







目录
第六章 请求到达WEB服务器,响应返回浏览器
一、服务器概览
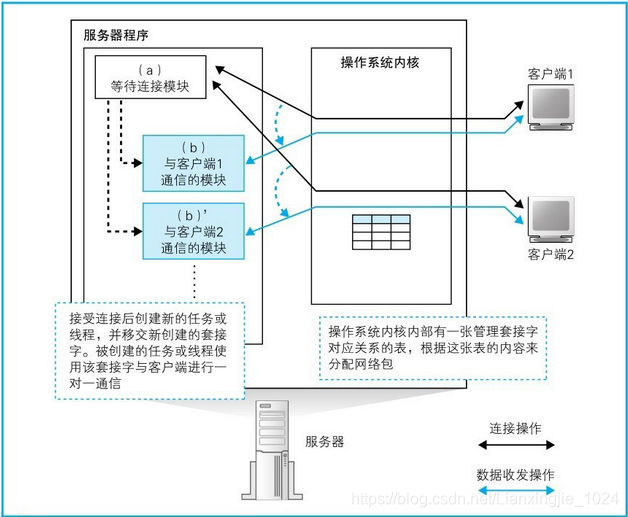
1. 服务器需要同时和多个客户端通信,但一个程序来处理多个客户端的请求是很难的,因为服务器必须把握每一个客户端的操作状态。因此一般的做法是,每有一个客户端连接进来,就启动一个新的服务器程序,确保服务器程序和客户端是一对一的状态。当然,这种方法在每次客户端发起连接时都需要启动新的程序,这个过程比较耗时,响应时间也会相应增加。因此,有一种方法是事先启动几个客户端通信模块,当客户端发起连接时,从空闲的模块中挑选一个出来将套接字移交给它来处理。
2. 服务器数据收发流程:
(1)创建套接字(创建套接字阶段)
(2-1)将套接字设置为等待连接状态(等待连接阶段)
(2-2)接受连接(接受连接阶段)
(3)收发数据(收发阶段)
(4)断开管道并删除套接字(断开阶段)

