







MySQL中我们经常会提起如下几个日志:
- binglog
- redo log
- undo log
那么这几个log分别有什么作用呢 ?
binlog
首先来说binlog,binlog是MySQL数据库级别的日志,不是单独针对某个数据库引擎,而是针对所有引擎,其主要作用是:
- 用来主从复制
- 崩溃异常恢复
binlog中记录的主要是逻辑日志、数据更新相关,select相关不会记录。binlog相关配置参数如下:
- max_binlog_size 单个binglog文件的最大值,默认1G
- binlog_cache_size 所有未提交的binglog日志会记录到缓存中,该参数控制该缓存大小,基于会话的,每个会话会分配一个binglog_cache_size大小的缓存,默认32K,不能设置过大也不能过小,如果一个事务的binlog日志超过该参数,会记录到给临时文件中,可以通过查看
binlog_cache_use使用缓存次数,binlog_cache_disk_use使用临时文件次数,来查看


- sync_binlog binlog同步到磁盘策略,N 表示每写多少次缓存就同步到磁盘,
0表示由OS系统决定何时刷盘,1表示每次事务提交都同步到磁盘,N表示每N个事务同步到磁盘,如果使用InnnoDB,对事务要求高的化,建议设置为 1 ,默认为1
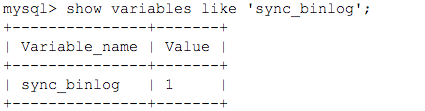
- binlog_do_db , binlog_ignore_db ,表示哪些库需要写binglog,哪些库可以忽略
- log_slave_updates 用来控制slave节点是否需要写入master节点的binlog,如果只是简单主从复制,那么slave节点不用开启,但是如果是级联复制, MASTER => SLAVE => SLAVE,则第一个SLAVE节点该参数必须开启
- binglog_format binglog日志格式,主要有STATEMENT,ROW,MIXED,其中
STATEMENT记录的是逻辑SQL语句,但是如果语句中有一些函数,如uuid,则会导致主从不一致,ROW记录的是行数据的更改记录,MIXED则是前两者的结合,在MIXED格式下,默认用的是STATEMENT,但是遇到相关函数,用户自定义函数,临时表,INSERT DELAY语句
redo log
我们知道,在MySQL中(innodb),一般如果我们更新记录,都是在buffer pool中进行更新的,而不是每次更新都直接写磁盘的,如果每次更新都写磁盘,那么磁盘IO会带来性能的急剧下降,但是缓存是易失的,如果OS Crash了,那么这部分的数据就永远也找不到了,针对这个问题,现在主流的数据库都在用了WAL机制(Write Ahead Log),先写日志在更改记录,这样的话即使OS Crash了,但是wal日志中持久化了相关的更改能够进行数据的恢复,MySQL中redo log 可以理解为 wal。
redo log包含两部分,一个是日志缓冲redo log buffer,另外一个是磁盘日志文件redo log file。
MySQL中更新一条记录时,首先会在缓存中查找该记录如果没有会从磁盘读取到缓存中,然后将更新的记录写到redo log中并更新缓存中的数据,然后返回成功,这个时候数据已经更新成功了,并且实现了持久化,至于磁盘数据文件中数据更新,则是依赖后面提到的checkpoint技术更新数据。
为什么要引入redo log 呢,每次更新直接写磁盘文件不就能实现持久化了吗 ?理论上是这样的,但是需要考虑到的是,每次更新都写磁盘数据文件的话,由于MySQL数据存储是基于页的,每次读取的数据是按照页读取的,不是只读取所需的记录而且读取了其他记录,这样如果每次更新都写磁盘的话,这个写是随机写的,性能急剧下降,同时同一个页中的数据如果有其他事务,还会有并发问题,MySQL在Buffer Pool中更新数据,并通过redo log来实现持久化,写redo log是顺序写的,比随机写性能高。
redo log首先是被记录在redo log buffer中的,然后按照一定的策略同步到磁盘中的,由innodb_flush_log_at_trx_commit参数控制,其策略如下:
0 事务commit的时候,只把redo log写入了redo log buffer中并没有写入到OS buffer,由master thread写入到OS buffer并调用fsync()同步到磁盘,而master thread每秒会进行一次redo log buffer同步到磁盘的操作,即每秒同步到磁盘一次,这时候数据库服务停止或者系统宕机都会丢失上一秒的所有数据1 事务commit的时候调用fsync()同步到磁盘,默认配置,这种情况即使OS Crash也不会丢失数据,但是每次提交都会有IO,有性能损耗2 事务commit的写入到redo log file,不是直接同步到磁盘,而是写入到OS buffer,然后每秒调用一次磁盘同步fsync(),这样如果这是数据库服务停止,那么重启数据库服务,不会丢失数据,但是如果系统宕机则会丢失上一秒的所有数据
