







Swift ——String 与 Array
1. String
1.1 String 在内存中的存储
先创建一个空的字符串,运行后打印地址,看到只有一个有效消息0xe000000000000000。
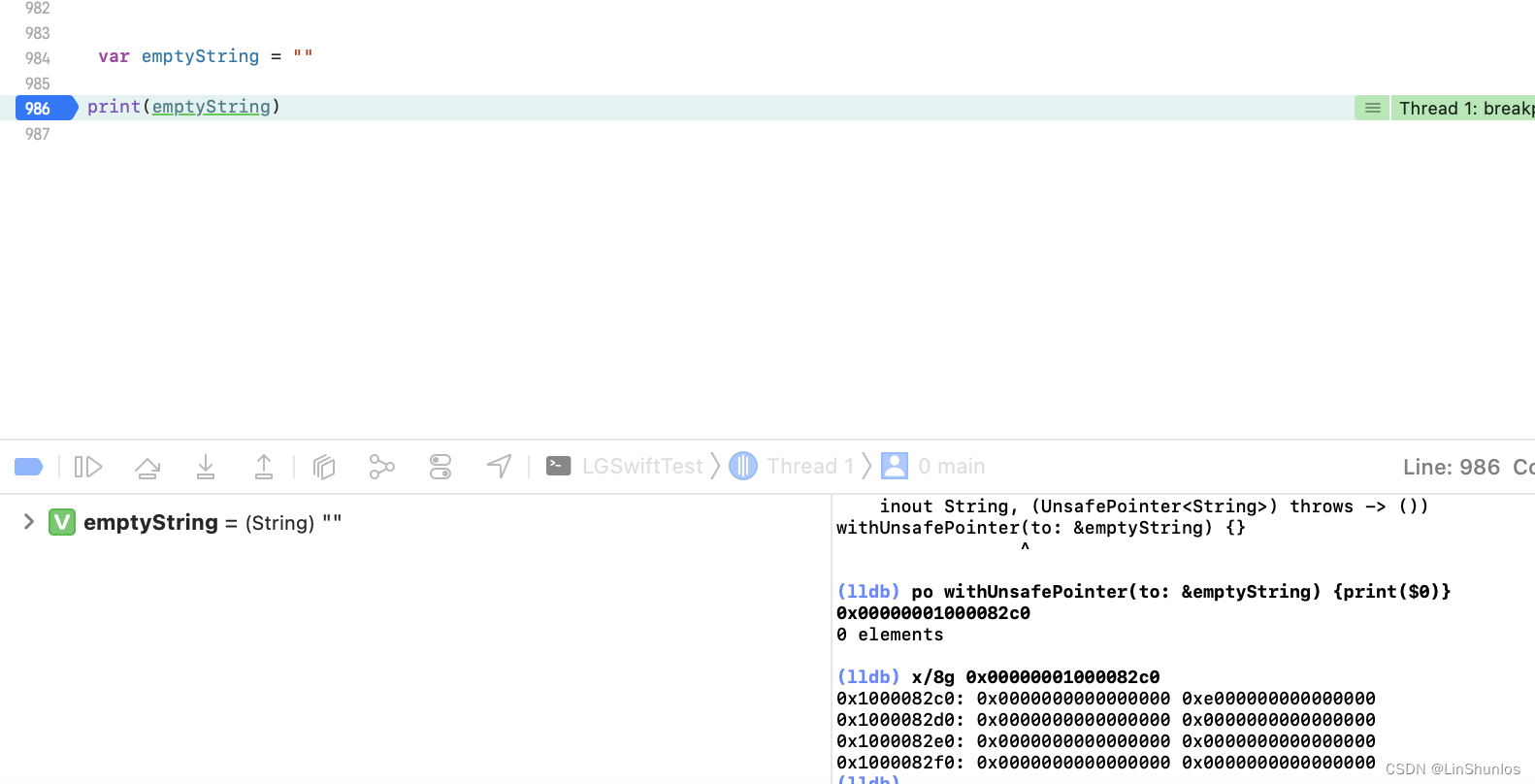
打开源码查看,看到在String.swift里面有一个初始化空字符串的方法。
public init() { self.init(_StringGuts()) }

那么看到StringGuts.swift方法里面,看到初始化空字符串的方法。

在看到StringObject.swift里面的empty方法。看到这里根据架构不同调用不同的初始化方法。
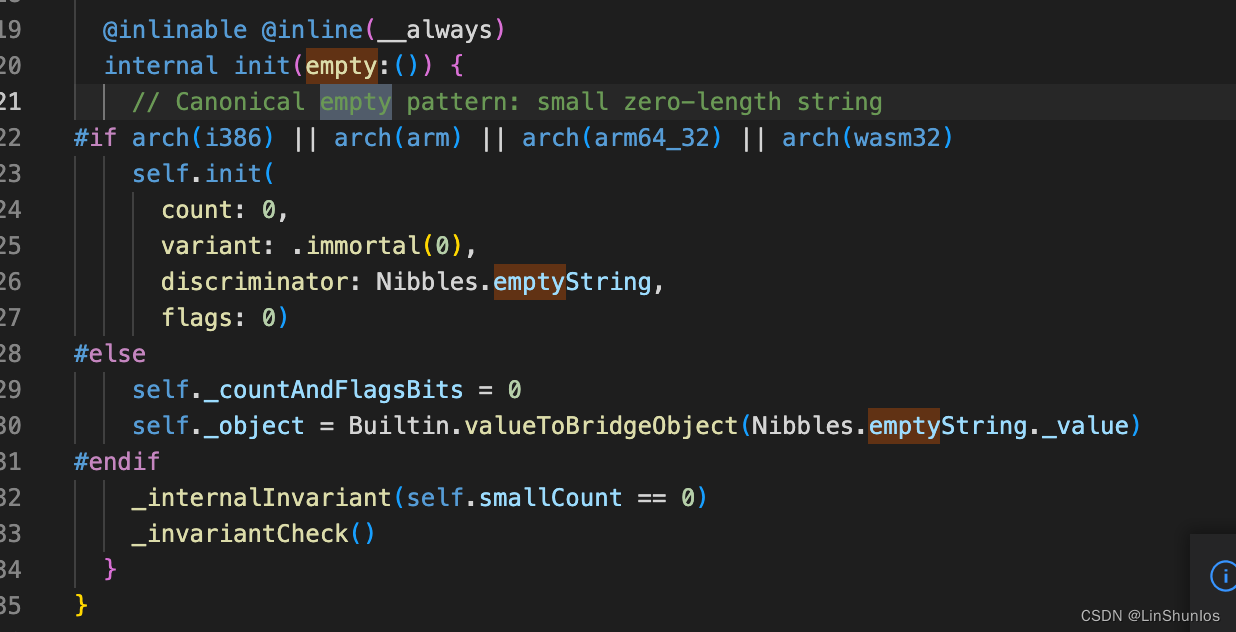
这里看到arm的结构调用的方法,这里对属性进行赋值。StringObject是一个结构体,这些属性是StringObject的成员变量,那么当对当前String字符串存储的就是这些成员变量。那么这些属性分别代表什么呢?
