






首先,我们了解 Map , Set 以及 哈希表 是什么。
Map和set是一种专门用于进行搜索的容器或数据结构,其搜索的效率与其具体实例
化的类有关(适于动态查找)
模型:
一般把搜索的数据称为关建字(key),和关键值对应的称为值(value),将其称为 Key-Value 键值对
所有模型有两种
①纯key模型 :TreeSet (基于二叉搜索树),HashSet (基于哈希表)
eg:有一个字典,查一个单词是否在字典中。
⑫Key - Value模型: Tree Map(基于二叉搜索树), HashMap (基于哈希表)
eg 统计文章中对应词出现的词数 <词,对应次数>
Map 中存放Key-Value键值对, Set中只存放Key。
Map是一个接口,该类没有继承自Collection,存储<K,V>结构的键值对,且K唯一,不能重复。
Map 常用方法
V get (Object key) 返回 key对应的v
V get OrDefault (Object key, V default value) 若key存在,返回对应value。否则,返回默认值
V put (K key,Vvalue) 设置Key对应的value
V remove (object key) 删除key对应的映射关系
boolean containsKey (Object key) 判段是否含有 key
boolean containsValue (Object value) 判断是否含有 value
Set<k> keySet() 返回所有key的不重复集合。
Collection <V> values() 返回所有value的可重复集合
Set<Map. Entry<K,V>> entrySet() 返回所有 key-value 映射关系
需要注意的是:
①Map是一个接口,不可直接实例化,只实例其实现类 TreeMap or HashMap
② Map 中 key 唯一, value 可重复
③ TreeMap中插入键值对时, key不为空,否则的空针异,但由value 可为空。而 HashMap中 key 可以为 null,但只能放一个。
④ Map中的Key可以全部分离出来,存到set中进行访问(因为key不能重复)
⑤ Map中Value 存到Collection的任何一个集中(value可有重复)
⑥ Map中键值对的key不能直接改,若要改,只能先删,再重新插入
Map Entry<K,V> 是Map内部实现的用来存放键值对映射关系的内部类,其主
要提供了
K getKey ()
V getValues()
V setValue( V value)
并没有设置K的方法。
TreeMap 与 HashMap 的区别

Set 是继承自 Collection 的接口类,只能存key
常见方法
bodean add (E e) 添加,重复的不添
void clear() 清空Set
boolean contains (Object o) 判 o 是否存在
Iterator<E> iterator () 返回迭代器
boolean remove (Object o) 移除 o
int size() 返回存放的元素个数
boolean isEmpty() 判断是否为空
Object[ ] toArray() 以数组的形式返回
boolean containsAll (Collection <?> c) 判断集合 c 中的元素是否在 Set 中全部存在。若全存,返回 true。否则,返回 false。
boolean addAll(Collection<? extends E>C) 将集合 c 中的元素添加到 Set 中,由于 Set 中 key 不重复,所以可以实现去重的效果。
注:
1.Set是继承自Collation的一个接口类
2.Set 的底层使用 Map 实现,其使用Key与Object的一个默认对象作为键值对插入Map中
3.Set 最大功能——对集合元素去重
4.实现Set接的常用类有TreeSet, HashSet 还有LinkedHashSet.
LinkedHashSet 是在HashSet的基础上维护了一个双向链表来记录插入次序
6.Set的修改同Map
7.TreeSet中不存 为 null 的 key,而 HashSet中可以,但也只能存一个。
TreeSet 与 HashSet 的区别: 同TreeMap 与 HashMap的区别,只存在一点不同——HashSet 不一定有序。
哈希表 :不经比较,可以直接得到所要元素。它构造一种存储结构,通过函数使元素所在
位置与关键码能建立一一映射关系(就像水浒传中 角色的外号,一提到豹子头 就知道是林冲。)即哈希法又称(散列法)
常见哈希函数:
hash (key) = key % Capacity(数组长度)通过对 key 取余得到其对应的地址,放入其中。取出时, 在通过该函数得出地址直接取出,无需比较。
(碰撞)冲突:经哈函得相同地址。 具有不同关建码而且有相同哈地的元素,称为“同义词”。(冲突是不可避免)
减少或降低冲突的的方法主要有
设计合理的哈希函数
哈函设计原则:①定义域必须包括需存储的全部建码,而如果散列表有 m 个地址时,
其值域必须在0到m-1之间
②经计算所得地址均匀分布
③比较简单
常见哈函
①直接定制法(常用) 地址: Hash(Key)=A*Key + B
