






1. 编写程序
列出c:/windows下的所有exe文件和dll文件,使用列表推导
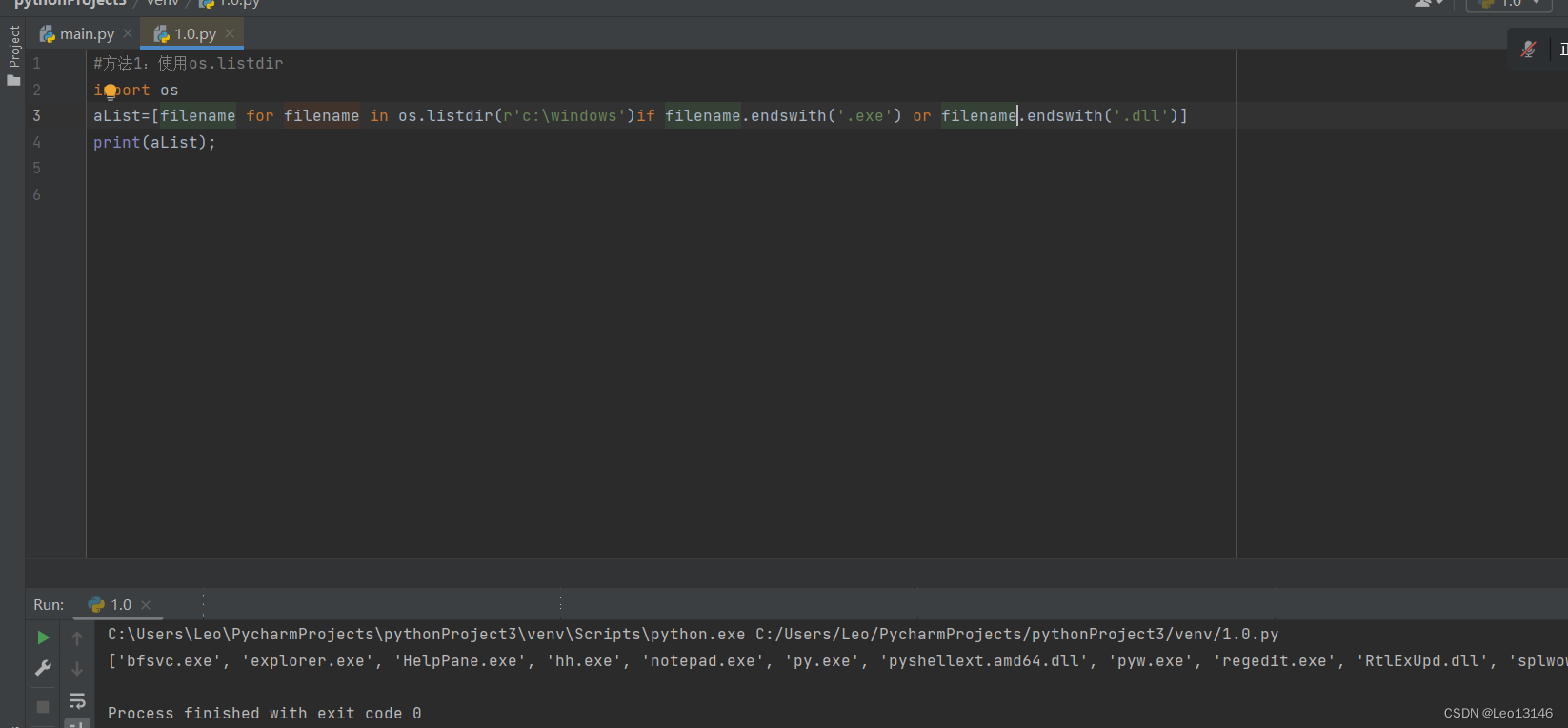
#方法:使用os.listdir
import os
aList=[filename for filename in os.listdir(r'c:\windows')if filename.endswith('.exe') or filename.endswith('.dll')]
print(aList);
2. 编写程序,列出1900年到今年以来,所有的闰年,使用列表推导
years=[ year for year in range(1900,2022) if year%4==0 and year%100!=0 or year%400==0] print (years)
3. 使用元祖的序列解包交换2个变量的值
x, y = 1, 2
print('x='+str(x)+' y='+str(y))
x, y = y, x
print('x='+str(x)+' y='+str(y))
4. 读取一个文本文件cnnnews.txt
f = open('e:/cnnnews.txt')
text = f.read()
f = open(r'/C/cnnews.txt')
text = f.read()
f.close()
5. 使用字典统计每个单词出现次数
str = "I love python I love python I love python I love python I love python I love python I love python"
word = input("输入要统计的单词,回车结束\n") #输入字符串以外的单词会报错,因为下面字典中只把字符串中存在的单词作为key
list = str.split(" ") #以空格为分隔符,把字符串分割成单词列表
dict = {} #创建一个空字典
for key in list: #把list中的单词,作为字典中的key(在字典中key是唯一的),把遍历到key的次数,作为value;
if dict.get(key) == None: #在字典中查找key,因为创建的是空字典,每个key第一次get结果都是None
dict[key] = 1 #(key来自list,绝对是字符串中的单词)第一次遍历到key的时候,get结果是None,在空字典中创建该key的键值对,key:1;在后续的遍历过程中,如果再次遍历到这个key,get结果不是None了
else:
dict[key] += 1 #遍历到某个key,已经在字典里存在了,就把次数+1
print(dict[word]) #返回要统计的单词出现次数
6. 如果不要区分大小写如何做?
提示:可以用字符串的函数 s.lower()来转换小写
l_str=[key.lower() for key in str]
7. 如果不想统计标点符号,如何实现
for i in str:
if i in string.punctuation:
str.remove(i)
8. IEEE和TIOBE是两大热门编程语言排行榜。IEEE榜排名前五的语言是:Python、C++、C、Java和C#。TIOBE榜排名前五的语言分别是:Java、C、Python、C++和VB.NET。请编程:
1)、上榜的所有语言
2)、两个榜单中同时出现的语言
3)、只在IEEE榜中出现的语言
4)、只在一个榜中出现的语言
IEEE = {'Python', 'C++', 'C', 'Java', 'C#'}
TIOBE = {'Java', 'C', 'Python', 'C++', 'VB.NET'}
print(f'上榜的所有语言{IEEE | TIOBE}')
print(f'两个榜单同时出现的语言{IEEE & TIOBE}')
print(f'只在IEEE中出现的语言{IEEE - TIOBE}')
print(f'只在一个榜中出现的语言{IEEE ^ TIOBE}')
9. 生成100个1至1000之间的随机数,要求这些随机数不重复,使用set来完成
nums=set()
while len(nums)!=100:
nums.add(random.randint(1, 1000))
print(nums)















 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









