






批量下载邮箱中的附件 可用、完善程序 支持IMAP和POP3
(注:Office Outlook作为专业邮箱软件可以提供更强大的筛选、下载功能,这个脚本肯定并不上Outlook。)
比如使用邮箱收作业、收调查表之类。
加入了很多处理和筛选功能,还有解决一些编码问题,可用性肯定比网上几十行的最简单的脚本要好很多。曾经当助教时用Python写了个程序,后来无聊就把它写得更完善了,很多细节都是查阅RFC文档的。
很多邮件数据并没不规范,所以得做各种兼容处理。
自己测了一个有2000封邮件的帐号基本不会有问题。
肯定不止我需要,分享给大家,直接丢个Github地址。
GitHub - Li-Jiajie/BatchAttachmentDownloader: 邮箱邮件附件批量下载 v1.3 多种保存模式、支持筛选 支持IMAP与POP3
可批量下载邮件中的附件,包含筛选功能,多种保存方式,比如按邮箱地址、按发件人之类的保存。
支持POP3和IMAP两种协议。
当然水平有限,要是不满足需求修改也是蛮方便的,里面注释和封装的都蛮全。
把下面信息替换掉就可以跑了。
有些邮箱(比如QQ邮箱)只允许访问最近一个月的邮件,在邮箱设置里可以调整,不是程序的问题。
超大附件暂不支持,有需求的人可以在基础上改改代码。
这里也放下代码,两个文件,一个main.py,一个email_helper.py。可移步Github获取最新版。
main.py
"""
https://github.com/Li-Jiajie/BatchAttachmentDownloader
BatchAttachmentDownloader v1.3.0
邮件附件批量下载
Python 3开发,支持IMAP4与POP3协议
支持多种附件保存模式、筛选模式
使用场景:通过邮箱收作业、调查等,批量下载附件 等
2020.10.22
Jiajie Li
"""
import email_helper
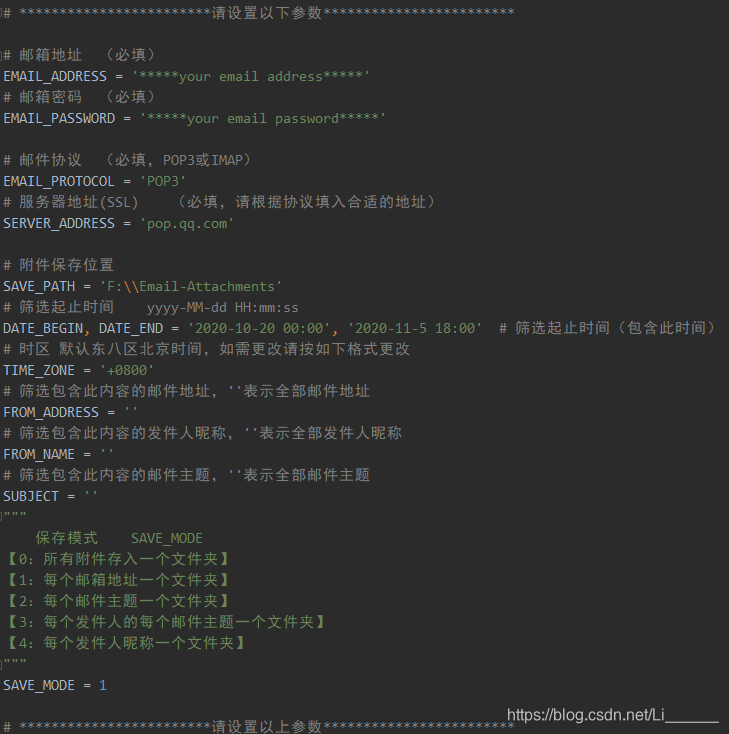
# ************************请设置以下参数************************
# 邮箱地址 (必填)
EMAIL_ADDRESS = '*****your email address*****'
# 邮箱密码 (必填)
EMAIL_PASSWORD = '*****your email password*****'
# 邮件协议 (必填,POP3或IMAP)
EMAIL_PROTOCOL = 'POP3'
# 服务器地址(SSL) (必填,请根据协议填入合适的地址)
SERVER_ADDRESS = 'pop.qq.com'
# 附件保存位置
SAVE_PATH = 'F:\\Email-Attachments'
# 筛选起止时间 yyyy-MM-dd HH:mm:ss
DATE_BEGIN, DATE_END = '2020-10-20 00:00', '2020-11-5 18:00' # 筛选起止时间(包含此时间)
# 时区 默认东八区北京时间,如需更改请按如下格式更改
TIME_ZONE = '+0800'
# 筛选包含此内容的邮件地址,''表示全部邮件地址
FROM_ADDRESS = ''
# 筛选包含此内容的发件人昵称,''表示全部发件人昵称
FROM_NAME = ''
# 筛选包含此内容的邮件主题,''表示全部邮件主题
SUBJECT = ''
"""
保存模式 SAVE_MODE
【0:所有附件存入一个文件夹】
【1:每个邮箱地址一个文件夹】
【2:每个邮件主题一个文件夹】
【3:每个发件人的每个邮件主题一个文件夹】
【4:每个发件人昵称一个文件夹】
"""
SAVE_MODE = 1
# ************************请设置以上参数************************
if __name__ == '__main__':
# 服务器连接与邮箱登录
downloader = email_helper.BatchEmail(EMAIL_PROTOCOL, SERVER_ADDRESS, EMAIL_ADDRESS, EMAIL_PASSWORD)
# 选项设置
downloader.set_save_mode(SAVE_MODE)
downloader.save_path = SAVE_PATH
downloader.date_begin = DATE_BEGIN
downloader.date_end = DATE_END
downloader.time_zone = TIME_ZONE
downloader.from_name = FROM_NAME
downloader.from_address = FROM_ADDRESS
downloader.subject = SUBJECT
# 下载附件
downloader.download_attachments()
downloader.close()
email_helper.py
import abc
import os
import re
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
from email.message import Message
import poplib
import datetime
import imaplib
import email
# 邮件信息类
class EmailInfo(object):
def __init__(self):
self.date = None
self.subject = None
self.from_address = None
self.from_name = None
self.size = None
self.attachments_name = []
# 返回易阅读的文件大小字符串(两位小数),如 12345678 bytes返回'11.77MB'
@staticmethod
def bytes_to_readable(bytes_size: int):
size_unit = [' Bytes', ' KB', ' MB', ' GB', ' TB', ' PB']
unit_index = 0
easy_read_size = bytes_size
while easy_read_size >= 1024:
easy_read_size /= 1024
unit_index += 1