优点:简单,均匀
缺点:需事先知道关键字的分布情况
场景:适合查较小,连续的情况
②除留余数法-(常用) 地址: Hash(Key)=Key%P(P≤m)
m分散列表中允许的地址数,P为 <= m 且最接近或等于m的质数
③平方取中法④折叠法⑤随机数作地址 ⑥数学方法
注:哈函越精密,产生活中可能性越小,但无法避免
调节负载因子
负载因子 = 元素个数 / 哈表长度 这个值一般要求 <= 0.75
通过哈表长度调节负载因子
闭散列也叫开放址法 当冲突时,若表未满则存在“下一个空位置
1.线性探测,从冲突位向后探测,直到寻找到下一个空位置
采用闭散列处理冲突时,不能随便物理删除已有元素,会影响其他元素
的搜索。因此线探采用标计的伪删除法来删除一个元素
2.二次探测:
hi=(h(key)+c1*i+c2*i^2)%m。这里c1和c2是常数,i是探测次数。与线性探测法不同,二次探测法以二次函数的方式来确定下一个探测位置,这样可以减少聚集现象,使元素在哈希表中分布得更均匀。例如,取c1=1,c2=1,h(key)=3,m=11,第一次冲突时i=1,则h1=(3+1×1+1×12)%11=5,即探测位置5。
闲散列最大缺陷空间利用率低,这也是哈希的缺陷。
开散列 一个地址对应一个单链表
如图所示:
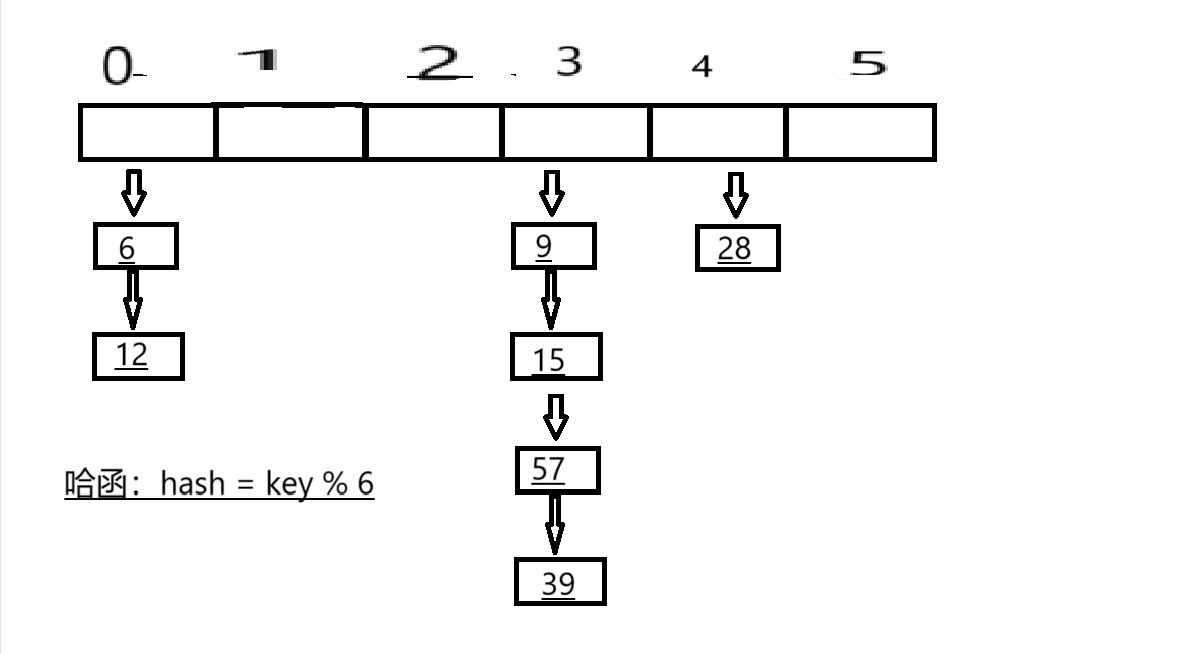
通常认为哈希表的插/删/查的时复为O(1)
使用示例:
package bit_0719;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class T1_0410 {
public static void main(String[] args) {
// HashMap示例
Map<String, Integer> hashMap = new HashMap<>();
// 添加元素
// put(K key, V value): 将指定键值对存入HashMap
// 如果键已存在,则替换对应的值
hashMap.put("Apple", 10);
hashMap.put("Banana", 5);
hashMap.put("Orange", 8);
// 获取元素
// get(Object key): 返回指定键所映射的值,如果键不存在则返回null
System.out.println("Apple的数量: " + hashMap.get("Apple"));
// 判断键是否存在
// containsKey(Object key): 检查HashMap中是否包含指定的键
System.out.println("包含Banana: " + hashMap.containsKey("Banana"));
// 删除元素
// remove(Object key): 删除指定键对应的键值对
hashMap.remove("Orange");
// 遍历HashMap
// entrySet(): 返回HashMap中所有键值对的Set集合
System.out.println("\nHashMap内容:");
for (Map.Entry<String, Integer> entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 获取HashMap大小
// size(): 返回HashMap中键值对的数量
System.out.println("\nHashMap大小: " + hashMap.size());
// 批量添加元素
// putAll(Map<? extends K, ? extends V> m): 将指定Map中的所有键值对复制到此HashMap中
Map<String, Integer> moreFruits = new HashMap<>();
moreFruits.put("Grape", 15);
moreFruits.put("Peach", 7);
hashMap.putAll(moreFruits);
System.out.println("\n批量添加后的HashMap:");
hashMap.forEach((k,v) -> System.out.println(k + ": " + v));
// 清空HashMap
// clear(): 移除HashMap中所有键值对
hashMap.clear();
System.out.println("\n清空后的HashMap大小: " + hashMap.size());
// HashSet示例
Set<String> hashSet = new HashSet<>();
// 添加元素
// add(E e): 将指定元素添加到HashSet中,如果元素已存在则返回false
hashSet.add("Red");
hashSet.add("Green");
hashSet.add("Blue");
// 判断元素是否存在
// contains(Object o): 检查HashSet中是否包含指定元素
System.out.println("\n包含Green: " + hashSet.contains("Green"));
// 删除元素
// remove(Object o): 从HashSet中移除指定元素
