其实range分区你学会了,其他的分区你也学会了,在这我就不敲了,咱们简单来看一下,hash分区,hash分区实现
负载均衡,平均分配值进行分区,那这个哈希就是平均分配的,也是一张表,还是partition by,只不过是变成hash了,然后根据咱们的
分区字段,然后进行p1和p2,这回就直接写p1,p2,p3,p4,但是我先做没有去指定范围,但是这个数据就会平均分布,然后他也是照样可以
去添加分区,这都是可以的,只不过是平均分布,然后类似于这种方式,看一下,用hash分区,平均分,就是p1这个里面5条数据,你如果插
10条数据,p1里面5条,p2里面5条,就是这个意思,这个很简单

还有一种是list分区,它是按照区域去划分的

比如说create一个table,partition by list分区,按照城市去分区,给partition取个名字,east,west,按照这种去分,
比如这是tianjin,这是dalian,按照天津和大连去分,按照字段值区分,east这只是一个名字,跟其他的没关系,然后现在是按照city
这个值去分的,我们可能会往这个表里灌数据,灌一千头,一万条,你要是tianjin的,数据进来一条tianjin的,或者是dalian的,
我就把数据放到east,这个只是一个分区的名字,你如果要是xian的,我就放到west里边,你要是上海呢,我就放到south里边,
你要是herbin,我就放到north这个区间里,others就放到other里,这个就是按照一个字段的不同表现形式,然后阈值去划分的,
他其实和range有点像,只不过是一种更好的分区的手段吧,可能我insert了5条记录了以后,我查一下分区,那你看我insert了
5条记录了,那我就查一下east,east就是tianjin,dalian,相当于把所有天津和大连的,这个数据查出来了,如果你查这条SQL的话
select * from personcity partition(east);查出来就有这个效果,这个是list分区
然后就是复合分区

其实部门分区怎么说呢,因为我是不怎么去建list分区,它是把范围分区和散列分区进行相结合,两种分区结合起来
做这个划分,范围分区和散列分区相结合,都是可以的,就是范围分区range,range和hash组合,这边是range分区,这边是hash分区
进行一个组合,或者是范围分区和列表分区list分区,他们两个之间也可以做一个组合,有各种各样的组合,然后这块你看我怎么做的
我这里正常来讲是一个table,建立一个range分区,在最外层建一个range分区,按照这个number,就是最外层按照一个Number做一个
range分区,然后里边有一个subpartition子分区,分区里面再套一个分区,按照这个hash,再给我平均分区,按照这个sname,我可以走
两个字段,去做分区,比如number等于1的,这个可能不是主键,随便举个列子,number等于1的有好几条记录,number等于1的可能有10条
记录吧,这10条记录都可以放到一个空间里了,number等于2的呢,这里也有10条,然后number等于1或者number等于2,在最开始的range
分区的基础之上,我在这个分区里面还可以分成4份,hash subpartition 4,好像不是这么说的,再往下看,是这样的,就是这4份是平均
的,接下来我看range是怎么去划分range的,range我分成是这样的,如果ID号小于1000,0到1000这些数据,放到外层的一个分区,然后
1000到2000放到最外层的分区,他这里有点别扭,语法就是这样的,没办法,我再描述一下,就是一开始,先看这个,
partition by range(sno),一个range分区,把数据切分成了三份,第一份是0到1000,第二份是1000到2000,第三份是2000以上,
2000加,大体上分了三个区间,然后我又做什么事了,其实这块我们再看一下,subpartition by hash(sname) subpartition 4,
一个区间按照name去分区,分成4份,其实是这样的,4小格吗,按照name哈希分区,应该是平均分配的,这个是关于复合分区,范围分区
和list分区怎么去整合,你这块就不是平均了,就是按照list去分区,都可以去做组合的,list里面指定太麻烦了,有没有什么快速
的方法来指定,这个就没有了,list其实怎么说呢,比如说省份,一共就那几个省份,你采用list分区,就是按照不同的业务去划分
不同的分区,分区也不是说非得选哪一种,按照真实的业务你自己去选择,刚才这块没问题吧