首先 _count 应该是代表当前字符串的大小。_variant在源码中寻找,看到其是一个枚举类型。而在之前的空字符串初始化方法中看到其传的是.immortal(0),其实际上代表的是原生的字符串。

接下来是_discriminator,之前初始化方法传入的是枚举变量的枚举值Nibbles.emptyString.找到其是空的。

在往下找看到其有拓展,并且传入是否为isASCII码。
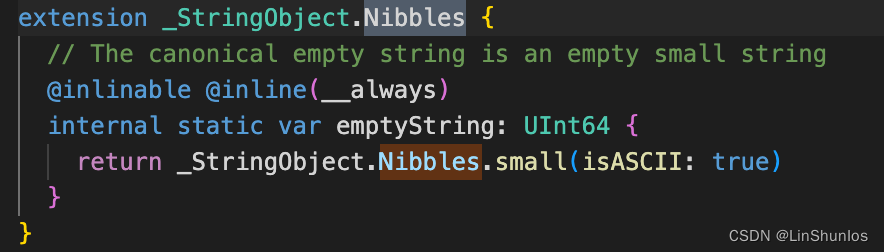
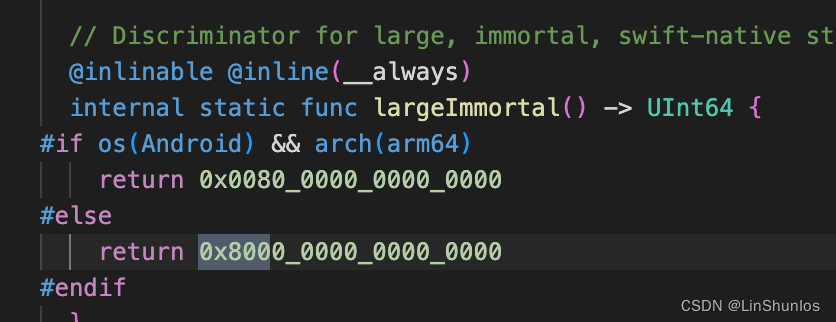
看到small函数根据传进来的isASCII返回0xE000_0000_0000_0000或者是0xA000_0000_0000_0000。这个就是我们之前返回的0xe000000000000000,代表时ASCII码。
改变字符串,发现确实成了0xa.
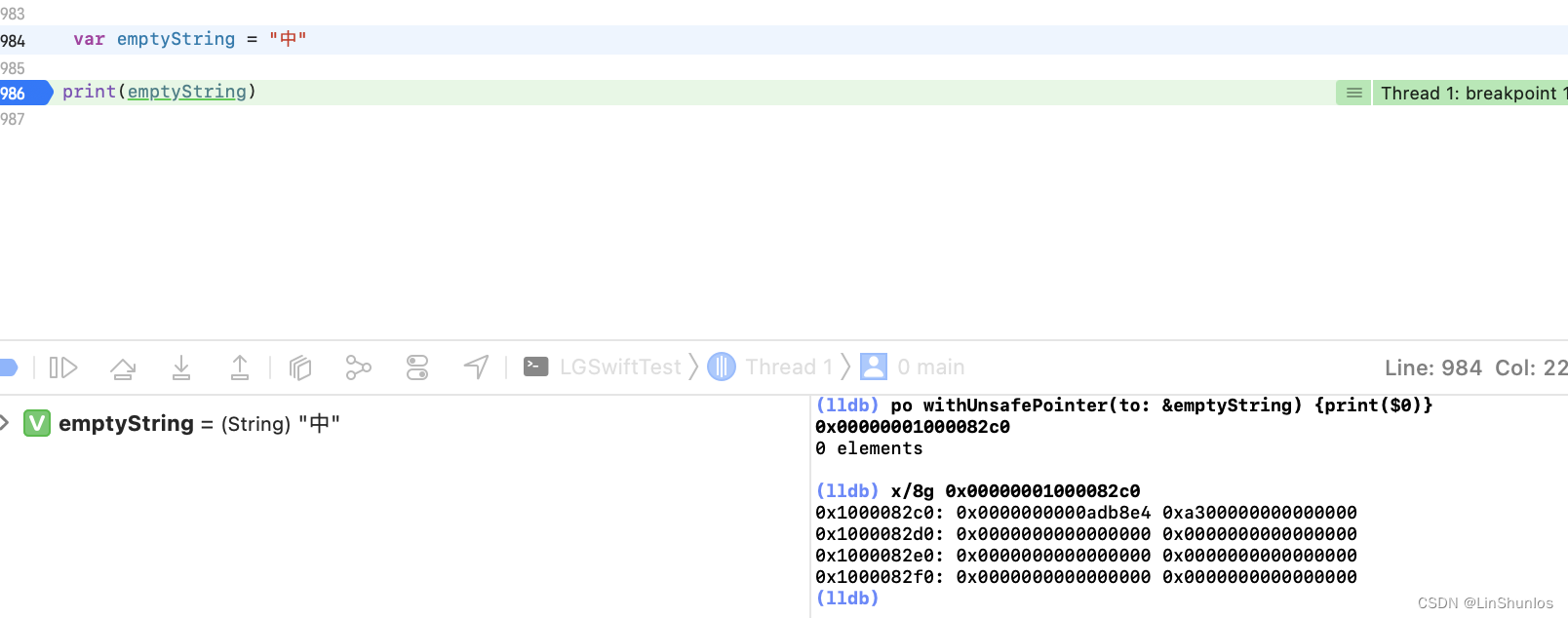
如果字符串改为ab,这里看到变成了0xe200000000000000,那么就是代表着0xe后面放的是字符串的count。
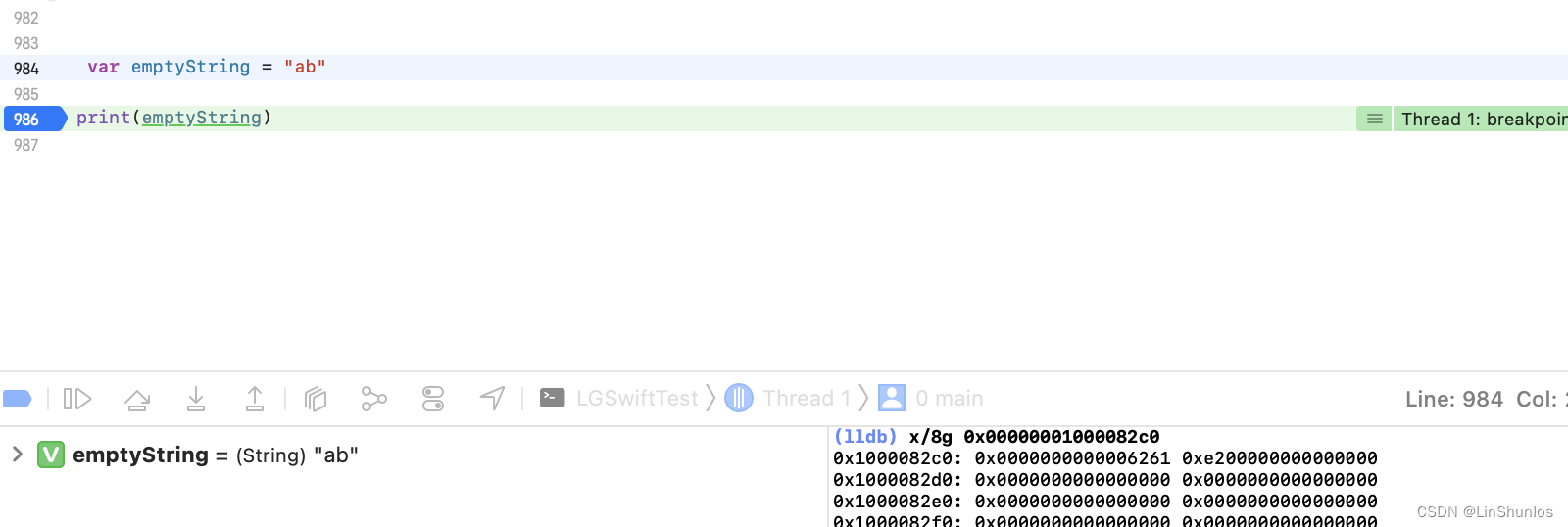