if unit_index == 0:
return str(easy_read_size) + size_unit[unit_index]
else:
return '{:.2f}'.format(easy_read_size) + size_unit[min(len(size_unit), unit_index)]
def print_info(self):
print('subject:', self.subject)
print('from_address:', self.from_address)
print('from_name:', self.from_name)
print('date:', self.date)
print('attachments:', self.attachments_name)
print('total size:', self.bytes_to_readable(self.size))
print('-----------------------------')
def add_attachment_name(self, attachment_name):
self.attachments_name.append(attachment_name)
# 附件储存类_基类
class Saver(metaclass=abc.ABCMeta):
__SUBJECT_MAX_LENGTH = 51
@abc.abstractmethod
def __init__(self, root_path, file_name, file_data):
self._root_path = root_path
self._file_name = file_name
self._file_data = file_data
def _save_file(self, directory_path):
# 储存文件,directory_path是绝对路径,不包含文件名
if not os.path.exists(directory_path):
os.makedirs(directory_path)
self._file_name = Saver.file_name_check_and_update(directory_path, self._file_name)
file = open(os.path.join(directory_path, self._file_name), 'wb')
file.write(self._file_data)
file.close()
@staticmethod
# 检查文件名,如果相同则自动递增编号。返回文件名,不包含路径。
def file_name_check_and_update(path, file_name):
file_number = 2
exist_file_list = os.listdir(path)
pure_name, extension = os.path.splitext(file_name)
while file_name in exist_file_list:
file_name = pure_name + '_' + str(file_number) + extension
file_number += 1
return file_name
@staticmethod
# 检查文件夹名词,去除非法字符并控制长度
def normalize_directory_name(directory_name):
normalized_name = re.sub('[*"/:?|<>\n]', '', directory_name, 0)
normalized_name = normalized_name[0:min(Saver.__SUBJECT_MAX_LENGTH, len(normalized_name))].strip()
return normalized_name
@abc.abstractmethod
def save(self):
pass
# 模式0:所有附件存入一个文件夹
class MergeSaver(Saver):
def __init__(self, root_path, file_name, file_data):
super().__init__(root_path, file_name, file_data)
def save(self):
self._save_file(self._root_path)
# 模式1:每个邮箱地址一个文件夹
class AddressClassifySaver(Saver):
def __init__(self, root_path, file_name, file_data, email_address):
super().__init__(root_path, file_name, file_data)
self._email_address = self.normalize_directory_name(email_address)
def save(self):
self._save_file(os.path.join(self._root_path, self._email_address))
# 模式2:每个邮件主题一个文件夹
class SubjectClassifySaver(Saver):
def __init__(self, root_path, file_name, file_data, email_subject):
super().__init__(root_path, file_name, file_data)
self._email_subject = self.normalize_directory_name(email_subject)
def save(self):
self._save_file(os.path.join(self._root_path, self._email_subject))
# 模式3:每个发件人的每个邮件主题一个文件夹
class AddressSubjectClassifySaver(Saver):
def __init__(self, root_path, file_name, file_data, email_address, email_subject):
super().__init__(root_path, file_name, file_data)
