






1. Trace文件
1.1. SQL_Trace
1.1.1. 开启/关闭当前会话的Trace文件
开启:alter session set sql_trace = true;
关闭:alter session set sql_trace = false;
1.1.2. 查看Trace文件文件
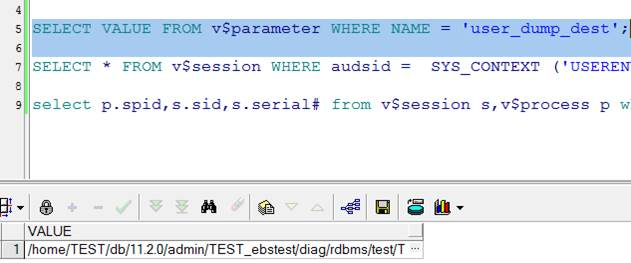
1、查看trc文件路径:
SELECT VALUE
FROM v$parameter
WHERE NAME = 'user_dump_dest';
或者:命令行执行show parameter user_dump_dest
2、查看trc文件名:
Trc文件名构成:“instance_name” + “_ora_” +”spid.trc”
查看当前会话SID:
SELECT *
FROM v$session
WHERE audsid = sys_context('USERENV',
'SESSIONID');
或者
SELECT inst_id, SID, serial#, audsid, username, osuser,
program, sql_id, sql_child_number, module, event
FROM gv$session
WHERE audsid = SYS_CONTEXT ('USERENV', 'SESSIONID');
或者
SELECT sid,
serial#
FROM v$session
WHERE audsid = userenv('SESSIONID');

查看spid:
SELECT p.spid,
s.sid,
s.serial#
FROM v$session s,
v$process p
WHERE s.paddr = p.addr
AND s.sid = 1102;

查看trc文件名:

1.1.3. DBMS_SESSION包
1、DBMS_SESSION包简介:
Oracle除了提供SQL的方法外,还提供了PL/SQL的接口,DBMS_SESSION包,将会话状态的设置和查询集成在这个包中。
开启:SQL> exec dbms_session.set_sql_trace(true);
关闭:SQL> exec dbms_session.set_sql_trace(false);
这种方式等同于:alter session set sql_trace,除了不能设置实例级的SQL_TRACE,其他优点缺点一致;另外还提供了另外级别的TRACE功能:
SQL> exec dbms_session.session_trace_enable(true,true);
SQL> exec dbms_session.session_trace_disable;
这个过程可以设置包含等待事件和绑定变量的sql_trace,10g开始提供。
2、DBMS_SESSION内置函数
函数一:UNIQUE_SESSION_ID
SELECT DBMS_SESSION.UNIQUE_SESSION_ID FROM DUAL

函数返回值在数据库的一个会话的生命周期中一个唯一确定的。
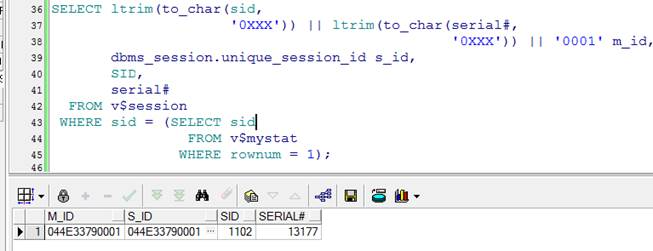
3、与V$SESSION视图的关联
方法一:16进制
SELECT ltrim(to_char(sid,
'0XXX')) || ltrim(to_char(serial#,
'0XXX')) || '0001' m_id,
dbms_session.unique_session_id s_id,
SID,
serial#
FROM v$session
WHERE sid = (SELECT sid
FROM v$mystat
WHERE rownum = 1);
函数的返回值为16进制数值,将V$SESSION视图中的SID和SERIAL#转换成16进制,进行比较。可以根据值的比较确定会话是否存活。如果存活就根据SID和SERIAL#去找对应TRACE文件
方法二:10进制
UNIQUE_SESSION_ID的值为:044E33790001。求UNIQUE_SESSION_ID与SID和SERIAL#之间的关系
最后的0001为一个序列号,然后将044E3379转化成10进制

