






SQL:
- Structured Query Language 结构化查询语言, 此语言是用于程序员和数据库软件进行交流的语言
DBMS:
- DataBaseManagementSystem: 数据库管理系统(俗称数据库软件)
- 常见的数据库管理系统(DBMS)
- MySQL: Oracle公司产品, MySQL08年被Sun公司收购, Sun公司09年被Oracle收购. 开源产品 市占率第一
- Oracle: Oracle公司产品, 闭源产品, 性能最强 价格最贵 市占率第二
- SQLServer: 微软公司产品, 闭源产品, 市占率第三
- DB2: IBM公司产品 ,闭源产品
- SQLite: 轻量级数据, 安装包只有几十k ,只具备基础的增删改查功能
数据类型
1.整数:
int(m) 和 bigint(m) , bigint等效java中的long, m代表显示长度,举例m=5,存18 查询到 00018 , 需要补零的话必须使用zerofill关键字
2.浮点数: double(m,d) m代表总长度,d代表小数长度 54.432 m=5 d=3
3.字符串
char(m): 固定长度字符串 , m=5 存abc 占5个字符长度 , 应用场景: 当存储长度固定时,比如存储性别char(1) , 最大字符长度255
varchar(m):可变长度字符串, m=5 存abc 占3个字符长度, 最大值65535但是建议保存255以内长度的数据
text(m):可变长度字符串, 最大值65535 建议保存长度大于255的数据
4.日期
date: 只能保存年月日
time: 只能保存时分秒
datetime: 保存年月日时分秒, 最大值9999-12-31, 默认值为null
timestamp(时间戳:保存1970年1月1日到现在的毫秒数):保存年月日时分秒, 最大值2038-1-19 , 默认值为当前系统时间(当赋值为null时触发默认值)
启动数据库:
mysql -u root -p
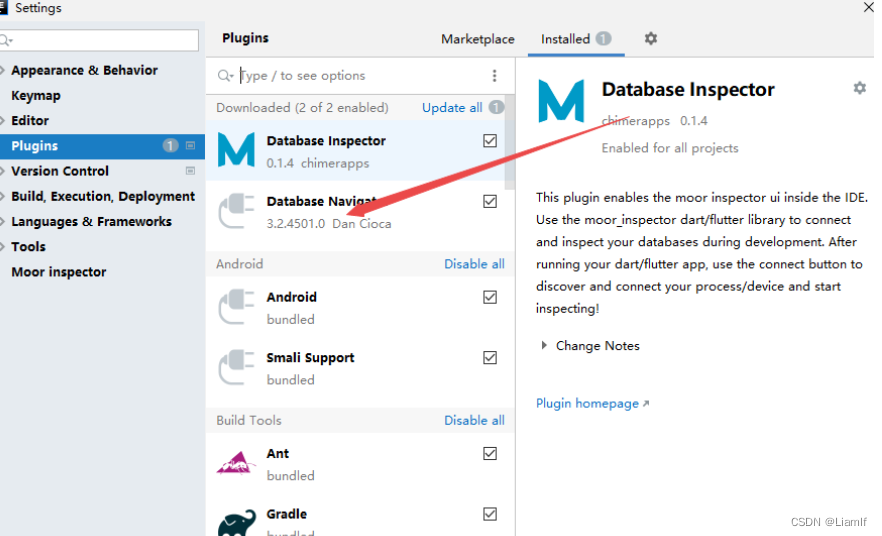
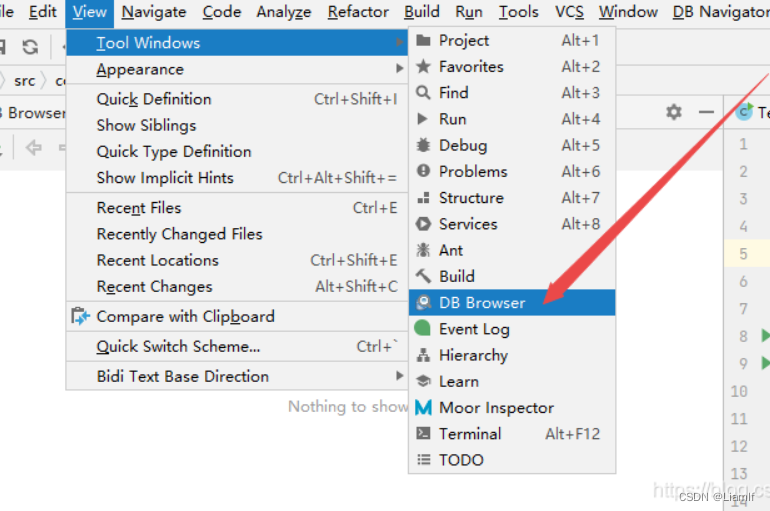
如果在IDEA中使用数据库的话要进行相关配置连接
1.