如果字符串改为abcd,这里看到变成了0xe400000000000000,那么再次证明0xe后面放的是字符串的count,而前面的0x0000000064636261代表着字符串的ASCII码。
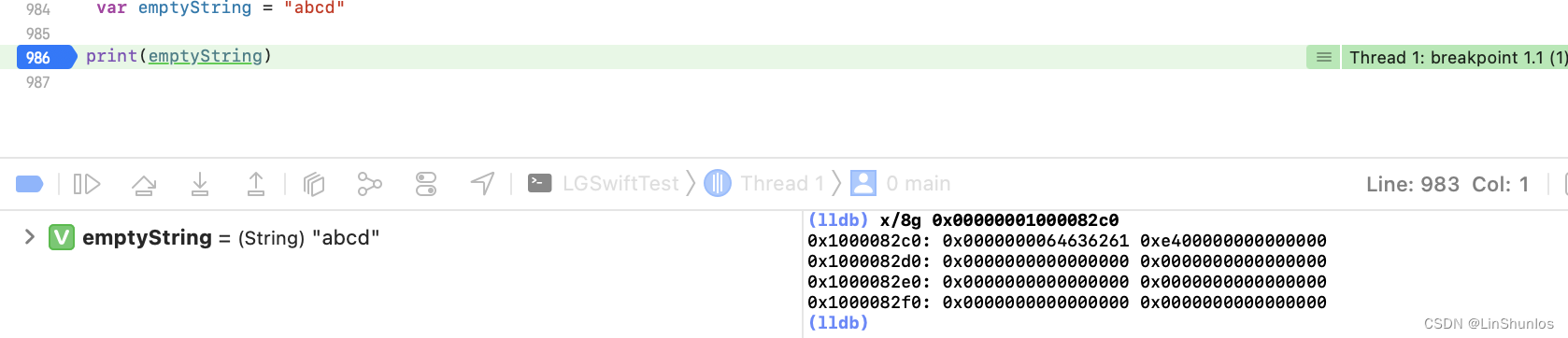
当超过了八个字符之后,看到字符存放到了第二个8字节的地址上。
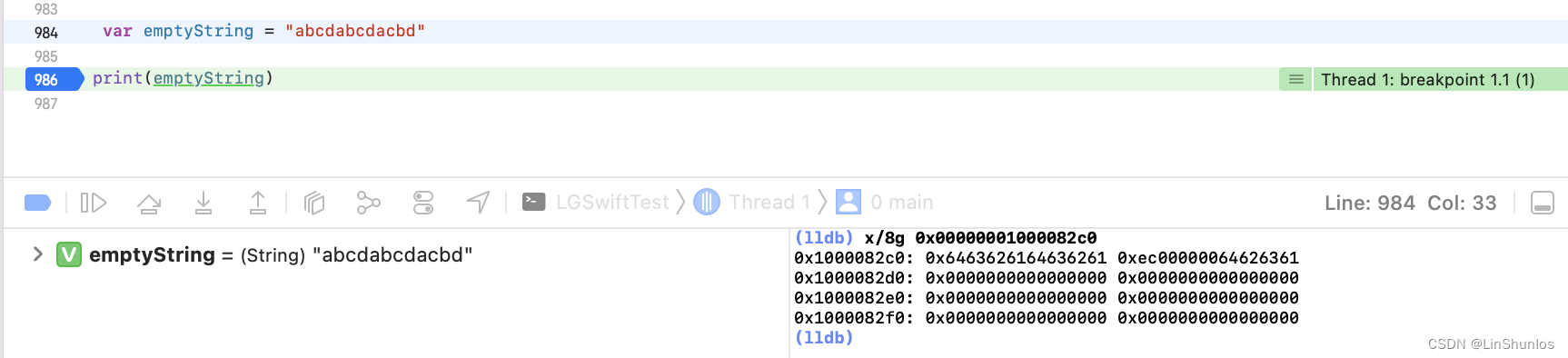
而在添加之后,看到其内存结构变了。那么也就是说,小字符串最多存放15个字母,并且对于小字符串来说,优先直接存放进内存当中。

那么大的字符串要怎么储存呢?看到源码。大字符串分native,shared和foreign三种。而对于原生(native)大字符串来说,这里采用尾递归分配的方式存储。

往下看到其内存结构,其63到60位存放的是discriminator,而60位到0位存放的是objectAddr,这个字符串的地址不是一个绝对地址,而是一个相对地址,其是从存储对象地址的“nativeBias”偏移量开始的。
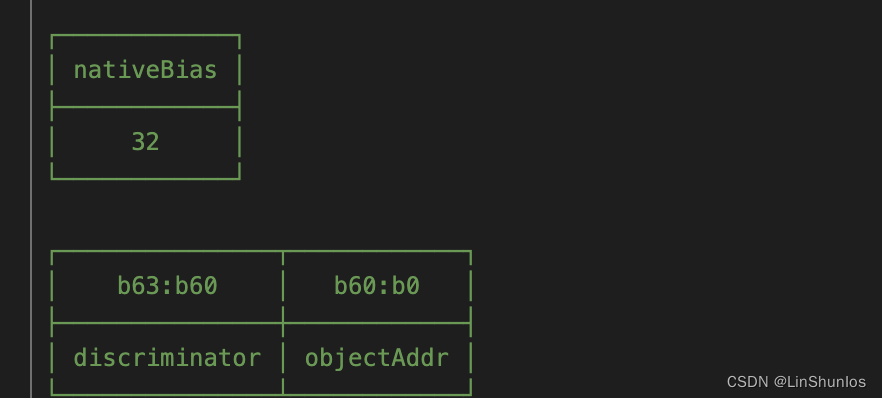
看到这里的大字符串,
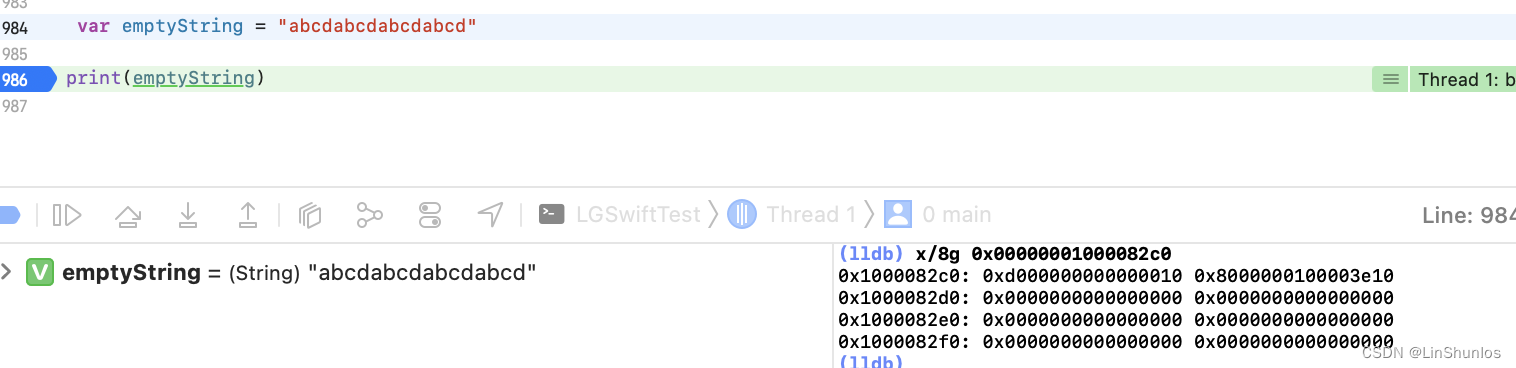
其中0x800代表着是个原生大字符串。
