







mysql数据库
一、入门介绍
1.1 SQL通用语法
- SQL 语句可以单行或多行书写,以分号结尾
- 可使用空格和缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写,关键字建议大写。
- 除了数字类型,其他类型需要使用单引号,mysql可以双引号。但是建议使用单引号
- 三种注释
- 多行注释:
/*注释内容*/ - 单行注释:
--注释内容#注释内容(mysql特有)
- 多行注释:
1.2 SQL分类
-
DDL(Data Definition Language)数据定义语言:用来定义数据库、表、列
关键字:create,drop,alter
-
DML(Data Manipulation Language)数据操作语言:用来查询数据库中表的数据进行增删改
关键字:insert,delete,update等
-
DQL(Data Query Language)数据查询语言:用来查询数据库中表的记录(数据)
关键字:select,where等
-
DCL(Data Control Language)数据控制语言(了解):用来定义数据库的访问权限和安全级别,及创建用户
关键字:GRANT,REVOKE等
1.3 登入、退出、备份
登入mysql
mysql -uroot -p密码mysql -hip(ip地址)-uroot -p连接目标的密码mysql - -hosp=ip -user=root - -password=连接目标密码
退出mysql
-
exit -
quit
数据备份
mysqldump -u用户名 -p密码 数据库名称>保存的路径:数据备份source 文件路径:数据还原(登入数据库-创建数据库-使用数据库-执行文件)
二、表的设计
2.1 数据库设计的范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式 (4NF)和第五范式(5NF,又称完美范式)
- 第一范式(1NF):每一张表都应该有主键,每一列都是不可分割的原子数据项
- 第二范式(2NF):在1NF的基础上,非码属性必须完全依赖于码,不能产生部分依赖(不能有复合主键)
- 第三范式(3NF):在2NF基础上,所有非主键字段直接依赖主键,不能产生传递依赖
2.1 多表之间的关系
-
一对一
- 理解:一个人只有一个身份证,一个身份证只能对应一个人
- 实现方式:
- 外键唯一:在任意一方添加唯一外键(此外键必须添加唯一约束)指向另一方的主键
- 主键共享:在任意一方的主键上添加外键指向另一方的主键
-
一对多/多对一
- 理解:一个部门有多个员工,一个员工只能对应一个部门
- 实现方式:两张表,在多的一方建立外键,指向一的一方的主键
-
多对多
- 理解:一个学生可以选择很多门课程,一个课程也可以被多名学生选择
- 实现方式:多对多关系实现需要借助第三张关系表。关系表至少包含两个字段,这两个字段作为第三张表的外键,分别指向两张表的主键
三、 DDL
3.1 操作数据库:CRUD
3.1.1 C(Create)创建
create database 数据库名称;:创建数据库create database if not exists 数据库名称;:创建数据库,判断不存在,再创建create database 数据库名称 character set 字符集名;:创建数据库,并指定字符集- **
create database if not exists 数据库名称 character set gbk;**创建db4数据库,判断是否存在,并指定字符集为gbk
3.1.1 R(Retrieve):查询
show databases;:查询所有数据的名库show create database 数据库名称;:查询某个数据库的字符集,查询某个数据库的创建语句
4.1.3 U(Update):修改
alter database 数据库名称 character set 字符集名称;:修改数据库的字符集
4.1.4 D(Delete):删除
drop database 数据库名称;:删除数据库drop database if exists 数据库名称;:判断数据库是否存在并且删除
4.1.5 数据库其他指令
select database();:查询当前正在使用的数据库名称;use 数据库名称;:使用数据库
4.2 操作表:CRUD
数据库数据类型
varchar:(最长255)可变长度的字符串,会根据实际的数据长度动态分配空间。
char:(最长255)定长字符串,不管实际的数据长度是多少,分配固定长度的空间去存储数据。使用不恰当的时候,可能会导致空间的浪费。
int:(最长11)数字中的整数型。等同于java的int。
bigint:数字中的长整型。等同于java中的long
float:单精度浮点型数据
double:双精度浮点型数据
date:短日期类型,只包含年月日
datetime:长日期类型,包含年月日时分秒
clob:字符大对象,最多可以存储4G的字符串。存储一篇文章,存储一个说明。超过255个字符的都要采用CLOB字符大对象来存储。
blob:二进制大对象,专门用来存储图片、声音、视频等流媒体数据。,往BLOB类型的字段上插入数据的时候,例如插入一个图片、视频等,需要使用IO流才行
4.2.1 C(Create)创建
创建表的规范!
