






虚拟机环境准备
注意:复制新的虚拟机是要重新生成mac地址! 博主学习使用CentOS7
-
虚拟机网络配置
- 网关配置 vi /etc/sysconfig/network-scripts/ifcfg-ens33
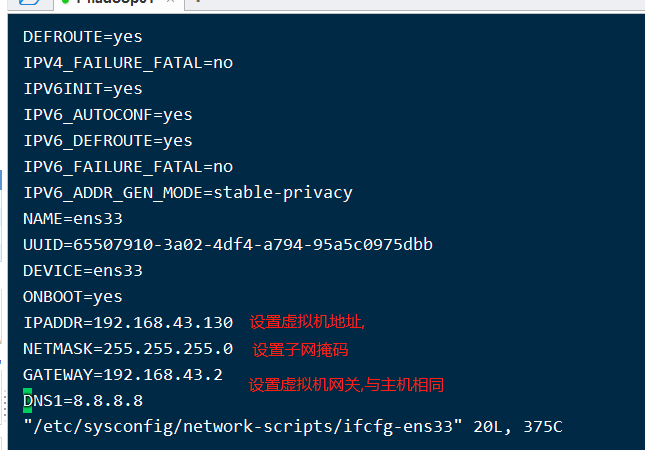
- wq命令保存后重启下(service network restart)
- 测试:查看本机ip命令:ip addr
- 测试:上网 命令:ping www.baidu.com
如果没有IP展示使用一下命令
service NetworkManager stop
chkconfig NetworkManager off 永久关闭 Manager网卡
service network restart 重启network网卡
-
修改主机名
vi /ect/sysconfig/network
HOSTNAME= hadoop01
或
hostnamectl set-hostname hadoop01
将主机与IP映射
vim /etc/hosts
添加IP 主机名,例如
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.43.130 hadoop01
保存重启
-
关闭防火墙
- 查看防火墙状态: systemctl status firewalld
- 查看防火墙是否开机自启动: systemctl is-enabled firewalld
- 关闭防火墙:
systemctl stop firewalld
systemctl stop firewalld.service
systemctl status firewalld
-
- 禁用防火墙自启动
systemctl disable firewalld
systemctl disable firewalld.service
systemctl is-enabled firewalld
-
配置新用户123的root权限
useradd 123
passwd root
重启生效
配置权限:vi /etc/sudoers
修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
123 ALL=(ALL) ALL
-
在/opt目录下创建文件夹
- 在/opt目录下创建module、software文件夹
/opt目录用来安装附加软件包,是用户级的程序目录
mkdir module
mkdir software
/usr:系统级的目录,比如C:/Windows/。
/usr/lib:比如C:/Windows/System32。
/usr/local:用户级的程序目录,比如C:/Progrem Files/。
用户自己编译的软件默认会安装到这个目录下
安装JDK
使用远程工具将JDK1.8导入software,解压到module
配置JDK环境变量
获取jdk路径: pwd
编辑/etc/profile文件
末尾添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
保存退出
让文件生效: source /etc/ profile
测试是否成功:java -version
Hadoop运行环境搭建
安装hadoop
将hadoop安装包导入software
解压至module
打开/etc/profile添加环境变量
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出
让修改文件生效:source /etc/profile
测试 :hadoop -version
安装JDK
使用远程工具将JDK1.8导入software,解压到module
配置JDK环境变量
获取jdk路径: pwd
编辑/etc/profile文件
末尾添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
保存退出
让文件生效: source /etc/ profile
测试是否成功:java -version
主机名和IP进行映射
将主机与IP映射
vim /etc/hosts
添加IP 主机名,例如
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.43.130 hadoop01
hadoop目录结构
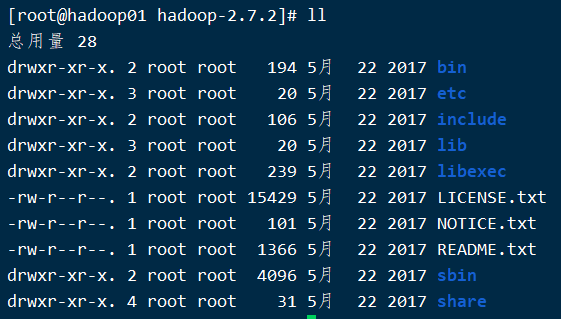
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
hadoop运行模式
运行模式
本地模式、伪分布式模式以及完全分布式模式。
伪分布式集群
- 配置集群
进入子目录 /opt/module/hadoop-2.7.2/etc/hadoop/
-
-
配置:hadoop-env.sh
-
修改JAVA_HOME和HADOOP_CONF_DIR
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HADOOP_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
保存退出,重新生效
source hadoop-env.sh
-
-
配置:core-site.xml
-
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
-
-
-
配置:hdfs-site.xml
-
-
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
-
启动集群测试
- 第一次启动时格式化,以后就不要总格式
- 进入hadoop根目录 执行 bin/hdfs namenode -format
- 启动NameNode
- sbin/hadoop-daemon.sh start namenode
- 启动DataNode
- sbin/hadoop-daemon.sh start datanode
- 查看集群
- 查看是否启动成功
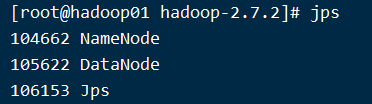
- web端查看HDFS文件系统
- http://hadoop01:50070/dfshealth.html#tab-overview
- 5007不能访问,问题处理
- https://blog.csdn.net/weixin_40814247/article/details/95115326
- 查看产生的Log日志
- 当前目录:/opt/module/hadoop-2.7.2/logs
- 注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。
配置集群在YARN上运行MR
配置 yarn-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置 yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
配置 mapred-env.sh
配置一下JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置 mapred-site.xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动集群
启动ResourceManager sbin/yarn-daemon.sh start resourcemanager
启动NodeManager sbin/yarn-daemon.sh start nodemanager
启动前必须保证NameNode和DataNode已经启动
YARN的浏览器页面查看
配置历史服务器
在mapred-site.xml文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
启动历史服务器:sbin/mr-jobhistory-daemon.sh start historyserver
查看历史服务器地址
http://hadoop101:19888/jobhistory
配置日志的聚集
日志聚集概念:将程序运行日志信息上传到HDFS系统上。
功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志,需要重新启动NodeManager 、ResourceManager和HistoryManager。
在yarn-site.xml文件里面增加如下配置。
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
查看日志
http://hadoop101:19888/jobhistory














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









