







Hive之SerDe
1. 什么是SerDe
SerDe 是两个单词的组合:serialized(序列化)和 deserialized(反序列化)。在进程进行远程通信时,数据以二进制序列的形式在网络上传输。发送方将对象转换为字节序列(序列化),接收方将字节序列恢复为对象(反序列化)。
Hive的反序列化是将key/value对反序列化为Hive表的各个列的值。Hive可以直接将数据加载到表中而不需要转换,从而在处理海量数据时节省大量时间。
在读写行数据时,流程如下:
-
读:
rust 复制代码 HDFS files --> InputFileFormat --> <key, value> --> Deserializer --> Row object -
写:
rust 复制代码 Row object --> Serializer --> <key, value> --> OutputFileFormat --> HDFS files
当向HDFS写数据时,数据先经过序列化转化成字节序列,然后以指定格式(OutputFileFormat)输出到HDFS。而从HDFS读数据时,过程则相反。
2. 序列化方式
Hive 内置了多种序列化方式,同时也支持自定义。以下是几种常见的内置序列化方式:
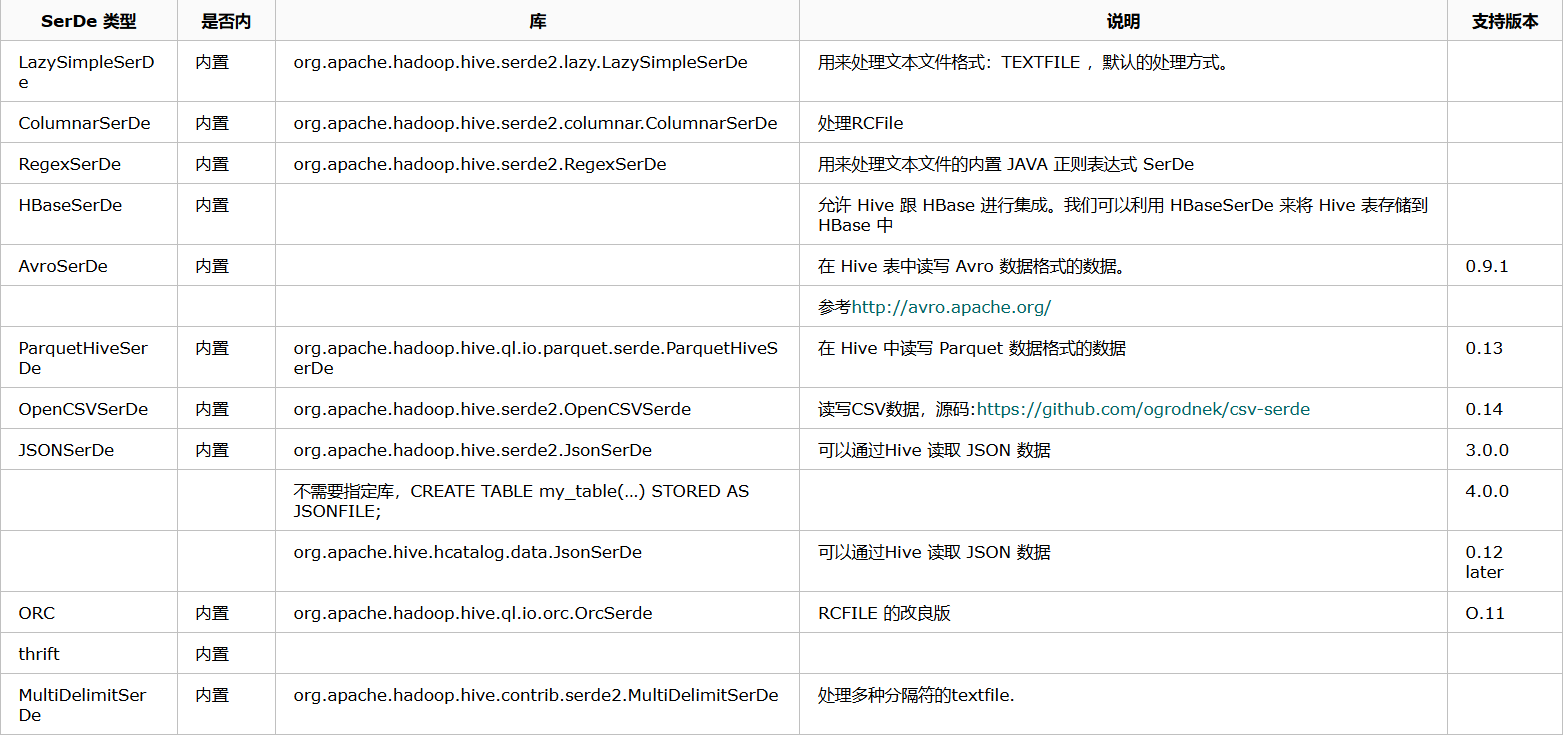
3. 详细解释RegexSerDe和MultiDelimitSerDe
3.1 RegexSerDe
RegexSerDe(正则表达式序列化/反序列化)是一种通过正则表达式解析和序列化数据的SerDe。它允许用户通过正则表达式定义如何将输入数据解析成表的各个列。具体来说,用户可以指定一个正则表达式来匹配输入数据,并将匹配的部分映射到表的列上。
特点:
- 灵活性高:适用于复杂和不规则格式的数据。
- 正则表达式:用户定义的正则表达式可以解析复杂的数据结构。
使用示例:
CREATE TABLE IF NOT EXISTS t_user
(
UserID BIGINT COMMENT '用户ID',
sex STRING COMMENT '性别',
Age INT COMMENT '年龄',
Occupation STRING COMMENT '职业',
Zipcode STRING COMMENT '邮政编码'
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "(.*)::(.*)::(.*)::(.*)::(.*)"
)
STORED AS TEXTFILE;
