






先说结论:
查询百万数据并导出,游标查询效率 远大于 分页查询,游标查询总耗时5s,分页查询102s,加上实际导出时间,游标查询并导出耗时16s,分页查询导出耗时118s,下方第4点记录了使用时的一些异常
环境说明:
SpringBoot版本: 2.7.10
ORM框架:MyBatis
数据库:mysql 5.7
数据导出:EasyExcel
1. 创建表
CREATE TABLE `t_user_test` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`user_name` varchar(30) NOT NULL COMMENT '姓名',
`age` int(3) NULL DEFAULT NULL COMMENT '年龄',
`address` varchar(50) NULL DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='用户测试表';
2.造数据,循环插入100w条数据
-- 创建存储过程
DELIMITER //
CREATE PROCEDURE insert_multiple_rows()
BEGIN
DECLARE i INT DEFAULT 1;
-- 循环插入100w条数据
WHILE i <= 1000000 DO
INSERT INTO t_user_test (user_name, age, address) VALUES (CONCAT('user_name_', i), FLOOR(RAND() * 100), CONCAT('address_', i));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- 调用存储过程
CALL insert_multiple_rows();
我本地执行完花了大概800多秒…这800多秒,先执行下面的操作吧!!!
3. 代码实现
3.1 数据库连接配置,必须在jdbc url上设置连接属性参数useCursorFetch=true
jdbc:mysql://localhost:3306/gooluke-admin?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useAffectedRows=true&useCursorFetch=true&serverTimezone=UTC
3.2 dao接口
/**
* 分页查询
*/
List<TUserTest> selectListByP(@Param("startIndex") int startIndex, @Param("pageSize") int pageSize);
/**
* 游标查询
*/
@Options(fetchSize = 300)
Cursor<TUserTest> selectListByCursor();
3.3 xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gooluke.admin.integration.dao.UserTestDAO">
<resultMap id="BaseResultMap" type="com.gooluke.admin.entity.TUserTest">
<result column="id" jdbcType="INTEGER" property="id"/>
<result column="user_name" jdbcType="VARCHAR" property="userName"/>
<result column="age" jdbcType="VARCHAR" property="age"/>
<result column="address" jdbcType="VARCHAR" property="address"/>
</resultMap>
<select id="selectListByP" resultMap="BaseResultMap">
select * from t_user_test limit #{startIndex}, #{pageSize}
</select>
<select id="selectListByCursor" resultMap="BaseResultMap">
select * from t_user_test
</select>
</mapper>
3.4 实体类忽略
3.3 查询接口
package com.gooluke.admin.service.impl;
import com.gooluke.admin.entity.TUserTest;
import com.gooluke.admin.integration.dao.UserTestDAO;
import com.gooluke.admin.service.DataService;
import io.github.hthbryant.gooluke.framework.biz.common.dto.BaseResponseDTO;
import io.github.hthbryant.gooluke.framework.biz.common.enums.ErrorStatus;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.cursor.Cursor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author gooluke
*/
@Service
@Slf4j
public class DataServiceImpl implements DataService {
@Autowired
private UserTestDAO userTestDAO;
@Override
public BaseResponseDTO exportByPage() {
AtomicInteger count = new AtomicInteger(0);
//这里因为知道数据就是要查100w条,所以简单实现下分页,没有查总条数,如果还要查总条数并返回,效率更差了
int currentPage = 1;
int pageSize = 1000;
long startTime = System.currentTimeMillis();
while (currentPage <= 1000) {
int startIndex = (currentPage - 1) * pageSize;
long start = System.currentTimeMillis();
List<TUserTest> userInfos = userTestDAO.selectListByP(startIndex, pageSize);
log.info("第{}页查询耗时为:{} ms", currentPage, (System.currentTimeMillis() - start));
for (TUserTest userInfo : userInfos) {
count.addAndGet(1);
}
//写excel
currentPage++;
}
log.info("处理数据量为:{}", count);
log.info("分页查询总处理耗时为:{} s", (System.currentTimeMillis() - startTime) / 1000);
return new BaseResponseDTO();
}
@Override
@Transactional
public BaseResponseDTO exportByCursor() {
AtomicInteger count = new AtomicInteger(0);
long startTime = System.currentTimeMillis();
Cursor<TUserTest> cursor = userTestDAO.selectListByCursor();
try {
Iterator<TUserTest> iterator = cursor.iterator();
while (iterator.hasNext()) {
TUserTest userInfo = iterator.next();
count.addAndGet(1);
//写excel
}
} catch (Exception e) {
log.error("游标查询异常,", e);
return new BaseResponseDTO(ErrorStatus.SYSTEM_ERROR);
} finally {
if (cursor != null) {
try {
cursor.close();
} catch (IOException e) {
log.error("游标关闭失败");
}
}
}
log.info("游标查询总处理数据量:{}", count);
log.info("游标查询总处理耗时:{} ms", (System.currentTimeMillis() - startTime));
return new BaseResponseDTO();
}
}
调了接口之后发现光是查询效率就有20倍!!!
