






1、什么是堆内存和栈内存?
答: 我们可以从几个方面来看它们之间的区别
- 分配方式
栈:由编译器自动分配和释放,一般存放函数的参数、局部变量、临时变量、函数返回地址等
堆:堆内存是由程序员进行分配和释放的,也称为动态内存分配。如果没有手动free,在程序结束时有可能由操作系统自动释放(但是仅限于有回收机制的语言, 像C/C++就必须进行手动释放,不然就有可能造成内存泄漏)
- 生命周期
栈:由于栈上的空间是自动分配自动回收的,所以栈上数据的生命周期只是在函数的运行过程中存在,运行后就释放掉了
堆:堆上的数据,只要程序员不释放空间,就可以一直访问到。
- 空间申请效率
栈:由系统自动分配,效率比较高
堆:比较慢
- 分配方向
栈:用户进程的用户栈从3GB虚拟空间的顶部开始,由顶向下延伸
堆:分配的空间从数据段的顶部end_data到用户栈的底部。由下往上,每分配一块空间,就把边界往上推进一段。
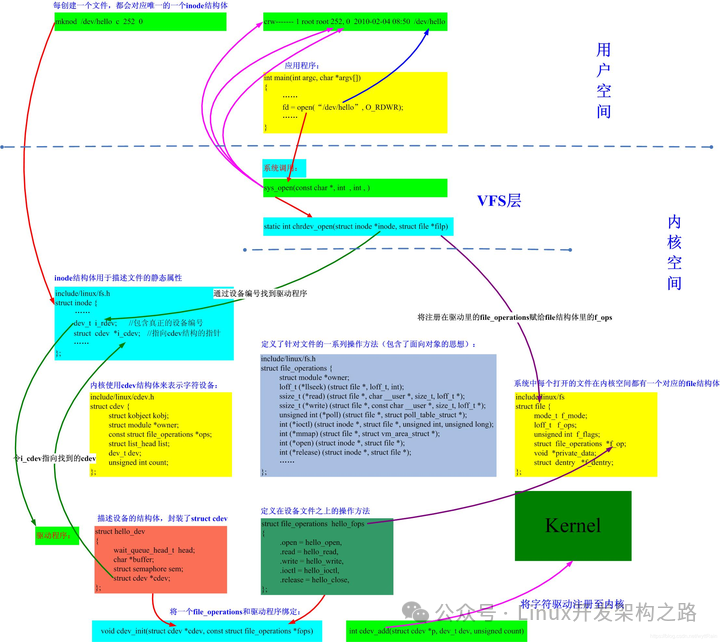
2、用户层open、read等函数如何调用到对应的驱动ops函数?
3.什么是MMU?MMU实现了什么功能?
答:MMU的中文全称为内存管理单元,主要实现的功能是将虚拟地址转换为物理地址。MMU的工作就是一个查询页表的过程,如果页表信息直接存储在内存中,那么查询起来非常费时,所以一般将页表信息存放在MMU上的一小块访问更快的区域,也就是TLB中,用于提高查找效率。
4.请描述进程和程序的区别?
程序是静态的,它是一些保存在磁盘上的指令的有序集合,没有任何执行的概念
进程是一个动态的概念,它是程序执行的过程,包括创建、调度和消亡
-
进程是一个独立的可调度的任务
-
进程是一个抽象实体。当系统在执行某个程序时,分配和释放的各种资源
-
进程是一个程序的一次执行的过程
-
进程是程序执行和资源管理的最小单位
5.进程和线程的区别有哪些?什么时候使用多进程?什么时候使用多线程?
进程和线程的区别:
-
资源分配:进程是操作系统分配资源的基本单位,包括独立的内存空间和文件描述符;线程是进程内的执行单元,共享进程的资源。
-
通信:进程间通信需要额外的机制,如管道、消息队列;线程间通信更方便,可以直接共享内存。
-
切换开销:进程切换开销大,涉及到上下文切换;线程切换开销小,因为线程共享进程的地址空间。
-
独立性:进程间相互独立,一个进程崩溃不会影响其他进程;线程共享进程的资源,一个线程崩溃可能导致整个进程崩溃。
多进程和多线程的选择:
-
多进程适合于需要独立运行、相互隔离、稳定性要求高的场景,如服务器端程序、并行计算等。
-
多线程适合于需要共享数据、资源共享、响应速度要求高的场景,如图形界面程序、网络编程等。
6.操作系统中进程调度策略有几种?
-
先来先服务(FCFS):按照进程到达的顺序进行调度,先到达的进程先被执行。
-
短作业优先(SJF):选择执行时间最短的进程优先执行,以减少平均等待时间。
-
优先级调度:根据进程的优先级来决定执行顺序,优先级高的进程先执行。
-
时间片轮转(Round Robin):每个进程被分配一个时间片,当时间片用完时,进程被暂停并放到队列末尾,轮流执行直到所有进程完成。
-
多级反馈队列调度:将进程按照优先级划分到不同的队列,每个队列有不同的时间片大小,进程根据优先级在不同队列中执行。
-
最短剩余时间优先(SRTF):在SJF的基础上,动态调整执行中的进程,如果有新进程到达且其执行时间比当前进程剩余时间短,则切换执行新进程。
7.为何进程需要有僵尸态?描述几种僵尸子进程回收的方法。
僵尸态是进程退出后,其父进程没有进行收尸操作而进入的状态。此时依然占用资源。不直接释放资源的原因在于父进程可能需要获取子进程的退出状态,用来判断子进程运行情况。若子进程因异常退出而直接释放不进入僵尸态,父进程无法得到结果则无法处理这些异常。
回收僵尸子进程可使用 pid_t wait(int *status); 函数,功能为回收僵尸态子进程,如果子进程还未结束则阻塞等待,如果没有子进程则立刻返回。
或使用pid_t waitpid(pid_t pid, int *status, int options); 函数,功能为按照指定的方式探测指定子进程状态改变,回收僵尸态子进程。可通过配置options参数改成非阻塞方式等待。
8.信号量与互斥锁的区别?
(1)、互斥量用于线程的互斥,信号量用于线程的同步。互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源。
(2)、互斥量值只能为0/1,信号量值可以为非负整数。也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
(3)、互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
9.简述程序编译的过程?