而后面的100003e10则是字符串的偏移地址,将其偏移32位后打印,得到字符串的信息。而10则依然是长度信息。

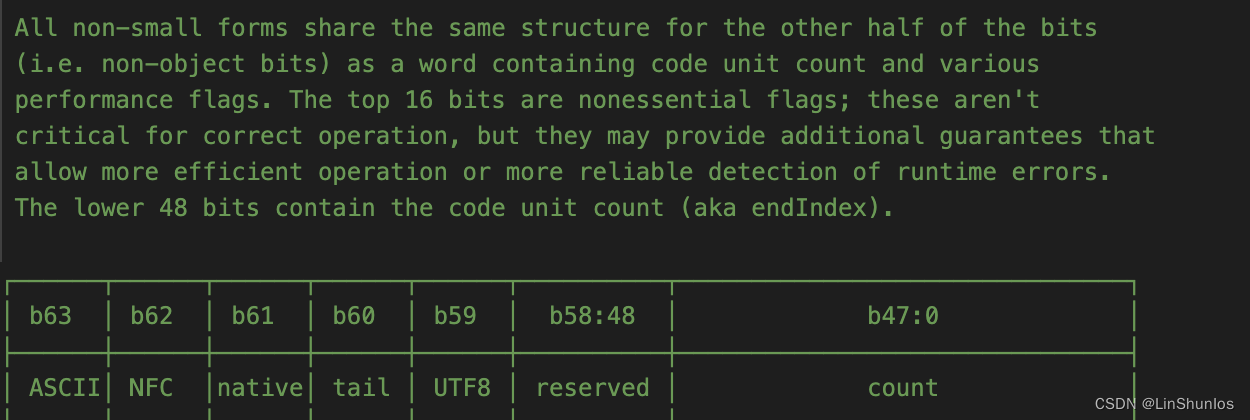
在源码中找到这样一个结构,看到这里说明所有的非小字符串都是用的这样的一个结构。而前八个字节的存储结构如下:
- isASCII:用来判断当前字符串是否是 ASCII,在高 63 位。
- isNFC:是否为C交互的字符串,这个默认为 1,在高 62 位。
- isNativelyStored:是否是原生存储,在 高 61 位。
- isTailAllocated:是否是尾部分配的,在 高 60 位。
- TBD:留作将来使用,在高 59 位到高 48 位。
- count:当前字符串的大小,在高 47位到低 0 位。
1.2 String.index
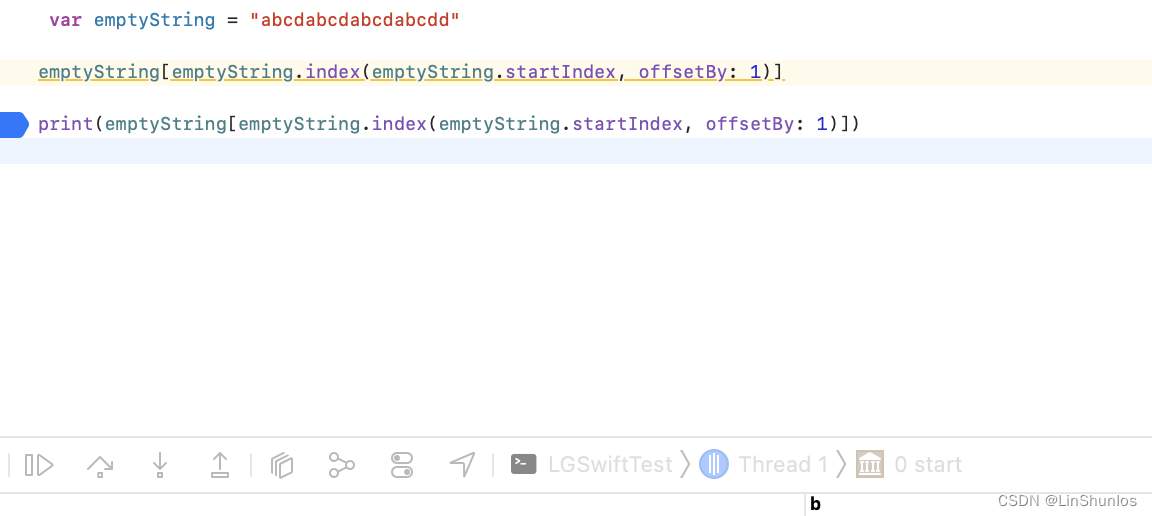
在swift中,我们无法通过[int]来获取string中对应index的值。我们需要使用emptyString.index(emptyString.startIndex, offsetBy: 1)来获取String.index,然后才可以获取对应的字符串。也就是说,在swift 中,[]中需要传入String.index类型的值。
为什么访问字符串需要这么繁琐呢?
