







Apache Flume
关于Flume
Hadoop的宗旨是处理大型数据集。通常,我们假设这些数据已经存储在HDFS中,但是如果数据不再HDFS怎么办?
设计Flume的宗旨是向Hadoop批量导入基于事件的海量数据。
Flueme通常用来向Hadoop导入日志文件。
1.安装Flume
①首先下载并解压Apache Flume
http://flume.apache.org/download.html
这里我下载的是( apache-flume-1.9.0-bin.tar.gz)
②为了方便起见我们把flume添加到path,如下图所示(12行和13行内容),我们可以在~/.bash_profile文件中进行配置。
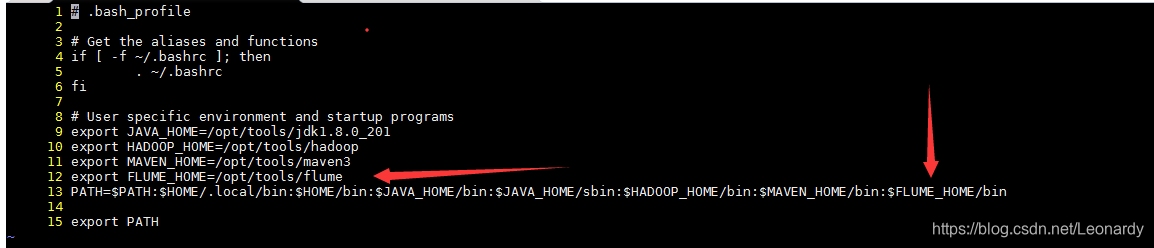
配置之后为了能够立即生效,我们还如要让系统重读配置文件。
source ~/.bash_profile
然后,可以用Flume-ng命令启动Flume代理。(指定help参数来查看帮助信息)
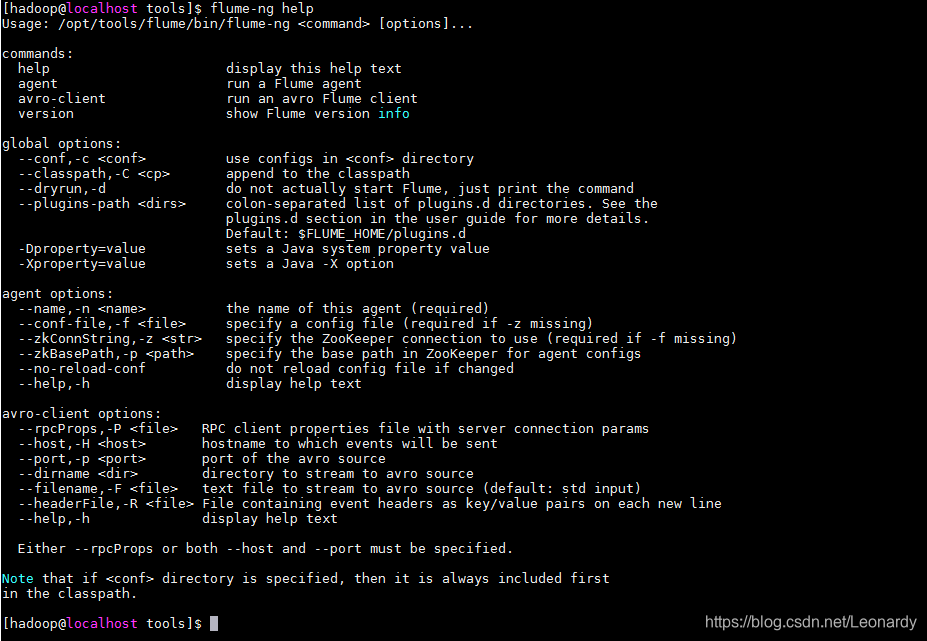
2.Flume样例
①创建一个文件夹,用flume来监视,如果文件夹内有新文件被添加,那么flume会把它的每一行内容输出到控制台。
mkdir /tmp/spooldir
②我们还需要一个flume的配置文件。这里我把它命名为`spool-to-logger.properties,文件内容如下:
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
agent1.sources.source1.channels=channel1
agent1.sinks.sink1.channel=channel1
// type=spooldir用来监视缓冲目录中的新增文件。
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/tmp/spooldir
// type=logger用于将事件记录输出到控制台。
agent1.sinks.sink1.type=logger
agent1.channels.channel1.type=file
③配置好以上内容后,我们用命令来启动flume代理。
flume-ng agent \
--conf-file flume/conf/spool-to-logger.properties <--之前的配置文件
--name agent1 <--配置文件中的代理名
--conf  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