预处理:预处理相当于根据预处理命令组装成新的C程序,不过常以i为扩展名。
编译:将得到的i文件翻译成汇编代码.s文件。
汇编:将汇编文件翻译成机器指令,并打包成可重定位目标程序的O文件。该文件是二进制文件。
链接:将引用的其他O文件并入到我们程序所在的o文件中,处理得到最终的可执行文件。
10.简述memcpy和strcpy的区别?
(1)、复制的内容不同。strcpy只能复制字符串,而memcpy可以复制任意内容,例如字符数组、整型、结构体、类等。
(2)、复制的方法不同。strcpy不需要指定长度,它遇到被复制字符的串结束符"0"才结束,所以容易溢出。memcpy则是根据其第3个参数决定复制的长度。
(3)、用途不同。通常在复制字符串时用strcpy,而需要复制其他类型数据时则一般用memcpy
11.什么是DMA?为什么需要DMA?DMA的数据传输流程是怎么样的?DMA有什么弊端?
DMA的中文全称是直接访问存储器,可以让存储器和外部设备直接进行数据交换。DMA在进行数据传输的过程中,其实是不需要CPU参与的,也就是说,当DMA在进行数据传输工作的时候,CPU也可以同步进行其他工作,大大提高了处理器的工作效率。DMA主要用于需要高速、大批量数据传送的系统中,目的是提高数据的吞吐量,如磁盘存取、图像处理、高速数据采集系统方面应用甚广。通常只有数据量较大的外设才需要支持DMA能力,比如视频、音频和网络接口。
DMA的工作过程是由一个DMA控制器来进行控制的。由DMA控制器来接收外设的DMA请求,然后发送一个总线请求信号给CPU,当CPU接收到总线请求信号后,会在总线状态处于空闲时,反馈一个信号给DMA控制器,DMA控制器会获得总线的控制权,然后反馈一个DMA应答信号给外部设备,表示当前允许进行DMA数据传输。
因为在进行DMA数据传输的时候,DMA控制器需要获得总线的控制权,这可能会影响CPU会中断请求的及时响应和处理。因此,在一些系统或速度要求不高,数据传输量不大的系统中,一般并不用DMA方式。
12.什么是cache?为什么需要cache?请简述一下cache的工作方式
cache是一块介于CPU和主存之间的高速缓冲存储器。cache的作用是加快处理器获取数据的速度,可以有效地提高CPU的效率。当主控发起对某个地址(这个地址是虚拟地址)的访问请求时,会将这个地址同时发送给MMU和cache,虚拟地址会在MMU中的TLB结构中查找,如果TLB命中,那么可以直接返回一个物理地址。如果TLB Miss,那么需要进一步访问MMU并查询页表,如果还是没有找到页表,那么就会触发一个缺页异常中断。同时,处理器通过高速缓存编码地址的索引域(Index)可以很快找到相应的高速缓存行对应的组。但是这里的高速缓存行的数据不一定是处理器所需要的,因此有必要进行一些检查,将高速缓存行中存放的标记域和通过虚实地址转换得到的物理地址的标记域进行比较。如果相同并且状态位匹配,那么就会发生高速缓存命中(cache hit),处理器经过字节选择与对齐(byte select and align)部件,最终就可以获取所需要的数据。如果发生高速缓存 未命中(cache miss),处理器需要用物理地址进一步访问主存储器来获得最终数据,数据也会填充到相应的高速缓存行中。上述描述的是VIPT(Virtual Index Physical Tag)的高速缓存组织方式。这个也是经典的cache运行模式了。
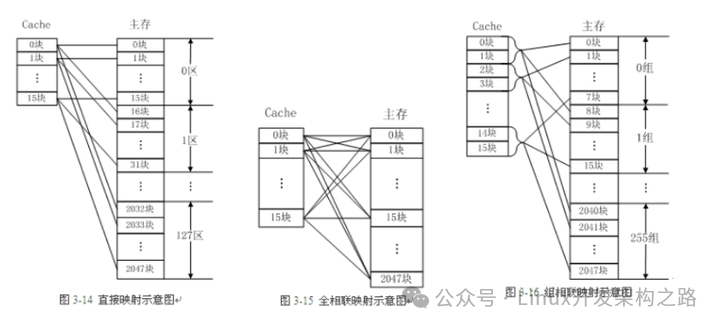
13.cache有哪几种映射方式?它们各自的优点和缺点是什么?
这里的映射指的是cache和主存之间的映射关系。常见的cache映射方式有三种:直接映射、全关联和组相连
-
直接映射:也就是cache和主存是一一对应的关系。但是,cache的大小是比主存要小得多的,也就是直接映射的话cache只能映射到主存的一小部分,如果处理器想要访问主存的地址A,而cache正好映射在主存地址A的这个区域,那自然好,但是如果处理器想要访问主存的地址B,而cache并没有映射到主存的这个区域,那么就会发生cache miss,那么cache就需要重新映射新的地址,如果处理器频繁地访问主存不同的地址数据,那么cache需要一直不断地重写,这样就会发生cache的颠簸,非常影响处理器效率。
-
全关联:全相联映射方式比较灵活,主存的各块可以映射到Cache的任一块中,Cache的利用率高,块冲突概率低,只要淘汰Cache中的某一块,即可调入主存的任一块。但是,由于Cache比较电路的设计和实现比较困难,这种方式只适合于小容量Cache采用。
-
组相连:组相连是现在最常见的一种cache映射方式,是直接映射和全关联的折中方法。也就是将一块内存分成了很多组,然后cache也分成了很多组,每组cache中都有多个cache line,例如,主存中的第0块、第8块……均映射于Cache的第0组,但可映射到Cache第0组中的第0块或第1块;主存的第1块、第9块……均映射于Cache的第1组,但可映射到Cache第1组中的第2块或第3块。这样就可以减少cache颠簸的概率。
14.怎样申请大块内核内存?
