









FlowRadar: A Better NetFlow for Data Centers(NSDI 2016)
摘要
NetFlow:数据交换方式,在各种应用中广泛使用,在一个hash表中维持一个活跃的流工作集来支持流插入、冲突解决以及流移除。但是,在商业数据中心交换机中很难实现,因为在商业数据中心中每个数据包的处理时间是有限的。因此,许多NetFlow以及其他的监控方法不得不简化或者选择一个数据包流的子集进行监控。本文中,观察监控所有流的需要,因此设计了FlowRadar,这是一个新的方法来维持流和它们的计数器。关键思想是:在拥有小内存和恒定插入时间的交换机内为每个流计数器编码,然后利用远端选择器的计算能力来实现网络范围的解码并分析流计数器。我们的评估展示了FlowRadar的内存使用与传统的使用hash表的NetFlow相近。使用FlowRadar,运营商可以更好地查看他们的网络,使用我们搭建在FlowRadar上的两个新的监控器应用。
1 介绍
NetFlow是一个广泛使用的监控工具,已经使用了超过20年,记录了流的信息(源IP,目的IP,源端口,目的端口,协议)和它们的特征(数据包数量,流开始/结束时间)。当一个流在截止时间前结束时,NetFlow将相应的流记录信息发送给远端选择器。NetFlow正在给不同的监控应用使用,例如核算网络使用量、容量计划、发现故障、入侵检测等。
尽管广泛使用,将NetFlow运用到硬件中的一个关键问题是如何在较短时间和有限的容量下使用一个数据结构来维持流的工作集。我们需要在流插入和移除旧的流时解决冲突。这个任务若考虑有限的单个数据包处理时间,在工业上是比较困难的。
为了解决这个难题,现今的NetFlow使用两个方法:(1)使用复杂的自定义芯片,这些芯片只有高档的路由器可以使用,这对于数据中心而言太昂贵了;(2)使用软件计算来自硬件的简单数据包,但是这将会花费交换机上大量的CPU资源。因为在数据中心缺少可用的NetFlow,运营商不得不基于采样或者匹配规则将数据包镜像到远程选择器,来分析数据包。但是镜像所有的数据包是不可能的,因为它花费了大量的带宽,以及选择器的存储和计算资源来分析每个数据包。
但是,在数据中心,越来越需要在所有时间对所有流的可见性。我们需要覆盖所有的流来抓取这个瞬间的环、黑洞以及交换差错,这些仅仅在网络中的几个流中出现,并且在流量分析上是很精细地信息(例如异常检测)。我们需要在所有的时间及时地覆盖这些流来辨别瞬间的丢包、暴发以及攻击。
本文中,我们提出了FlowRadar,它使用很少的内存为所有的流技术,并在很短的时间内(10ms)将流计数器发出。FlowRadar设计的关键是在廉价交换机上有限单数据包处理时间和远程选择器上CPU资源利用中权衡。我们介绍一个编码流程集,这个流程集主需要对每个数据包恒定时间的指挥,因此可以简单地部署在工业界的廉价交换机上。我们然后在远程选择器上解码这些流程集并且提供一个网络范围的分析,针对所有时间和交换机。我们使用下面的一些关键部署在FlowRadar上:
在交换机上为每个数据包设定恒定的时间,抓取编码的流计数器:我们介绍一个编码流程集,是一系列单元格,可以为流(五元组)和它们的计数器编码。编码流程集确保每个数据包的处理时间恒定,通过接收而不是处理哈希冲突。它将一个流对应到许多单元格中,允许流在一个单元格中产生碰撞,但是确保每个单元格有恒定的内存使用率。因为编码流程集很小,我们可以周期性地将整个流程集发送给选择器,在较短时间内。我们编码流程集的数据结构是Invertible Bloom filter Lookup Table(IBLT)的扩展,但是提供了更好的对计数更新的支持。
在远端选择器上对网络范围的解码和分析:当每个交换机单独地对流和计数器编码时,我们发现大部分流穿过了不止一个交换机。通过利用流经交换机的冗余性,我们将编码流程集设计地更加复杂。我们接下来使用一个网络范围的解码工具来解码流经交换机的流和计数器。通过网络范围的解码,我们的编码流程集可以将需要的内存占用减少(每记录100K流)5.6%与一个NetFlow的理想(当然也不现实)实施(使用perfect hashing,即没有碰撞)相比,同时解码成功率有99%。
FlowRadar可以支持广泛范围的应用监控,包括NetFlow可以支持的应用以及一些新的需要在所有时间监控所有流的应用。我们在FlowRadar中设计了两个系统:一个通过网络范围的流分析来检测瞬时的流和黑洞,另一个使用时序分析提供了对于每个流的丢失率。
2 动力
本节中,我们讨论了在NetFlow中部署实施的关键挑战,然后描述了三个可用的监控解决方案:NetFlow在高档路由器中使用自定义的芯片,NetFlow在廉价交换机中的工业芯片以及可选择的镜像。为了解决这些方法的限制,我们提出了FlowRadar架构,整个架构描述了一个很好的在交换机和远程选择器的很好地选择。
2.1 支持NetFlow的关键挑战
NetFlow已经使用超过20年了,针对NetFlow的路由器和交换机的改进和扩展有很多。我们在这里没有说明关于NetFlow的所有解决方案,我们关注NetFlow的基本功能:存储流表域(五元组)和在一个hash表中的记录(例如数据包数量、流开始/结束时间、流持续时间等)。关键挑战就是如何维持一个活跃的hash表中的流,在给定的有限的数据包处理时间内。
维持流的活跃的工作集:有两个关键任务:
(1)如何在流插入的过程中处理哈希冲突:当我们插入一个新的流时,可能与现存的流产生冲突,我们的解决方案是在每个hash表的每个单元格中存储多个流,来减少溢出的可能性(如,d-left hashing),这就需要原子多字节存储器访问。另一个解决方案是将现存的流移走来腾出位置给新的流(例如Cuckoo hashing),这就需要在最差情况下对每个数据包的多个非常量内存访问。每个都非常具有挑战性,在具有高流量的工业芯片上。
(2)如何去除一个之前的流:我们需要周期性地将之前的流去除从而在hash表中腾出位置给新的流。如果一个TCP流获得了一个FIN,我们可以将这个流从hash表中移除。但是,在数据中心中,有很多稳定的链接被多次使用。为了辨别闲置的流,NetFlow记录了一个流最后被看到的时间,并且周期性地扫描整个hash表来检查每个流的不活跃时间。如果一个流是不活跃的持续时间已经超过了时间限制,NetFlow就将这个流移除,并且发送给它的计数器。这个不活跃时间限制仅可以被设置在10到600s之间,默认是15s。当hash表很大时,将会花费一定时间和交换机的CPU资源来扫描该hash表和清理表条目。
