处理select列表 产生vt8
9.distinct:将重复的行从vt8中去除 产生vt9
10.order by:将vt9的行按order by子句中的列列表排序 生成一个游标 vc10
11.top:从vc10的开始处选择指定数量或比例的行 生成vt11 并返回调用者
SELECT
XXX
FROM XXX WHERE XXX GROUP BY XXX HAVING XXX
ORDER BY
XXX
LIMIT
XXX;
测试1:from先于where执行,where优先select执行
表结构数据:

查询工资大于本部门平均工资的员工
根据sql执行顺序正确写法:
SELECT
empno,ename,sal,deptno,(SELECT AVG(sal) FROM t_emp WHERE deptno = a.deptno) AS avgSal
FROM
t_emp AS a
WHERE
sal > (SELECT AVG(sal) FROM t_emp WHERE deptno = a.deptno)执行结果:
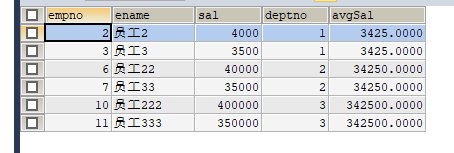
结论1:mysqll查询出正确的结果,a.deptNo可以使用,因此在执行where的时候from已经执行,from先于where。
根据sql执行顺序测试错误写法:
SELECT
empno,ename,sal,deptno,(SELECT AVG(sal) FROM t_emp WHERE deptno = a.deptno) AS avgSal
FROM
t_emp AS a
WHERE
sal > avgSal执行结果:

结论2:mysqll不知道avgSal,因此在执行where的时候select并没有执行,where先于select。
测试2:on优先于(join_type) join执行,(join_type) join 优先于where执行
表结构数据:
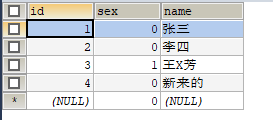
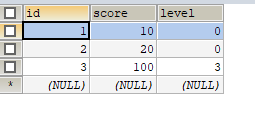
只查询参加过考试的学生成绩(标准写法应使用INNER JOIN,这里我测试sql执行顺序就不用这中写法了。)
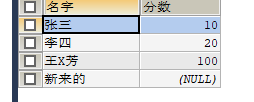
根据sql执行顺序正确写法:
SELECT
a.name AS '名字',
b.score AS '分数'
FROM
test_student a
LEFT JOIN test_score b ON a.id = b.id
WHERE
b.score IS NOT NULL测试结果:

结论1:on优先于join,join优先于where执行 。
根据sql执行顺序测试错误的写法:
SELECT
ts.name AS '名字', tc.score AS '分数'
FROM
test_student ts
LEFT JOIN test_score tc ON (ts.id = tc.id AND tc.score IS NOT NULL)测试结果:没有达到预期,没有考试的人员也查询了出来。
原因:on优先于join执行,即join的数据是on过滤后的数据(on执行前并没有生成中间表,tc拿的是原来表的数据,没有score为null的记录,where能限制到是因为join后中间已经生成,tc.score拿到的是中间表的数据,有score为null的数据,才会限制到,得出我们预期的正确结果)。
分析1:ON优先于join执行(但是left join test_score tc也被解析了,否则on不会拿到tc.id),即实际join的表为on条件限制后的数据,由于这个时候还没有后join表,因此tc实际是原来的表,原来的表中并没有score为null的行,因此新来的人员没有向我们预期的在on后面的条件中限制到。
分析2:join的真实数据是执行条件on后的数据,因此on只能限制到原来test_score中的数据,并不能限制到join后的中间表的数据,因为这个时候中间表还没有生成(这里where为什么能得到正确答案也就明白了,where执行的时候join和on已执行,中间表已经生成,where就限制的是join后的中间表,因此能判断到socre为null的数据)。
假设1:如果LEFT JOIN先于ON执行,则会立马根据被join的表生成中间表,然后根据on条件限制又生成一张中间表,要生成两次表,(mysql如果使用这种方式的话则上面没有达到预期的sql会达到我们的预期,查询出来的数据不会有未参加考试的人员)。
假设2:如果ON先于LEFT JOIN执行,则只需要根据on把符合条件的数据查询出来JOIN一次生成一张中间表就行了,效率高很多(msyql使用这种方式,则on不会限制到生成的中间表的数据字段,因为中间表还没有生成,因此才出现上面我们没有达到预期的结果)。
结论2:on优先于join执行,即join的数据为on限制后的数据,on中的tc为原始表数据,原始表数据无score为null的字段,on限制score is not null失败,join优先from(这个实验同时也说明了为什么在on后面加条件比在where后面加条件效率高得多,因为join的数据是on过滤后的数据,条件如果加到where后面,join就join的全部的数据,中间表就更大,并且where条件限制还要重新生成中间表)。















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