在Linux内核环境下,申请大块内存的成功率随着系统运行时间的增加而减少,虽然可以通过vmalloc系列调用申请物理不连续但虚拟地址连续的内存,但毕竟其使用效率不高且在32位系统上vmalloc的内存地址空间有限。所以,一般的建议是在系统启动阶段申请大块内存,但是其成功的概率也只是比较高而已,而不是100%。如果程序真的比较在意这个申请的成功与否,只能退用“启动内存”(Boot Memory)。下面就是申请并导出启动内存的一段示例代码:
void* x_bootmem = NULL;``EXPORT_SYMBOL(x_bootmem);`` ``unsigned long x_bootmem_size = 0;``EXPORT_SYMBOL(x_bootmem_size);`` ``static int __init x_bootmem_setup(char *str)``{` `x_bootmem_size = memparse(str, &str);` `x_bootmem = alloc_bootmem(x_bootmem_size);` `printk("Reserved %lu bytes from %p for x\n", x_bootmem_size, x_bootmem);`` ` `return 1;``}``__setup("x-bootmem=", x_bootmem_setup);
可见其应用还是比较简单的,不过利弊总是共生的,它不可避免也有其自身的限制:
内存申请代码只能连接进内核,不能在模块中使用。
被申请的内存不会被页分配器和slab分配器所使用和统计,也就是说它处于系统的可见内存之外,即使在将来的某个地方你释放了它。
一般用户只会申请一大块内存,如果需要在其上实现复杂的内存管理则需要自己实现。
在不允许内存分配失败的场合,通过启动内存预留内存空间将是我们唯一的选择。
15.用户进程间通信主要哪几种方式?
(1)管道(Pipe):管道可用于具有亲缘关系进程间的通信,允许一个进程和另一个与它有共同祖先的进程之间进行通信。
(2)命名管道(named pipe):命名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。命名管道在文件系统中有对应的文件名。命名管道通过命令mkfifo或系统调用mkfifo来创建。
(3)信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数)。
(4)消息(Message)队列:消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺
(5)共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
(6)信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
(7)套接字(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
16.通过伙伴系统申请内核内存的函数有哪些?
在物理页面管理上实现了基于区的伙伴系统(zone based buddy system)。对不同区的内存使用单独的伙伴系统(buddy system)管理,而且独立地监控空闲页。相应接口alloc_pages(gfp_mask, order),_ _get_free_pages(gfp_mask, order)等。
补充知识:
1.原理说明
Linux内核中采 用了一种同时适用于32位和64位系统的内 存分页模型,对于32位系统来说,两级页表足够用了,而在x86_64系 统中,用到了四级页表。
* 页全局目录(Page Global Directory)
* 页上级目录(Page Upper Directory)
* 页中间目录(Page Middle Directory)
* 页表(Page Table)
页全局目录包含若干页上级目录的地址,页上级目录又依次包含若干页中间目录的地址,而页中间目录又包含若干页表的地址,每一个页表项指 向一个页框。Linux中采用4KB大小的 页框作为标准的内存分配单元。
多级分页目录结构
1.1.伙伴系统算法
在实际应用中,经常需要分配一组连续的页框,而频繁地申请和释放不同大小的连续页框,必然导致在已分配页框的内存块中分散了许多小块的 空闲页框。这样,即使这些页框是空闲的,其他需要分配连续页框的应用也很难得到满足。
为了避免出现这种情况,Linux内核中引入了伙伴系统算法(buddy system)。把所有的空闲页框分组为11个 块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连 续页框,对应4MB大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍。
假设要申请一个256个页框的块,先从256个页框的链表中查找空闲块,如果没有,就去512个 页框的链表中找,找到了则将页框块分为2个256个 页框的块,一个分配给应用,另外一个移到256个页框的链表中。如果512个页框的链表中仍没有空闲块,继续向1024个页 框的链表查找,如果仍然没有,则返回错误。
页框块在释放时,会主动将两个连续的页框块合并为一个较大的页框块。
1.2.slab分配器
slab分配器源于 Solaris 2.4 的 分配算法,工作于物理内存页框分配器之上,管理特定大小对象的缓存,进行快速而高效的内存分配。
slab分配器为每种使用的内核对象建立单独的缓冲区。Linux 内核已经采用了伙伴系统管理物理内存页框,因此 slab分配器直接工作于伙伴系 统之上。每种缓冲区由多个 slab 组成,每个 slab就是一组连续的物理内存页框,被划分成了固定数目的对象。根据对象大小的不同,缺省情况下一个 slab 最多可以由 1024个页框构成。出于对齐 等其它方面的要求,slab 中分配给对象的内存可能大于用户要求的对象实际大小,这会造成一定的 内存浪费。
2.常用内存分配函数
2.1.__get_free_pages
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
__get_free_pages函数是最原始的内存分配方式,直接从伙伴系统中获取原始页框,返回值为第一个页框的起始地址。__get_free_pages在实现上只是封装了alloc_pages函 数,从代码分析,alloc_pages函数会分配长度为1<
2.2.kmem_cache_alloc
struct kmem_cache *kmem_cache_create(const char *name, size_t size,
size_t align, unsigned long flags,
void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long))
void *kmem_cache_alloc(struct kmem_cache *c, gfp_t flags)
kmem_cache_create/ kmem_cache_alloc是基于slab分配器的一种内存分配方式,适用于反复分配释放同一大小内存块的场合。首先用kmem_cache_create创建一个高速缓存区域,然后用kmem_cache_alloc从 该高速缓存区域中获取新的内存块。kmem_cache_alloc一次能分配的最大内存由mm/slab.c文件中的MAX_OBJ_ORDER宏定义,在默认的2.6.18内核版本中,该宏定义为5, 于是一次最多能申请1<<5 * 4KB也就是128KB的 连续物理内存。分析内核源码发现,kmem_cache_create函数的size参数大于128KB时会调用BUG()。测试结果验证了分析结果,用kmem_cache_create分 配超过128KB的内存时使内核崩溃。
2.3.kmalloc
void *kmalloc(size_t size, gfp_t flags)