在工业芯片中有限的单个数据包的处理时间:在一个工业芯片(数据中心的商用交换机)中维持一个活跃的工作集是困难的,关键的限制是在工业芯片中我们可以在每个数据包上花费的时间是有限的。假设一个交换机每个端口是40Gps,这意味着12ns处理每个64Byte的数据包(当到100Gbps时,情况更加糟糕)。让我们假设,通过执行完美的数据包管道,并将所有其他的数据包处理功能(数据包头解析、第2/3层转发、ACL等)分配给其他阶段,那么整个12ns都可以专门给NetFlow使用。但是,在NetFlow内部,需要计算hash值,寻找SRAM,运行一些ALU操作,再写回SRAM。甚至是片状的SRAM(大概1ns的访问时间,再12ns内完成整个操作仍然很困难。
2.2 可选择的监控解决方案
因为在工业芯片中,处理每个数据包的时间是有限的,因此不能实现复杂的过程,和NetFlow要求的不恒定时间的插入和删除操作,因此有以下三个选择:

在自定义芯片中的基于硬件的NetFlow:一个解决方案是,设计一个在交换机硬件中设计一个自定义的芯片来为流维持一个活跃的工作集。我们可以在静态随机存储器(SRAM)的芯片上缓存大众的流条目,而其他的就缓存在静态随机存储器(SRAM)或动态随机存储器(DRAM)的芯片外。我们还可以将SRAM与昂贵的需要消耗能量的TCAM(三态内容寻址存储器)相结合来支持平行的查询。甚至是昂贵的自定义芯片,Cisco高档路由器的测试展现了仍然有大约16%的交换机CPU负载来在硬件中存储65K的流条目。Cisco高度推荐NetFlow用户选择采样来减少NetFlow在这些路由器上的负载。
在工业芯片中的基于软件采样的NetFlow:另一个解决方案是采样数据包并将它们镜像到交换机软件中,在软件中维持一个活跃的流表工作集。这个方法在便宜的工业芯片中可以适用,但是比在高档路由器中基于硬件的NetFlow占用了更多的CPU负载。为了减少交换机CPU负载,并避免打断其他进程(例如,OSPF、规则更新等),操作者不得不将采样率设置地尽量低(低到在4K数据中采样1个)。在如此低的采样率下,操作者不能使用NetFlow运行细粒度的流量分析(例如异常检测)或者抓取只发生在一些流上面的事件(例如瞬时的loops或者blackholes)。
可选择的镜像(sFlow,EverFlow):最后一个解决方案中,现在的数据中心运行商仅仅基于规则匹配来采样数据包或选择数据包,然后将这些数据包镜像到远程选择器中。远程选择器提取出每个流的信息,并进行细节分析。这个解决方案在现在的工业芯片中可以使用,在云中使用资源的效果最佳。但是,着花费了很多的带宽来将所有的数据包转发给收集者,在收集者端将会产生太多的容量和计算负载。因此,运营商仅仅可以看到被选数据包的一部分信息。
2.3 FlowRadar架构
不是像现有的监控方案那样求助于采样,我们旨在为所有时间的所有流提供完整的可视化。为了实现这个,我们打算在交换机的工业芯片和远程选择器的计算能耗上最佳使用容量。
在交换机上抓取编码的流计数器:FlowRadar选择将流和它们的计数器编码在一个固定的小尺寸内存的可以部署在有恒定流插入时间的工业芯片内。在各种方法上,我们可以不采样就抓取所有的流,并且定期地将这些编码后的流计数器发送到远程选择器,在一个很短的时间内。
在远程选择器上解码和分析流计数器:假设一个编码的流和计数器从许多交换机中输出,我们可以使用远程收集器的计算能力来解码这些流,并为不同的监控应用程序提供流空间分析。
3 使用案例
因为FlowRadar为每个流提供了计数器,可以轻松地集成NetFlow上运行的监控应用,例如审计、容量规划、应用监控、性能分析和安全分析。本节中,我们展示了FlowRadar提供了良好的监控支持,较基于采样的NetFlow和sFlow/EverFlow而言,在两个方面:(1)流覆盖率:没有使用采样,计算所有的流;(2)暂时的覆盖率:每个很短的时间间隔(10ms)将这些计数器输出。
3.1 流覆盖率
瞬时loop/blackhole检测:瞬时loop和blackholes对于检测是很重要的,因为它们将会导致数据包的丢失。只有很少的数据包丢失也会导致严重的尾延迟增加和吞吐量降低(特别是由于TCP丢失导致的拥塞),导致违反SLAs(服务等级协议)甚至是收益的降低。但是瞬时回路和blackholes很难检测,因为它们仅在一个很短的时间间隔内影响一些数据包。EverFlow和采样的NetFlow只选择一些数据包去监控,因此可能缺失了大部分的瞬时回路和blackholes。另外,瞬时回路和blackholes将仅仅影响某一种类的流,因此向Pingmesh之类的探测方法可能甚至不能注意到它们的存在。相反,如果我们可以在每个流中捕捉所有的数据包,并且在每个交换机内实时维持一个相应得计数器,我们可以快速识别出那些正在经历loops或者blackholes的数据流。
在匹配-行为表中的错误:交换机通常为数据包处理维持一个匹配-行为表的管道。数据中心已经报告了表格损坏,当交换机内存经历一些软错误(即,bit flips),这些损坏可以导致数据包丢失或者是在流量中小概率的不正确的转发。这样的损坏很难发现,因为它们不能看到真实的损坏的表。它们也很难被采样的NetFlow或EverFlow检测到,因为我们不能提前决定正确的需要监控的数据包。相反,因为FlowRadar可以监控所有的数据包,我们可以在问题发生时就发现问题。
精细粒度的流量分析:先前的研究已经展示了数据包采样对于许多要求精细力度的监控任务(例如理解流大小的分布和异常检测)是不够的。因为FlowRadar监控所有的数据包,我们可以提供更多的精确的流量分析和异常检测。
3.2 暂时的覆盖率