2.
3.

4.
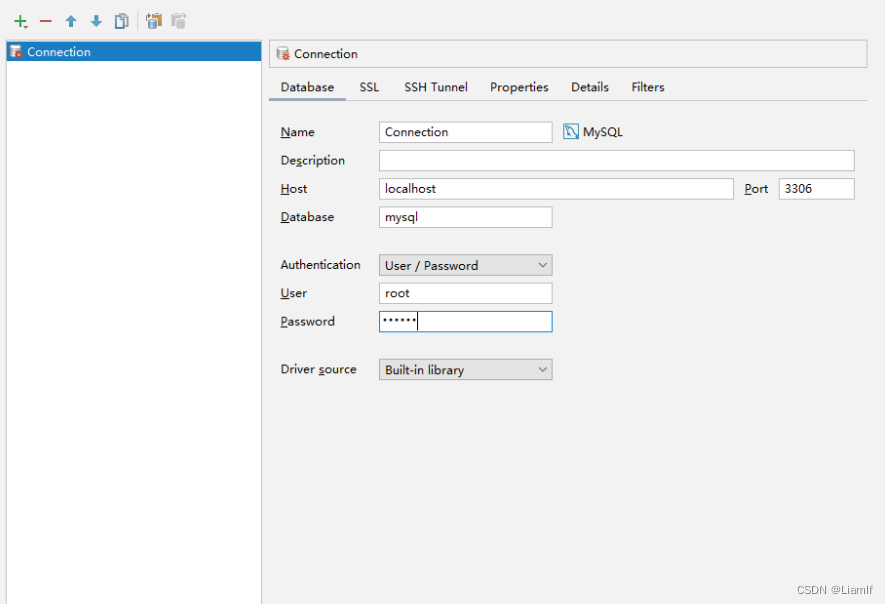
5.
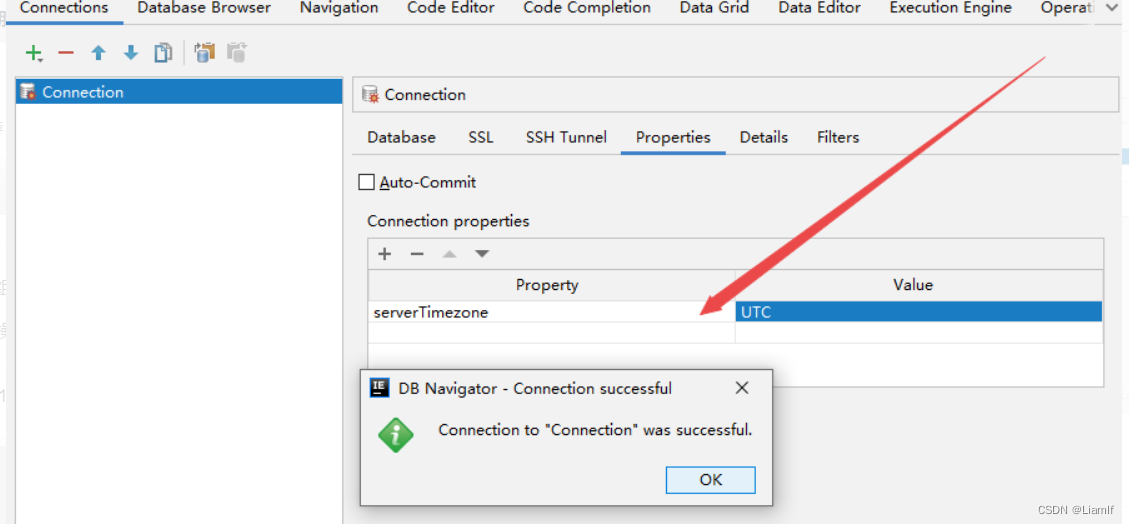
完活后我们需要在该项目的resources下配置相关信息
spring.datasource.url=jdbc:mysql://localhost:3306/xxx? useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=rootxxx:代表你要连接的数据库名
username自己的用户名
password:自己的数据库密码(不要犯错)
数据库保存数据:
1.以表为单位保存数据
2.先建库后建表
SQL语句格式要求:
- 以;结尾
- 不区分大小写
- 可以包含空格和换行
数据库相关SQL
1.查询所有数据库
格式: show databases;
2.创建数据库
格式: create database 数据库名 charset=utf8/gbk;
3.查看数据库信息
格式: show create database 数据库名
4.删除格式: drop database 数据库名;
5.使用数据库
- 执行表相关和数据相关的SQL语句之前必须使用了某一个数据库 否则会报错.