kmalloc是内核中最常用的一种内存分配方式,它通过调用kmem_cache_alloc函数来实现。kmalloc一次最多能申请的内存大小由include/linux/Kmalloc_size.h的 内容来决定,在默认的2.6.18内核版本中,kmalloc一 次最多能申请大小为131702B也就是128KB字 节的连续物理内存。测试结果表明,如果试图用kmalloc函数分配大于128KB的内存,编译不能通过。
2.4.vmalloc
void *vmalloc(unsigned long size)
前面几种内存分配方式都是物理连续的,能保证较低的平均访问时间。但是在某些场合中,对内存区的请求不是很频繁,较高的内存访问时间也 可以接受,这是就可以分配一段线性连续,物理不连续的地址,带来的好处是一次可以分配较大块的内存。图3-1表 示的是vmalloc分配的内存使用的地址范围。vmalloc对 一次能分配的内存大小没有明确限制。出于性能考虑,应谨慎使用vmalloc函数。在测试过程中, 最大能一次分配1GB的空间。
Linux内核部分内存分布
2.5.dma_alloc_coherent
void *dma_alloc_coherent(struct device *dev, size_t size,
ma_addr_t *dma_handle, gfp_t gfp)
DMA是一种硬件机制,允许外围设备和主存之间直接传输IO数据,而不需要CPU的参与,使用DMA机制能大幅提高与设备通信的 吞吐量。DMA操作中,涉及到CPU高速缓 存和对应的内存数据一致性的问题,必须保证两者的数据一致,在x86_64体系结构中,硬件已经很 好的解决了这个问题,dma_alloc_coherent和__get_free_pages函数实现差别不大,前者实际是调用__alloc_pages函 数来分配内存,因此一次分配内存的大小限制和后者一样。__get_free_pages分配的内 存同样可以用于DMA操作。测试结果证明,dma_alloc_coherent函 数一次能分配的最大内存也为4M。
2.6.ioremap
void * ioremap (unsigned long offset, unsigned long size)
ioremap是一种更直接的内存“分配”方式,使用时直接指定物理起始地址和需要分配内存的大小,然后将该段 物理地址映射到内核地址空间。ioremap用到的物理地址空间都是事先确定的,和上面的几种内存 分配方式并不太一样,并不是分配一段新的物理内存。ioremap多用于设备驱动,可以让CPU直接访问外部设备的IO空间。ioremap能映射的内存由原有的物理内存空间决定,所以没有进行测试。
2.7.Boot Memory
如果要分配大量的连续物理内存,上述的分配函数都不能满足,就只能用比较特殊的方式,在Linux内 核引导阶段来预留部分内存。
2.7.1.在内核引导时分配内存
void* alloc_bootmem(unsigned long size)
可以在Linux内核引导过程中绕过伙伴系统来分配大块内存。使用方法是在Linux内核引导时,调用mem_init函数之前 用alloc_bootmem函数申请指定大小的内存。如果需要在其他地方调用这块内存,可以将alloc_bootmem返回的内存首地址通过EXPORT_SYMBOL导 出,然后就可以使用这块内存了。这种内存分配方式的缺点是,申请内存的代码必须在链接到内核中的代码里才能使用,因此必须重新编译内核,而且内存管理系统 看不到这部分内存,需要用户自行管理。测试结果表明,重新编译内核后重启,能够访问引导时分配的内存块。
2.7.2.通过内核引导参数预留顶部内存
在Linux内核引导时,传入参数“mem=size”保留顶部的内存区间。比如系统有256MB内 存,参数“mem=248M”会预留顶部的8MB内存,进入系统后可以调用ioremap(0xF800000,0x800000)来申请这段内存。
3.几种分配函数的比较
分配原理最大内存其他
__get_free_pages直接对页框进行操作4MB适用于分配较大量的连续物理内存
kmem_cache_alloc基于slab机制实现128KB适合需要频繁申请释放相同大小内存块时使用
kmalloc基于kmem_cache_alloc实现128KB最常见的分配方式,需要小于页框大小的内存时可以使用
vmalloc建立非连续物理内存到虚拟地址的映射物理不连续,适合需要大内存,但是对地址连续性没有要求的场合
dma_alloc_coherent基于__alloc_pages实现4MB适用于DMA操 作
ioremap实现已知物理地址到虚拟地址的映射适用于物理地址已知的场合,如设备驱动
alloc_bootmem在启动kernel时,预留一段内存,内核看不见小于物理内存大小,内存管理要求较高
17.下面程序会有怎样的输出呢?
int cnt = 0;
while(1) {
++cnt;
ptr = (char *)malloc(1024*1024*128);
if (ptr == NULL) {
printf(“%s\n”, “is null”);
break;
}
}
printf(“%d\n”, cnt);
在Linux32位机上输出的结果应该是:
is null
3057
为什么是3057?
因为用户态虚拟内存地址空间是3G,3057大概就是3G。
可见malloc时是在虚拟地址空间申请的,由于代码里并没有对申请的地址进行访问,所以实际上是不会分配物理内存的,直到对地址进行访问,由于缺页中断才开始处理页表映射,然后分配物理内存。
那如果有对地址进行访问,能够分到多少内存呢?
这就取决于Linux的内核参数和目前剩余的内存了!!!!
18.伙伴系统算法是怎么实现的?它和slab算法有什么区别?
伙伴系统中包含了多条内存链表,每条链表中的包含了多个内存大小相等的内存块(比如4KB链表,代表这台链表中所有的内存块大小都是4KB),比如我们想要分配一个8KB大小的内存,但是发现对应大小的链表上已经没有空闲内存块, 那么伙伴系统就会从16KB的链表中找到一个空闲内存块,然后分成两个8KB的大小,把其中一个返回给申请者使用,另一块放到8KB对应的链表中进行管理。到这里可能有童靴会有疑问:如果我只需要1KB甚至更小的内存,而伙伴系统链表中只有32KB的链表有空闲块了,那岂不是要切很久?
对于进程描述符这些对象大小比较小的,如果直接采用伙伴系统进行分配和释放,不仅会造成大量的内存碎片,并且在处理速度上也会比较慢,slab机制的工作就是针对一些 经常分配并释放的对象,它是基于对象进行管理的,相同类型的对象归为一类 , 每次要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样的大小出去,而当要释放时,将其重新保存到该列表中,而不是直接返回给伙伴系统 。注意:slab分配器最终还是由伙伴系统来分配物理页面的
19.Linux是如何避免内存碎片的?
使用伙伴系统算法来避免外部碎片,用slab算法来避免内部碎片
-
内部碎片:内部碎片就是已经被分配出去的,能明确指出属于哪个进程,缺不能被利用的内存空间(这个内存块被某一个进程占有,但是这个进程却不用它,然后别的进程也用不了它,这个内存块就被称为内部碎片)
-
外部碎片:外部碎片是指还没被分配出去,但是由于内存块太小了,无法分配给申请内存的进程。
20.用户态切换到内核态的方式有哪些?
系统调用:程序的执行一般是在用户态下执行的,但当程序需要使用操作系统提供的服务时, 比如说打开某一设备、创建文件、读写文件(这些均属于系统调用)等,就需要向操作系统发 出调用服务的请求,这就是系统调用。
异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由 当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
外围设备的中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时 CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执 行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
21.分页机制和分段机制有哪些共同点和区别呢?
