








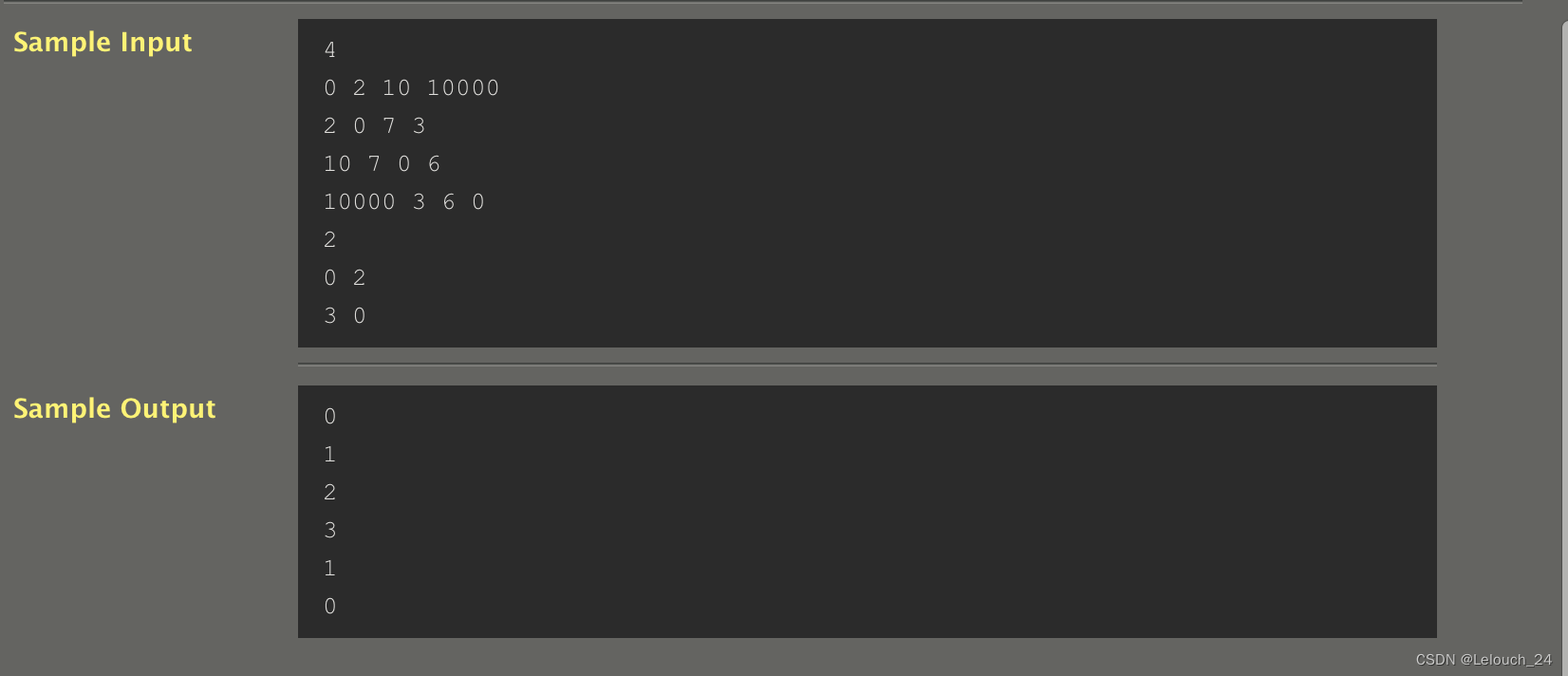
上一题 《用弗洛伊德算法求赋权图的两点间的最短路径》参考了别的文章
这题和上上题可以借鉴一样的思路,就稍微复杂一点的,在上一题的基础上,再创建一个三维数组,一个二维数组
int lu[maxnum][maxnum][maxnum]:第一个值设为a,第二个值设为b,第三个值设为c,a,b用于定位某个节点到某个节点,c用于记录路线,即,数组用于记录某个节点到各个节点最短路径的途经节点。
wei[maxnum][maxnum]:用于记录lu[maxnum][maxnum][maxnum]数组的路径最前端此时位于第几个位置,便于更新途径节点
更新最短路径时,应将前者路径复制到新路径的前端,然后再加上末节点,就完成了路径的更新。
写错啦!!!,那是迪杰斯特拉算法,后段只要加一个结点就行了,Floyd算法路径更新,前后都可能有不止一个结点,所以要把前后两个路径和起来,noj测试数据太拉了,没发现我之前写的错的,ac了,我也没发现,直到后来我写离散大作业(用Floyd算法实现城市之间最短路径计算)的时候,发现我的路径永远只有3个结点,才意识到有些问题,找了半天发现是路径更新这里出了问题,然后回头来把noj这里也改回来了(😓😓,在此之前看到文章的读者我太抱歉了哈哈哈哈哈,如果有机会回来再看到记得改掉)
代码如下:
#include <stdio.h>
#include <stdlib.h>
#define maxnum 105
int ans[maxnum][maxnum];
int lu[maxnum][maxnum][maxnum];
int wei[maxnum][maxnum];
void luchu(int n)
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
wei[i][j]=1;
for(int i = 0;i < n;i++)
{
for(int j = 0;j < n;j++)
{
lu[i][j][wei[i][j]]=i;
wei[i][j]++;
lu[i][j][wei[i][j]]=j;
wei[i][j]++;
}
}
}
void floyd(int n)
{
int i,j,k;
for(i = 0;i < n;i++)
{
for(j = 0;j < n;j++)
{
scanf("%d",&ans[i][j]);
}
}
for(k = 0;k < n;k++)
{
for(i = 0;i < n;i++)
{
for(j = 0;j < n;j++)
{
if(ans[i][j]>ans[i][k]+ans[k][j] ) //lu[i][j]=lu[i][k]+j
{
ans[i][j]=ans[i][k]+ans[k][j];
int w;
for(w=1;w<wei[i][k];w++)
{
lu[i][j][w]=lu[i][k][w]; //更新路径
}
for(w=2;w<wei[k][j];w++)
{
lu[i][j][wei[i][k]+w-2]=lu[k][j][w];
}
wei[i][j]=wei[i][k]+wei[k][j]-2;
}
}
}
}
}
void print(int m)
{
int i;
int x,y;
scanf("%d",&m);
int temp1[maxnum];
int temp2[maxnum];
for(i = 0;i < m;i++)
{
scanf("%d %d",&temp1[i],&temp2[i]);
}
for(i = 0;i < m;i++)
{
for(int j=1;j<maxnum;j++)
{
if(lu[temp1[i]][temp2[i]][j]!=temp2[i])
printf("%d\n",lu[temp1[i]][temp2[i]][j]);
else
{
printf("%d\n",lu[temp1[i]][temp2[i]][j]);
break;
}
}
}
}
int main()
{
int n,m;
scanf("%d",&n);
int i, j;
luchu(n);
floyd(n);
print(m);
return 0;
}有问题可以私信我















 1304
1304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