3. 首先,协议栈调用socket创建套接字;接下来调用bind将端口号写入套接字中;之后协议栈会调用listen向套接字写入等待连接状态这一控制信息;然后,协议栈会调用accept来接受连接(在执行accept的时候,一般来说服务器端都是处于等待包到达的状态,这时应用程序会暂停运行);一旦客户端的连接包到达,协议栈会给等待连接的套接字复制一个副本,然后将连接对象等控制信息写入新的套接字中。到这里,我们就创建了一个新的套接字,并和客户端套接字连接在一起了。原来等待连接的套接字它还会以等待连接的状态继续存在,当再次调用accept,客户端连接包到达时,它又可以再次执行接受连接操作。当accept结束之后,等待连接的过程也就结束了,这时等待连接模块会启动客户端通信模块。
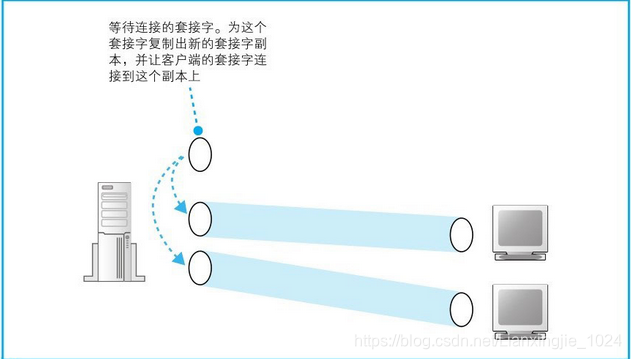
4. 新创建的套接字副本必须和原来的等待连接的套接字具有相同的端口号,因此要确定某个套接字时,不仅使用服务器端套接字对应的端口号,还同时使用客户端的端口号再加上IP地址。
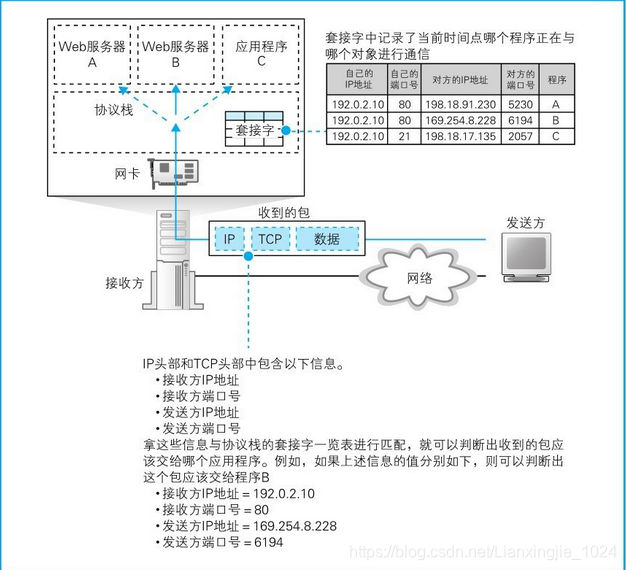
5. 应用程序和协议栈之间是使用描述符来指代套接字的原因如下:
(1)等待连接的套接字中没有客户端IP地址和端口号
(2)使用描述符这一种信息比较简单
二、服务器的接收操作
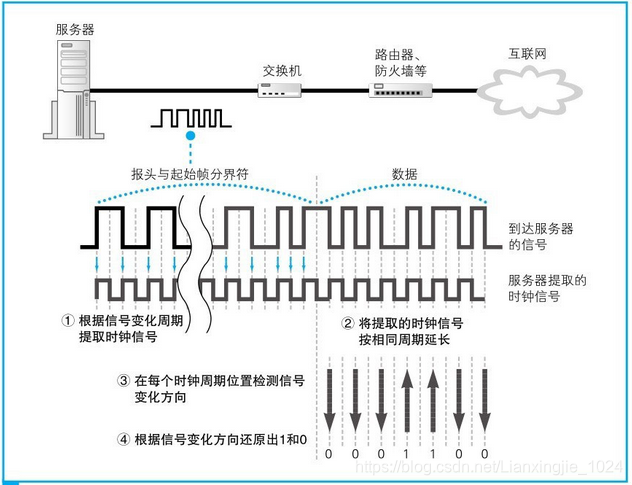
1. 接收操作的第一步是网卡接收到信号,然后将其还原成数字信息。首先,PHY (MAU)模块会将信号转换成通用格式并发送给MAC模块,MAC模块再从头开始将信号转换为数字信息,并存放到缓冲区中:当到达信号的末尾时,还需要检查FCS,若值产生差异,包会被丢弃;如果FCS校验正常,接下来检查MAC头部中接收方MAC地址,如果与自己的MAC地址不一致直接丢弃,一致则将包放入缓冲区中。到这里,MAC模块的工作就完成了,接下来网卡会通过中断机制通知计算机CPU收到了一个包,CPU就会暂停当前的工作,并切换到网卡的任务。然后,网卡驱动会开始运行,从网卡缓冲区中将接收到的包读取出来,根据MAC头部判断协议类型,并将包交给相应的协议栈。例如当以太类型的值是IP协议时,会调用TCP/IP协议栈,并将包转交给它。
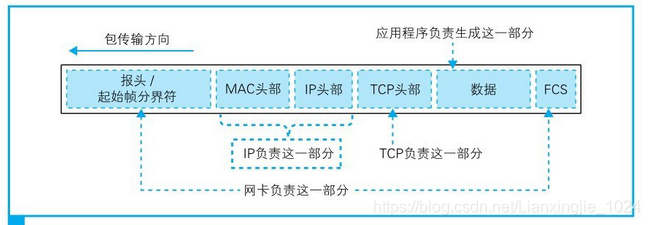
2. 协议栈的IP模块收到包会检查IP头部:
(1)判断是不是发给自己的,不是发给自己的包,会像路由器一样根据路由表对包进行转发
(2)判断网络包是否经过分片,如果是分片则将包暂时存放在内存中,等所有分片全部到达后将分片组装起来还原成原始包
(3)检查IP头部的协议号字段,并将包转交给相应的模块(TCP/UDP/ICMP)
3. TCP模块如果收到的是发起连接的包:
(1)确认TCP头部的控制位SYN,表示这是一个发起连接的包
(2)检查包的接收方端口号,确认是否存在该端口且该端口有正在处于等待连接状态的套接字
(3)为相应的等待连接套接字复制一个新的副本
(4)将发送方IP地址、端口号、序号初始值、窗口大小等必要的参数写入这个副本中,同时分配用于发送缓冲区和接收缓冲区的内存空间
(5)生成代表接收确认的ACK号,用于从服务器向客户端发送数据的序号初始值,表示接收缓冲区剩余容量的窗口大小,并用这些信息生成TCP头部,委托IP模块发送给客户端
4. TCP模块如果收到的是数据包时:
(1)根据收到的包的发送方IP地址、发送方端口号、接收方IP地址、接收方端口号找到相对应的套接字
(2)将数据块拼合起来并保存在接收缓冲区中,数据会被转交给应用程序
(3)生成确认应答的TCP头部,并根据接收包的序号和数据长度计算出ACK号,然后委托IP模块发送给客户端
三、Web服务器程序解释请求消息并作出响应
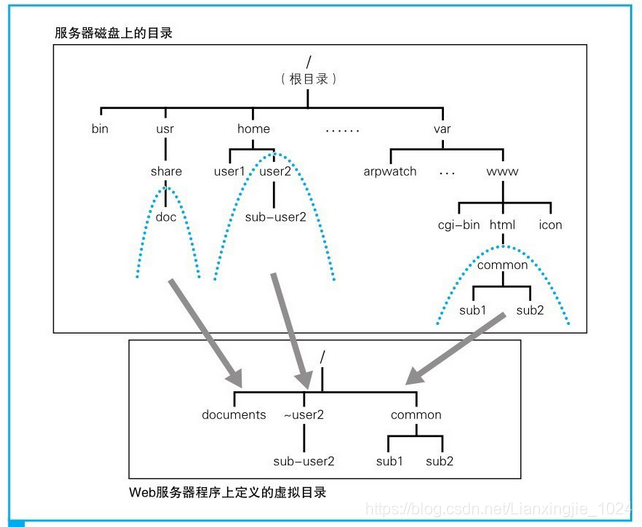
1. 将请求的URI转换为实际的文件名:Web服务器公开的目录其实并不是磁盘上的实际目录,而是如图这样的虚拟目录,而URI中写的就是在这个虚拟目录结构下的路径名。因此,当读取文件时,需要先查询虚拟目录与实际目录的对应关系,并将URI转换成实际的文件名后,才能读取文件并返回数据。如果请求消息中的URI如(1)所示,那么因为/~user2/…对应的实际目录为/home/user2/…,所以将URI转换成实际文件名后应该是如(2)所示。有些Web服务器程序还具有文件名改写功能,只要设置好改写的规则,当URI中的路径符合改写规则时,就可以将URI中的文件名改写成其他的文件名进行访问。当出于某些原因Web服务器的目录和文件名发生变化,但又希望用户通过原来的网址进行访问的时候,这个功能非常有用。

