









《数据挖掘》国防科技大学
《数据挖掘》青岛大学
《数据挖掘与python实践》
python:聚类
数据挖掘之聚类

聚类概述
聚类的概念
聚类(Clustering)是把数据集按照相似性划分为多个子集的过程,每个子集是一个簇(cluster),使得簇内高相似、簇间低相似。聚类是无监督学习。
聚类的过程
数据准备→特征选择&特征提取→聚类→结果评估
聚类的质量
每个簇的质量用簇内距离刻画,聚类的总体质量用簇间距离衡量。
常用的距离函数:
- 闵可夫斯基距离 Minkowski → 曼哈顿距离 Manhattan、欧氏距离 Euclidean
- 二次型距离 Quadratic
- 余弦距离
- 二元特征样本的距离度量
簇中心:

簇的直径:簇中任意两个对象之间距离的最大者,也称为簇外径;
簇的内径:簇中任意两个对象之间距离的最小者;
簇的平均距离:簇中任意两个对象之间距离的和与簇中元素个数取2的组合数(平方数)的比值;
簇的中心距离和:簇中每个点到中心点的距离之和。
簇间距离之最小距离:

簇间距离之最大距离:

簇间距离之平均距离:

簇间距离之均值(中心)距离:

聚类的评价函数
簇内差异(Within cluster variation)和簇间差异(Between cluster variation)。在同一个簇中的对象尽可能“相似”,不同簇中的对象则尽可能“相异”。
- 簇内差异:可以用簇的中心距离和来定义
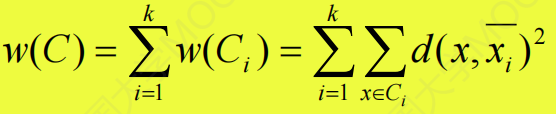
- 簇间差异:定义为聚类中心点间的距离
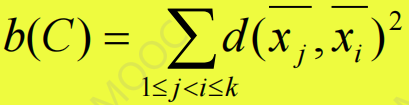
聚类C的评价函数可以利用簇内差异w©和簇间差异b©设置为以下几种形式:
(1) f©=w©;
(2) f©= 1/b©
(3) f©= w©/b©;
(4) f©= αw©+β(1/b©) 且α+β=1。
(5) F©=(w©,1/b©),F为二元目标函数,或多目标函数。
1. 划分聚类
将含有n个对象的数据集D划分成k个簇,并且k≤n;每个簇至少包含一个对象,每个对象属于且属于一个簇。
过程:
- 创建初始k划分
- 迭代计算各个簇的聚类中心并根据聚类中心调整聚类情况直至收敛。
K-means
思路
每次聚类保证局部最优,随后调整聚类,利用局部最优聚类的上限来不断逼近全局最优。
每个簇用该簇中对象的均值表示,实际是基于质心的技术。
- 评价指标:距离
- 优化目标函数:簇内差异函数w©,即所有数据对象到它的簇中心点的距离平方和
- 寻优策略:使目标函数达到最小值(簇中心不变化等价于w©达最小)。