共同点 :
-
分页机制和分段机制都是为了提高内存利用率,较少内存碎片。
-
页和段都是离散存储的,所以两者都是离散分配内存的方式。但是,每个页和段中的内存是连续的。
区别 :
-
页的大小是固定的,由操作系统决定;而段的大小不固定,取决于我们当前运行的程序。
-
分页仅仅是为了满足操作系统内存管理的需求,而段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满足用户的需要。
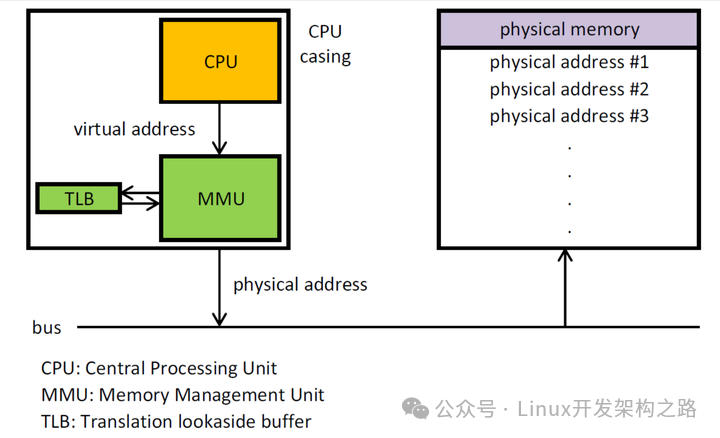
22.CPU 寻址了解吗?为什么需要虚拟地址空间?
现代处理器使用的是一种称为 虚拟寻址(Virtual Addressing) 的寻址方式。使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。实际上完成虚拟地址转换为物理地址转换的硬件是 CPU 中含有一个被称为 内存管理单元(Memory Management Unit, MMU) 的硬件。如图
为什么要有虚拟地址空间呢?
先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,程序都是直接访问和操作的都是物理内存 。但是这样有什么问题呢?
-
用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易(有意或者无意)破坏操作系统,造成操作系统崩溃。
-
想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行。为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
总结来说:如果直接把物理地址暴露出来的话会带来严重问题,比如可能对操作系统造成伤害以及给同时运行多个程序造成困难。
通过虚拟地址访问内存有以下优势:
-
程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
-
程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
-
不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
23.软件访问硬件的几种方式
软件访问硬件其实就是一种 IO 操作,软件访问硬件的方式,也就是 I/O 操作的方式有哪些。
硬件在 I/O 上大致分为并行和串行,同时也对应串行接口和并行接口。
随着计算机技术的发展,I/O 控制方式也在不断发展。选择和衡量 I/O 控制方式有如下三条原则
-
数据传送速度足够快,能满足用户的需求但又不丢失数据;
-
系统开销小,所需的处理控制程序少;
-
能充分发挥硬件资源的能力,使 I/O 设备尽可能忙,而 CPU 等待时间尽可能少。
24.聊聊软件访问硬件的几种方式
软件访问硬件其实就是一种 IO 操作,软件访问硬件的方式,也就是 I/O 操作的方式有哪些。
硬件在 I/O 上大致分为并行和串行,同时也对应串行接口和并行接口。
随着计算机技术的发展,I/O 控制方式也在不断发展。选择和衡量 I/O 控制方式有如下三条原则
(1) 数据传送速度足够快,能满足用户的需求但又不丢失数据;(2) 系统开销小,所需的处理控制程序少;(3) 能充分发挥硬件资源的能力,使 I/O 设备尽可能忙,而 CPU 等待时间尽可能少。
根据以上控制原则,I/O 操作可以分为四类
-
直接访问:直接访问由用户进程直接控制主存或 CPU 和外围设备之间的信息传送。直接程序控制方式又称为忙/等待方式。
-
中断驱动:为了减少程序直接控制方式下 CPU 的等待时间以及提高系统的并行程度,系统引入了中断机制。中断机制引入后,外围设备仅当操作正常结束或异常结束时才向 CPU 发出中断请求。在 I/O 设备输入每个数据的过程中,由于无需 CPU 的干预,一定程度上实现了 CPU 与 I/O 设备的并行工作。
上述两种方法的特点都是以 CPU 为中心,数据传送通过一段程序来实现,软件的传送手段限制了数据传送的速度。接下来介绍的这两种 I/O 控制方式采用硬件的方法来显示 I/O 的控制
-
DMA 直接内存访问:为了进一步减少 CPU 对 I/O 操作的干预,防止因并行操作设备过多使 CPU 来不及处理或因速度不匹配而造成的数据丢失现象,引入了 DMA 控制方式。
-
通道控制方式:通道,独立于 CPU 的专门负责输入输出控制的处理机,它控制设备与内存直接进行数据交换。有自己的通道指令,这些指令由 CPU 启动,并在操作结束时向 CPU 发出中断信号。
25.线程间的同步方式有四种
临界区
临界区对应着一个 CcriticalSection 对象,当线程需要访问保护数据时,调用 EnterCriticalSection 函数;当对保护数据的操作完成之后,调用 LeaveCriticalSection 函数释放对临界区对象的拥有权,以使另一个线程可以夺取临界区对象并访问受保护的数据。
PS: 关键段对象会记录拥有该对象的线程句柄即其具有 “线程所有权” 概念,即进入代码段的线程在 leave 之前,可以重复进入关键代码区域。所以关键段可以用于线程间的互斥,但不可以用于同步(同步需要在一个线程进入,在另一个线程 leave)
互斥量
互斥与临界区很相似,但是使用时相对复杂一些(互斥量为内核对象),不仅可以在同一应用程序的线程间实现同步,还可以在不同的进程间实现同步,从而实现资源的安全共享。
PS:
-
互斥量由于也有线程所有权的概念,故也只能进行线程间的资源互斥访问,不能由于线程同步;
-
由于互斥量是内核对象,因此其可以进行进程间通信,同时还具有一个很好的特性,就是在进程间通信时完美的解决了 “遗弃” 问题。
信号量
信号量的用法和互斥的用法很相似,不同的是它可以同一时刻允许多个线程访问同一个资源,PV 操作
PS: 事件可以完美解决线程间的同步问题,同时信号量也属于内核对象,可用于进程间的通信。
事件
事件分为手动置位事件和自动置位事件。事件 Event 内部它包含一个使用计数(所有内核对象都有),一个布尔值表示是手动置位事件还是自动置位事件,另一个布尔值用来表示事件有无触发。由 SetEvent() 来触发,由 ResetEvent() 来设成未触发。
PS: 事件是内核对象,可以解决线程间同步问题,因此也能解决互斥问题。
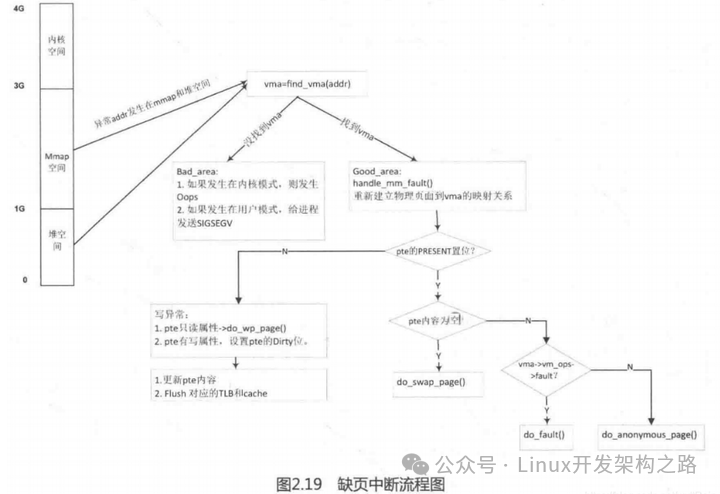
26.什么是缺页中断?发生缺页中断后的处理流程是怎么样的?