接下来我们看一下间隔分区,其实工作中正常来讲,间隔分区是用的比较多的,一般我也是会用到间隔分区,其实很多
数据结构我都会用到间隔分区,间隔维度主要是可以按照时间维度去进行分区,这是我最喜欢的事情,它是11g以后才出来的
新特性,在实际工作中也是非常常用的,Interval分区,Interval Partition,这也是ORACLE一项非常引以为荣的技术,可以动态的
去指定分区,让高效的海量处理数据成为可能,他其实是range分区的一个延展,一个扩充,最终实现了range分区的一个自动化,咱们
同学想一想,range分区你得手写上P1,P2,P3,...,不够了还得alter table,add partition,那现在这种间隔的分区,可以写好了函数
以后,他自己可以去进行分区,咱们可以看一下,create table,table名字叫做interval_sale,这个东西可以直接运行的,在这里咱们
说range,range的一个升级版吧,叫做interval分区,它是可以去实现一个自动化分区

现在这个语句已经写好了,首先create一个table叫做interval_sale,然后指定两个字段,一个sid,和sdate,你注意看
我们这里又一个date,他是一个timestamp类型的,有一个时间戳,然后我现在进行partition的时候,sdate时间进行
分区,然后下面有一个函数,这个函数的目的就是,这个函数就是ORACLE里面的函数了,举个例子,这个函数的最终执行
结果呢,其实就是月份,SELECT numtominterval(1,'MONTH') FROM DUAL;

是按照0到01这个月份,做一个分区的,他自己回去累加的,举个例子吧,你只要放一个分区的起始点即可,
先DROP掉已经存在的,我要建的range分区,其实我在以前就建立过一遍了,就是这张表,interval_sale,这张表,包括这种
分区模式,在我们上课之前已经建立过一遍了,听好我要问的问题,刚才我把那张表给drop掉了,那现在请问,我要做这个事情,
SELECT * FROM user_tab_partition,那我问你,之前建立的interval分区,还存在吗,能理解我说的意思吗,N多年以前,已经建立
range分区这种表了,但是我刚才把他drop掉了,drop掉之后,range分区还存在吗,我已经把表都删了,那分区还存在吗,问你一下,
能理解我说的意思吧,咱们看一下,看见了吧,可能你看不出来

这个东西已经变样了,但是这个东西还是存在的,flashback,闪回咋写的,我有点忘了,我记得在同义词里面有,
flashback table 表名 to before drop;我要把这张表还原回来,然后to before drop,能理解我的意思吧,flashback
哪张表啊,其实之前我建了interval_sale,然后to before drop,我要做这个事情,flashback table interval_sale
to before drop,我要做这个事情,然后我又回来了

然后去查询,看到了吧,那你告诉我,分区之后,他到底存不存在啊,是不是还是存在的,能理解我说的意思吧,因为
什么啊,因为ORACLE里面有好多闪回机制,你把表drop了以后,我物理的分区其实还是一直存在的,如果你做什么事啊,
除非你purge recyclebin

我现在继续drop掉,drop掉之后呢,他的名字就变了个样了
你这个表不存在了,就放到recyclebin里面了,垃圾箱里了,这个bin,这里面生成一堆啥东西我也不知道,总之它是通过这个
能够让你在purge之前,purge recyclebin;在purge recyclebin的时候,我一执行,执行完之后我再去查询,我只能把垃圾箱的数据
全部down了之后,我这个分区才会物理的删除,能理解我说的意思吧,有人的说ORACLE提供了很强大的机制,以前用SQLServer,老的
版本,老的MSYQL的时候,经常SELECT * FROM,DELETE FROM 什么的,把你的数据全干掉了,或者误操作把表删掉了,那没关系,ORACLE
里面会有一些数据恢复的机制,包括很多种吧

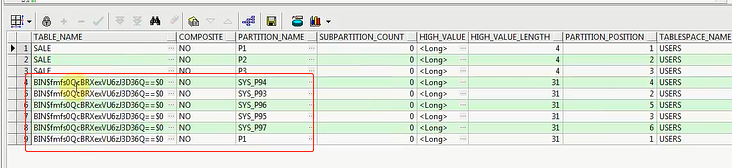
你看这个SALE,就是我们刚才做的例子,我把它干掉,我们最开始建立的不是一个SALE,这个SALE应该是
range分区,我把这个drop掉,drop掉之后呢,我就一查,我就查这个