MySQL中写redo log是通过两次提交来写入的:
- innoDB更新缓存中的数据,然后记录redo log并并标记为prepare状态
- 记录binlog
- innoDB更改redo log中的状态为commit
这样我们结合redo log和binlog能够在OS Crash之后恢复数据,具体逻辑如下:
- 如果redolog中为prepare状态并且binglog也写入,这时候通过XID能够关联redo log和binlog中的记录,这时候这条记录认为是已经更新成功的,重启后会恢复这条数据
- 如果redo log为prepare状态但是binglog没有没写入,即通过XID在binlog中找不到对应的记录,则认为这条记录没有写入成功,不会恢复
redo log是innoDB数据库特有,而binlog则是MySQL数据库所有库都有的,如果说没有需要开启binlog的需求(如主从复制、数据备份恢复),那么只需要redo log就可以了,但是如果开启了binlog,不采用上述逻辑的话,可能会导致redo log和binlog不一致,这样有可能导致主从不一致
------------------------------------------------------------------------------------------
如果需要对于数据事务要求比较高,则建议开启:innodb_flush_log_at_trx_commit=1 ;sync_binlog=1
redo log中的数据是基于log block块进行写入的,我们知道MySQL中的数据是基于页page来存储和读取的,log block的大小是512字节,和磁盘扇区大小一样,写入的时候可以保证原子性,不需要double-write
redo log是循环写入的,比如配置两个redo log file,先写redo-logfile1,写满了然后写redologfile2,如果都满了无法写入的时候会进行checkpoint,然后接着写redologfile1循环。
redo log相关配置参数:
- innodb_flush_log_at_trx_commit 同步磁盘策略,重要参数
- innodb_log_file_size 单个redo log文件大小,这个参数不能设置太小,太小的话会导致频繁checkpoint,频繁同步磁盘,太大的话会导致恢复的时间长,一般建议1GB
- innodb_log_files_in_group redo log日志文件个数,一般建议3个或者4个
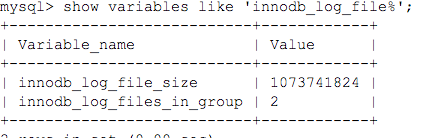
- innodb_log_group_home_dir redo log file存放在哪个文件夹目录下,默认是
./即当前data目录下 - innodb_log_buffer_size 写redo log文件时候使用缓冲池大小,默认为16MB,可以适当调大该值
undo log
undo log也就是大家常说的回滚日志,undo log中记录的是逻辑日志(如果回滚的话,基于页的话会影响其他事务),undo log主要作用是两个:
- 回滚数据
- MVCC实现
undo log的产生也会伴随着redo log,因为undo log也需要持久性的保护。一般undo log分为两类:
- insert undo log
- update undo log
undo log采用的是段管理的方式,存放在数据库内部中一个特殊的段中(undo segement),InnoDB中对undo同样采取的是段管理方式,rollback segement,每个回滚段中记录了1024个undo log segment,在每个undo log segment中进行页的申请,通过innodb_undo_logs来设置rollback segement数量,默认情况下是128,故可同时支持在线事务数量为128*1024。
默认情况下rollback segement都写入一个文件中innodb_undo_tablespaces来设置平均分配到多少个文件中,默认值为0
undo log相关配置:
- innodb_max_undo_log_size undo log文件最大大小,默认为1G,如果设置
innodb_undo_log_truncate=ON,则会达到最大大小限制的时候,触发回收 - innodb_undo_directory