- 格式: use 数据库名;
表相关的SQL语句
1.查询所有表
show tables;
2.创建表
格式: create table 表名(字段1名 类型,字段2名 类型)charset=utf8/gbk;
3.查看表信息
格式: show create table 表名;
4.删除表
格式: drop table 表名;
5.修改表名
格式: rename table 原名 to 新名;
6.查看表字段
格式: desc 表名; desc = description 描述
7.添加表字段
最后面添加格式: alter table 表名 add 字段名 类型;
最前面添加格式: alter table 表名 add 字段名 类型 first;
在xxx字段的后面添加格式: alter table 表名 add 字段名 类型 after xxx;
8.删除表字段
alter table 表名 drop 字段名;
9.修改表字段
alter table 表名 change 原名 新名 新类型;
数据库SQL2
必须使用某一个数据库并创建保存的数据表
增删改查(基础)
1.插入数据
全表插入格式: insert into 表名 values(值1,值2,....);
指定字段插入格式: insert into 表名(字段1名,字段2名) values(值1,值2);

2. 查询数据
select 字段信息 from 表名 where 条件;
3.修改数据
update 表名 set 字段1名=值,字段2名=值 where 条件;
4.删除数据
delete from 表名 where 条件
主键约束 primary key
- 约束: 创建表时给表字段添加的限制条件
- 主键: 表示数据唯一性的字段称为主键
- 主键约束: 限制主键的值唯一且非空
- 举例:
create table t5(id int primary key,name varchar(30));
insert into t5 values(1,"a");
insert into t5 values(2,"b");
insert into t5 values(2,"c"); //重复报错
insert into t5 values(null,"d"); //不能为null 报错
主键约束+自增 primary key auto_increment
- 当字段设置为自增后 插入null值时会触发自增
- 自增规则: 从历史最大值+1
- 举例:
create table t6(id int primary key auto_increment,name varchar(50));
insert into t6 values(null,"a");
insert into t6 values(null,"b");
insert into t6 values(10,"c");
数据库SQL语句的分类(重)
- DDL: 数据定义语言, 包括数据库相关和表相关的SQL,
- truncate table 表名; 删除表并创建新表
- DML: 数据操作语言,包括:增删改查相关的SQL语句
- DQL: 数据查询语言,包括:select查询相关
- TCL: 事务控制语言,包含和事务相关的SQL语句
- DCL: 数据控制语言, 包含创建用户以及用户权限分配相关SQL
比较运算符
> < >= <= = !=和<>
常用:
1.AND和OR
- and: 等效java中的&&, 需要多个条件同时满足时使用
- or: 等效java中的|| , 多个条件满足一个时使用
格式:select * from 表名 where 条件1 and 条件2;
2.is null is not null
select 字段名 from 表名 where 字段名 is null/is not null;