优点:
① k-means算法简单、经典,常作为其它聚类算法的参照或被改进。
② k-means算法以k个簇的误差平方和最小为目标,当聚类的每个簇是密集的,且簇与簇之间区别明显时,其聚类效果较好。
③ k-means算法处理大数据集高效,具较好的可扩展性。
④ 聚类时间快。
缺点:
① k-means算法对初始中心点的选择比较敏感。
② k-means算法对参数k比较敏感。
③ 在连续属性的数据集上很容易实现,但在具有离散属性的数据集上却不能适用。
④ 主要发现圆形或者球形簇,对不同形状和密度的簇效果不好。
⑤ k-means算法对噪声和离群点非常敏感。
⑥ 不同的初始值,结果可能不同。
算法效率分析
该算法的计算复杂度为O(nkt)
n为数据集中对象的数目
k为期望得到的簇的数目
t为迭代的次数
改进:
① 空簇问题:需要选择一个替补的中心
- 选择一个距离当前任何质心最远的,并可消除当前对总平方误差影响最大的点
- 从具有最大w(Ci)的簇中选择一个替补质心,并对该簇进行分裂,以此降低聚类的w©。
② 离群点孤立点)问题:k-means算法使用误差平方和w©作为优化目标时,离群点可能过度影响所发现的簇质量。
- k-modes 算法:实现对离散数据的快速聚类,保留k-means算法的效率同时将k-means的应用范围扩大到离散数据。
1)度量记录之间的相似性D的计算公式:比较两记录之间所有属性,如属性值不同则给D加1,相同则不加。
2)更新簇中心:使用簇中每个属性出现频率最大的那个属性值代表簇中心的属性值 - k-prototype算法:可以对离散与数值属性两种混合的数据进行聚类。在k-prototype中定义了一个对数值与离散属性都计算的相异性度量标准。
1)混合属性的相似性D度量标准:数值属性采用K-means算法中的度量方法得到P1,离散属性采用K-modes算法中的度量方法得到P2,那么D=P1+a*P2,a是权重。如果觉得离散属性重要,则增加a,否则减少a,a=0时即只有数值属性。
2)更新簇中心的方法:结合K-means与K-modes的簇中心更新方式 - 总结:k-modes和k-prototype将只针对数值属性的k-means算法扩展到可以解决离散属性与混合属性,k-modes的算法时间复杂度比其余两者低,但还存在:K值确定、k-prototype中权重a的确定、k个初始记录的选择三个问题。
- k-中心点算法:不采用簇中的平均值作为参照点,选用簇中位置最中心的对象,即中心点作为参照点。
K-medoids (k-中心点法)
每个簇用接近簇中心的一个对象来表示,实际是基于代表对象的技术。
k-medoids(k-中心点)算法选用簇中位置最中心的对象作为代表对象,对n个对象给出k个划分。代表对象也被称为是中心点,其他对象被称为非代表对象。
PAM(Partitioning Around Medoid,围绕中心点的划分)是聚类分析中基于划分的聚类算法,是最早提出的k-中心点算法之一。
PAM 算法思想
首先为每个簇随机选择一个代表对象作中心点,其余对象(非中心点)分配给最近的代表对象所在的簇。然后反复地用非代表对象替换代表对象,使其聚类质量更高(用某种代价函数评估),直到聚类质量无法提高为止。




总代价
每当重新分配发生时,替换的总代价是数据集D中的每个对象到新中心点的距离变化的累加和。

• 如果总代价是负的,那么实际的平方-误差将会减小,Oi可以被Oh替代;
• 如果总代价是正的,则当前的中心点Oi被认为是可接受的,在本次迭代中没有变化。
代价计算的四种情况:
Oi和Om是两个原中心点,Oh将替换Oi作为新的中心点。




性能分析
(1)消除了k-平均算法对于孤立点的敏感性;
(2)不易被极端数据影响,方法更加健壮,但是执行代价高;
(3) 必须指定聚类数目k,并且k的取值对聚类质量影响很大;
(4) 对小的数据集非常有效,对大数据集效率不高。特别是n和k都很大的时候。
(5) 相对于K-means而言计算较为复杂烦琐。
2. 层次聚类
对给定的数据集进行层次的分解,直到某种条件满足为止。
- 凝聚的层次聚类:一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。代表算法是AGNES算法。
- 分裂的层次聚类:采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。代表算法是DIANA算法。
层次聚类存在的主要问题
• 合并或分裂的决定需要检查和估算大量的对象或簇
• 一个步骤一旦完成便不能被撤消
• 避免考虑选择不同的组合,减少计算代价
• 不能更正错误的决定
• 不具有很好的可扩展性
• 改进方法:将层次聚类和其他的聚类技术进行集成,形成多阶段聚类
BIRCH:使用CF-tree 对对象进行层次划分,然后采用其他的聚类算法对聚类结果进行求精
CURE:采用固定数目的代表对象来表示每个簇,然后依据一个指定的收缩因子向着聚类中心对它们进行收缩
CHAMELEON:使用动态模型进行层次聚类