分页查询总耗时102s,第一页的时候查询耗时20ms左右,干到第999页的时候已经要202ms了
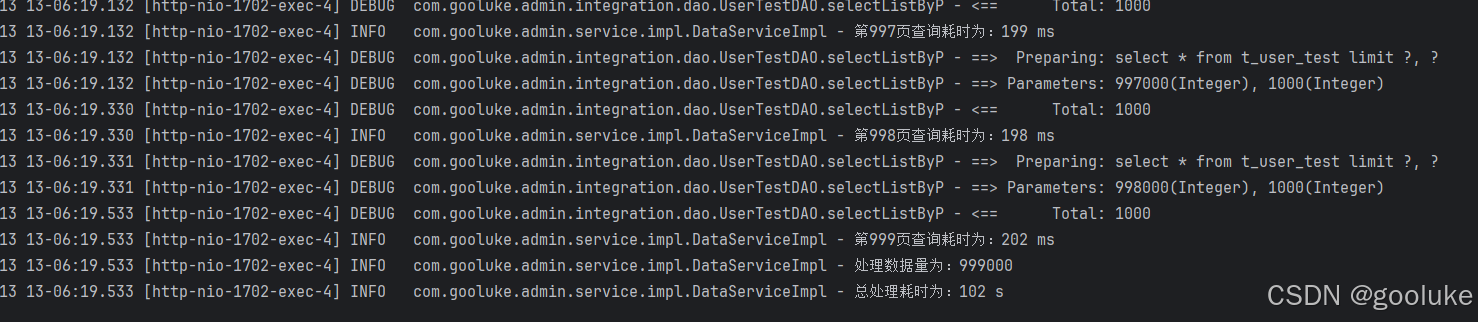
游标查询总耗时5s

3.4 数据导出,EasyExcel
如果没有使用过EasyExcel的可以参考EasyExcel官网:https://easyexcel.opensource.alibaba.com/
定义数据导出对象
package com.gooluke.admin.excel.exportdata;
import com.alibaba.excel.annotation.ExcelProperty;
import lombok.Data;
@Data
public class UserTestListExcelData {
@ExcelProperty(value = "id", index = 0)
private Integer id;
@ExcelProperty(value = "姓名", index = 1)
private String userName;
@ExcelProperty(value = "年龄", index = 2)
private Integer age;
@ExcelProperty(value = "电话号码", index = 3)
private String address;
}
代码调整:因为上述只做了查询,没有导出逻辑
我们定义了一个导出对象,所以我们把查询结果直接用这个对象接收,省去了转换带来的性能影响
dao层:
/**
* 分页查询
*/
List<UserTestListExcelData> selectListByP(@Param("startIndex") int startIndex, @Param("pageSize") int pageSize);
/**
* 游标查询
*/
@Options(fetchSize = 300)
Cursor<UserTestListExcelData> selectListByCursor();
xml
<select id="selectListByP" resultType="com.gooluke.admin.excel.exportdata.UserTestListExcelData">
select
id,
user_name as userName,
age,
address
from t_user_test limit #{startIndex}, #{pageSize}
</select>
<select id="selectListByCursor" resultType="com.gooluke.admin.excel.exportdata.UserTestListExcelData">
select
id,
user_name as userName,
age,
address
from t_user_test
</select>
service
@Value("${file.excel.path}")
private String filePath;
@Autowired
private UserTestDAO userTestDAO;
@Override