我们先来回答第一个问题,聊到这个问题我们就必须要明白 Swift String 代表的是什么? swift中String是由一系列的 characters (字符)组成,字符的表示方式有很多种,比如我们最熟悉的 ASCII码,ASCII 码一共规定了128个字符的编码,对于英文字符来说 128 个字符已经够用了,但是相 对于其他语言来说,这是远远不够用的。
这也就意味着不同国家不同语言都需要有自己的编码格式,这个时候同一个二进制文件就有可能 被翻译成不同的字符,有没有一种编码能够把所有的符号都纳入其中—这就是我们熟悉的Unicode ,但是 Unicode 只是规定了符号对应的二进制代码,并没有详细明确这个二进制代 码应该如何存储。
这里我们举一个列子:假设我们有一个字符串"我是Kody",其中对应的 Unicode 分 别是
我 6212
是 662F
K 004B
O:006F
D: 0064
y: 0079
可以看到,上述的文字每一个对应一个十六进制的数,对于计算机来说能够识别的是二进制,所以这个时候如果存储就会出现下面的情况,对于纯英文字母来说,会有一定的浪费。
我 0110 0010 0001 0010
是 0110 0110 0010 1111
K 0000 0000 0100 1011
O 0000 0000 0110 1111
D 0000 0000 0110 0100
y 0000 0000 0111 1001
为了解决这个问题,swift使用了UTF-8。UTF-8 最大的一个特点,就是它是一种变⻓的编码方式。它可以使用1~4个字节表示一个符 号,根据不同的符号而变化字节⻓度。这里我们简单说一下 UTF-8 的规则:
- 单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码 完全相同;
- n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为 10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