是不是一样的,然后我还可以把SALE这张表给flashback回来,然后我还可以去查到这个SALE,都是一样的
只要你删除不recyclebin,都是没问题的

都是可以flashback回来的,其实这个东西我不想讲,看到之前有张表,同时提一下,咱们再回到这块,回到interval
这块,我们刚才说了,这个东西是逐月递增的,或者是按照其他的东西,按照年也可以,计算的话按照天也可以,这是一个
函数,你可以看一下,这个东西一堆一堆的,计算日期函数,如果不明白的话,在这我只能告诉你,你要百度,你要自己课下
去学习,说这个东西到底什么意思啊,他有tomonth,tomin,很多,很多区间去划分的函数,所以说呢咱们在这按月份去说吧,
那我先做看这一个,就是interval分区你只要指定一个起始值就可以了,那我这个起始值是多少呢,是2014年2月1号,
也就说什么意思呢,2014年2月1号之前所有的数据,给我划分成一个区间叫P1,从2014年2月1号以后,每隔一个月,给我
建立一个分区,每隔一个月给我建立一个分区,他就是这种机制,咱们直接把这个create出来,create出来之后咱们看一下
看一下这个partitions,当前interval_sale这张表里,肯这是没问题的,现在是没任何分区的,动态分区
你看不出来

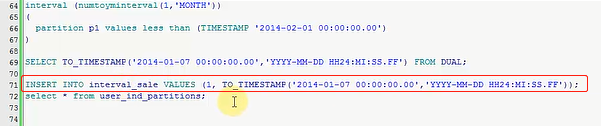
咱们去insert几条记录,INTERT INTO咱们的这几张表,然后VALUES什么啊,values咱们的id,这里要传一个timestamp类型的
比如咱们来一个字符串吧,这样去写行吗,先看看,我这里面是不是要用函数转换啊,我现在写一个1月,比如说1月7号吧,
这个时间不行吧,这个月份应该怎么去转换啊,应该有一个函数,来看一下,SELECT * FROM DUAL,这个函数的转换应该是
TO_TIMESTAMP,我就按照刚才的那个值,他有一个模板,我也记不住,咱们找一下,就他了,24小时的,就是时间转换函数,
之前我们也说了

可以把这个东西直接copy过来,行不行呢,插入成功
咱们这回去做这个事情,先不要着急看他,先看这个,SELECT * FROM 咱们的interval,
这里是有一条数据的,因为我刚才插入了一条数据

但是你注意,我插入的是1月7号,咱们先查一下,这啥意思

怎么会是这样呢,我刷新一下,SALE,好像出现了一个小问题,我再查一下,我刚才是指定了一个间隔分区,我再加入
几条记录,难道不能够这么去插入吗,比如我加2号和3号,这块我变成2月份,比如变成2月5号,比如这是3月份,3月6号,
之前这条数据已经加完了,就是1月7号的我先insert,成功
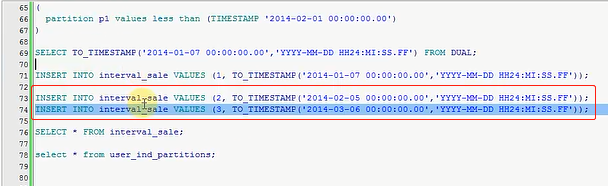
成功以后再去看这条记录,去看这张表,这张表是有3条数据的

咱们看partition,可能是不存在这里的

这是index,sorry,难怪会出现这个问题呢,这是index,咱们应该查tab_partition,SELECT * FROM user_tab_partition
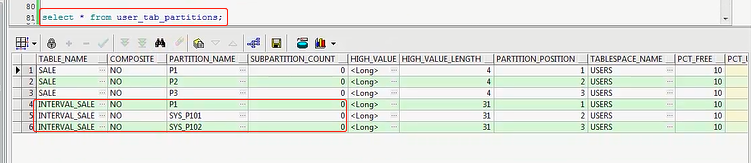
已经出来了,我之前interval,现在已经有了,咱们再查一下吧
SELECT * FROM interval_sale PARTITION(P1);