self._email_address = self.normalize_directory_name(email_address)
self._email_subject = self.normalize_directory_name(email_subject)
def save(self):
self._save_file(os.path.join(self._root_path, self._email_address, self._email_subject))
# 模式4:每个发件人昵称一个文件夹
class AliasClassifySaver(Saver):
def __init__(self, root_path, file_name, file_data, from_alias):
super().__init__(root_path, file_name, file_data)
self._from_alias = self.normalize_directory_name(from_alias)
def save(self):
self._save_file(os.path.join(self._root_path, self._from_alias))
# 储存器工厂
class SaverFactor:
def __init__(self, mode: int):
self.__mode = mode
def __call__(self, root_path, file_name, file_data, email_info: EmailInfo):
"""
保存模式 SAVE_MODE
【0:所有附件存入一个文件夹】
【1:每个邮箱地址一个文件夹】
【2:每个邮件主题一个文件夹】
【3:每个发件人的每个邮件主题一个文件夹】
【4:每个发件人昵称一个文件夹】
"""
if self.__mode == 0:
return MergeSaver(root_path, file_name, file_data)
elif self.__mode == 1:
return AddressClassifySaver(root_path, file_name, file_data, email_info.from_address)
elif self.__mode == 2:
return SubjectClassifySaver(root_path, file_name, file_data, email_info.subject)
elif self.__mode == 3:
return AddressSubjectClassifySaver(root_path, file_name, file_data, email_info.from_address,
email_info.subject)
elif self.__mode == 4:
return AliasClassifySaver(root_path, file_name, file_data, email_info.from_name)
else:
return None
# 邮件属性判断_基类
class EmailJudge:
@abc.abstractmethod
def judge(self):
pass
# 日期判断
class DateJudge(EmailJudge):
def __init__(self, date_begin, date_end, time_zone, email_date):
self.__date_begin = date_begin
self.__date_end = date_end
self.__time_zone = time_zone
self.__email_date = email_date
def judge(self):
# Date格式'4 Jan 2020 11:59:25 +0800'
date_mail = datetime.datetime.strptime(self.__email_date, '%d %b %Y %H:%M:%S %z')
date_begin = datetime.datetime.strptime((self.__date_begin + self.__time_zone), '%Y-%m-%d %H:%M%z')
date_end = datetime.datetime.strptime((self.__date_end + self.__time_zone), '%Y-%m-%d %H:%M%z')
return date_begin < date_mail < date_end
@staticmethod
# 比较是否比Target时间更早,用于结束邮件遍历的循环。包含时区。
def is_earlier(email_time, target_time):
email_datetime = datetime.datetime.strptime(email_time, '%d %b %Y %H:%M:%S %z')
target_datetime = datetime.datetime.strptime(target_time, '%Y-%m-%d %H:%M%z')
return email_datetime < target_datetime
# 邮件主题判断
class SubjectJudge(EmailJudge):
def __init__(self, subject_include, email_subject):
self.__subject_include = subject_include
self.__email_subject = email_subject
def judge(self):
return self.__subject_include in self.__email_subject
# 邮件发件人地址判断
class AddressJudge(EmailJudge):
def __init__(self, address_include, email_from_address):
self.__address_include = address_include
self.__email_from_address = email_from_address
def judge(self):
return self.__address_include in self.__email_from_address