对于 Swift 来说, String 是一系列字符的集合,也就意味着 String 中的每一个元素是不等 ⻓的。那也就意味着我们在进行内存移动的时候步⻓是不一样的,什么意思?比如我们有一个Array 的数组(Int 类型),当我们遍历数组中的元素的时候,因为每个元素的内存大小是一致 的,所以每次的偏移量就是 8 个字节。但是对于字符串来说不一样,比如我要方位 str[1] 那么我是不是要把 我 这个字段遍历完 成之后才能够确定 是 的偏移量?依次内推每一次都要重新遍历计算偏移量,这个时候无疑增 加了很多的内存消耗。这就是为什么我们不能通过 Int 作为下标来去访问 String。
对于String.index来说,其定义如下:
- position aka encodedOffset:一个 48 bit 值,用来记录码位偏移量。
- transcoded offset:一个 2 bit 的值,用来记录字符使用的码位数量。
- grapheme cache:一个 6 bit 的值,用来记录下一个字符的边界。
- reserved:7 bit 的预留字段 scalar aligned: 一个 1 bit 的值,用来记录标量是否已经对齐过。

所以对于 String 的 Index 的本质是 是一个 64 位的位域信息,其中存储最重要的就是 encodedOffset 和 transcoded offset。当我们构建 String 的 Index 的时候,其实是把 encodedOffset 和 transcoded offset 计算出来存放到 Index 的内存信息里面。
2. Array
2.1 Array 的内存结构
创建一个数组。

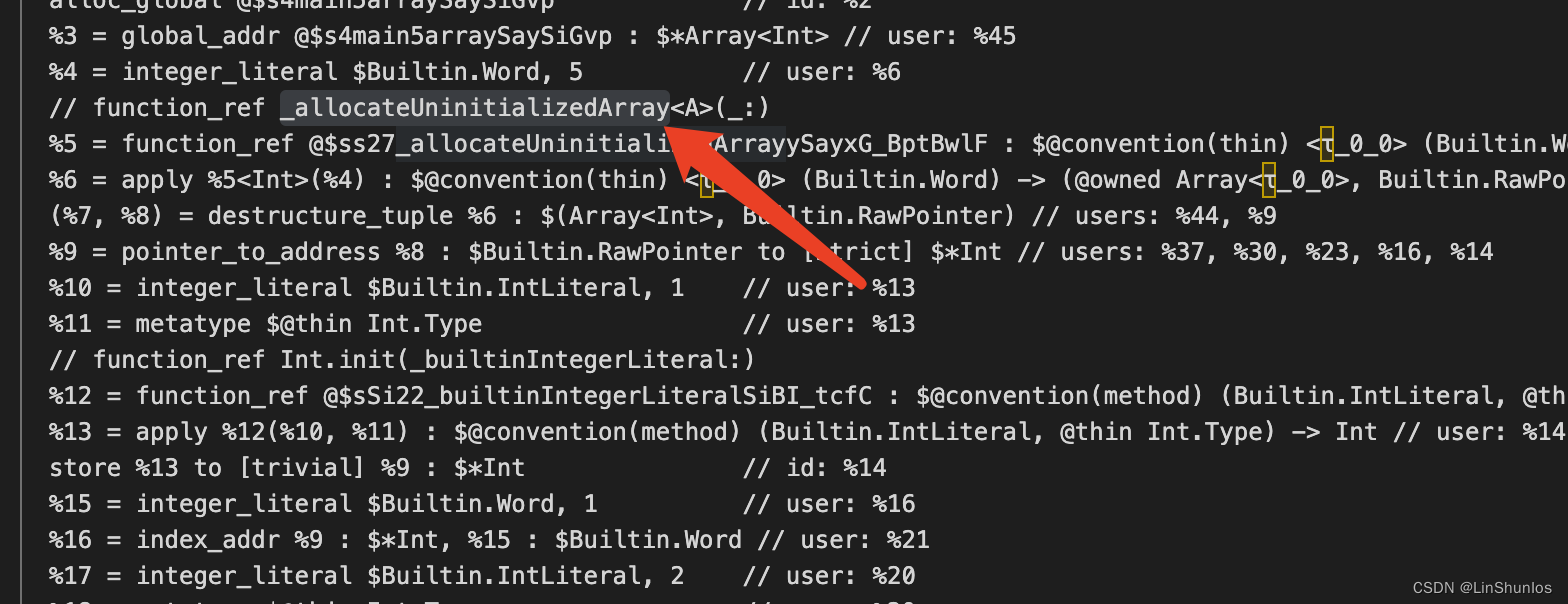
将其编译成sil文件,看到这里调用了_allocateUninitializedArray。这里传入 一个参数%4,也就是数组的大小。%6的返回值则是一个元组。%9获取的是%8的地址,然后%10和%11则是构建Int,然后将其存到%9,那么%8大概就是代表array元素开始的首地址。