我们知道用户空间存在虚拟内存,而用户进程访问虚拟内存的时候,正常情况下,虚拟内存和物理内存需要建立映射关系,用户才可以进一步去访问对应的物理内存,而当进程去访问那些还没有建立映射关系的虚拟内存时,CPU就会触发一个缺页中断异常。
27.何为中断上下文?为什么中断上下文中不能调用含有睡眠的函数?
当CPU响应一个中断并正在执行中断服务程序,那么内核处于中断上下文中。
当ARM处理器响应中断时,ARM处理器会自动保存终端店的CPSR寄存器和LR寄存器内容,并关闭本地中断,进入IRQ模式。
但在Linux内核中,ARM IRQ模式很短暂(中断上半部执行非常快),很快就退出IRQ模式进入SVC模式,并且把IRQ模式的栈内容负责到SVC模式的栈中,保存中断现场,也就是说中断上下文运行在SVC模式下。既然中断上下文运行在SVC模式下,并且中断现场已经保存在中断打断的进程的内核栈中,为什么中断上下文不能睡眠呢?
假使现在CPU正在执行一个进程A,这个时候发生了中断,那么中断处理函数会用进程A的内核栈来保存中断上下文。睡眠是什么概念呢?也就是需要调用schedule()函数让当前的进程让出CPU,选择另一个进程继续执行。如果这个时候再发生睡眠或者中断,那么会将中断上下文覆盖了原本进程A的内核栈,当后面这个中断返回的时候,找不到最开始的那个中断的上下文,就再也回不去上一次的中断处理函数中了。
28.什么是软中断?什么是tasklet?什么是工作队列
软中断是预留给系统中对时间要求最为严格和最重要的下半部使用的,而且目前驱动中只有块设备和网络子系统使用了软中断。软中断指的,其实就是我们上面所描述的中断的下半部的处理程序。一般是以内核线程的方式运行。系统静态定义了若干种软中断的类型。并且Linux内核开发者不希望用户再扩充新的软中断类型,如果需要,建议使用tasklet
tasklet是基于软中断机制的另一种变种,运行在软中断上下文中。
workqueue是以内核线程的方式来处理中断下半部事务,是基于进程上下文的,而软中断和tasklet是基于中断上下文的,优先级要比进程上下文高,所以当软中断或者tasklet的处理时间太长的话,如果在对于实时性要求较高的进程中发生了中断,那么对于系统性能影响会很大。
29.说说Linux内核中的写时复制技术
在传统的UNIX操作系统中,创建新进程的时候会复制父进程拥有的所有资源,这样进程的创建就变得很低效。每次创建子进程时都要把父进程的进程地址空间的内容复制到子进程,但是子进程又不一定需要用到这些资源,出现没必要的复制动作,浪费了资源。
现代操作系统都采用 写时复制技术(COW) 。该技术就是在父进程创建子进程的时候不需要复制进程地址空间的内容给子进程,只需要负责父进程的进程地址空间的页表给子进程, 这样父子进程就可以共享相同的物理内存了。当父子进程的其中一方需要修改到物理内存时,就会触发 写保护的缺页异常, 才会把共享页面的内容复制出来,从而让父子进程拥有各自的副本。
30.什么是异常向量?ARM架构中的异常向量分成哪几种?
当系统发生异常时,程序跳到一个固定地址继续运行,不同类型的异常都有固定的地址,这个固定的异常地址就叫做异常向量。在ARM的架构中,异常向量分成7种
1、RESET:当系统正常运行的过程中,按下了RESET,就会跳到RESET异常去进行重启动作
2、Undefined instructions:处理器无法识别指令的异常, 处理器执行的指令是有规范的, 如果 尝试执行 不符合要求的指令, 就会进入到该异常指令对应的地址中
3、Software Interrupt:软中断,软件中需要打断处理器工作,可以使用软中断实现
4、Prefetch Abort:预取指令失败, ARM 在执行指令的过程中, 要先去预取指令准备执行, 如果预取指令失败, 就会产生该异常
5、Data Abort”:获取数据失败
6、IQR:中断
7、FIQ:快速中断
31.如何处理 Linux 中的内核崩溃问题?
-
检查日志:检查/var/log/messages、/var/log/syslog和dmesg中是否有相关消息。
-
检查硬件:确保没有硬件故障,如 RAM 故障或过热。
-
检查内核更新:确保内核是最新的,如果最近的更新导致问题,则考虑回滚。
-
验证系统配置:检查系统文件和启动参数中是否存在错误配置。
-
测试内核模块:删除或更新任何有问题的内核模块。
-
使用 kdump:配置 kdump 以捕获核心转储以供进一步分析。
32.系统调用read( )/write( ),内核具体做了什么?
-
用户空间发起read()/write()系统调用,并将参数传递给内核。
-
内核根据系统调用号找到相应的内核函数进行处理,如sys_read()/sys_write()。
-
内核根据文件描述符找到对应的文件对象,并执行读取或写入操作。
-
在读取操作中,内核将数据从文件或设备读取到内核空间,并通过页缓存层进行管理。
-
在写入操作中,内核将数据从用户空间拷贝到内核空间,并通过文件系统层将数据写入文件或设备。
-
内核可能会通过缓存管理、块设备管理和驱动程序等层次对数据进行处理和传输。
33.堆栈溢出一般是由什么原因导致的?