每个流的缺失率:数据包丢失可能由很多原因引起(例如拥塞,交换机端口出错,数据包碰撞等),并且可能给应用带来很大的影响。尽管每个TCP连接可以检测自身的丢失(使用序列号或者基于交换机支持),对于操作者去理解在网络的哪个地方发生了丢失,以及多少流/应用被这个丢失所影响,以及随着时间丢失率如何变化,是很难的。有较低采样率的NetFlow不能捕获到没有被采样的数据中的丢失情况,甚至对于那些已经采样的流,我们也不能从估计的流计数来推测丢失。EverFlow可以仅捕获控制数据包(例如NACK:否定应答)来推测丢失和拥塞状况。相反,如果我们可以在交换机上实施FlowRadar,我们可以直接获得一个对于所有流的每条流的丢失率,在数据包流经后立即发生。
调试ECMP负载失衡:ECMP(等价路由)负载失衡可能导致网络中带宽的不充分利用,可能导致应用性能的严重丢失。短暂的负载失衡可能由以下引起:(1)网络(例如ECMP没有hash到正确的流表上)(2)应用(例如应用产生了一个突然的burst)。如果操作者可以快速地辨别出以上两种原因,他们就可以做出快速反应来为网络重新配置ECMP功能或是限制那个特定的应用的速率。EverFlow可以诊断一些负载失衡问题,通过镜像所有的SYN和FIN数据包,并且记录每个ECMP路径上的流量数量。但是,这不能诊断是上述那个原因,因为没有每个流具体的数据包计数器信息,也不知道流量随时间的改变,传统的NetFlow有类似的限制(即,没有随着时间记录流)。
及时的攻击检测:一些攻击显示了特定的短暂的流量模式,这些模式很难被检测到,如果我们仅仅像NetFlow那样记录每个流的数据包数量,或者像EverFlow那样仅仅捕捉SYN/FIN数据包。例如,TCP低速率攻击发送一系列的小流量突发事件,这些突发事件总是触发TCPS重新传输超时,从而将TCP流限制为理想速率的一小部分。在较短时间间隔内每个流的计数器可以使我们通过瞬时分析检测到这些攻击,也可以快速地报告这些攻击(不用等待像NetFlow那样的非活跃超时)。
4 FlowRadar设计
FlowRadar的关键设计是一个对于存储的流和他们的计数器的一个编码系统,在一个固定大小的较小的内存中,这需要交换机上恒定的插入时间,以及一个可以被远程连接器快速解码的策略。当发生突发流时,我们可以使用网络范围的编码来从许多编码流程集中将这些流解码。我们还可以在内存使用和解码成功率上权衡。
4.1 编码流程集
对于NetFlow的关键挑战是,如何解决流冲突。我们的解决方案关注如何拥抱碰撞(embrace collisions)而不是对流碰撞作出反应。我们允许流碰撞,在没有增加内存使用率的情况下,同时确保我们可以在收集器解码单独的流和它们的计数器。
有两个设计的关键来允许我们embrace collisions:(1)首先我们将相同的流hash到多个地点(就像Bloom filters)。在这种方法下,一个流在一个bins中产生碰撞的几率减小了。(2)当多个流在同一个单元格中时,在一个链表中存储它们是昂贵的。相反,而我们使用一个XOR方法来操作这些流中的数据包,并且没有使用额外的bit。在这个方法下,FlowRadar可以工作在一个固定大小的内存内,并且可以与许多流共享,对于所有流有恒定的更新和插入时间。
基于这两个设计,编码流程集数据结构如图2所示:包括了两个部分,其一是flow filter:仅仅是一个普通的Bloom filter,有列0和列1,用来测试一个新的数据包是否属于一个新的流。第二部分时counting table,被用来存储流计数器,这个counting table包括以下方面:flowxor(所有流的五元组的XOR)、flowcount(流的数量)、packetcount(所有流的数据包数量)。

就像算法1中,当一个数据包到来时,我们首先提取数据包的flow fields,同时检查flow fliter来查看是否这个流已经被存储在flowset中,如果一个数据包来自一个新的流,我们要更新counting table,相应增加Flowxor、Flowcount、Packetcount。如果一个数据包来自已存在的流,我们仅增加Packetcount。

每个交换机每若干毫秒将流程集发送给收集器,我们将这个时间称为time slots,在本文的剩余部分,我们将time slots设置为10ms,除非有特殊说明是其他值。
当FlowRadar收集器接收到一个编码流程集,它可以为每个流计数器解码,一旦看到只有一个流的单元格时(称作pure cell)。对于一个pure cell中的每个流,我们使用相同的hash函数来定位这个流的其他单元格,并且将它从其他单元格中移除(通过使用FlowXOR来xor,减少数据包数量,缩减流数量)。我们然后寻找其他的pure cells,然后在每个pure cells上进行相同的操作。这个过程当没有pure cells时停止,具体是算法3。

4.2 网络范围的解码
操作者可以基于流的期望值配置编码流量集的大小。但是,根据流的数量可能有一个突发流量。这种情况下,我们可能有一些流不能解码,当我们在一个SingleDecode过程中没有任何单元格可以使用时,为了解决一个流的突发,我们建议一个网络范围的解码系统,可以关联多重的编码流程集,在不同的交换机上。我们的网络范围的解码过程有两步:解码交换机的流,以及在单个交换机中解码流数量。
解码交换机的流:关键的是:如果我们使用不同的hash功能,在不同的交换机上,如果我们不能在一个编码流程集上解码一个流,很有可能我们能在另一个编码流程集上解码成功。例如,假设我们在两个相邻的交换机A1和A2上收集流程集,我们知道来自A1和A2的流有相同的子集。这些流有可能被单独解码到A1而不是A2,如果它们匹配了A2的flow filter,我们可以将这些流从A2移除后,这可能带来更多的单个流的单元格。我们可以在A2上再次运行SingleDecode算法。

整个过程就像算法2描述的那样,假设我们有N个编码流程集:A1……AN,从SingleDecode S1……SN获得相关的流的集合。对于任意两个相邻的Ai和Aj,我们检查可以从Ai但不能从Aj获得的所有流(例如Si-Sj)来查看它是否还出现在Aj中。我们接下来再对所有的流程集在进行SingleDecode,得到新的组S1……SN,然后继续检查相邻的一对对。我们重复整个过程直到不能再解码更多的流。