关联公式:10进制UNIQUE_SESSION_ID = SID * 65536 +SERIAL#
65536一个固定值,16的四次幂。
函数二:IS_SESSION_ALIVE
根据UNIQUE_SESSION_ID返回的值,检查会话是否存活。
DECLARE
v_result BOOLEAN;
BEGIN
v_result := dbms_session.is_session_alive('&UNIQUE_SESSION_ID');
IF v_result THEN
dbms_output.put_line('ACTIVE');
ELSIF NOT v_result THEN
dbms_output.put_line('NOT ACTIVE');
ELSE
dbms_output.put_line('NULL RESULT');
END IF;
END;
这里检查的值和V$SESSION视图中STATUS列的值没有关系,V$SESSION视图中STATUS列指出当前这个会话是否处于活动状态,而IS_SESSION_ALIVE的值指出这个会话是否还存在,于当前是否活动无关。
2. Tkprof介绍
2.1. 格式化
Tkprof主要是用来解释trace文件内容的,把原始的trace文件转化为容易理解的文件
2.1.1. tkprof格式化trace文件
| 1、语法 tkprof tracefile outputfile [explain= ] [table= ] [print= ] [insert= ] [sys= ] [sort= ] 参数和选项: explain=user/password 执行explain命令将结果放在SQL trace的输出文件中 table=schema.table 指定tkprof处理sql trace文件时临时表的模式名和表名 insert=scriptfile 创建一个文件名为scriptfile的文件,包含了tkprof存放的输出sql语句 sys=[yes/no] 确定系统是否列出由sys用户产生或重调的sql语句 print=number 将仅生成排序后的第一条sql语句的输出结果 record=recordfile 这个选项创建一个名为recorderfile的文件,包含了所有重调用的sql语句 sort=sort_option 按照指定的方法对sql trace的输出文件进行降序排序。 其中:sort_option 选项如下:
2、tkprof实例 不输入任何参数,直接输入tkprof,可以获取一个完整的参数列表 tkprof /home/DEV/db/11.2.0/admin/DEV_ebsdev/diag/rdbms/dev/DEV/trace/DEV_ora_7616_HAND_YZJ_CR720404_1022_133921.trc /home/appldev/trace/DEV_ora_7616_HAND_YZJ_CR720404.txt
.trm文件:元数据跟踪文件,元数据 描述了存储在.trc跟踪文件中的跟踪记录 |

2.1.2. 实例分析
1、用tkprof命令转换.trc文件
tkprof
/home/DEV/db/11.2.0/admin/DEV_ebsdev/diag/rdbms/dev/DEV/trace/
DEV_ora_23891_HAND_YZJ_CR721811_1023_134748.trc
/home/appldev/trace/DEV_ora_23891_HAND_YZJ_CR721811.txt
sort='(prsela exeela fchela)'
explain=apps/apps
sys=no
2、SQL语句执行总览

主要看elapsed处理时间(单位秒)。
参数说明:
call:每次SQL语句的处理都分成三个部分
- Parse:这步将SQL语句转换成执行计划,包括检查是否有正确的授权和所需要用到的表、列以及其他引用到的对象是否存在;
- Execute:这步是真正的由Oracle来执行语句,对于insert、update、delete操作,这步会修改数据,对于select操作,这步只是确定选择的记录;
- Fetch:返回查询语句中所获得的记录,这步只有select语句会被执行。
count:这个SQL语句被parse、execute、fetch的次数;
cpu:这个语句对于所有的parse、execute、fetch所消耗的cpu的时间,以秒为单位;
elapsed:这个语句所有消耗在parse、execut、fetch的总的时间;
disk:从磁盘上的数据文件中物理读取的块的数量。一般来说更想知道的是正在从缓存中读取的数据而不是从磁盘上读取的数据。
query:在一致性读模式下,所有parse、execute、fetch所获得的buffer的数量。一致性模式的buffer是用于给一个长时间运行的事务提供一个一致性读的快照,缓存实际上在头部存储了状态。
current:在current模式下所获得的buffer的数量。一般在current模式下执行insert、update、delete操作都会获取 buffer。在current模式下如果在高速缓存区发现有新的缓存足够给当前的事务使用,则这些buffer都会被读入了缓存区中。
rows: 所有SQL语句返回的记录数目,但是不包括子查询中返回的记录数目。对于select语句,返回记录是在fetch这步,对于insert、update、delete操作,返回记录则是在execute这步。
3、SQL执行效率分析
A、query+current/rows 平均每行所需的block数,太大的话(超过20)SQL语句效率太低
B、Parse_count/Execute_count parse count应尽量接近1,如果太高的话,SQL会进行不必要的reparse
C、Fetch_row/Fetch_count Fetch Array的大小,太小的话就没有充分利用批量Fetch的功能,增加了数据在客户端和服务器之间的往返次数。
D、disk/query+current 磁盘IO所占逻辑IO的比例,太大的话有可能是db_buffer_size过小(也跟SQL的具体特性有关)
E、elapsed/cpu 太大表示执行过程中花费了大量的时间等待某种资源
F、cpu Or elapsed 太大表示执行时间过长,或消耗了了大量的CPU时间,应该考虑优化
G、执行计划中的Rows表示在该处理阶段所访问的行数,要尽量减少
4、运行环境信息:

第一行表示发生在解析的硬解析数量,如果是软解析则Misses in library cache during parse将为0;
第二行表示优化模式是:ALL_ROWS (即CBO优化方式)
第三行是用户的ID,可以获取执行时的会话信息。获取用户信息可以通过如下SQL:

5、行源操作,查看COST值以及关联关系

参数:
cr=3 一致性读取,pr=0 物理读取,pw=0 物理写,time = 16 占用时间,单位:微秒
Trace文件除了关注SQL语句执行情况中的elapsed SQL总耗时间外,还需要关注的是该部分的数据。
A. 关注其中的cost值和表之间的关联情况。Cost值和执行计划中的cost值一样,值越大,说明耗时越长,这是需要注意有可能存在优化项的地方。
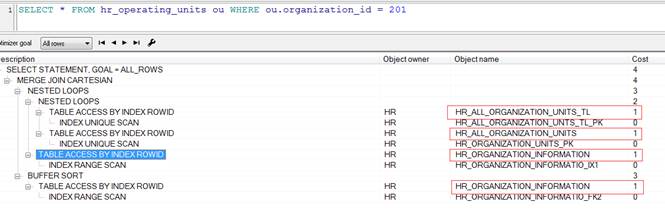
B. 另一点,就是看表关联之间是否存在TABLE ACCESS FULL全表扫描(下图是截取其他某trace文件),全表扫描可视情况通过建立适当的索引来优化;在sql语句中,我们也可能使用了某些不必要的视图,这些视图对应的sql查询本身部分就是要进行全表扫描,这种情况下可考虑放弃视图,使用基表。
如下图:SQL中查询表:HR_ALL_ORGANIZATION_UNITS,在这里使用了全表扫描,如果实在很大SQL中,肯定会影响执行效率,所以我们对于全表扫描的的SQL,要进行优化。

我们看下这段代码的执行计划:
当参数为空时,会扫描全表,所用的花费为3

当参数不为空时,走的索引,所花费的时间为1

还有如果是因为SQL中使用了视图导致全表扫描,我们可以考虑使用基表。SQL中也尽量不要使用视图,可以节省很多COST。
6、执行计划

这里是SQL运行的实际执行计划,比我们用F5所得到的执行计划更加详细
7、等待事件(TOP5)