-
递归调用深度过大:如果递归函数的层次过多,每个函数调用都会在栈上分配一定的内存空间,当递归层次太深时,可能会超出栈的容量。
-
局部变量和数组占用过多空间:当函数内定义的局部变量或者数组占用的内存空间过多时,超出了栈的容量限制,就会发生堆栈溢出。
-
函数调用参数传递错误:如果函数调用时传递的参数错误或者参数数量不匹配,可能导致函数内部使用了错误的参数值而引起堆栈溢出。
-
递归调用条件不正确:在递归算法中,没有正确设置终止条件,导致无限循环调用自身而造成堆栈溢出。
-
缓冲区溢出:当输入数据长度超过程序预留缓冲区大小时,写入数据就会超出缓冲区范围,覆盖到相邻内存空间,从而引起堆栈溢出。
34.深拷贝和浅拷贝的区别
拷贝的内容:
-
浅拷贝只复制对象的指针或引用,不会创建新的对象副本。因此,原对象和拷贝后的对象会共享同一块内存空间。
-
深拷贝会创建一个全新的独立对象,并将原对象中的所有数据进行复制。这样,在内存中会存在两个完全独立且相同内容的对象。
对象关系:
-
浅拷贝保留了原始对象和拷贝对象之间的关联关系。如果原始对象发生改变,可能会影响到拷贝后的对象。
-
深拷贝破除了原始对象和拷贝对象之间的关联关系。它们在内存中是完全独立、互不干扰的。
内存管理:
-
浅拷贝并不需要额外分配内存,只需简单地复制指针或引用即可。
-
深拷贝需要分配额外内存来保存完整数据副本,并确保对应资源释放时不会出现冲突。
35.多线程如何保证线程安全
-
互斥锁(Mutex):使用互斥锁来实现对共享资源的互斥访问。只有获得锁的线程才能执行临界区代码,其他线程需要等待。
-
读写锁(ReadWrite Lock):适用于读操作远远超过写操作的场景。允许多个线程同时读取共享资源,但在写入时需要独占访问。
-
原子操作(Atomic Operations):使用原子操作可以确保某个操作是不可分割、不会被中断的。常见原子操作包括自增、自减、交换等。
-
条件变量(Condition Variable):用于实现线程间的等待和通知机制。当一个条件不满足时,线程可以等待条件变量;当满足条件时,通过发送信号或广播唤醒等待中的线程。
-
线程安全数据结构:选择已经封装好的线程安全数据结构,如并发队列、并发哈希表等。这些数据结构已经考虑了并发访问下的一致性和同步问题。
-
同步控制:使用同步控制机制来限制对共享资源的访问。如使用信号量、屏障等来协调线程的执行顺序。
-
避免共享数据:尽可能避免多个线程直接访问共享数据,通过消息传递或其他方式来实现线程间的通信。
-
线程安全编程范式:在设计和编写代码时,采用一些线程安全的编程范式,如不可变对象、函数式编程等。
36.socket在什么情况下可读?
-
接收缓冲区有数据,一定可读
-
对方正常关闭socket,也是可读
-
对于侦听socket,有新连接到达也可读
-
socket有错误发生,且pending
37.TCP通讯中,select到读事件,但是读到的数据量是0,为什么,如何解决?
select 返回0代表超时。select出错返回-1。
select到读事件,但是读到的数据量为0,说明对方已经关闭了socket的读端。本端关闭读即可。
当select出错时,会将接口置为可读又可写。这时就要通过判断select的返回值为-1来区分。
38.tcp连接建立的时候3次握手,断开连接的4次握手的具体过程
三次握手 — 第一次握手是客户端connect连接到server,server accept client的请求之后,向client端发送一个消息,相当于说我都准备好了,你连接上我了,这是第二次握手,第3次握手就是client向server发送的,就是对第二次握手消息的确认。之后client和server就开始通讯了。
四次握手 — 断开连接的一端发送close请求是第一次握手,另外一端接收到断开连接的请求之后需要对close进行确认,发送一个消息,这是第二次握手,发送了确认消息之后还要向对端发送close消息,要关闭对对端的连接,这是第3次握手,而在最初发送断开连接的一端接收到消息之后,进入到一个很重要的状态time_wait状态,这个状态也是面试官经常问道的问题,最后一次握手是最初发送断开连接的一端接收到消息之后。对消息的确认。
39.connect方法会阻塞,请问有什么方法可以避免其长时间阻塞?
最通常的方法最有效的是加定时器;也可以采用非阻塞模式。
或者考虑采用异步传输机制,同步传输与异步传输的主要区别在于同步传输中,如果调用recvfrom后会一致阻塞运行,从而导致调用线程暂停运行;异步传输机制则不然,会立即返回。
40.socket编程,如果client断电了,服务器如何快速知道?