# 邮件发件人姓名判断
class NameJudge(EmailJudge):
def __init__(self, name_include, email_from_name):
self.__name_include = name_include
self.__email_from_name = email_from_name
def judge(self):
return self.__name_include in self.__email_from_name
# 邮件筛选器
class EmailFilter:
def __init__(self):
self.__judges = []
def add_judge(self, judge: EmailJudge):
self.__judges.append(judge)
def judge_conditions(self):
for condition_judge in self.__judges:
if not condition_judge.judge():
return False
return True
# 批量邮件下载类
class BatchEmail:
def __init__(self, mode, email_server, email_address, email_password):
self.__save_mode = 0 # 附件保存模式
self.save_path = 'Email-Attachments' # 附件保存位置
# 筛选属性
self.date_begin, self.date_end = '2020-1-1 00:00', '2020-1-4 20:00' # 筛选属性:起止时间
self.time_zone = '+0800' # 筛选属性:时区
self.from_address = '' # 筛选属性:发件人地址
self.from_name = '' # 筛选属性:发件人姓名
self.subject = '' # 筛选属性:邮件主题
self.__saver_factor = None
if mode.lower().find('pop') != -1:
self.__receiver = Pop3Receiver(email_server, email_address, email_password)
elif mode.lower().find('imap') != -1:
self.__receiver = ImapReceiver(email_server, email_address, email_password)
else:
print('请选择邮件协议,POP3或IMAP。')
return
def set_save_mode(self, save_mode):
self.__save_mode = save_mode
self.__saver_factor = SaverFactor(self.__save_mode)
def download_attachments(self):
if self.__receiver is None:
return
# 邮件数量和总大小:
mail_quantity, mail_total_size = self.__receiver.get_email_status()
print('邮件总数:', mail_quantity)
if mail_total_size > 0:
print('邮件总大小:', EmailInfo.bytes_to_readable(mail_total_size), end='\n\n')
# mail_list中是各邮件信息,格式['number octets'] (1 octet = 8 bits)
mail_list = self.__receiver.get_mail_list()
error_count = 0
# 倒序读取(从最新的开始)
for mail_number in mail_list:
# mail_number = '590' # debug
try:
content_byte = self.__receiver.get_mail_header_bytes(mail_number)
mail_message = self.parse_mail_byte_content(content_byte)
message_info = self.__get_email_info(mail_message)
except Exception as e:
print('邮件接收或解码失败,邮件编号:[%s] 错误信息:%s' % (mail_number, e))
error_count += 1
continue
email_filter = EmailFilter()
email_filter.add_judge(DateJudge(self.date_begin, self.date_end, self.time_zone, message_info.date))
email_filter.add_judge(SubjectJudge(self.subject, message_info.subject))
email_filter.add_judge(AddressJudge(self.from_address, message_info.from_address))
email_filter.add_judge(NameJudge(self.from_name, message_info.from_name))
# 超出设定的最早时间则结束循环
if DateJudge.is_earlier(message_info.date, self.date_begin + self.time_zone):
break
if email_filter.judge_conditions():
content_byte, message_info.size = self.__receiver.get_full_mail_bytes(mail_number) # 接收完整邮件
mail_message = self.parse_mail_byte_content(content_byte)
file_number = self.__save_email_attachments(mail_message, message_info)
print(
'( %d / %d )【%s】' % (
