







flume:实时日志收集系统,是日志收集之王。
flume的特性:
(1)可靠性
(2)可伸缩性
(3)高性能
(4)可延展性
(5)开源社区的支持
flume的概念:
(1)agent——>使用JVM 运行flume,每台机器运行一个agent,但是可以在一个 agent中包含多个sources和sinks。
(2)client——>生产数据,运行在一个独立的线程。
(3)source——>从client收集数据,传递给channel。
(4)channel——>连接 sources 和 sinks 。
(5)sink——>从channel收集数据,运行在一个独立线程。
(6)events——>是flume的数据处理单元,可以是日志,avro,spool等。
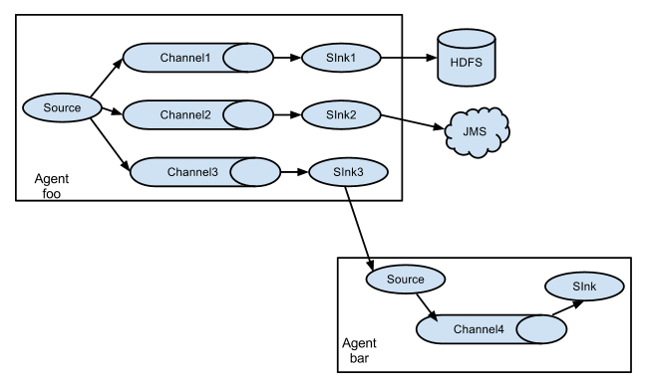
flume的数据流图:
flume的例子
(以exec为例)
1.(1)先在flume的conf目录下创建一个exec.conf文件,
vi conf/exec.conf(2)在exec.conf文件中输入以下内容:
# Name the components on this agent
agent1.sources = r1
agent1.sinks = k1
agent1.channels = c1
#define source monitor a file
agent1.sources.r1.type = exec
#(定义数据源的地址及查看数据源的方式为:tail -n +0 -F /home/storm/work/access.log )
agent1.sources.r1.command = tail -n +0 -F /home/storm/work/access.log
agent1.sources.r1.channels = c1
# Describe the sink
# Each sink's type must be defined
agent1.sinks.k1.type = file_roll
#(定义flume的输出地址为:/home/storm/flume/data)
agent1.sinks.k1.sink.directory=/home/storm/flume/data
agent1.sinks.k1.sink.serializer = text
agent1.sinks.k1.sink.serializer.appendNewline = true
#a21.sinks.r2.sink.rollInterval = 3600
agent1.sinks.k1.sink.rollInterval = 43200
agent1.sinks.k1.channel = c1
# Use a channel which buffers events in memory
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 1002.启动flume
bin/flume-ng agent -c conf -n agent1 -f conf/exec.conf -Dflume.root.logger=INFO,console >> logs/flume.log 2>&1 &参数说明:
-c conf 指定配置目录为conf。
-f conf/exec.conf指定配置文件为conf/avro.conf (注意路径,当前路径与配置所指的路径)。
-n agent1 指定agent名字为agent1,需要与exec.conf中的一致。
-Dflume.root.logger=INFO,console 指定DEBUF模式在console输出INFO信息。
“>>logs/flume.log 2>&1 & “指的是把输出的日志信息追加到logs/flume.log。















 102
102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









