







EDomics数据库中包含了很多物种的基因组、转录组的数据,当我想下载某一物种的全部gene annotation 信息,发现只能分页展示分页下载,这很令我苦恼。于是求助了同班的野原新之助同学,具体方法如下。
1.打开网页(Google chorme),搜索出你想要的内容
这里是Am什么什么物种,想要它的GO的全部注释信息 ,total 24714
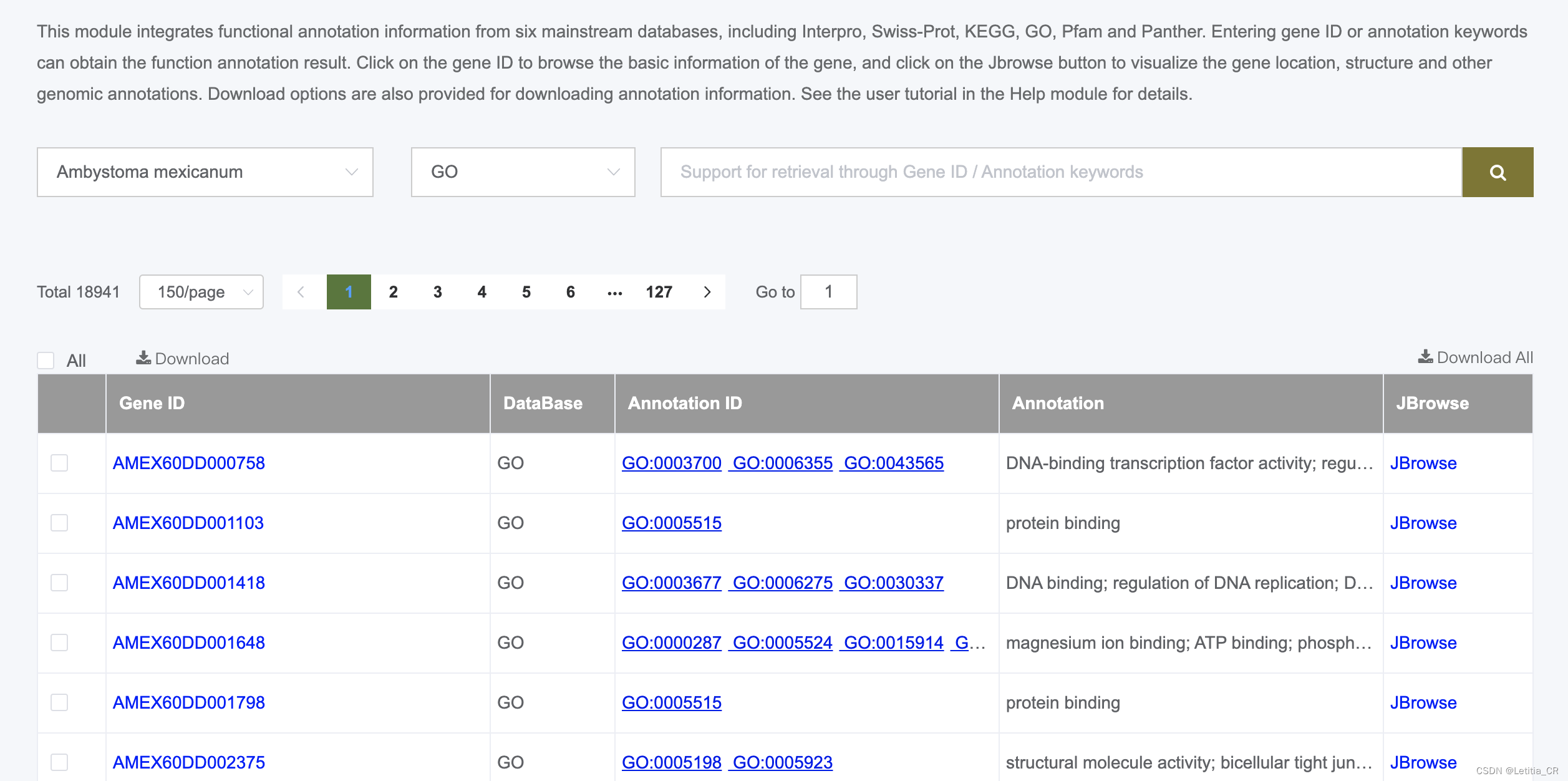
2.F12——网络——点击download all——观察网络活动