需要注意的是,如果我们有每个数据包的路由信息,FlowDecode可以加速,因为对于一个在Ai的解码流,我们进检查Ai先前的hup和之后的hup,而不是所有的neighbor。
在单个交换机的计数器解码:尽管我们可以轻松地使用FlowDecode解码流,我们不能解码它们的计数器。这是因为A和B对于同一个流的计数器可能不相同,因为数据包会丢失和正在运行中的数据包(例如,在A中输出队列的数据包)。幸运的是,在FlowDecode进程中,我们可能已经直到在一个编码流程集的所有流。就是说,在每个单元格中,我们知道在一个单元格中的所有六和这些流的计数器的总和。一般情况下,我们知道CountTable[i].PacketCount=![]() 假设流程集有mc个单元格和n条流,我们有mc个等式和n个变量,这意味着,我们需要解决MX=b,X是n个变量的矩阵,M和b来自上面的等式。我们在算法4中展示了结构M和b。
假设流程集有mc个单元格和n条流,我们有mc个等式和n个变量,这意味着,我们需要解决MX=b,X是n个变量的矩阵,M和b来自上面的等式。我们在算法4中展示了结构M和b。

解决一大组稀疏线性方程组是困难的。使用Matlab中最快的解数程序lsqr(正交分解最小二乘法)(基于迭代),需要花费超过1min来获得计数器,对于100K的流。我们在两个方面加速计算:(1)我们提供了一个对于计数器的近似求解,所以解决者可以从一个大约的数目开始,从而更快地接近最终结果。因为对于相同的流量,计数器在跳跃中变化很近,我们可以在FlowDecode过程中获得近似的计数器。就是说,当使用Aj的流解码Ai时(算法2,7-21行),我们在一个相同的流中将Ai中的计数器视为Aj中的计数器。我们需要给初始值一个大约的计数来开始迭代,从而可以汇聚得快一些。(2)我们为迭代器使用一个宽松的停止准则,因为计数器通常是一个整数,只要当结果现在一个整数上下浮动在0.5以内时,就停止迭代器。这明显地减少了迭代的次数。通过这两种加速,我们减少了计算时间,大约70倍。
4.3 解码错误分析
SingleDecode:我们现在对编码流程集做一个关于出错率的形式化分析。假设流过滤器使用kf个hash函数和mf个单元格,计数表格有kc个hash函数和mc个单元格,每个单元格有sc个bit。所以总的内存使用是mc*sc+mf。假设有n个流在编码流程集中,对于flow filter,对于一个single new flow(即,一个新的流被认为是已存在的流)的flase positive是![]() 。因此,n个流中没有一个经历false positives的可能性是
。因此,n个流中没有一个经历false positives的可能性是![]() 。当flow filter有一个false positive时,我们可以通过检查在解码后是否有non-zero PacketCounts来探测它。在这种情况下,这个计数器是不可信的,但我们仍然获得所有的流。
。当flow filter有一个false positive时,我们可以通过检查在解码后是否有non-zero PacketCounts来探测它。在这种情况下,这个计数器是不可信的,但我们仍然获得所有的流。
对于计数表,SingleDecode的解码成功率(即,我们可以解码所有流的可能性)被证明是大于![]() ,如果mc>ckcn,ckc是一个与kc有关的常数。当我们没能将计数表中的一些流解码时,已经解码的流和它们的计数时正确的。
,如果mc>ckcn,ckc是一个与kc有关的常数。当我们没能将计数表中的一些流解码时,已经解码的流和它们的计数时正确的。
我们选择使用分离的流过滤器和计数表,而不是一个整合的(即,计数表同样也是一个bloom filter来测试一个新的流),因为一个整合的将会花费更多的内存。对于一个整合的,对于每个数据包,我们检查hash到的kc单元格,并且当且仅当这kc个单元格的FlowCount是0是,才将它视为一个新的流。但是,这个解决方案需要比分离的方案更多的内存。因为对于计数表,一个好的参数设置是:kc=3,mc=1.24n,当n大于10K,基于我们的实验。在这样的一个参数设置下,当我们将计数表当作bloom filter,the false positive rate对于新的流是![]() ,大于99.9%。为了使false positive rate对于所有n个流足够低,我们应当增加kc和mc。
,大于99.9%。为了使false positive rate对于所有n个流足够低,我们应当增加kc和mc。
NetDecode:我们分开讨论FlowDecode 和CounterDecode。对于FlowDecode,我们首先考虑一个简单地pair-decode情形,我们在一系列相同的流上的两个端点间运行NetDecode。这可以被视作是在一个有2kc个hash函数和2mc个单元格的计数表中解码n个流。这意味着我们将仅仅需要单元格的一般,使用SingleDecode。在我们的实验中,我们仅仅需要mc=8K,解码10K的在两端都出现的流,这甚至比流的数量还少。
对于更加普遍的网络范围的FlowDecode,如果在网络中有比期望更多的以及比FlowDecode需要的更多的流,解码成功率就与pair-decode情形下类似。这是因为对于每个节点A,解码它的流与解码A的流程集对和从包括A流的所有邻居是相似的。但是,更有可能的是只有一个位置的节点有比期望更多的流,其余的可以SingleDecode。在这种情形下,解码成功率比pair-decode高。
对于CounterDecode,我们需要至少与变量(每个流计数器)数量相等的线性等式,因为我们对于每个单元格有一个等式,我们需要单元格的数量mc,来作为变量n最小值。事实上,mc应当稍微比n大,来维持一个高可能性的拥有n个无依赖性的线性等式。
完整的NetDecode过程被CounterDecode而不是FlowDecode瓶颈住,因为CounterDecode需要更多的内存和时间来解码。因为CounterDecode仅能在一个节点上运行,内存使用率和NetDecode在一个节点上的解码速度绝大部分依赖于它自己解码流程集的流的数目,而不是含有相似流的其他流程集的数目。
5 评估
我们描述了FlowRadar可以扩展到许多流和被内存、带宽、计算负载限制的大型网络中,通过模拟FatTree拓扑结构。