len(mail_list) - int(mail_number) + 1, len(mail_list), message_info.subject), end='')
print('已保存,下一封') if file_number != 0 else print('无附件')
message_info.print_info()
else:
print('( %d / %d )【%s】不符合筛选条件,下一封' % (
len(mail_list) - int(mail_number) + 1, len(mail_list), message_info.subject))
print('处理完成')
if error_count > 0:
print('有 %d 个邮件发生错误,请手动检查' % error_count)
def close(self):
self.__receiver.close()
@staticmethod
# 将邮件中的bytes数据转为字符串
def decode_mail_info_str(content):
result_content = []
for value, charset in decode_header(content):
if type(value) != str:
if charset is None:
value = value.decode(errors='replace')
elif charset.lower() in ['gbk', 'gb2312', 'gb18030']:
# 一些特殊符号标着gbk,但编码可能是gb18030中的。gb18030向下兼容gbk、gb2312,所以一律用gb18030。
value = value.decode(encoding='gb18030', errors='replace')
else:
value = value.decode(charset, errors='replace')
result_content.append(value)
return ' '.join(result_content)
@staticmethod
# 把邮件内容解析为Message对象
def parse_mail_byte_content(content_byte):
try:
mail_content = content_byte.decode()
except UnicodeDecodeError as e:
mail_content = content_byte.decode(encoding='GB18030', errors='replace') # GB18030兼容GB231、GBK
return Parser().parsestr(mail_content)
# 附件解析与保存,返回附件数量
def __save_email_attachments(self, message: Message, email_info):
file_count = 0
for part in message.walk():
file_name = part.get_filename()
if file_name:
file_name = self.decode_mail_info_str(file_name)
email_info.add_attachment_name(file_name)
data = part.get_payload(decode=True)
self.__saver_factor(self.save_path, file_name, data, email_info).save()
file_count += 1
return file_count
def __get_email_info(self, message: Message):
email_info = EmailInfo()
try:
email_info.subject = self.decode_mail_info_str(message.get('Subject'))
except TypeError as e:
email_info.subject = '无主题'
name, address = parseaddr(message.get('From'))
email_info.from_address = address
email_info.from_name = self.decode_mail_info_str(name)
date = message.get('Date')
# 少数情况下无Data字段,Received
if date is None:
received = message.get('Received')
if received is None:
# 极少数邮件信息头内没有时间信息,偶发于一些系统发送的邮件
raise ValueError('该邮件收件时间解析失败,邮件主题:【%s】' % email_info.subject)
date = received[received.rfind(';') + 1:]
# Date格式'Sat, 4 Jan 2020 11:59:25 +0800', 也有可能是'4 Jul 2019 21:37:08 +0800'
# 开头星期去除,部分数据末尾有附加信息,因此以首个冒号后+12截取
date_begin_index = 0
for date_begin_index in range(len(date)):
if '0' <= date[date_begin_index] <= '9':
break
date = date.replace('GMT', '+0000') # 部分邮件用GMT表示
email_info.date = date[date_begin_index:date.find(':') + 12]
return email_info
# POP3协议 邮件接收类
class Pop3Receiver:
def __init__(self, host: str, email_address: str, email_password: str):
# 连接POP3服务器(SSL):
try:
self.__connection = poplib.POP3_SSL(host)
except OSError as e:
print('连接服务器失败,请检查服务器地址或网络连接。')
self.close()
return
self.__connection.set_debuglevel(False)
