






一、Hive数据
1.数据展示
数据来源:KingCountry数据集
数据解释:longtitude double类型:经度,latitude double类型:纬度

2.实现目标
目的:根据经纬度转换成具体地址,如:某国某省某市某街道
二、环境配置
Hadoop:3.1.3
Hive:3.1.3
Mysql:8
JDK:1.8
集群:hadoop102,hadoop103,hadoop104
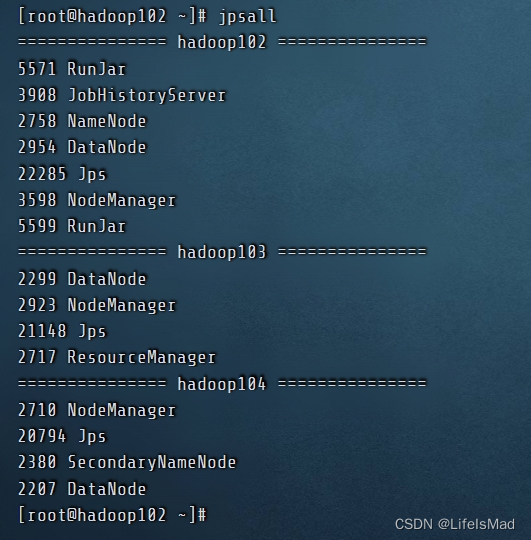
非高可用,jpsall 如下
三、GenericUDF概念介绍
直接参考 https://juejin.cn/post/6984580196594614308
四、Java GenericUDF编写
1.Maven配置
(1)本地仓库配置
IDEA Maven的默认仓库地址在C盘用户目录下的.m2下,需要将整个.m2迁移至D盘下
找到IDEA Maven的安装目录中的settings.xml文件和chains.xml文件并迁移至.m2目录
(2)setting.xml配置
关于阿里云镜像的配置,不配置的话下载速度高达0.1kb/s
-<mirrors>
<!-- mirror| Specifies a repository mirror site to use instead of a given repository. The repository that| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.| <mirror><id>aliyun</id><mirrorOf>central</mirrorOf><name>aliyun</name><url>https://maven.aliyun.com/repository/public</url> </mirror> -->
-<mirror>
<id>aliyun</id>
<mirrorOf>central</mirrorOf>
<name>aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
-<mirror>
<id>maven-default-http-blocker</id>
<mirrorOf>external:http:*</mirrorOf>
<name>Pseudo repository to mirror external repositories initially using HTTP.</name>
<url>http://0.0.0.0/</url>
<blocked>true</blocked>
</mirror>
</mirrors>(3)IDEA配置
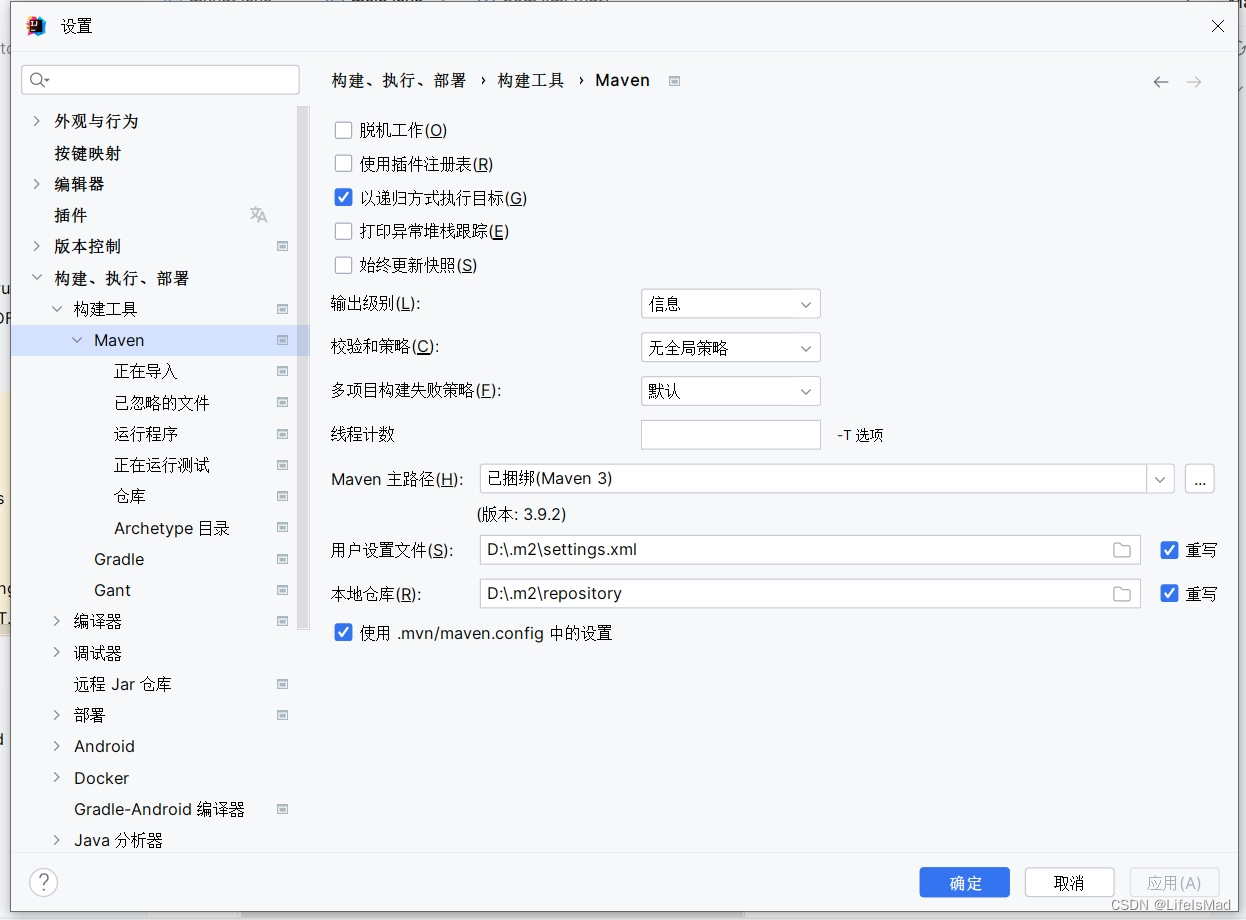
修改用户设置文件,本地仓库地址,设置重写,修改成迁移后的目录,分别对应仓库repository和设置文件settings.xml
2.pom.xml环境依赖配置
包括:
hadoop对应版本依赖
hive对应版本依赖
junit版本(是一个测试框架,但是目前还不会使用)
阿里巴巴依赖(因为案例调用了百度地图接口的坐标转换服务)
Maven打包全部依赖的插件maven-assembly-plugin
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>udf</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<!--添加 hive 依赖-->
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
<dependency>
<groupId>org.jetbrains</groupId>
<artifactId>annotations-java5</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
</dependencies>
<!-- 添加这个插件,可以打包的时候把依赖都打包了 -->