5.1 扩展到许多流
参数设置:我们使用FatTree模拟一个网络,其中k=8(共80个交换机)。我们将每个交换机中流的数量设置在10ms内1k到1000k。我们在每队interPod ToR中形成相等数量的流。然后将这些流平分到ECMP路径中。在这个方法上,每个交换机有相同数量的流。我们设置flow filter来确保n条流中的一个流经历一个false positive的可能性是1/10对于SingleDecode失败率。我们设置最佳的kf和mf根据4.3节中的公式。我们将kc设置为4,因为这是对于NetDecode最好的。我们基于指导书选择mc。我们根据流的期望数值设置FlowCounter的大小。我们保守地将NetFlow和FlowRadar的包计数器设置为4Byte,尽管在FlowRadar中,我们在很短时间内收集数据,并且因此可以看到更少的数据包,需要更少的byte提供给数据包计数器。因为我们的结果仅仅与流的数量相关,而与数据包无关,我们生成一个随机的流序列作为输入。
我们在3.6GHz的CPU上运行了解码,并且在多核的不同的流程集上并行运行。
FlowRadar的内存使用与NetFlow接近,如果使用一个完美hash表的话:我们首先对比NetFlow和FlowRadar的内存使用,就像在第2节中描述的那样,在一个工业芯片中(有单数据包处理时间限制)使用基于hash的方法来进行流插入与冲突处理。如果我们运行一个简单的hash表,它将占用8.5T来存储100K的流,来确保99%情况下没有冲突发生。在一个自定义的芯片中的真实的数据结构可能是专用信息。因此,我们与对于NetFlow的最好的可能性(使用一个没有冲突的完美的hash表)对比。
尽管使用一个完美的hash表,NetFlow将需要在每个单元格中存储一个流的开始时间和上一次在一个非活跃的时间内(每4Byte)被看到的时间。但是,在FlowRadar中,我们不需要在硬件中维持一个时间戳,因为我们频繁地向远端收集器报告信息。为了完全地去耦合FlowRadar数据结构的优势和移除时间戳,我们还与没有时间戳的完美hash函数对比,这可以被认为是我们可以达到的最好的效果。
图3显示了NetFlow在每个交换机上使用2.5MB的hash表的情况。FlowRadar仅需要2.88MB/交换机用来SingleDecode,2.36MB/交换机用来NetDecode,;来存储100K的流,有99%的解码成功率,这分别比NetFlow高了15.2%和低了5.6%。最好的可能的内存使用是不用时间戳的完美hash表,有1.7MB。对于1M的流,我们需要29.7MB/交换机用来SingleDecode,24.8MB/交换机用来NetDecode,比使用完美hash和时间戳的NetFlow高了18.8%和低了0.8%。
FlowRadar仅仅需要一个小的带宽占用来每10ms发送编码流程集:图4显示了我们只需要2.3Gbps每个交换机来在10ms内为100K的流发送编码数据集,在100ms内是0.23Gbps。在facebook的网络中,一个交换机连接了100台有10Gbps的主机,每个主机发送最多100s到1000s的实时流量在5ms内。假设10ms内交换机中总共有2K*44条流量,FlowRadar进占用0.52%的带宽。
使用NetDecode的FlowRadae可以支持比SingleDecode更多的26.6%-30%的流,在更多的解码时间下:操作者可以基于期望的流数量来配置FlowRadar,当流的数量超过了期望的数量,我们可以使用NetDecode来解码更多的流,在相同的内存下。图5显示了在1K和1M的期望流数量下,NetDecode可以解码26.6%-30%更多的流比SingleDecode,所以我们的解决方案可以解决流数量的突发情况。
图6显示了每个流程集的平均解码时间,在100K的期望流下。当流量低于100K个流时,收集者可以使用SingleDecode来在10ms内快速甄别所有的流。当流量高于100K时,我们需要NetDecode,使用283ms和3275ms来解码分别是101K和126.8K的流程集。
我们将NetDecode的时间划分到CounterDecode和FlowDecode,结果像图7显示的那样,随着流数量的增加,CounterDecode时间也快速增加,但是FlowDecode的时间仍然很少。如果我们仅仅需要解码流,我们仅需要135ms,这对于CounterDecode的3140ms已经相当小了。需要注意的是,流的突发状况并不常见,所以等待额外的时间来获得解码流和计数器是可以的。
我们并不依赖路由信息来减少NetDecode时间,因为这仅仅只能帮助减少FlowDecode时间,这本来就占用NetDecode的很少一部分,路由信息可以帮助减少FlowDecode时间两倍。
5.2 扩展到更多的交换机
我们现在研究如何将FlowRadar扩展到更大的网络空间,作为最直接的比较,我们假设在不同网络大小的每个交换机内有相同大小的流。
当有更多交换机时,内存和带宽使用没有增加:这是因为解码成功率至于流的数量和单元格的数量有关,显然,这对于SingleDecode是正确的,对于NetDecode也是正确的,因为只要所有的流出现在至少2个流程集中,NetDecode的解码率与之类似,不管该流出现在多少流程集中。原因是流的数量的瓶颈可以从CounterDecode被解码,这与其他的流程集无关。对于有102.5K单元格的流程集,两个这样的流程集已经可以解码超过110K的流,但是CounterDecode尽可以支持100K的流(被线性无关方程所限制)。
解码需要成比例的更多的核以及更多的交换机:每个交换机的SingleDecode时间仅与一个流程集中流的数量有关。例如,为了在10ms内解码100K的流,我们需要在远端收集器有与交换机相同数量的核。这就意味着,对于一个有27K个服务器(K=48FatTree)以及每个服务器有16个核的网络,我们需要大约0.65%的服务器用来解码。
NetDecode仅发生在流暴发的时候。每个交换机的解码时间随着有更多的交换机缓慢地增长,因为大多数时间被花费在CounterDecode,这仅仅与一个流程集中的流的数量有关。