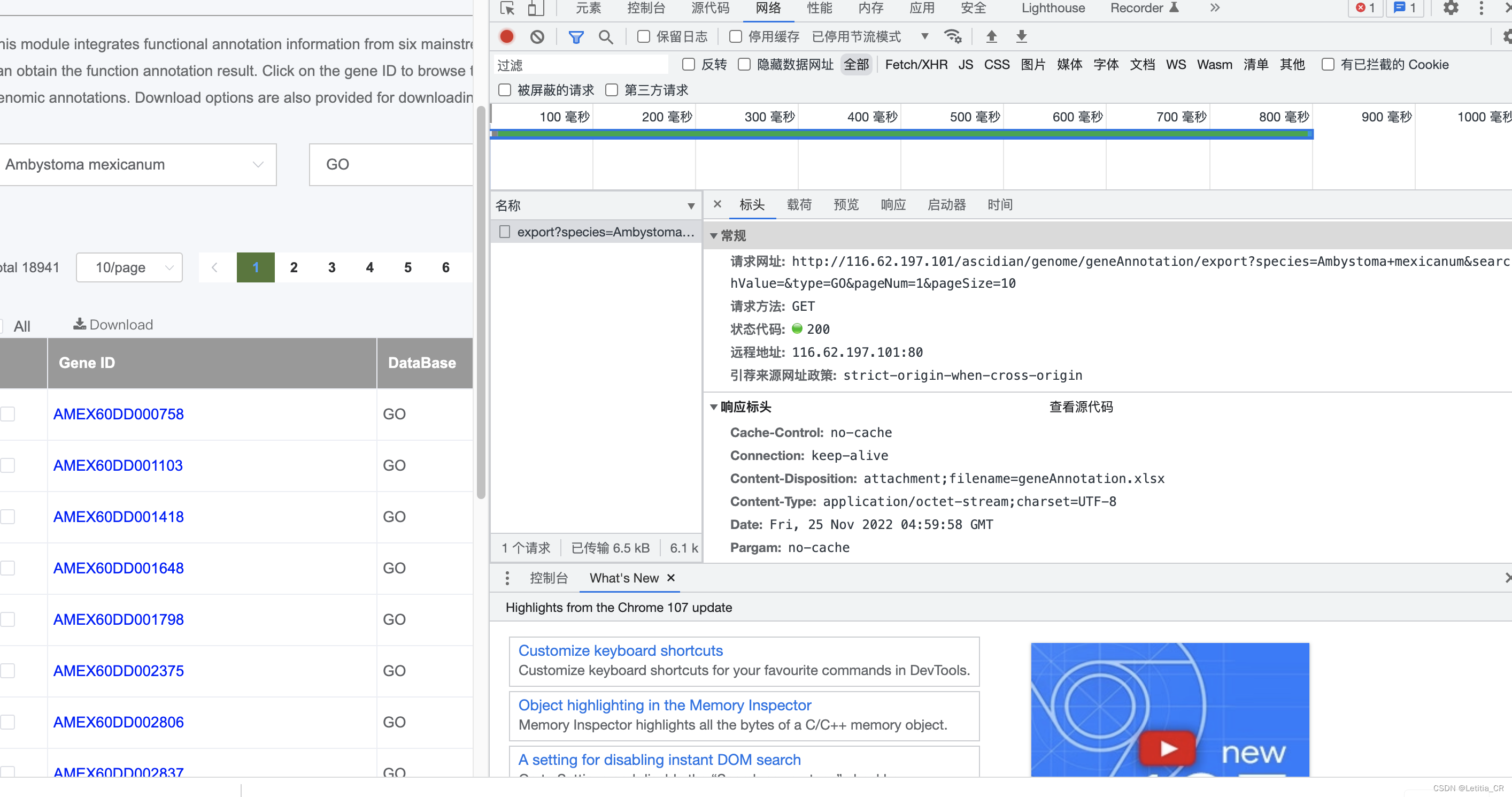
3.复制请求网址到新的标签页中
解析他的下载行为,前面是搜索条件,后面的是pageSize更改到我们想要的最大数量,18941——改成25000,然后就会自动下载啦!
4.随意抽样检查一下,哇!全都对诶!
感谢野原新之助同学,又是投机取巧的一天嘻嘻

















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