3.betwenn x and y俩者之间
select 字段名 from b表名 where 字段名 (not) betwenn 值1 and 值2
4. in(x,y,z)
select * from 表名 where 字段名 (not) in(值1,值2,值3);
5.distinct 去掉重复数据
select distinct 字段名 from 表名:
6.模糊查询 like
select* from 表名 where 字段名 like %%;
- %: 代表0或多个未知字符
- _:代表1个未知字符
- 举例:
- 以x开头 x%
- 以x结尾 %x
- 包含x %x%
- 第二个字符是x _x%
- 以x开头以y结尾 x%y
- 第三个是x倒数第二个是y __x%y_
7.排序 order by
select*from 表名 order by 字段名 asc(升序)/desc(降序)
8.分页查询
limit 跳过的条数,请求的条数(每页的条数)
跳过的条数=(请求的页数-1)* 每页的条数
select*from 表名 order by 字段名 limit(跳过的条数,请求的条数)
8.别名
select 字段名 as 别名 from表名;
聚合函数
通过聚合函数可以对查询多的多条数据进行统计查询
1.平均值
avg()
select avg(求平均的字段名) from 表名 where 条件;
2.最大值/最小值
max()/min()
select max/min(字段名) from 表名 where 条件;
3.求和
sum()
select sum(字段名) from 表名 where 条件;
4.计数
count(*)
select count(*) from 表名;
count不能计算含有null的数据会跳过
5.分组查询
group by
可以将某个字段相同值的数据划分为一组,然后以组的单位进行统计查询
select 字段名1 聚合函数 from 表名 where 条件 group by 字段名1;
where不能写聚合函数的条件
6.having关键字
having后面专门写聚合函数条件,而且需要和group by 分组查询结合使用,写在group by 后面
写法一:
select 字段名1 聚合函数 from 表名 group by 字段名1 having 聚合函数条件;
写法二:
select 字段名1 聚合函数 别名 from 表名 group by 字段名1 聚合函数条件;
7.子查询
select*from 表名 where 字段条件>(select 聚合函数 from 表名 where 字段名2);
E.g:
查询工资大于2号部门的平均工资的员工信息
小条件:select avg(sal) from emp where dept_id=2;
跟大条件结合起来:
select*from emp where sal>(select avg(sal) from emp where dept_id=2);
我的理解: 大条件>(小条件);
各种查询语句的关键字顺序
select 字段信息 from 表名 where 普通条件字段条件 group by 分组字段名 having 聚合函数条件 order by 排序字段名 limit(跳过的条数,请求的条数);
关联查询
关系:
1. 一对一:A B表 A表一条数据对应B表一条数据,同时B也对应A.
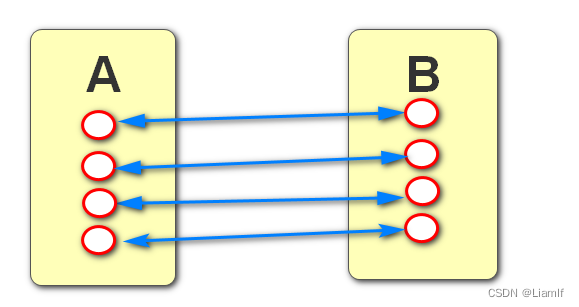
2.一对多: A,B表, A表一条数据对应B表的多条数据,同时B表也对应A表的一条数据

3.多对多: AB表 A多条数据对应B表的多条,同时B多条对应A多条
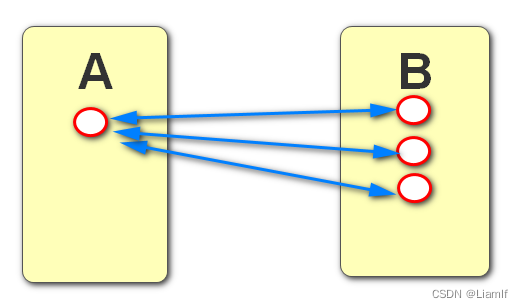
如果两张表之间存在关联关系,如何建立关系?