FlowDecode时间随着更大的网络而增加,因为它花费了更多的时间来检查一个相邻交换机的解码流,当在一个更待的网络中有更多的相邻交换机。在一个FatTree网络中,假设每个交换机有k个邻居,在这个网络中总的交换机数量是n=5/4*k*k,所以每个流程集只需要检查O(根号n)个其他的流程集。我们检查不同FatTree大小网络的FlowDecode时间,通过将k从4增加到16.每个交换机的内存设置为期望对于SingleDecode有100K流。我们生成流量以至于在每个交换机的数量到达最大值(126.8K)可以被NetDecode。图8显示了结果,FlowDecode时间随着k线性增长,但是,与CounterDecode(反解码器相比),它仍然是小部分。对于每个交换机126.8K的流,和k=16的FatTree,FlowDecode只使用0.24s,这是整个解码时间的7.1%。路由信息可以将FlowDecode加速到0.093s,这只占用整个解码时间的2.9%。

6 FlowRadar分析
我们显示了FlowRadar的两个使用情形:瞬时的loop和黑洞检测,在网络范围的流分析和提供每个流的丢失率,使用时序分析。
6.1 Transient loop/blackhole detection
使用FlowRadar,我们可以通过将交换机连接在一起推测每个流的路径,来记录每个流。结果,我们可以轻松地提供整个网络范围的所有的loop和blackhole,它们发生的事件以及它们影响的流。
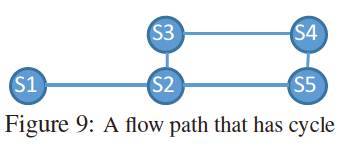
Loops:我们首先区分出在每个时间间隔内看到同一个流的所有交换机,如果交换机来自一个环,我们将它假设为一个loop。我们不能总结出这一定有一个loop,因为可能其中会发生路由变化。例如,图9所示,我们可能使用FlowRadar在同一个时间间隔内观察所有的交换机的所有计数器,由(S2,S3,S4,S5)形成。但是,这可能由路由变化引起,从1->2->5变化到1->2->3->4->5。为了确认这个信息,我们需要将在这个环山的跳(S2)与不在这个环上的跳的计数器(S1)相比较。如果计数器1<计数器2,那么我们可以总结这是一个loop,例如,如果计数器1<计数器3,那么这是一个loop。
Blackholes:如果一个瞬时的blackhole比一个时隙要大,我们可以通过查看在一些跳上停留的流的路径。如果一个瞬时的blackhole比一个时隙要短,我们将仍然看到在一个时隙blackhole前后的很大的不同。需要注意的是,我们不需要计数器,只需要流的信息来检测blackhole。因此,当发生暴发流时,我们可以运行FlowDecode而不使用CounterDecode来更快地检测blackhole。
评估:我们创建一个k=4的FatTree拓扑,在DeterLab的16个主机和20个交换机上。我们调整OVS来支持我们的流量收集。我们将所有的数据包直接发送到用户空间并维持解码流程集。我们为单独的流安装接下来的规则,使用不同的源IP和目的IP地址对。我们从每个主机发送持久的流到另一个主机,每5ms发送一个数据包。这是来确保每个流有在每个时隙有至少一个数据包,尽管有些数据包可能接近时隙边界了。
我们模拟了一个情景:VM迁移可能导致瞬时的loop,当路由表中的边界交换机S1中原VM的位置更新了,将更新信息发送到聚合交换机S2,但是S2还没有更新,所以将数据包又发送回了S1。我们手动地更新边界交换机S1的规则,在10ms以内。这就形成了一个loop:S1->S2->S1,这里S2是一个聚合交换机,我们可以在10ms内检测这个loop。
为了形成一个blackhole,我们手动删除一个边界交换机中的规则,我们可以在20ms内检测blackhole,这是因为在最初的10ms内仍然有流量,当blackhole发生时,所以我们仅能在接下来的10ms内检测与确认。
6.2 每个流的丢失图
FlowRadar可以生成一个网络范围的丢失图,通过在上行和下行交换机(或主机)间的对比,在一系列时隙内。一个简单的方法是,对于每个流,上行和下行计数器中的差距就是每个时隙丢失的。但是,这个方法在实际中并不实用,因为对于两个交换机可能有时间同步的原因或者是有仍然在传输中的数据包。
为了解决这个问题,我们可以等待直到流结束,来对比在不同跳的数据包总数。但是这个将会花费很长的时间,相反,我们可以通过对比flowlets(一个flow可以看成是有多个flowlets组成)而不是flow来更快地检测loss。假设在Flowradar中的时隙是10ms,我们将flowlets定义为流中由大于时隙的间隙分隔的包的突发。使用FlowRadar,我们可以在连个时隙间识别flowlets,使用等于0的计数器。给定一个flowlet f,上行和下行交换机收集一系列的计数器:U1……Ut和D1……Dt(D0和Dt+1是0)。我们计算这个flowlet f的总丢失数为![]() ,这是因为如果一个数据包丢失没有在至少10ms内到达下行交换机,将很有可能丢失了。
,这是因为如果一个数据包丢失没有在至少10ms内到达下行交换机,将很有可能丢失了。
在这种方法下,我们可以获得精确的丢失数目和丢失率,对于所有已经结束的flowlets。对于我们检测延迟的关键因素是flowlets的持续时间。例如,在数据中心中,许多流有短小的flowlets。例如,在一个生产的Web搜索工作量,87.5%的划分/聚合的搜寻流被一个大于15ms的间隔花费。95%的询问流可以在10ms内结束。另外,95%的背景大流有10-200ms的流完成时间,有潜在的flowlets。
评估:我们在一个k=8的FatTree上运行我们的解决方案,在一个ns-3的模拟器中。FatTree有128个主机,连接了80台交换机,使用10G的链路。我们从一个生产的Web搜索数据中心使用相同的工作负载分布,但是添加了1000个partition-aggregate个询问每秒,使用20个入度(即,回答节点的数目)以及包的大小是1.5KB。在我们的实验中,每个端口的询问大小是150KB,意味着100个有1.5KB大小的数据包。Flowlet的持续时间大多数小于30ms,最多是160ms。50%的背景流量有0ms的间隔时间,意味着应用发送a spike of flows。剩下的至少40%的背景流量有大于10ms的间隔时间,对于周期性地更新和短小的信息。