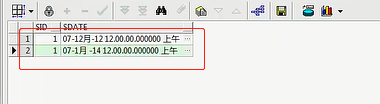
P1里头有一条数据,这是之前咱们插入的1月7号,1月7号以前的都是属于P1分区的,比如我再插入一个,比如我插入一个
更小的值,你刚才不是说2014年吗,我再来一个2012年,12年12月7号,提交

我再次去查这个P1,你就会发现两天条记录
这个东西就相当于什么啊,以你这个时间为基准,这之前的记录都分成一个区域,从这个以后,每一个月,我会有一个
区域,每一个月会有一个区,然后我通过查这个,里面分区的name,分区name是自定义的,你没法去控制

如果你能查到这个表,查到这个东西,然后现在咱们看
SELECT * FROM interval_sale PARTITION(SYS_P01);
查询这个,查询,我现在看到了,2月5号的数据,我在查一下下个分区
SELECT * FROM interval_sale PARTITION(SYS_P02);
这个是3月6号的

有人说那一下年的呢,我再插入一条数据,比如咱们不这么去分,之前14年的1月份,2月份,3月份,都有了吗
包括之前的就不说了,现在我要来一个15年的12月7号,他两是相同的,只不过年份不同,之前这是12年的,现在我来一个15年的,
我再insert