<build>
<plugins>
<!-- Maven Assembly Plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<!-- get all project dependencies -->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<!-- bind to the packaging phase -->
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>2.GenericUDF类
结合测试类和注释,哪里不懂就测试一下,然后println就完事
这里漏了判断空值的情况
需要在遇到参数值为null的情况下特殊处理,比如return null
package com.tipdm.udf;
import com.alibaba.fastjson.JSON;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.DoubleObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import java.util.concurrent.TimeUnit;
public class myudf extends GenericUDF {
/*
三个@Override必写
*/
// 全局变量
DoubleObjectInspector longitude;
DoubleObjectInspector latitude;
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
/*
initialize:
1.涉及参数个数的确认
2.参数类型的确认(xxxxObejectInspector,xxxx可以理解为hive表字段类型)
3.最终udf返回类型的确认(
return PrimitiveObjectInspectorFactory.javaxxxxObjectInspector
xxxx可以理解为最终处理后的输出的hive字段类型
and 这个工厂类似乎是为了方便hive类型转为maperreduce类型(工厂类下有getWritable方法)
)
4.initialize在整个udf过程中只运行一次,可以类比mapperreduce的setup初始化
5.ObjectInspector[]中存储的应该是参数对象,不包括参数的具体值
*/
if (arguments.length!=2){
throw new UDFArgumentException("参数个数不为2");
}
ObjectInspector a = arguments[0];
//System.out.println(a );
//System.out.println();
ObjectInspector b = arguments[1];
if (!(a instanceof DoubleObjectInspector) || !(b instanceof DoubleObjectInspector)) {
throw new UDFArgumentException("first argument must be a list / array, second argument must be a string");
}
this.longitude= (DoubleObjectInspector) a;
this.latitude= (DoubleObjectInspector) b;
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arg) throws HiveException {
/*
evaluate:
1.evaluate可以类比于map,对传入数据的每一行进行处理
例如:传入两列,第一行为(1,0),对第一行进行处理再到第二行
!!!!默认情况下,没有先后依赖的话,evalate应该是并发执行的!!!!