我们运行Flow Radar来在每个交换机上收集每10ms的编码流程集。我们定义探测延迟是丢失发生时间和我们报告丢失的时间差。图10显示了丢失探测延迟的CDF。我们可以探测超过57%的丢失,在20ms内,和超过99%的丢失,在50ms内。

7 实施
编码和输出交换机上的计数器:FlowRadar仅仅提供简单的操作(例如,hashing,xor,计数等),这可以被部署在现存的商业芯片上。例如,hashing已经可以在第二层转发上使用,并且实施ECMP功能。FlowRadar很容易被部署。
我们已经在P4模拟器上部署了我们的原型,我们使用一系列的计数器来存储我们的计数表和flow filter。当每个数据包到达时,我们使用基于hash的一个API来为计数表生成kc个hash值,为flow filter生成kf个hash值,使用bit xor头部信息到XOR域。在控制平面,我们使用读取状态的API读取数据内容。
因为编码流程集很小,我们可以将整个编码流程集输出到收集器而不是基于每个流输出它们。为了防止当输出时在数据平面产生冲突,我们可以使用两个编码流程集的表:进来的数据包更新每个表当我们在另一个表中输出数据时。需要注意的是,在内存使用和输出负载之间要有一个权衡。如果我们更频繁地输出(有较小的输出间隔),在间隔中就会有更少的流,因此需要更小的内存。操作者可以配置不同的时间间隔和交换机性能,本文将时间间隔设置为10ms。
操作情景:与NetFlow相同,我们可以将FlowRadar的编码流程集部署到每个端口或每个交换机。如果部署到每个交换机,则将会使用更小的内存,因为流是多路的。就是说,就流量而言,所有端口不太可能同时发生突发事件。
在每个交换机中部署,我们仍然需要辨别流进和流出的流(例如,在同一个连接中两个单向的流)。一个方法是将输入端口和输出端口存储为编码流程集中另外的域,例如我们针对五元组所做的InputPortXOR和OutputPortXOR。另一种方法是维持两个编码流程集,一个给输入流使用,另一个给输出流使用。
FlowRadar可以被在任何交换机中被部署。FlowRadar已经可以独立地报告每条流的计数器在一个短时隙内,在每个被部署的交换机内。如果FlowRadar在更多的交换机中被部署,我们可以借助网络范围的解码来处理一个流爆发中的更多的流。注意,我们的网络范围的解码不需要完全的部署,只要有流穿过两个或更多的编码流程集,我们可以开始从网络范围的解码获得好处。操作者可以选择在哪里实施,并且他们知道他们在哪些流上部署了FlowRadar。在理想情况下,如果所有的交换机都被部署了,我们就知道在所有位置的每个流的计数器,以及这些流的路径。操作者也可以选择交换机的自己,例如,如果我们尽在ToR交换机上部署,那个计数器仍然可以覆盖所有的活动(例如,丢失),但是我们不能再知道流在网络中出现的精确的位置。就像我们在5.2节中所说,解码成功率没有改变,只要我们还有至少2个流程集,所以部分地部署不会影响解码成功率。
8 相关工作
8.1 监控数据中心的工具
因为NetFlow的问题,数据中心运营商开始发明和使用另外的监控工具。除了sFlow和EverFlow,还有另外的网络监控工具。OpenFlow提供了为每条安装的规则的计数器,这只有当运营商知道需要跟踪哪个流时是有用的。Planck使用采样镜像到交换机,这可能对于我们在第2节中描述的一些场景不适用。还有许多端主机的监控措施,例如SNAP(可以捕捉TCP层的数据)、pingmesh(可以使用活跃的探针)。FlowRadar是端主机的补充,对于个体的流提供网络内的视图。
8.2 测量数据结构
有许多基于hash的数据结构提供给网络测量。与它们相比,FlowRadar有三个特点:(1)为许多流存储流-计数器对,(2)在工业芯片中部署简单,(3)支持网络范围的解码。
数据结构的性能测量和计数容量:有人假设一组用于数据丢失、延迟、爆发测量的数据结构。但是,这些解决方案都不能维持每个流量指标并且可以扩展到大量流量。有许多基于散列的数据结构可以保持每个流状态的小内存[15,42,36,43]。但是,它们中的大多数不适合NetFlow,因为它们只能保持值(即每个流状态)。相反,FlowRadar提供密钥值对(即流元组和分组计数器),并且可以扩展到大量流。用于存储键值对的基于散列的数据结构:Cuckoo散列[33]和左侧散列[14,38]是两种散列表设计,可以存储内存使用率较低的键值对。但是,在NetFlow的商用芯片中,两者都很难实现。这是因为NetFlow需要立即为传入数据包插入流,以便后续数据包可以更新相同的条目(即原子读取更新操作)。否则,如果一个数据包读取前一个数据包正在更新的单元,则计数器将变得不正确。今天,商用芯片已经具有事务存储器,支持以计数器的原子方式进行读取更新操作。但是,典型的商用芯片可以针对每个数据包6仅针对少数(最多四个)4B或8B长计数器处理读取更新操作。这是因为为了支持商用芯片的高链路速率(目前通常为几Tbps),商用芯片必须采用高度并行化的数据包处理设计,并且原子执行逻辑与这种并行性不一致。实际上,为了支持少量计数器的这种原子读更新语义,商用硅必须采用类似于操作数转发的各种复杂硬件逻辑[7]。
一个d-way Cuckoo哈希表[33]将每个键哈希到d个位置并将键存储在一个空位置。当所有d个位置都已满时,我们需要通过移动项目来重建表格,以便为新密钥腾出空间。然而,这种重建过程只能用交换机软件(即控制平面)来实现,因为它需要多次且通常无限次的存储器访问[33]。在交换机软件中运行重建过程不适合NetFlow,因为NetFlow需要原子读取更新语义。