在这个例子中,input.regex定义了正则表达式(.*)::(.*)::(.*)::(.*)::(.*),表示输入数据由五个部分组成,各部分之间用双冒号(::)分隔。
3.2 MultiDelimitSerDe
MultiDelimitSerDe(多分隔符序列化/反序列化)是一种通过指定字段分隔符解析和序列化数据的SerDe。用户可以定义一个或多个分隔符来解析输入数据并将其映射到表的各个列上。
特点:
- 简单直接:适用于格式固定且由特定分隔符分隔的数据。
- 分隔符:通过指定分隔符来解析数据。
使用示例:
CREATE TABLE t_user
(
Userid bigint comment '用户ID',
sex string comment '性别',
Age int comment '年龄',
Occupation string comment '职业',
Zipcode string comment '邮政编码'
) ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.MultiDelimitSerDe'
WITH SERDEPROPERTIES (
"field.delim" = "::"
)
STORED AS TEXTFILE;
在这个例子中,field.delim定义了字段分隔符::,表示输入数据的各字段之间由双冒号分隔。
4. SerDe2的作用
SerDe(Serialization/Deserialization)是序列化/反序列化的缩写,指的是将数据在存储格式和对象格式之间转换的过程。Hive中的SerDe用于解析输入数据(从文件中读取)并将其映射到表的列上,以及将查询结果序列化回输出格式。
作用:
- 解析数据:将输入数据文件解析成Hive表的各列。
- 序列化数据:将查询结果序列化回文件格式。
SerDe2是Hive中提供的一种更强大、更灵活的SerDe机制,可以支持更多的数据解析需求,如正则表达式解析、复杂的多分隔符解析等。
5. 总结
- RegexSerDe:适用于复杂和不规则数据格式,通过正则表达式解析数据。
- MultiDelimitSerDe:适用于格式固定且由特定分隔符分隔的数据,通过指定分隔符解析数据。
- SerDe2:Hive中的序列化/反序列化机制,负责将数据在存储格式和对象格式之间进行转换,提供了灵活的解析和序列化能力。















 4074
4074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









