






我是一个2023年面试的java程序员,工作经验是两年,下面我要记录我面试的内容。欢迎大家一起探讨一起学习,有不正确的地方勿喷,希望大佬指教。如有侵权的文章可联系我删除。
一.代码优化细节
1、尽量指定类、方法的final修饰符
带有final 修饰符的类是不可派生的。在Java核心API中,有许多应用final的例子,例如java.lang.String,整个类都是 final的。为类指定final修饰符可以让类不可以被继承,为方法指定final修饰符可以让方法不可以被重写。如果指定了一个类为final,则该 类所有的方法都是final的。Java编译器会寻找机会内联所有的final方法,内联对于提升Java运行效率作用重大,具体参见Java运行期优 化。此举能够使性能平均提高50%。
2.尽量重用对象特别是String对象的使用
出现字符串连接时应该使用StringBuilder/StringBuffer代替。由于Java虚拟机不仅要花时间生成对象,以后可能还需要花时间对这些对象进行垃圾回收和处理,因此,生成过多的对象将会给程序的性能带来很大的影响。
3、尽可能使用局部变量
调用方法时传递的参数以及在调用中创建的临时变量都保存在栈中速度较快,其他变量,如静态变量、实例变量等,都在堆中创建,速度较慢。另外,栈中创建的变量,随着方法的运行结束,这些内容就没了,不需要额外的垃圾回收。
4、及时关闭流
Java编程过程中,进行数据库连接、I/O流操作时务必小心,在使用完毕后,及时关闭以释放资源。因为对这些大对象的操作会造成系统大的开销,稍有不慎,将会导致严重的后果。
二.给你两张关联,一张主表,一张附表,实现查出主表的数据还有附表与主表关联的数据,并且分页展示出来。
先新建表容易理解
建表语句:
CREATE TABLE `a_table` (
`a_id` int(11) DEFAULT NULL,
`a_name` varchar(10) DEFAULT NULL,
`a_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8CREATE TABLE `b_table` (
`b_id` int(11) DEFAULT NULL,
`b_name` varchar(10) DEFAULT NULL,
`b_part` varchar(10) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8使用左外连接多表联查实现查出主表的数据还有附表与主表关联的数据
关键字:left join on / left outer join on
语句:select * from a_table a left join b_table b on a.a_id = b.b_id;
执行结果:

说明:
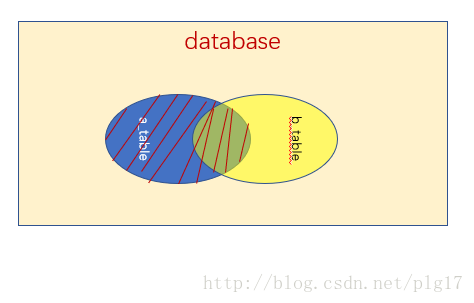
left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。
左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL
原文链接:https://blog.csdn.net/plg17/article/details/78758593
分页实现
MyBatis 分页插件 PageHelper
第一步:导包
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.1.2</version>
</dependency>第二步:配置到spring 和mybait 整合的配置文件中
<!--3.创建sqlSessionFactory-->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource"></property>
<!--配置mybatis 插件-->
<property name="plugins">
<set>
<!--配置pageHelper 分页插件-->
<bean class="com.github.pagehelper.PageInterceptor">
<property name="properties">
<props>
<!--方言:-->
<prop key="helperDialect">mysql</prop>
</props>
</property>
</bean>
</set>
</property>
</bean>第三步:方法调用
使用PageHelper.startPage 静态方法调用startPage :
特点:
1. 静态方法,传递两个参数(当前页码,每页查询条数)
2. 使用pageHelper 分页的时候,不再关注分页语句,查询全部的语句
3. 自动的对PageHelper.startPage 方法下的第一个sql 查询进行分页
PageHelper.startPage(1,5);
//紧跟着的第一个select 方法会被分页
List<Country> list = countryMapper.findAll();
也就是说再Service层PageHelper.startPage(1,5);语句后一定是紧跟查询语句。
Service层示例代码
public PageInfo findPage(int page,int pageSize){
PageHelper.startPage(page,pageSize);
List<Company> List=companyDao.selectAll();
PageInfo pageInfo = new PageInfo(list);
return pageInfo;
}
返回的信息就是pageInfo对象,该类是插件里的类,这个类里面的属性还是值得看一看
public class PageInfo<T> implements Serializable {
private static final long serialVersionUID = 1L;
//当前页
private int pageNum;
//每页的数量
private int pageSize;
//当前页的数量
private int size;
//由于startRow 和endRow 不常用,这里说个具体的用法
//可以在页面中"显示startRow 到endRow 共size 条数据"
//当前页面第一个元素在数据库中的行号
private int startRow;
//当前页面最后一个元素在数据库中的行号
private int endRow;
//总记录数
private long total;
//总页数
private int pages;
//结果集
private List<T> list;
//前一页
private int prePage;
//下一页
private int nextPage;
//是否为第一页
private boolean isFirstPage = false;
//是否为最后一页
private boolean isLastPage = false;
//是否有前一页
private boolean hasPreviousPage = false;
//是否有下一页
private boolean hasNextPage = false;
//导航页码数
private int navigatePages;
//所有导航页号
private int[] navigatepageNums;
//导航条上的第一页
private int navigateFirstPage;
//导航条上的最后一页
private int navigateLastPage;
}第四步:在Controller中,将service层返回来的PageInfo对象放入request域中
在jsp页面中的取值根据PageInfo中的get方法,使用EL表达式取出保存的值。原文链接:https://blog.csdn.net/xueyijin/article/details/128365377
三.提问简单的数据结构,问工作中有没有用到数据结构,最后提问我java冒泡排序,还有递归算法
1、 数组(Arrary)
数组是一种线性结构的数据,连续的存储空间和相同的类型数据。查询速度快,但是数组的容量固定,无法扩容,只能存储同类型的数据,对于添加和删除元素比较慢
2、栈(Stark)
栈是一种先进后出的一种结构,好比水桶。例如虚拟机栈,方法栈等
3、链表(Linked List)
链表是一种线性的链式结构,链表的内存不是连续的,前一个节点存储的地址不一定就是一个元素,可能是一个引用,通过这个引用可以拿到对应的对象。链表是通过一个节点指向另一个节点的地址将元素串起来。
单向链表:最简单的链表格式。链表的最小单元为节点,每一个节点包含了数据和指向下一个节点的指针。
双向链表:两个方向的链表。链表的每个节点包含了数据以及前一个节点地址的指针和后一个节点的地址指针。这种数据结构的好处是通过当前节点可以通过时间复杂度o(1)很快定位到前置节点和后置节点,但是通过前置指针和后置指针的配置增加了内存的消耗。
循环链表:跟双向列表差不多,但是唯一的区别就是尾节点的后置指针指向头节点,头节点也有指针指向了尾节点。
3、哈希(Hash)
哈希也叫做散列。通过key-vlue的方式存储,在很大程度上提高了数据的查询,增加和删除。hash结合数组和链表的特性(数组查询快,链表增删快)。
Java最经典的HashMap的底层实现是数组+链表+红黑树
hash函数在hash表中起到至关重要作用,数据通过hash函数生成一个固定的hash值,通过hash值可以很快的定位到元素。但是hash值不是唯一的,就将hash值相同的放入链表中,如果链表的长度超过8,或者大小超过64,就将链表转化为红黑树。
4、队列(Queue)
队列是特殊的线性结构,一种先进先出的数据存储结构,数据的删除操作只能在头部操作,插入在尾部操作。
5、树(Tree)
树是一种线性结构,有节点组成的集合。
二叉树:每一个节点最多有两个子树
完全二叉树:除了最外层节点,其他的节点都达到最大的层数
满二叉树:一个树的节点要么是叶子节点,要么就是有两个节点
平衡二叉树:任何节点的子树高度差不超过1;
二叉查找树:任意节点的左子树都不能为空,并且左子树所有节点的值都小于根节点;任意节点的右子树不能为空,并且右子树所有节点的值都大于根节点;任意节点的左右子树都是一个二叉查找树。
B树:一种堆读写优化的自平衡二叉树,在数据库索引的常用索引数据的结构。
B+树:所有非叶子节点都是索引部分,节点中仅包含根节点的最大或者最小的关键字;所有叶子节点包含了所有关键字的信息以及含有这些关键字记录的指针,而且叶子节点数据根据关键节点的大小从小到大排列;m个子树的中间节点包含有m个元素,每个元素不包含数据,只包含索引。
红黑树
红黑树是一种平衡二叉树,通过颜色约束树的平衡。每一个元素要么红色,要么黑色;根节点一定是黑色;每个叶子节点都是黑色的;如果一个节点为红色,那么他的所有子节点都是黑色,因为每一条路径上都不能出现相邻两个节点是同一颜色;每一个叶子节点的所有路径存在的黑色节点都相同。
6、堆(Heap)
堆是一种特殊的树形结构,父节点的值大于等于子节点的值或者小于子节点的值。对于max heap根节点是所有节点的最大值 或者min heap根节点值是所有节点最小的值。
7、图(Graph)
一个图就是一些顶点的集合,这些顶点通过一系列边结对(连接)。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接。
节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。
原文链接:https://blog.csdn.net/m554062212/article/details/127916390
冒泡排序:
package com;
public class demo {
public static void main(String[] args) {
//冒泡排序算法
int[] numbers=new int[]{1,5,8,2,3,9,4};
//需进行length-1次冒泡
for(int i=0;i<numbers.length-1;i++)
{
for(int j=0;j<numbers.length-1-i;j++)
{
if(numbers[j]>numbers[j+1])
{
int temp=numbers[j];
numbers[j]=numbers[j+1];
numbers[j+1]=temp;
}
}
}
System.out.println("从小到大排序后的结果是:");
for(int i=0;i<numbers.length;i++)
System.out.print(numbers[i]+" ");
}
}递归算法:
import java.util.Scanner;
public class Test {
int sum = 0;
public static void main(String[] args) {
System.out.printf("输入 n 的值:");
Scanner scanner = new Scanner(System.in);
int i = scanner.nextInt();
int a;
// 注意 由于mul不是静态方法所以要先声明对象
Recusion recusion = new Recusion();
a = recusion.mul(i);
System.out.println(i+"的阶乘的结果为:"+ a);
}
public int mul(int i) {
//出口 当 i等于1和0时跳出递归
if (i == 1 || i == 0) {
return 1;
}else {
return i * mul(i - 1);
}
}
}四.多表查询去重、
用distinct用来查询不重复记录的条数,即用distinct来返回不重复字段的条数(count(distinct id)),其原因是distinct只能返回他的目标字段,而无法返回其他字段。
注意事项
distinct 【查询字段】,必须放在要查询字段的开头,即放在第一个参数;
只能在SELECT 语句中使用,不能在 INSERT, DELETE, UPDATE 中使用;
DISTINCT 表示对后面的所有参数的拼接取 不重复的记录,即查出的参数拼接每行记录都是唯一的
不能与all同时使用,默认情况下,查询时返回的就是所有的结果原文链接:https://blog.csdn.net/shenziheng1/article/details/102536146















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