使用定时器(适合有数据流动的情况);使用socket选项SO_KEEPALIVE(适合没有数据流动的情况);

黑客/网络安全学习包


资料目录
-
成长路线图&学习规划
-
配套视频教程
-
SRC&黑客文籍
-
护网行动资料
-
黑客必读书单
-
面试题合集
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

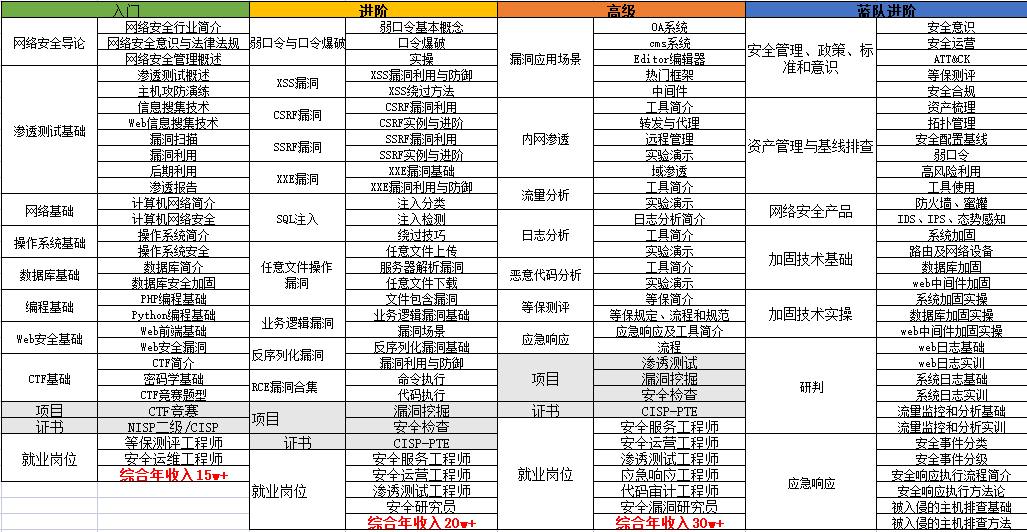
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
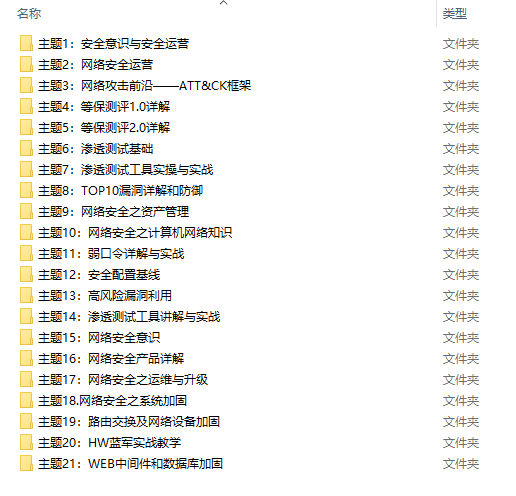
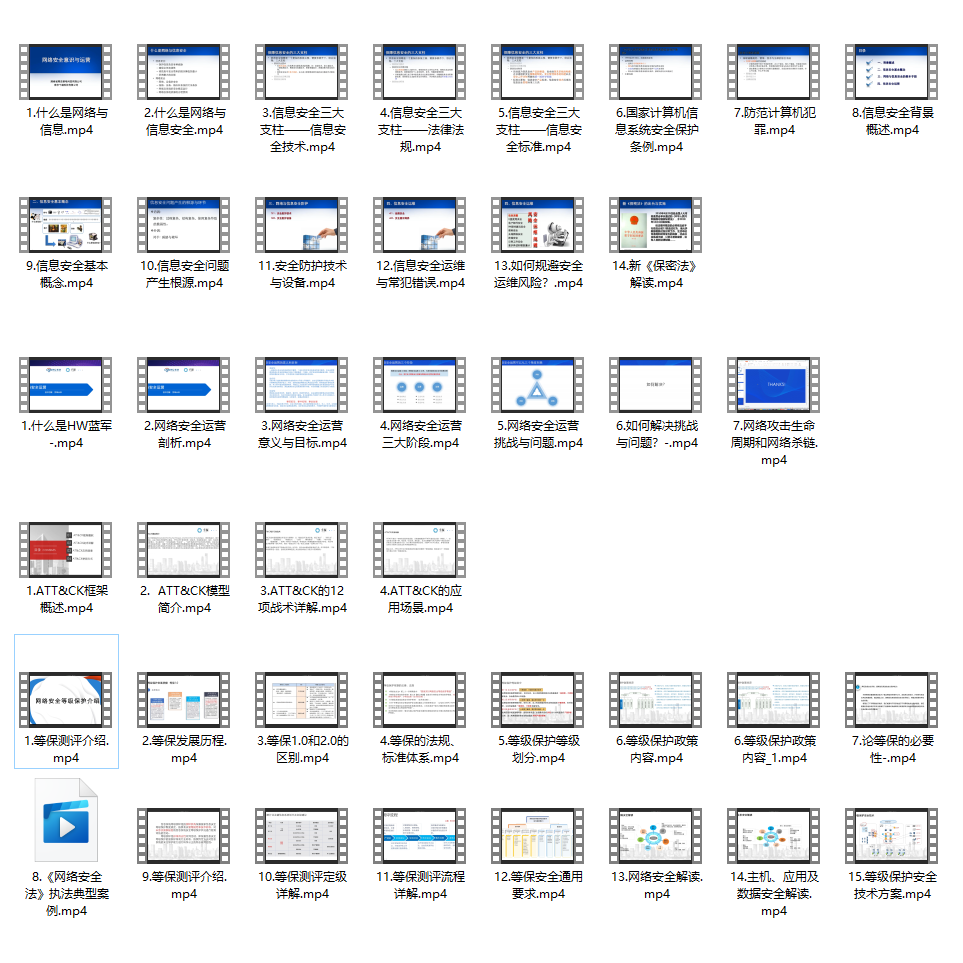
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
CSDN大礼包:《黑客&网络安全入门&进阶学习资源包》免费分享
3.SRC&黑客文籍
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!
4.护网行动资料
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!
5.黑客必读书单
**

**
6.面试题合集
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
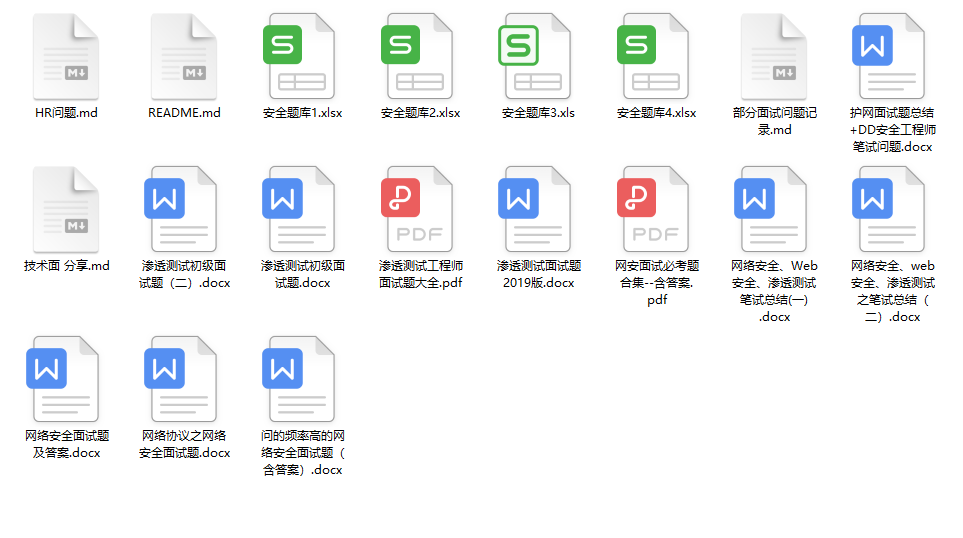
更多内容为防止和谐,可以扫描获取~

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