d-left哈希将具有n个桶的哈希表拆分为d个相等的子表,每个子表具有n / d桶,其中每个桶包含L个单元以容纳L个密钥。 d-left哈希一个新的密钥到d桶,每个子表中有一个,并将密钥放入负载最小的桶中,打破左边的连接。 d-left需要首先读取所有Ld单元并测试是否有任何匹配的传入流。如果匹配,我们递增计数器;否则,我们在最小负载桶中的空单元格中放入一个新条目。支持d-left有两个关键挑战:首先,d-left需要原子读取测试更新操作,而不是读取更新操作。测试逻辑不仅需要更多的ALU和MUX,而且还要求显着增加原子操作逻辑的复杂性,使关键部分的时间更长。其次,d-left只能在对所有Ld单元(每个具有13字节5元组字段和4字节计数器的单元)的测试完成后做出插入决定,这也增加了原子操作逻辑的大小。较长的原子操作持续时间对于商用硅中的高度并行化分组处理可能是一种灾难。
相比之下,FlowRadar更容易在商用芯片中实现,原因有三:首先,FlowRadar只需要原子读取更新操作(即increment / xor)而不是原子读取测试更新,这在硅片设计中要简单得多原子操作时间较短。其次,FlowRadar只需要对单个单元进行原子操作,而数据包可以并行更新不同的单元。因此,FlowRadar需要明显更短的原子操作,更适合具有高线速的商用硅。
因为最小的d-left配置(即d = 4和L = 1)需要原子读取 - 测试 - 更新4 * 17 = 68B,所以不可能支持d-left与今天的商用硅片,但今天的硅只支持4 * 8B = 32B。因此,我们将FlowRadar与未来硅片可能支持的基本d-left设置(即d = 4和L = 1)进行比较,并将[16]推荐的设置(即d = 3和L = 5)进行比较这更难实施。为了在2.74MB的内存上保持100K流量,基本d-left的溢出率为1.04%; FlowRadar和推荐的d-left都没有溢出。在流突发期间,即使计数器无法解码,FlowRadar仍然可以报告流量。这种流量信息可用于各种任务,例如瞬态黑洞检测,路线验证和流量持续时间测量。例如,要在2.74MB内存中保持152K流量,基本d-left的溢出率为10%;推荐的d-left的溢出率为1.2%; FlowRadar仍然可以解码所有152K流(但不是它们的计数器)。
Invertibleble Bloom过滤器查找表(IBLT):FlowRadar的灵感来自可逆布隆过滤器(IBF)[21]和可逆布隆过滤器查找表(IBLT)[24]。 IBF用于保存一组项目。通过比较两个IBF,可以很容易地提取两组之间的差异。而不是保留一组元素,FlowRadar需要收集流的键值存储及其数据包计数器。
IBLT是IBF的扩展,可以存储键值存储。我们的计数表基于IBLT,但有两个关键扩展:(1)如何处理值更新。由于IBLT在识别密钥是新密钥还是旧密钥之前没有流过滤器,因此它将具有新值的现有密钥视为具有具有现有密钥值对的重复密钥的新密钥值对。然后,它使用算术和而不是FlowXOR字段中的XOR和,以及流的哈希值的总和而不是简单的流计数器。此设计在FlowXOR和FlowCount字段中占用更多位,这会占用FlowRadar用于流过滤器的大量内存。它还需要大数(超过64位整数)的计算,以及更复杂的散列函数。我们的实验表明,IBLT仅为100K密钥节省了2.6%的内存,但代价是解码时间增加了4.6倍。 (2)如何解码密钥。我们的单节点编码方案类似于IBLT,但由于简单的FlowXOR和FlowCount字段,所以花费的时间要少得多。此外,通过额外的流量过滤器,我们支持跨多个编码流量集的网络流量和计数器解码。
9 结论
我们提出了FlowRadar,这是一种为短时间尺度内的所有流提供流量计数器的新方法,可在数据中心网络中提供更好的可见性。 FlowRadar使用小内存和交换机上的恒定插入时间对流及其计数器进行编码。然后,它引入了跨交换机的流量网络范围的解码,以处理内存有限的流量突发。我们的设计可以在许多方面进行改进,以进一步降低计算,内存和带宽的成本,例如减少NetDecode时间和更好的方法来利用交换跳跃中的冗余。
注:MatrixRadar:
- FlowRadar是在数据中心中对NetFlow的改进,NetFlow是一个监控工具,记录流的信息(五元组)和特征(数据包数量、流开始/结束时间),当流在截止时间前结束时,NetFlow将流记录信息发送给远端收集器进行处理。NetFlow的限制是无法在一个较短时间和有限容量下使用一个数据结构来维持流的工作集。有时为了实现在有限时间下完成分析,便采用基于采样的NetFlow,这降低了流量分析的精确度。
- 因此提出了FlowRadar:在数据平面,交换机将流信息在固定的较短时间内编码保存到有限的存储空间中,控制平面周期性收集这些编码后的流量信息,解码出网络中各个交换机经过的流和流信息。FlowRadar监控的是所有时间的所有流量。
- 数据平面的编码过程:(1)flow filter:Bloom filter,测试一个新的数据包是否属于一个新的流(2)counting table:存储流计数器,包括flowxor、flowcount、packetcount

4. 控制平面的解码过程:
(1)扫描寻找Counting table中flowcount=1的表项,该表项被称为pure cell,其中flowxor域存储的就是该表项中唯一流的五元组异或的结果,packetcount也是该表项中唯一流的数据包数量;
(2)可以从pure cell中提取解码该流的流量信息;
(3)该流还可能存在于其他的counting table中,将该流的信息从其他counting table中剔除(使用hash函数)。
5. FlowRadar的缺陷:
(1)在解码阶段的复杂度与出错率较高,占用较多的空间资源;
(2)若解码过程中无法再找到Pure cell,将导致无法解出所有流的flowID及其流量信息;
(3)FlowRadar为了保证较高的解码成功率,在单个交换机上,其流量统计表的表项数与流经此交换机的最大流数的比值要大于一个边界值(通常是1.29),这意味着流量统计表的表项数要很大。
6. MatrixRadar:flow filter、FlowID表(存放流的五元组)、流量统计表(存放编码后的流量信息:包数和字节数)->两级hash,更新数据包所属流在流量统计表中的流量信息。比FlowRadar存储空间、带宽占用、占用交换机的计算资源更少。















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