public BaseResponseDTO exportByPage() {
String time = new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new Date());
String fileName = filePath + "分页查询导出百万数据_" + time + ".xlsx";
ExcelWriter excelWriter = EasyExcel.write(fileName, UserTestListExcelData.class).build();
WriteSheet writeSheet = EasyExcel.writerSheet("分页查询导出").build();
AtomicInteger count = new AtomicInteger(0);
int currentPage = 1;
int pageSize = 1000;
long startTime = System.currentTimeMillis();
while (currentPage <= 1000) {
int startIndex = (currentPage - 1) * pageSize;
long start = System.currentTimeMillis();
List<UserTestListExcelData> userInfos = userTestDAO.selectListByP(startIndex, pageSize);
log.info("第{}页查询耗时为:{} ms", currentPage, (System.currentTimeMillis() - start));
count.addAndGet(userInfos.size());
excelWriter.write(userInfos, writeSheet);
currentPage++;
}
excelWriter.finish();
log.info("处理数据量为:{}", count);
log.info("数据写入完成:{}", fileName);
log.info("分页查询总处理耗时为:{} s", (System.currentTimeMillis() - startTime) / 1000);
return new BaseResponseDTO();
}
@Override
@Transactional
public BaseResponseDTO exportByCursor() {
String time = new SimpleDateFormat("yyyyMMddHHmmssSSS").format(new Date());
String fileName = filePath + "游标查询导出百万数据_" + time + ".xlsx";
ExcelWriter excelWriter = EasyExcel.write(fileName, UserTestListExcelData.class).build();
WriteSheet writeSheet = EasyExcel.writerSheet("游标查询导出").build();
AtomicInteger count = new AtomicInteger(0);