- 一对一: 可以在两张关系表中任何一个表里面添加建立关系的字段,指向另外一张表的主键
- 一对多: 在一对多的两张表里面的表示"多"的表中添加建立关系的字段指向另外一张表的主键
- 多对多:需要创建一个单独的关系表,关系表中两个字段分别指向另外两张表的主键
关联查询
同属查询俩个表之间或多个表的查询方式
1.等值连接(查询交集数据)
select*from A,B where 关联关系and 其他条件;
select e.name,d.name
from emp e,dept d where e.dept_id=d.id;
2.内连接
查询俩个表的交集数据,经常使用
select*from A join B on 关联关系 where 条件;
select e.name,d.name
from emp e join dept d on e.dept_id=d.id;
3. 外连接
查询一张表的全部信息和另外一张表的交集数据
select*from A left/right join B on 关联关系 where 条件;
select d.name,loc,e.name,sal
from emp e right join dept d on dept_id=d.id where e.manager is not null
- 如果查询的是多张表中的数据则使用关联查询:(等值链接,内连接和外连接)
- 如果查询的是多张表的交集数据,则使用等值链接或内连接(推荐)
- 如果查询的是一张表的全部和其它表的交集数据则使用外连接
JDBC
作用: 通过Java代码执行所学的SQL语句
JavaDataBaseConnectivity: Java数据库链接
JDBC是Sun公司提供的一套专门用于Java语言和数据库进行连接的API(Application Programma Interface应用程序编程接口)
Sun公司为了避免Java程序员每一种数据库软件都学习一套新的方法, 通过JDBC接口将方法名定义好,各个数据库厂商根据此接口中的方法名写各自的实现类(jar包(驱动)), 这样Java程序员只需要掌握JDBC接口中方法的调用即可访问任何数据库, 即使在工作中换了数据库软件,代码也不需要发生改变.
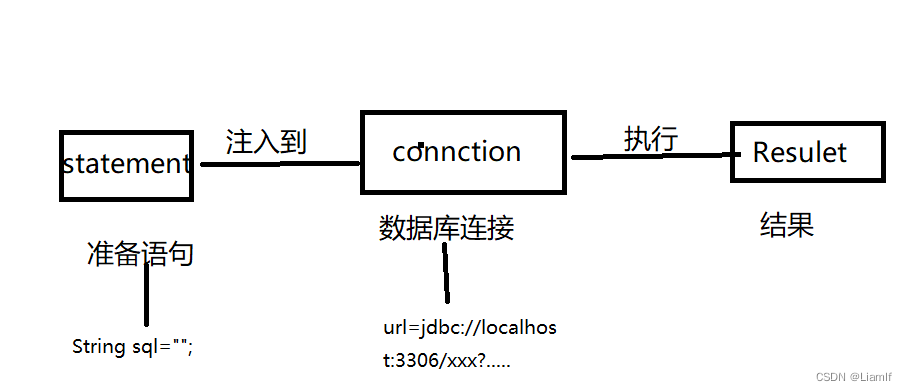
如何通过JDBC和数据库软件进行链接并执行SQL语句
- 创建maven工程
- 在工程的pom.xml文件中添加MySQL驱动的依赖 和修改jdk和字符集
<!-- 设置 JDK 版本为 1.8 -->
<properties>
<maven.compiler.target>1.8</maven.compiler.target> <maven.compiler.source>1.8</maven.compiler.source>
<!-- 设置编码为 UTF-8 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.encoding>UTF-8</maven.compiler.encoding></properties>
<!--添加MySQL相关的依赖,Maven会通过此依赖找到对应的jar包文件下载到工程中-->
<!-- 连接MySQL数据库的依赖 -->
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
</dependencies>Statement执行SQL语句的对象
- execute("sql"); 可以执行任意sql语句,但是推荐执行DDL(数据定义语言,包括数据库相关和表相关)
- int row = executeUpdate("sql"); 执行增删改, 此方法的返回值为生效的行数
- ResultSet rs = executeQuery("sql"); 执行查询相关的SQL语句, ResultSet对象里面装着查询回来的结果.
DBCP数据库连接池
- DataBaseConnectionPool: 数据库连接池
- 作用: 将链接重用,避免频繁的开关链接所带来的资源浪费.