指定undo log所在文件目录,生产环境建议配置单独的磁盘 - innodb_undo_log_truncate 是否开启undo log回收
- innodb_undo_logs undo log rollback segment个数,与
innodb_rollback_segments含义一致,后续可能会弃用,建议使用innodb_rollback_segments配置,默认为128,也就是最大的配置,建议>=35,因为32个给临时表空间使用,1个给系统表空间使用,2个独立的表空间用来回收,这时候还剩余128-33=95个rollback segment,这就是innodb_undo_tablespaces最多可以配置95个 - innodb_undo_tablespaces undolog表空间文件个数,最多可以配置为95个
- innodb_purge_rseg_truncate_frequency 后台purge线程执行多少次之后才真正释放rollback segment回滚段操作
独立undo log能够降低磁盘的IO竞争,建议生产环境单独磁盘配置undo log
[mysqld]
# undolog回滚表空间的配置
innodb_max_undo_log_size = 1G
innodb_undo_directory = /data1/mysql/undolog
innodb_undo_log_truncate = ON
innodb_undo_logs = 128
innodb_undo_tablespaces = 8
innodb_purge_rseg_truncate_frequency = 128
LSN
LSN是log sequence number的简写,innodb引擎中LSN占用8个字节,LSN会随着数据的写入逐渐增长,我们通过LSN可以获取到几个信息:
- 数据页的版本信息
- 写入的日志总量,通过LSN的开始号码和结束号码,能够推算出写入的日志量
- 可以知道checkpoint的位置
LSN不仅存在于redo log中,还存在于数据页中,每个数据页的头部都有一个fil_page_lsn,记录了该页的LSN,当我们的数据进行checkpoint之后,内存中的页更新到磁盘上之后,file_page_lsn则会更新为checkpint对应的LSN,如果重启恢复的时候,发现redo log中ye的LSN和磁盘上对应LSN不一致的话,如果磁盘上页的LSN比redo log中页的LSN小的话,表明重启前数据有更新,但是未写入到磁盘数据页中,这样的话,我们在恢复的时候不用将redo log中所有的数据都进行恢复,只要通过LSN就能够判断哪些数据需要恢复。
Chcekpoint
MySQL中所谓的Checkpoint机制指的是将缓存中更新的页即所谓的脏页数据同步到磁盘上,其主要解决的如下几个问题:
- 缩短数据库的恢复时间,checkpoint之后,在恢复的时候不是恢复所有的redo log而是从Checkpoint之后的地方开始恢复
- 缓冲池不够用时,将脏页刷新到磁盘
- 重做日志不可用时,刷新脏页到磁盘
在InnoDB中,有两种Chcekpoint:
Sharp Checkpoint在数据库关闭的时候将所有的脏页都刷新到磁盘,默认innodb_fast_shutdown=1Fuzzy Checkpoint刷新一部分脏页而不是将所有的脏页都刷新到磁盘,如果在``数据库运行的时候也使用也使用Sharp Checkpoint,那么数据库的可用性将受到极大的影响,因此在数据库运行的时候采用Fuzzy Checkpoint来进行脏页的刷新
Fuzzy Checkpoint在如下几种情况将发生
- Master Thread Checkpoint,master线程每秒或每10秒按照一定的比例从缓冲池的脏页列表中选取数据刷新到磁盘中
- FLUSH_LRU_LIST Checkpoint InndoDB中需要保证LRU有空闲页可以使用,通过Page cleaner线程来保证LRU列表的可用,通过
innodb_page_cleaners控制page cleaner的个数,inndodb_lru_scan_depth来设置LRU列表可用空闲页的个数 - async/sync Flush Checkpoint 这里指的是redo log不可用的情况下,需要强制将一些脏页刷新同步到磁盘
- dirty page too much Checkpoint 脏页数量太多,需要强制将一部分脏页刷新到磁盘,保证有足够的缓存空间。
在redo log中,通过LSN和Checkpoint,我们每次在重启恢复的时候,只需要恢复Checkpoint LSN和redo log LSN之间的数据即可。
















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