hashSet.remove("Blue");
// 遍历HashSet
System.out.println("\nHashSet内容:");
for (String color : hashSet) {
System.out.println(color);
}
// 获取HashSet大小
// size(): 返回HashSet中元素的数量
System.out.println("\nHashSet大小: " + hashSet.size());
// 批量添加元素
// addAll(Collection<? extends E> c): 将指定集合中的所有元素添加到HashSet中
Set<String> moreColors = new HashSet<>();
moreColors.add("Yellow");
moreColors.add("Purple");
hashSet.addAll(moreColors);
System.out.println("\n批量添加后的HashSet:");
hashSet.forEach(System.out::println);
// 清空HashSet
// clear(): 移除HashSet中所有元素
hashSet.clear();
System.out.println("\n清空后的HashSet大小: " + hashMap.size());
// 测试更多Map方法
hashMap.put("Apple", 10);
hashMap.put("Banana", 5);
// getOrDefault(Object key, V defaultValue): 获取指定键对应的值,如果键不存在则返回默认值
System.out.println("\n测试getOrDefault: " + hashMap.getOrDefault("Pear", 0));
// containsValue(Object value): 检查HashMap中是否包含指定的值
System.out.println("测试containsValue: " + hashMap.containsValue(5));
// keySet(): 返回HashMap中所有键的Set集合
System.out.println("\n所有key: " + hashMap.keySet());
// values(): 返回HashMap中所有值的Collection集合
System.out.println("所有value: " + hashMap.values());
// entrySet(): 返回HashMap中所有键值对的Set集合
System.out.println("所有entry: " + hashMap.entrySet());
// 测试更多Set方法
hashSet.add("Red");
hashSet.add("Green");
// iterator(): 返回此集合中元素的迭代器
System.out.println("\nSet迭代器测试:");
Iterator<String> it = hashSet.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
// toArray(): 返回包含此集合中所有元素的数组
System.out.println("\nSet转数组: " + Arrays.toString(hashSet.toArray()));
Set<String> testSet = new HashSet<>();
testSet.add("Red");
testSet.add("Blue");
// containsAll(Collection<?> c): 检查HashSet是否包含指定集合中的所有元素
System.out.println("测试containsAll: " + hashSet.containsAll(testSet));
// isEmpty(): 检查HashSet是否为空
System.out.println("测试isEmpty: " + hashSet.isEmpty());
}
}运行结果:
Apple的数量: 10
包含Banana: trueHashMap内容:
Apple: 10
Banana: 5HashMap大小: 2
批量添加后的HashMap:
Apple: 10
Grape: 15
Peach: 7
Banana: 5清空后的HashMap大小: 0
包含Green: true
HashSet内容:
Red
GreenHashSet大小: 2
批量添加后的HashSet:
Red
Yellow
Purple
Green清空后的HashSet大小: 0
测试getOrDefault: 0
测试containsValue: true所有key: [Apple, Banana]
所有value: [10, 5]
所有entry: [Apple=10, Banana=5]Set迭代器测试:
Red
GreenSet转数组: [Red, Green]
测试containsAll: false
测试isEmpty: false


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