poplib._MAXLINE = 32768 # POP3数据单行最长长度,在有些邮件中,该长度会超出协议建议值,所以适当调高
# 服务器欢迎文字:
print(self.__connection.getwelcome().decode())
# 登录:
self.__connection.user(email_address)
try:
self.__connection.pass_(email_password)
except Exception as e:
print(e.args)
print('登陆失败,请检查用户名/密码。并确保您的邮箱已开启POP3服务。')
self.close()
return
def get_mail_list(self):
# mail_list中是各邮件信息,格式['number octets'] (1 octet = 8 bits)
response, mail_list, octets = self.__connection.list()
return [x.split()[0].decode() for x in reversed(mail_list)]
def get_email_status(self):
return self.__connection.stat()
def get_mail_header_bytes(self, mail_number: str):
# TOP命令接收前n行,此处仅读取邮件属性,读部分数据可加快速度。TOP非所有服务器支持,若不支持请使用RETR。
response, content_byte, octets = self.__connection.top(mail_number, 40)
# 第一个空行前之是头部信息 RFC822
try:
mail_header_end = content_byte.index(b'')
except ValueError as e:
mail_header_end = len(content_byte)
return self.__merge_bytes_list(content_byte[:mail_header_end])
def get_full_mail_bytes(self, mail_number: str):
response, content_byte, size = self.__connection.retr(mail_number)
return self.__merge_bytes_list(content_byte), size
@staticmethod
def __merge_bytes_list(bytes_list):
# 注:极个别邮件中,同一封邮件存在多种编码,那么就不要join后整体解码,而是每一行单独解码。情况少见,暂时忽略。
return b'\n'.join(bytes_list)
def close(self):
if self.__connection is not None:
try:
self.__connection.close()
except OSError as e:
print('断开时发生错误')
self.__connection = None
# IMAP4协议 邮件接收类
class ImapReceiver:
def __init__(self, host: str, email_address: str, email_password: str):
# 连接IMAP4服务器(SSL):
try:
self.__connection = imaplib.IMAP4_SSL(host)
except OSError as e:
print('连接服务器失败,请检查服务器地址或网络连接。')
self.close()
return
# 登录:
try:
s = self.__connection.login(email_address, email_password)
except Exception as e:
print(e.args)
print('登陆失败,请检查用户名/密码。并确保您的邮箱已开启IMAP服务。')
self.close()
return
def get_email_status(self):
response, data = self.__connection.status('INBOX', '(MESSAGES)')
quantity = int(re.findall('\d+', data[0].split()[2].decode())[0])
return quantity, -1
def get_mail_list(self):
self.__connection.select()
response, mail_list = self.__connection.search(None, 'ALL')
return [x.decode() for x in reversed(mail_list[0].split())]
def get_mail_header_bytes(self, mail_number: str):
response, data = self.__connection.fetch(mail_number, '(BODY[HEADER])')
if data[0] is None:
# 极少数邮件无法获取到内容,一般是系统发送的邮件
raise ValueError('邮件解析失败')
return data[0][1]
def get_full_mail_bytes(self, mail_number: str):
response, data = self.__connection.fetch(mail_number, '(RFC822)')
size = int(re.findall('\d+', data[0][0].split()[2].decode())[0])
return data[0][1], size
def close(self):
if self.__connection is not None:
try:
self.__connection.close()
except OSError as e:
print('断开时发生错误')
self.__connection = None

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