成功了以后呢,现在我的分区可能有多了一个了

你会发现你有个103了,103他单独这一个月,就是指定的这12月份这一个月,肯定是有一个单独的分区的,你通过这
你就能看到,上限是多少,上限是16年的1月1号,然后这边的上限是多少啊,这边的上限是4月1号,因为刚才我们建立的这条数据,
就是102里面存的是这个,是3月6号,这个分区的上限是4月1号之前,就是一个月一个月的会去给你建分区,你只要满足在14年
2月1号之后,这个月份就会单独的建立一个分区,这个就是一个interval分区,能理解我说的意思吧,分区之后数据文件是什么样子的,
这个是物理存储到其他地方,我也不知道,你要问ORACLE的OCM,分区之后是放到哪儿,数据文件肯定是单独独立的,一个分区一个文件,
肯定是这样的,然后我看看这边,分区这边不断增加会有问题吗,分区数目有没有限制,分区数目是没限制的,就是你采用这种INTEVRVAL
分区,这个是什么场景下用的,比如你们公司,一个月的数据量就会很大的,一个月的数据量就200,300万,那你就不会做这个事情了,
我就按照月份,按照时间维度,或者有的公司一天数据量就很大,按照天去分区,我一天一部分数据,一天一部分数据,或者是按照月走,
或者是按照年走,或者是按照季度走,或者你按照week周走,一周一分区,他就是不同的文件,只要你硬盘足够大,有空间的话,只要你硬盘
足够大,有空间的话是没问题的,能明白我的意思吧,可以分开存储,它本身就是分开,就是跟我们的分区索引是一样的,只能采用分区字段,
你只能在刚才我们看到的date,你只能给他建索引,一模一样的,包括几种形式去建是一样的,我举个例子吧,之前我们是把一个表放在一个
物理存储了,一块区间去查了,现在我可以按照哈希分区,range分区,或者list分区,或者是其他的分区,现在咱们说一种range分区,按照
月份,一个月份一个数据文件,一个月份一个单独文件,他这个东西什么概念呢,我现在有一个client端,我要查询的时候,我要查3月份的,
3月份的我就查这一个数据文件,其他的数据文件是不查的,只要当前的ORACLE服务器磁盘够用,能理解我的意思吧,这个分区是可以无线的
加的,比如一个最简单的例子,你建表一样,你开始建了10张数据库,数据库里建立10张表,后来业务扩展了,建立100张表,100张表
不就是100个数据文件吗,然后你建了1000张表后发现,完了,咱们的ORACLE服务器不够用了,怎么办,要加硬盘,这个道理也是一样的,
能理解我说的意思吧,然后呢,还有什么,后期要加其他字段的索引,后期如果你要加其他字段的索引的话,那就不行了,那你如果
加索引的话只能是走全表的索引了,就是跟分区没关系了,就像有人说的,我把它进行分区了,你想在分区上加索引,你只能使用
分区字段去加索引,但是如果你要是加在其它字段上,那就是全表索引了,全表的索引,就是global索引,然后呢,刚才咱们所说的
是什么啊,有的人说我的业务就是这样的,那其实这个东西,技术跟业务,是相结合的,跟设计是想结合的,比如我们怎么去做啊,
咱们现在就这样,我们就按照时间间隔,一个月份,然后我去做分区,你前台的表单,然后访问咱们的应用层,就是JAVA,数据库,
还有一种情况是跨分区,比如我们是一个月份一个月份的分区,然后你现在是想查1月份到5月份的数据,你说这个跟谁玩啊,
你就想查1月份到5月份的数据,那他肯定效率不高啊,肯定是把这5块都查了啊,他肯定是走5个数据文件吗,你要是1月份到
12月份1年的,那肯定是有走数据文件了,1月份到12月份都查了,那是全表扫描能理解我说的意思吧,所以说很多业务,分完区之后,
你可以做缓冲表,你要是按照月份去查,你还可以去做客其他的事情,比如你跨分区查,
分区之后的数据文件是什么样子,这个之前说过了,分区不断增加会不会有问题,就跟你数据库表多建几个一样,能分开存储吗,
能分开存储然后这种分区怎么去建索引,跟正常的建索引是一样的,分区索引,然后如果你在其它字段上去建索引,相当于
全表去建索引,比如后期要加其他字段索引呢,那这个问题还是之前的话题,相当于加全表的索引,分区越多会影响全局索引
的查询速度吗,这个不影响,分区索引和全局索引是两码事,
他只是影响磁盘的IO,你想想之前一个索引,现在两个索引,又建立三个索引,又建立了四个索引,维护的IO可能就更多了,但是
分区越多影响查询的速度,这个肯定是不影响的,为什么不影响,就是你还没有理解分区索引的概念,你要知道把一张表分成
三个区间之后,他就相当于单独的一张表了,你分区越多,你建索引越多,索引其实还是在这一块区域上去建的,这个意思,
分区你可以理解为分表,分区你可以理解为单独的建了一个表,接下来就是我刚才说的那个问题,分区索引是多个,分区
索引看情况,如果是普通的local索引,肯定是多个,比如你有10个分区,然后你create index,然后什么什么on table,那个字段,
然后这样的一个local索引,其实就相当于你分10个区,建了10个索引,建10个索引是完全不影响咱们查,就是不影响SELECT,
也不影响update的效率的,知道为什么吗,因为我分了10个区以后,一条数据不可能跨分区去插入吧,能理解我说的意思吧,
一条数据,比如我指定月份分区,你这条数据肯定是指定1月份,或者2月份的,
你不可能是这条数据是1月份或者2月份的,所以你插入的时候只能往一个区里插,我这个索引只有一把索引,这是没有任何