这些都是等待时间,涉及到底层的东西,但是对SQL性能优化有很大的帮助。等待时间太长,会浪费大部分资源。
我们也可以从另外的方面来了解这些东西:
SELECT EXECUTIONS,
DISK_READS,
BUFFER_GETS,
ROUND((BUFFER_GETS - DISK_READS)/BUFFER_GETS,2) HIT_RADIAO,
ROUND(DISK_READS/EXECUTIONS,2) READIO_PER_RUN,
SQL_TEXT
FROM V$SQLAREA
WHERE EXECUTIONS > 0
AND BUFFER_GETS > 0
AND SQL_TEXT LIKE ''
AND (BUFFER_GETS - DISK_READS) / BUFFER_GETS < 0.8;
这是一段查询共享池中已经解析过的SQL语句及其相关信息
其中字段意思为:
--EXECUTIONS 所有子游标的执行这条语句次数
--DISK_READS 所有子游标运行这条语句导致的读磁盘次数
--BUFFER_GETS 所有子游标运行这条语句导致的读内存次数
--Hit_radio 命中率
--Reads_per_run 每次执行读写磁盘数
笼统的说EXECUTIONS,BUFFER_GETS,Hit_radio越高表示读内存多,磁盘少是比较理想的状态,因此越高越好另外两个越高读磁盘次数越多,因此低点好。
而且一般比较好的SQL:(BUFFER_GETS-DISK_READS)/BUFFER_GETS这个比值一般是小于0.8的。
2.1.3. 视图换成基表实例
知道一个业务实体ID,要获取对应的业务实体名称。我们可以选择视图:
HR_OPERATING_UNITS,
或者使用基表:
HR_ALL_ORGANIZATION_UNITS,HR_ALL_ORGANIZATION_UNITS_TL
1、当我们使用视图时:
2、当我们使用基表时:

从上面的两个执行计划我们可以发现,我们其实只需要两个表,只会在一个表上花费时间,但是使用视图的话,我们要进行几张表表的扫描,而且在三张表上花费时间,并且应为多张表的笛卡尔(MERGE JOIN)关联,需要在值集进行排序,所以在内存排序(BUFFER SORT)上又会发给一定的时间。
所以我们在很大的SQL中要尽量避免使用视图,用基表来减少SQL执行所花费的时间。
3. 其他追踪事件
3.1. 10046(SQL_TRACE)
3.1.1. 使用方法
10046事件和SQL_TRACE作用一样,都是用来追踪SQL,通过生成的trace来了解SQL的执行过程。和普通的SQL_TRACE方法相比,10046事件提供了可选的追踪级别。
10046事件可选四个级别:level 1、4、8、12:
Level 0 停用SQL跟踪,相当于SQL_TRACE=FALSE
Level 1 标准SQL跟踪,相当于SQL_TRACE=TRUE
Level 4 在level 1的基础上增加绑定变量的信息
Level 8 在level 1的基础上增加等待事件的信息
Level 12 在level 1的基础上增加绑定变量和等待事件的信息
10046事件不但可以跟踪用户会话(trace文件位于USER_DUMP_DEST),也可以跟踪background进程(trace文件位于BACKGROUND_DUMP_DEST)。
根据追踪的方法不同,最后生成的trace文件的大小也不同个,起决定于4个因素:
跟踪级别,跟踪时长,会话的活动级别和MAX_DUMP_FILE_SIZE参数设置。
1、数据基础参数设置:
alter session set tracefile_identifier='10046';
设置追踪标识符,标识符可随意指定,本例中生成的trace文件名中会包含‘10046’字样,方便查找;
alter session set timed_statistics=true;
设置为true,否则不会有CPU时间信息;
alter session set max_dump_file_size ='UNLIMITED';
Trace文件的最大尺寸(单位为操作系统块),UMLIMITED表示没有限制
2、开启、关闭追踪
alter session set events '10046 trace name context forever, level 12';
alter session set events '10046 trace name context off';
3、获取Trace文件
SELECT * FROM v$parameter t WHERE t.NAME = 'user_dump_dest';

3.1.2. 其他使用法
通过使用配置文件的方式,可以在接口程序中使用10046事件开启trace,也可以在请求,form个性化等方式,只要能执行代码,就都可以使用该事件去进行追踪,看个人选择。此处仅为接口中使用10046事件做代码注释
g_trace VARCHAR2(1) := nvl(fnd_profile.value('CUX_O2E_OM_WS_TRACE_FLAG'), 'N');
IF g_trace = 'Y' THEN
EXECUTE IMMEDIATE 'ALTER session SET tracefile_identifier = CRMORDER_' || p_transaction_id || ' ';
EXECUTE IMMEDIATE 'ALTER session SET timed_statistics = TRUE ';
EXECUTE IMMEDIATE 'ALTER session SET statistics_level = ALL ';
EXECUTE IMMEDIATE 'ALTER session SET max_dump_file_size = unlimited ';
EXECUTE IMMEDIATE 'alter session set events ''10046 trace name context forever,level 12'' ';
END IF;















 9661
9661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