每个节点都会执行evaluate的内容!!
如果有需要向外部发送请求的情况,需要考虑设置并发延迟,控制并发数量,防止请求被阻断
2.DeferredObject[]中存储的应该是参数的具体数值,是经过序列化的,需要反序列化
3.正确获取参数的值后,按照预定逻辑处理即可
*/
String longitude= String.valueOf(this.longitude.getPrimitiveJavaObject(arg[0].get()));
//System.out.println(longitude);
String latitude= String.valueOf(this.longitude.getPrimitiveJavaObject(arg[1].get()));
//System.out.println(latitude);
try {
// 对应最终返回的数据类型,这里java基本类型或者Writable类型似乎也可以
return getLocationByBaiduMap(longitude,latitude);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
@Override
public String getDisplayString(String[] strings) {
/*
getDisplayString:
1.当程序报错的时候显示的内容,string[0]返回的是 xxxx evaluate xxxx 啥的
狗屎一坨,最容易出问题不就是evaluate还能是哪,initialize都没啥好改的
毫无参考价值
2.我的建议是返回“我爱BUG“
3.废物方法
*/
return strings[0];
}
public String getLocationByBaiduMap(String longitude,String latitude) throws Exception {
// 百度ak,需要自行去百度申请开发者账号,申请应用服务
String ak = "czxhaztj6bdGnOmbwnrwpvCoWx8AqiOi";
String addrJson;
String resultjson;
String addr;
/*
1.发送请求
2.检查状态码,是否被阻断
3.若被阻断则等待几秒钟,直到不阻断,能够正常获取请求的结果
!!或者可以2w/月开个会员,那就不用等待了 qwq !!
*/
do {
addrJson = geturl("http://api.map.baidu.com/reverse_geocoding/v3/?ak=" + ak + "&location=" + latitude + "," + longitude + "&output=json&pois=1");
//System.out.println(addrJson);
//System.out.println(JSON.parseObject(addrJson).get("status").toString());
if (JSON.parseObject(addrJson).get("status").toString().equals("0")){
break;
}
//System.out.println(JSON.parseObject(resultjson).get("formatted_address").equals(""));
else {
TimeUnit.SECONDS.sleep(5);
System.out.println(1);
}
//String addr=jobjectaddr.getJSONObject("result").getString("formatted_address");
}while (!JSON.parseObject(addrJson).get("result").toString().equals("0"));
// 处理请求返回的结果
resultjson = JSON.parseObject(addrJson).get("result").toString();
// System.out.println(resultjson);
addr = JSON.parseObject(resultjson).get("formatted_address").toString();
return addr;
}
private static String geturl(String geturl) throws Exception {
//请求的webservice的url
URL url = new URL(geturl);
//创建http链接,得到connection对象
HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection();