AGNES
算法思想
AGNES (AGglomerative NESting)算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。聚类的合并过程反复进行直到所有的对象最终满足簇数目。

性能分析
• AGNES算法思想比较简单,但经常会遇到合并点难以选择的困难
• AGNES算法的时间复杂性为O(n2)
• 这种聚类方法不具有很好的可伸缩性
• 该算法仅可用于规模相对较小的数据集。
DIANA
算法思想
DIANA(Divisive ANAlysis)算法采用自顶向下的策略。首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到每个对象自成一簇,或者达到了某个终结条件。
与AGNES算法类似,用户可以在DIANA聚类算法中指定簇的数目k作为算法的一个结束条件。同时算法要使用簇的直径和平均相异度两种测度方法。
在DIANA算法的处理过程中,刚开始将所有的对象放在一个簇中,然后根据一定的评价函数将其分裂为两个子簇,其中一个叫原始(original)簇,简记Co,另一个叫分裂(split或divisive)的子簇,记作Cs。


性能分析
• DIANA算法与AGNES算法一样,其时间复杂性为O(n2)
• 这种聚类方法同样不具有很好的可伸缩性
• 该算法在n很大的情况就不适用。
BIRCH
• BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)全称是:利用层次方法的平衡迭代规约和聚类。这个算法利用了一个树型结构来帮助我们快速的聚类,这个树结构类似于平衡B+树。特点是能利用有限的内存资源完成对大数据集的高质量的聚类,同时通过单遍扫描数据集能最小化I/O代价。
- 聚类特征(Clustering Feature,简称CF) :
• CF是一个三元组,代表了簇的所有信息。
• 给定N个d维的数据点{x1,x2,…,xn},CF定义如下:CF=(N,LS,SS) N是簇中包含的样本数量,LS是N个样本点的向量和,SS是N个样本点各个特征的平方和。
• CF有个特性,即可以求和:如果CF1=(n1,LS1,SS1),CF2=(n2,LS2,SS2),则CF1+CF2=(n1+n2, LS1+LS2, SS1+SS2)。

- 聚类特征树(Clustering Feature Tree,简称CF Tree)。
聚类特征CF是BIRCH增量聚类算法的核心,CF树中的节点都是由CF组成。
3. 密度聚类
根据密度条件对邻近对象分组形成簇,簇的增长或者根据邻域密度,或者根据特定的密度函数(只要临近区域的密度超过某个阈值,就继续聚类)
主要特点:
发现任意形状的聚类
处理噪音
一遍扫描
需要密度参数作为终止条件
概念
ε-邻域:给定对象半径𝜀内的邻域称为该对象的𝜀-邻域
核心对象:如果对象的𝜀-邻域至少包含最小数目MinPts个对象,则称该对象为核心对象
直接密度可达:给定对象集合D,如果p是在q 的𝜀-邻域内,而q是核心对象, 则称对象p是从对象q关于𝜀和MinPts直接密度可达的
密度可达:如果存在一个对象链p1, …, pn,p1= q, pn= p,使得pi+1是从pi直接密度可达的,则称对象p是从对象q关于𝜀 和MinPts(间接)密度可达的

密度相连的:如果存在对象o使得p和q都是从o关于𝜀和MinPts密度可达的,则称对象p与q关于𝜀和MinPts是密度相连的

基于密度的簇是基于密度可达性的最大的密度相连对象的集合,即簇C 满足
连通性:对于C 中任意的p 和q,p 与q 是关于𝜀和MinPts密度相连的
极大性:对于任意的p 和q,如果p 属于C 簇,并且q 是从p 出发关于𝜀和MinPts密度可达的,则q 也属于C 簇
边界点( Border point )的Eps 邻域有少于MinPts 个对象, 但它的邻域中有核心对象
噪声点( Noise point )是除核心对象和边界点之外的点
DBSCAN
算法思想

优点
抗噪声
能处理各种形状和大小集群
缺点
对用户定义的参数是敏感的,参数难以确定(特别是对于高维数据),设置的细微不同可能导致差别很大的聚类。全局密度参数不能刻画内在的聚类结构。















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