性能影响的,然后咱们举一个例子,刚才说到什么事啊,其实刚才我还是想说,设计跟你这个技术,是应该完全像结合的,
比如这是咱们一个传统的行业,表单,这里面有很多的复选框,比如说要你查询,这里有一个开始的日期,这里有一个
结束的日期,这是开始,然后呢让你去填数,进行一个检索,还有其他的条件咱们先不理会了下面就是展示数据的,就是
这么一个小DEMO,假如你现在查的是1月1号,或者是1月15号,查1月15号到30号,到1月30号,然后走了一个JAVA层,然后DB层,
走到DB层咱们是按照月份去分区的,所以说你都是1月份的,都是1月份的话,这个效率很高,因为什么啊,因为咱们month这个字段,
date这个字段,月份的这个字段首先建了分区了,然后建了分区索引了,所以你要查这个数据呢,肯定是在一个数据文件里,
如果你有这个情况,只想查1月15号,到3月8号的,你就想跨分区去查,查2月8号的,那他肯定会走两个数据文件,
因为你1月15号到1月30号,它是在一个数据文件里,但是从2月1号到2月8号呢,他又是在一个数据文件里,这个时候你
就得去设计了,怎么去设计,你前端就得JS去验证,如果输入这个数字我就告诉它,我们不能跨月份去查询,能理解我说的
意思吗,这个东西从设计的角度,去越过一些其他的问题,你觉得查询上会觉得很慢的的一个问题,或者即使是跨分区也可以,
我们之前就是有这么一个需求,就是要查一个季度的,1月份到3月份,怎么办啊,正常我的物理表可以抽取月份的数据,
抽取记录的数据做汇总,那我就想查跨两个月,1月份到2月份,那怎么办,那你就刚脆让他查呗,相对来讲效率稍微会慢一点,
但是这个都无所谓,你说我就想查1月15号到2月15号的,那肯定不行,就相当于你查整张表了差不多就是一年的所有数据,
这个效率肯定是不行的,很多事情你是业务和设计解决才行的,就是技术加上业务,有时候设计要比技术更好,
你设计的东西可以屏蔽很多查询慢的问题,所以还是你在技术的基础上,加上设计,你才能设计性能最好的产品,能理解
我说的意思吧,一定是这样的,我这个东西就像跨12个月份查,你没办法,你永远查12块数据,怎么可能快呢,还有,你就
别用ORACLE了,把数据直接灌到内存里,来查吗,很多种方案,那你就换解决方案,你就换技术,一种技术行不通,就换一种技术,
肯定有一种行得通的,但是我还是要建立你什么啊,
不要轻易地去换另外一种技术,从设计者的角度去考虑,你作为一个架构去考虑,不能说来了一个新东西我就换一种技术,
你得考虑全方位,是不是非得有必要去用这种东西,在原有的设计基础之上,真的解决不了这个业务了,那你还得考虑
这个可行性行不行,那你这个时候才会去考虑去加一种新的技术,因为这个东西是有风险的,到底行不行的通,你还得
派一个人去做一个需求调研,然后再去做这个事情,这个东西就是这样的,软件开发其实就是这样的,今天咱们就到这儿吧,
还记得我这个问题吗,这个数据库表结构,我再次说一下,可能你们之前理解的不太明白,现在我再花点时间把这个东西说一下,
首先我有一张数据库表,这个数据库表是一个很大的tree,是一个很长的树,层次结构也很深,数据也很多,可能几千,几万条,
首先这个TREE就有一个问题,做高效的查询,那我用前端技术,异步加载,我根据ID查询ID下的节点,子节点有了之后,再根据
子节点查出这个子节点下的子节点,不让你玩这个,不让你玩这个异步加载,很多情况是不能异步加载的,异步加载有些场合可以,
有些场合不行,就得让你直接展示一棵树,因为展示这棵树不仅仅是前端,有人说你们这个业务很简单,就是一颗树展示到界面上,
你一次查一个parentId,展示节点完全OK,但是还有很多很多业务场景,不仅仅是需要展示的还需要做统计分析的,做统计查询
做关联,那这个时候你就需要查一颗整体的树,就根据这个id查询他的孩子,孙子,都查出来,然后要跟其他的一张大表,大的基表,
千,万,上亿的数据,然后再和其他的表join,我用户登录的可能是这样的一张表,但是过滤的时候是根据树的层次结构去过滤的,
你得join A,B,C,D这三张表,还有一种需求是说,你这棵树层级很深,这是第一层,这是第二层,这是第三层,这是第四层,那我
先做就想让你查钱三层,第四层,第五层数据你不要,总之就这三需求,第一个需求就是你怎么能快速的检索一棵树,1,2,3,4,5
都给我查出来,第二个需求是怎么从第一层查到第三层,如何实现数据量比较大的join,你让这个性能变得高,就这三个问题,
仔细好好想一想,其实就是利用咱们这种数据库设计,然后加上一些特殊的东西就能实现,我的问题能理解吧,
我的问题能理解的话,你就去想一想,去做一做,今天就到这儿吧,START WITH和CONNECTOR BY,你进行一个怎么说呢,开始可以,
但是后来就不行了,START WITH可能首先来讲性能可能低一点,如果能合理的树形结构快一点,性能可能稍微高一点,当然
这不是主要的,主要的问题是什么啊,主要是到最后三个问题,你进行START WITH CONNECTOR BY以后,然后你去join四张表了,
最终我可能要过滤出来一千万条数据,一条数据你就得从START WITH,CONNECTOR BY结尾,本身就是一个FOR循环,
你这个数据还得去FOR循环,你想想这个性能就很慢,就是想一想,你可以百度,今天就到这儿吧






















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