//设置请求的方法类型
httpURLConnection.setRequestMethod("POST");
//设置请求的内容类型
httpURLConnection.setRequestProperty("Content-type", "application/x-www-form-urlencoded");
//设置发送数据
httpURLConnection.setDoOutput(true);
//设置接受数据
httpURLConnection.setDoInput(true);
//发送数据,使用输出流
OutputStream outputStream = httpURLConnection.getOutputStream();
//发送的soap协议的数据
String content = "user_id="+ URLEncoder.encode("用户Id", "utf-8");
//发送数据
outputStream.write(content.getBytes());
//接收数据
InputStream inputStream = httpURLConnection.getInputStream();
BufferedReader in = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"));
StringBuffer buffer = new StringBuffer();
String line = "";
while ((line = in.readLine()) != null){
buffer.append(line);
}
String str = buffer.toString();
return str;
}
}
3.GenericUDF测试类
import com.tipdm.udf.myudf;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.JavaStringObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class main {
public static void main(String[] args) throws Exception {
myudf example=new myudf();
ObjectInspector longtitude = PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;
ObjectInspector lagitude=PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;
// 测试initialize
JavaStringObjectInspector resultInspector = (JavaStringObjectInspector) example.initialize(new ObjectInspector[]{longtitude, lagitude});
System.out.println(resultInspector.toString());
// 测试evaluate,一条数据
System.out.println(example.evaluate(new GenericUDF.DeferredObject[]{new GenericUDF.DeferredJavaObject(-122.113),new GenericUDF.DeferredJavaObject(44)}));
//JavaStringObjectInspector resultInspector = (JavaStringObjectInspector) example.initialize(new ObjectInspector[]{longtitude, lagitude});
//System.out.println(new com.tipdm.udf.myudf().initialize((ObjectInspector[]) new DoubleObjectInspector[]{new DoubleINs(122),new DoubleObjectInspector(47)}));
}
}
4.容易出现的问题
最容易出问题的就是evaluate的执行过程,基本上问题都出在这,本例中出现最多的就是空指针问题,将一个null指向了变量,所以最好多测试不同的情况,以排查可能出现问题的语句
四、GenericUDF打包上传至集群
1.打包方式的选择
网上提供的打包方式有三种,一种是上传至HDFS,一种是直接将打包好的jar包直接放入服务器hive目录的lib目录下,另一种是在hive目录下创建auxlib目录,并在hive的conf目录下vim hive-site.xml添加auxlib目录的配置