2. 运行CGI程序:根据URI判断要访问的文件为程序文件(这里的判断方法是在Web服务器中事先设置好的,例如将.cgi、.php等扩展名的文件设置为程序),Web服务器会委托操作系统运行这个程序,然后从请求消息中取出数据并交给运行的程序。运行的程序收到数据后会进行一系列处理,并将输出的数据返回给Web服务器。这些输出的数据一般来说会嵌入到HTML文档中,因此Web服务器可以直接将其作为响应消息返回给客户端。输出数据的内容是由运行的程序生成的,Web服务器并不过问,也不会去改变程序输出的内容。
3. Web服务器的访问控制:Web服务器的基本工作方式就是根据请求消息的内容判断数据源,并从中获取数据返回给客户端,不过在执行这些操作之前,Web服务器还可以检查事先设置的一些规则,并根据规则允许或禁止访问。这种根据规则判断是否允许访问的功能称为访问控制。
4. Web服务器的访问控制规则主要有以下3种:(1)客户端IP地址(2)客户端域名(3)用户名和密码
四、浏览器接收响应消息并显示内容
1. 通过响应的数据类型判断其中的内容:要显示内容,首先需要判断响应消息中的数据属于哪种类型。Web可以处理的数据包括文字、图像、声音、视频等多种类型,每种数据的显示方法都不同,因此必须先要知道返回了什么类型的数据,否则无法正确显示。原则上可以根据响应消息开头的Content-Type头部字段的值来进行判断。

2. 消息的Content-Type定义的常见数据类型

完结
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