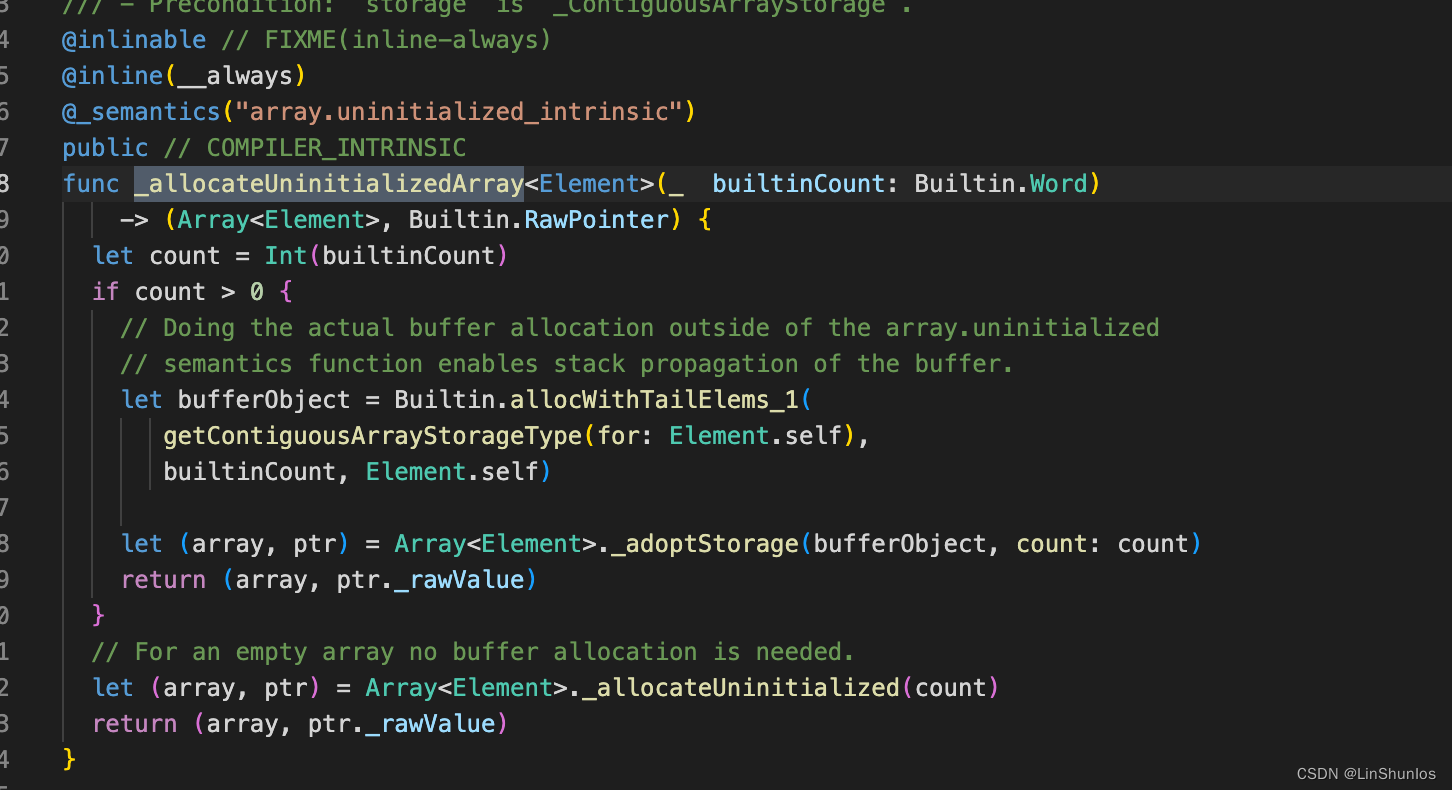
在源码中找到_allocateUninitializedArray,这里有一个参数count,这里会判断count是否大于0,如果大于0就创建内存空间,否则就是空类型的数组, 就会调用_allocateUninitialized。
看到_adoptStorage函数,这里调用了_ContiguousArrayBuffer,然后返回buffer和buffer第一个元素的首地址。
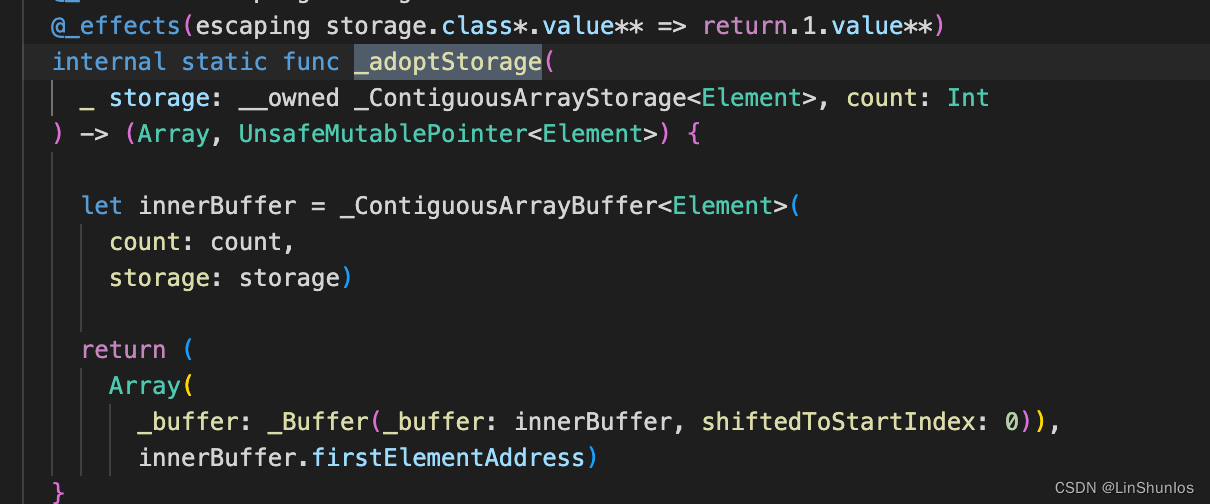
这里 Array是Struct,其里面存放着_ContiguousArrayStorage,也就是值类型里面包含着引用类型,而对于引用类型来说最重要的就是他的内存布局
- metadata
- 引用计数
- 元素的个数
- 容量的大小
- 标志位
- 元素的内存地址。
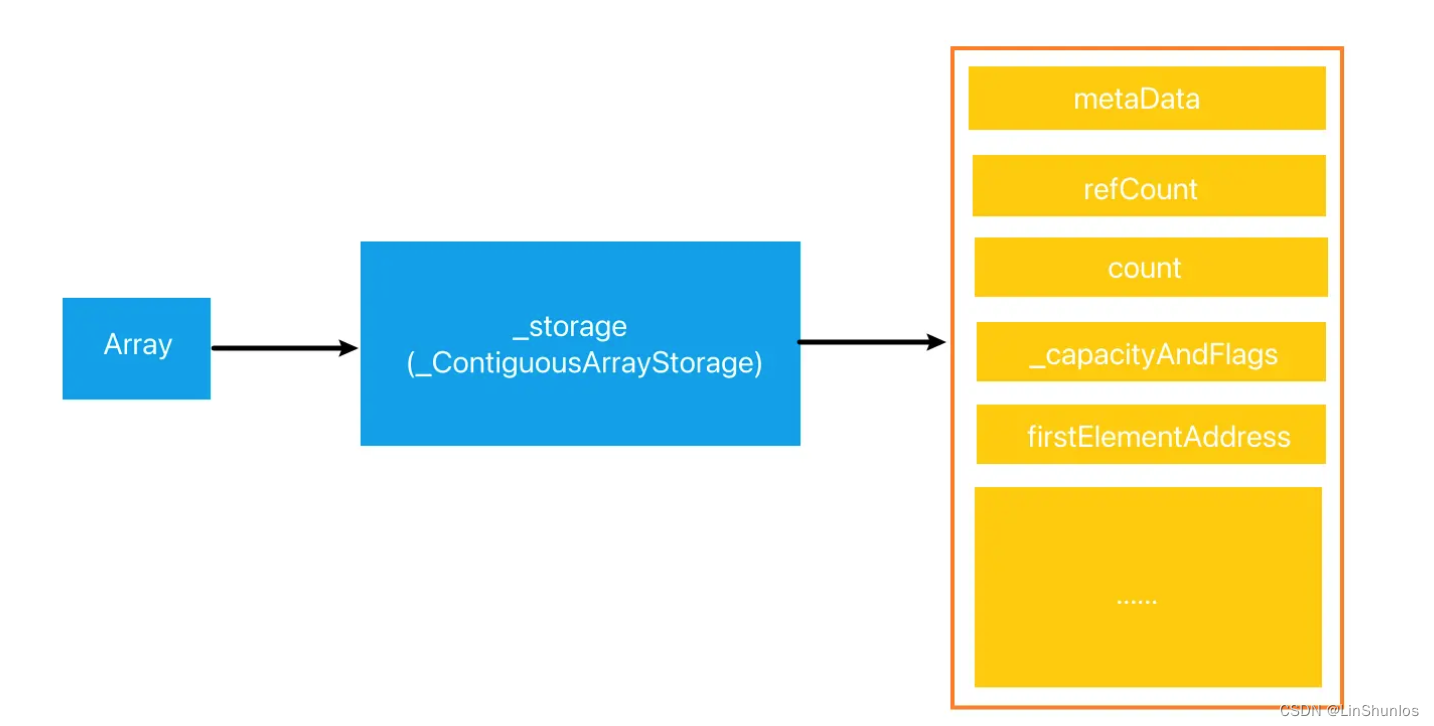
直接po可以看到array的值, 其表现像个值类型,但本质上存储的时候还是一个引用类型。
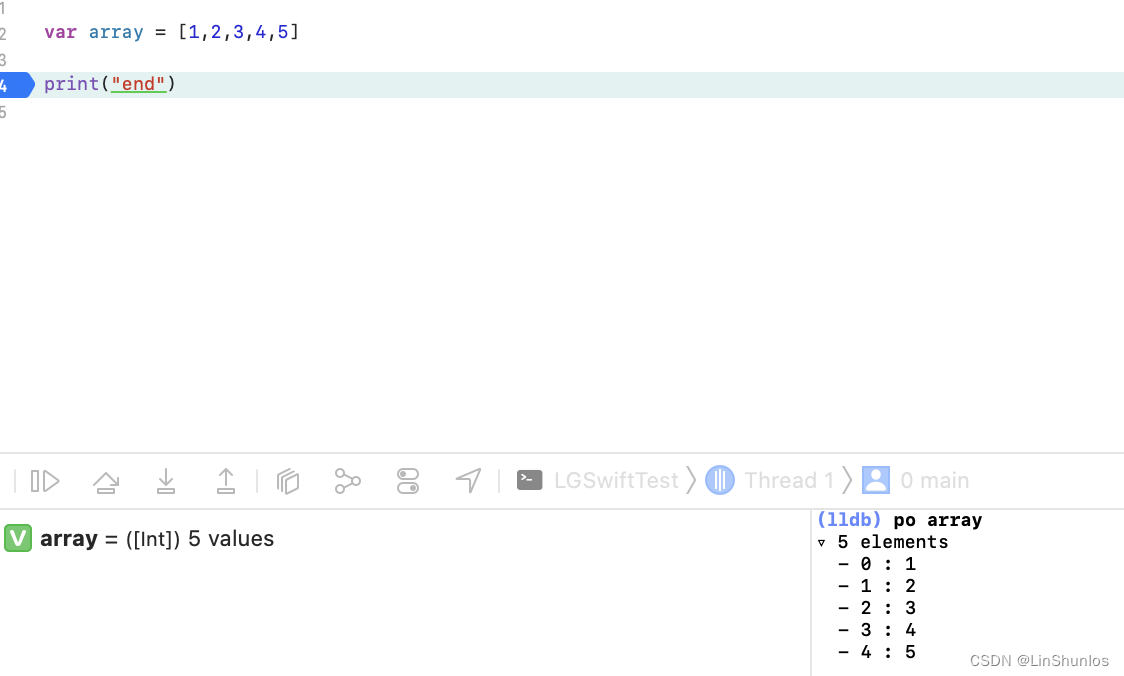
这里0x000000010120b960是_ContiguousArrayStorage的地址。而0x000000010120b960就是后面信息的地址。0x0000000200000003是refcount,0x0000000000000005是数组的长度,0x000000000000000a是
容量的大小和标志位,后面就是数组内容。
2.2 array数组的拼接
当调用append的时候,数组就应该扩容了。

看到源码,这里调用了_makeUniqueAndReserveCapacityIfNotUnique,
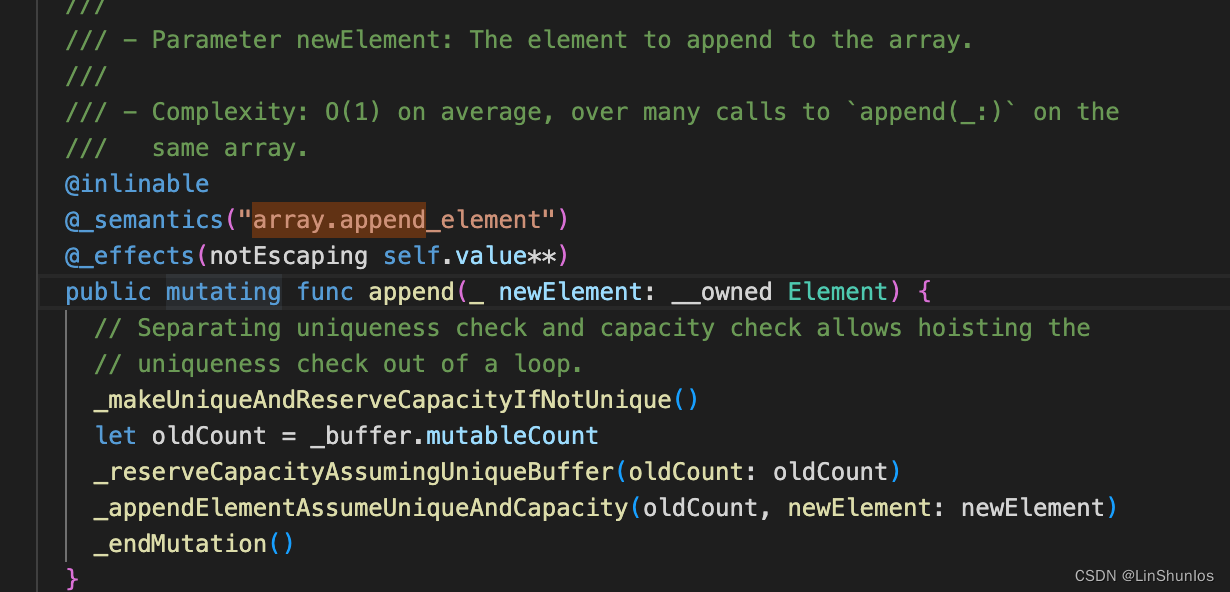
这里判断如果!_buffer.beginCOWMutation(),也就是不为写时复制,那么就调用_createNewBuffer,其容量为之前的count + 1.