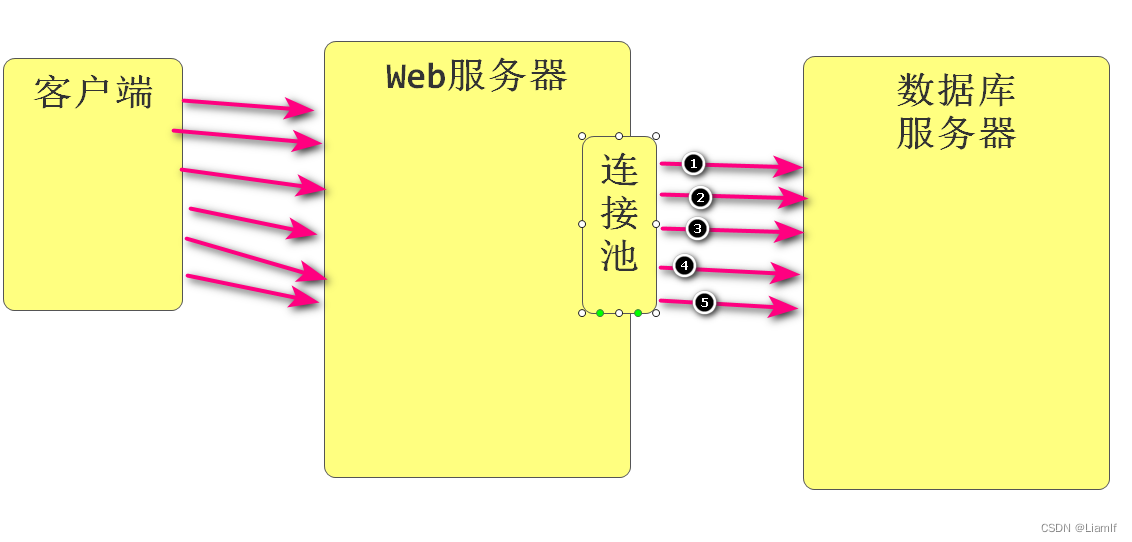
- 如何使用数据库连接池?
- 在pom.xml文件中添加连接池相关的依赖
<!-- 数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.21</version>
</dependency>//创建表示连接池的对象
DruidDataSource ds = new DruidDataSource();
//设置链接数据库的信息
ds.setUrl("jdbc:mysql://localhost:3306/empdb?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false");
ds.setUsername("root");
ds.setPassword("root");
//写自己的密码
//设置初始连接数量
ds.setInitialSize(3);
//设置最大连接数量ds.setMaxActive(5);
//从连接池中获取链接 异常抛出
Connection conn = ds.getConnection();System.out.println("连接对象:"+conn);SQL注入(非常重要,工作中要绝对避免)
- SQL注入是往本应该传值的地方,传递进去了SQL语句导致原有SQL语句的逻辑发生改变,这个过程称为SQL注入
where username='xxx' and password='' or '1'='1'
- SQL注入漏洞是网站的低级漏洞,但是危害比较大, 黑客可以利用此漏洞对网站进行攻击
通过preparedStatement执行语句可以避免
预编译的SQL执行对象,在创建对象时将SQL语句的逻辑判断部分进行编译
可以理解为将SQL语句中的逻辑部分锁死,只留下"?",等待将用户输入的内容替换进来,
当"?"被替换时,会以值的方式进行处理,不会在对原有的SQL语句的逻辑产生影响,从而避免里Sql注入.
PreparedStatement
- 通过PreparedStatement执行SQL语句可以避免出现SQL注入漏洞
- 内部原理: 使用PreparedStatement 可以起到预编译的作用, 可以将编译SQL语句的时间点提前(从之前执行SQL语句时编译提前到创建时), 编译时间点提前可以将SQL语句中业务逻辑部分编译好(将业务部分锁死),之后将用户输入的内容替换到SQL语句时,用户输入的内容只能以值的形式添加到SQL语句中,不会影响原有SQL语句的判断逻辑,所以避免了SQL注入的漏洞
- 执行setString()方法替换?时 会自动给字符串添加引号,并且用户输入的字符串中出现了引号关键字时会进行转义操作 password=''' or ''1''
数据库常见错误列表
1.未开启数据库服务

- 在此电脑上右键->管理->服务和应用程序->找到MySQL或MariaDB 右键启动
2.用户名或密码错误

3.SQL语句拼写错误

4.创建或删除数据库时存在的错误

5.主键值插入错误
















 7954
7954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