生产开发中只考虑第一种
以下是打包过程
IDEA右侧M图标,生命周期下双击package即可,要注意检查插件和依赖有无缺失
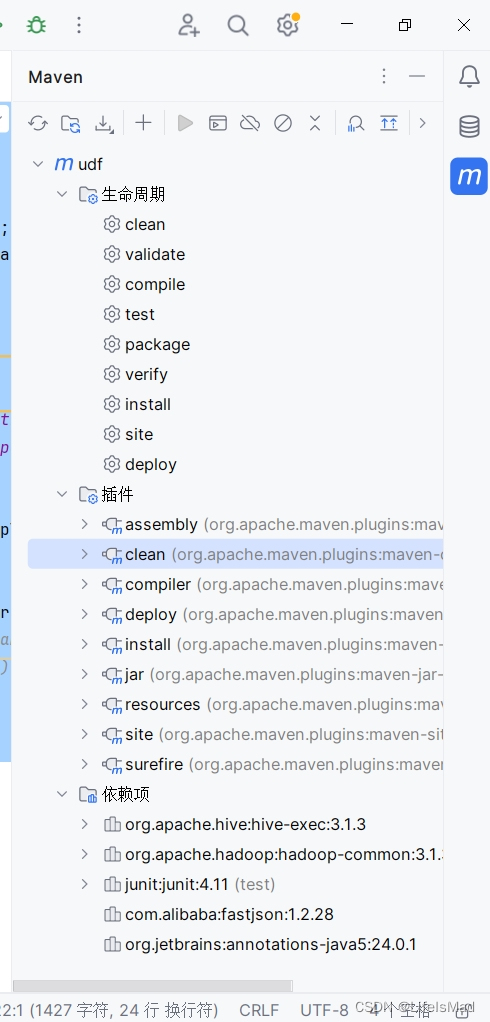
打包后的jar包在项目的tar目录下

2.上传过程可能遇到的问题
文件大小几十MB以上,如果上传后只有几KB,那就没有打包依赖或者上传错文件,注意检查
打包了依赖的jar包后缀是带有jar-with-dependencies的

五、创建永久函数
1.HiveSQL代码
set role admin;
create function gotbaiduaddr as 'com.tipdm.udf.myudf' USING JAR 'hdfs:///udf-1.0-SNAPSHOT-jar-with-dependencies.jar' ;
drop function gotbaiduaddr;
show functions like "*got*";
reload function ;
select
gotbaiduaddr(longitude,latitude)
from dwd_kingcountry_house
limit 0,1000;2.注意事项
(1)权限问题
创建函数和删除函数需要在admin角色下,这个admin是在hive中的角色,拥有超级权限,如果不在admin角色下执行会报权限错误
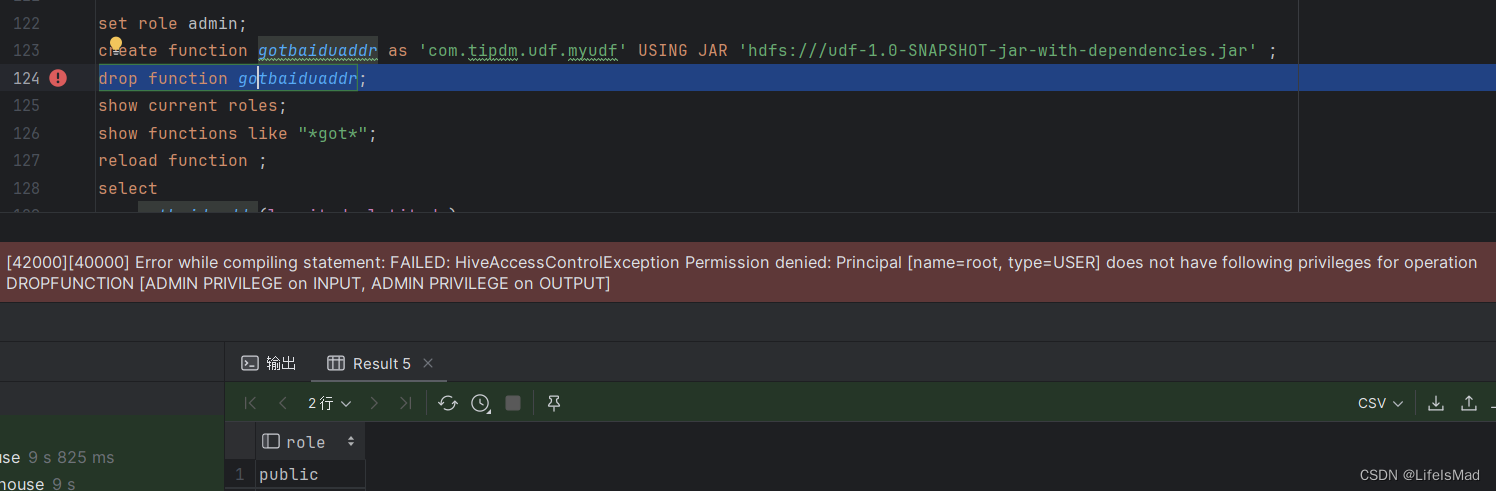
而连接登录时所使用的用户是root,角色是public,而在hive-site.xml中,设置的管理员是root用户,却不能以管理员直接登录,参考hive-site.xml如下
a.hive-site.xml参考
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.security.authorization.enabled</name>
<value>true</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<property>
<name>hive.users.in.admin.role</name>
<value>root</value>
</property>
<property>
<name>hive.security.authorization.manager</name>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory</value>
</property>
<property>
<name>hive.security.authenticator.manager</name>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value>
</property>
</configuration>
hive.users.in.admin.role可能要这么理解
设置的是可以拥有admin角色的用户,我这里是root,我使用root登录的时候,默认是public角色,应该是一个普通权限的角色,这样的设置可能是为了更安全的操作,当需要在admin角色下操作的时候,需要手动切换角色,网上说可以同时存在多个角色,但应该是只能有一个角色在生效
(2)函数语法问题
create function gotbaiduaddr as 'com.tipdm.udf.myudf' USING JAR 'hdfs:///udf-1.0-SNAPSHOT-jar-with-dependencies.jar' ;create function xxx:创建的时候需要注意当前在哪个数据库下,在哪个数据库下创建就只能在哪个数据库下使用,可以指定数据库,如 create function db_name.func_name
as "xxxxx":指定类名,如果这个类在包下则写包路径,如“com.xxx.xxx.xxx类”,如果不在包目录下直接写类名“xxxx类”
using jar "xxxx.jar":jar包路径要添加hdfs前缀hdfs://
(3)函数同步问题
创建函数之后,根据网上资料,需要同步函数,重新加载函数库才能使用,别的用户也才能使用,但是在测试过程中发现
reload function后函数不会更新,如果你创建了个函数,然后删除这个函数,再重新创建,再reload function 函数并不能直接马上更新,还是原来的函数,所有在测试的时候还是
drop function后,重启hiveserver2,重新连接后再去create function,忒麻烦














 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