long startTime = System.currentTimeMillis();
Cursor<UserTestListExcelData> cursor = userTestDAO.selectListByCursor();
ArrayList<UserTestListExcelData> writeList = new ArrayList<>();
try {
for (UserTestListExcelData userInfo : cursor) {
writeList.add(userInfo);
if (writeList.size() == 1000) {
excelWriter.write(writeList, writeSheet);
writeList.clear();
}
count.addAndGet(1);
}
if (!writeList.isEmpty()) {
excelWriter.write(writeList,writeSheet);
writeList.clear();
}
excelWriter.finish();
log.info("数据写入完成:{}", fileName);
} catch (Exception e) {
log.error("游标查询异常,", e);
return new BaseResponseDTO(ErrorStatus.SYSTEM_ERROR);
} finally {
if (cursor != null) {
try {
cursor.close();
} catch (IOException e) {
log.error("游标关闭失败");
}
}
}
log.info("游标查询总处理数据量:{}", count);
log.info("游标查询总处理耗时:{} ms", (System.currentTimeMillis() - startTime));
return new BaseResponseDTO();
}
导出耗时结果对比: 游标>>分页查询
分页查询花了118s
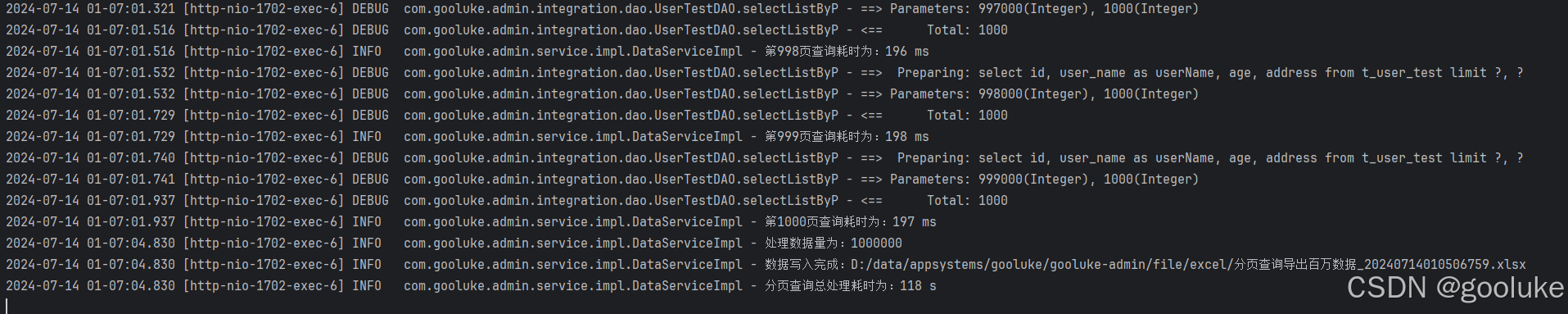
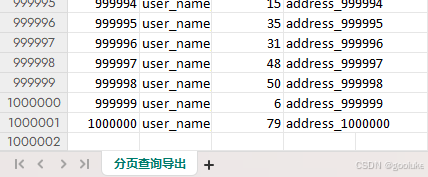
游标查询花了16s

4. 异常记录
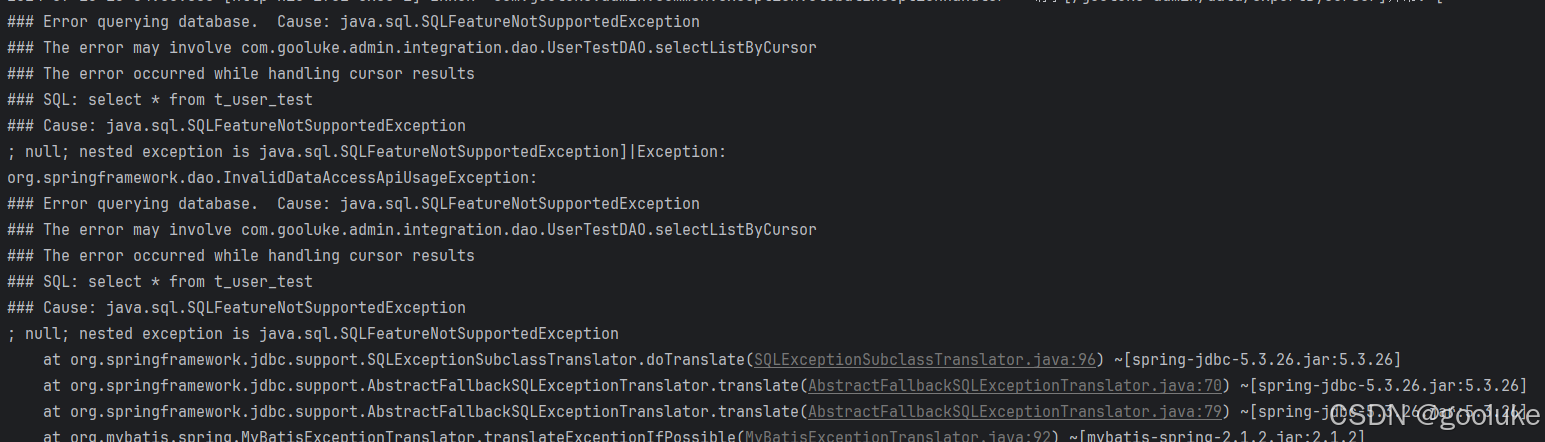
4.1 Cause: java.sql.SQLFeatureNotSupportedException
这里我报错的原因是我用的是druid数据源,druid包的版本太低了,之前是’com.alibaba:druid:1.1.12’,后来升到1.2.20就可以了
参考链接:https://blog.csdn.net/m0_56070893/article/details/136257787
4.2 java.lang.IllegalStateException:A Cursor is already closed.
这里报错的原因是方法上没有加事务注解@Transactional,加上即可


















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