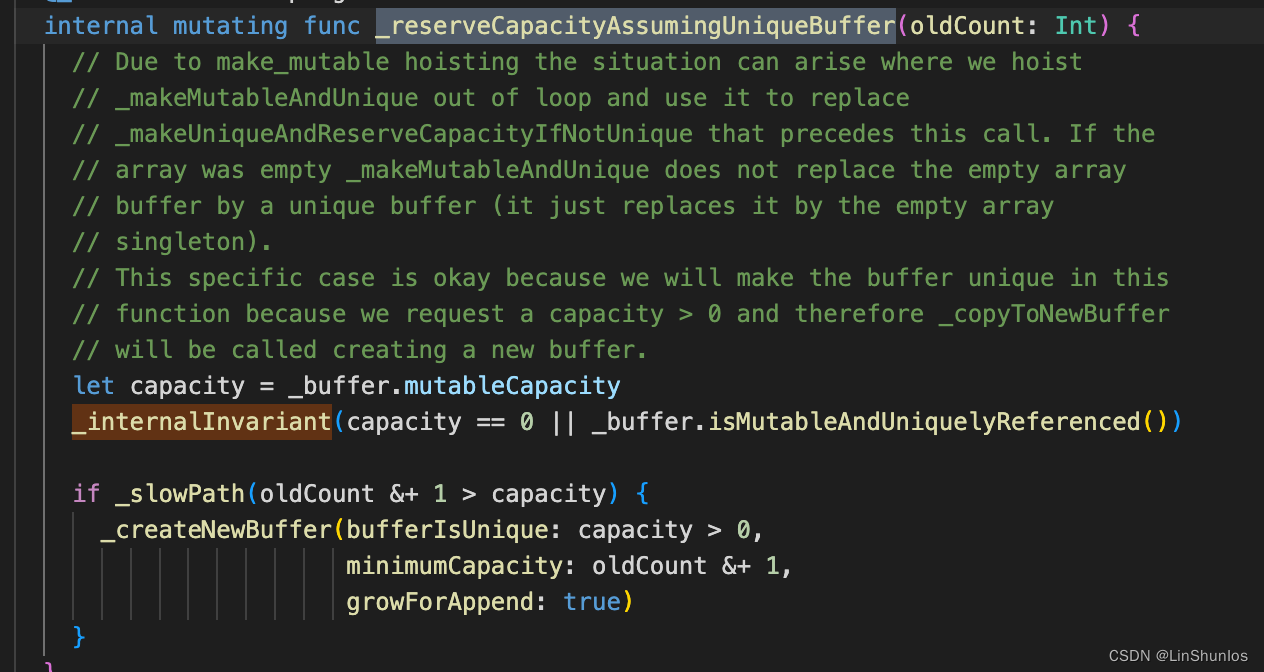
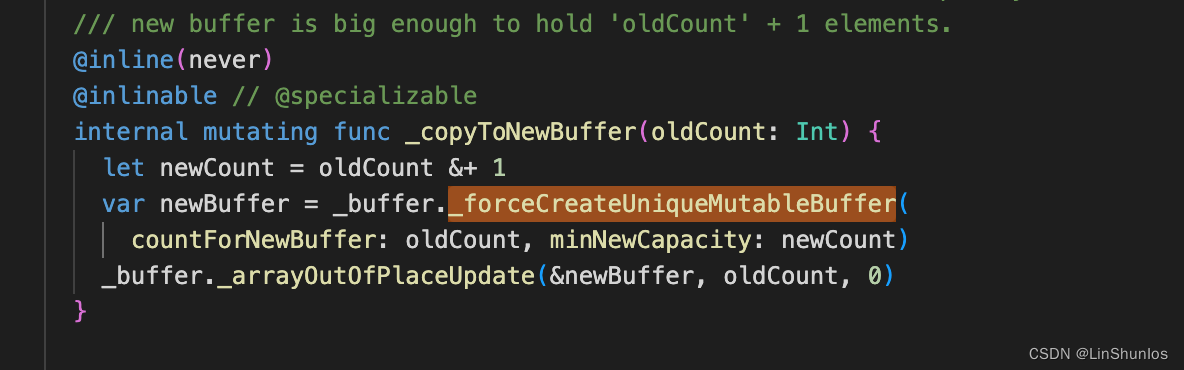
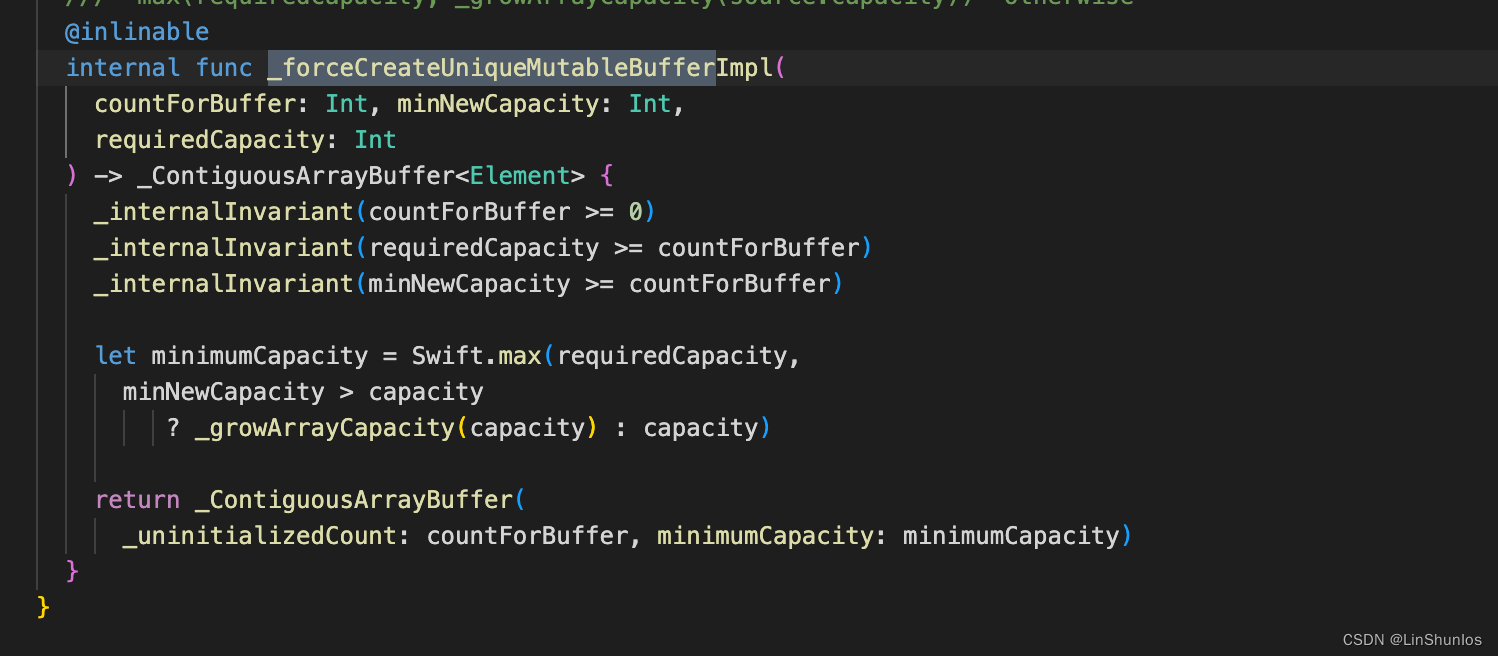
然后还会调用_reserveCapacityAssumingUniqueBuffer。这里判断oldCount &+ 1 > capacity,如果大于就会调用_createNewBuffer,并且这里是以2倍的方式扩容的。















 1579
1579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