- 必须指定自增主键,不要uuid。并且主键建立后最好不要再有数据修改的需求。
- 占用的数据量更小
- 数据顺序递增,不会导致索引节点的频繁分裂
- 数字类型比字符类型效率更高
- 创建表选择字段的时候,在符合业务需求的情况下尽量小,数据类型尽量简单
- 显式申明存储引擎
- 显式申明字符集
- 对经常要查询的列添加索引或者组合索引
- 对字段和表添加COMMENT
- 字段尽量不要为NULL
- NULL需要占用额外的空间存储
- 进行比较的时候会更复杂,还会导致你select (column)的时候不准确
- 含有NULL值的列,会对SQL优化产生影响,尤其是组合索引中
CREATE DATABASE IF NOT EXISTS `dev_ops_db`;
CREATE TABLE IF NOT EXISTS `dev_ops_db`.`monitor_table_holiday` (
`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`holiday_date` date NOT NULL default '1999-01-01' COMMENT '节假日日期',
`holiday_name` varchar(36) NOT NULL default '' COMMENT '节假日名称',
PRIMARY KEY (`id`),
KEY `holiday_date` (`holiday_date`) #注意:最后一列,不需要加逗号!
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='节假日数据表';
4.2.2 R(Retrieve):查询
-
show tables;:查询某个数据库中所有的表名称 -
desc 表名;:查询表结构
4.2.3 U(Update):修改
alter table 表名 rename to 新的表名;:修改表名alter table 表名 character set 字符集名称;:修改表的字符集alter table 表名 add 列名 数据类型;:添加一列alter table 表名 change 列名 新列名 新数据类型;:修改列名称 类型alter table 表名 modify 列名 新数据类型:修改列名称 类型alter table 表名 drop 列名;:删除列
4.2.4 D(Delete):删除
drop table if exists 表名;:删除表
四 DML:增删改表中的数据
4.1 添加数据
-
insert into 表名(列名1,列名2,.....列名n) values(值1,值2,…..值n);:列名和值要一一对应 -
insert into 表名([列名1,]列名2,.....列名n) values([值1,]值2,…..值n);:如果列名是自增可以忽略不写 -
insert into 表名 values(值1,值2,….值n);:如果表名后不定义列名,则默认给所有列添加值 -
insert into 表名 valuse ([列值],[列值]),([列值],[列值]),([列值],[列值]);:批量插入 -
insert into 表名 select语句:将查询结果插入到表中
有字段没有插入数据,默认值是NULL!
4.2 删除数据
-
delete from 表名 where 条件;:注意!!不加条件的话,则删除表中所有记录 -
delete from 表名;:不推荐使用(有多少条记录就会执行多少次删除操作效率低下) -
truncate table 表名;: 推荐使用(效率更高,先删除表,然后再创建一张一样的表)
5.3 修改数据
update 表名 set 列名1=值1,列名2=值2…..where 条件;:如果不加任何条件,则会将表中所有记录全部修改。
注意:数据库不允许边查询边删除或修改!因为某一些情况,要删除/更新的字段业务比较复杂,也就是说where条件后面会跟上子查询
排错思路:
- 把子查询的结果创建临时表存储
- 把这个临时表作为原表删除的条件
五、DQL:单表查询
5.1 语法执行顺序
-
FROM和JOIN -
WHERE -
GROUP BY -
HAVING -
SELECT -
DISTINCT -
ORDER BY:此时可以用as别名了 -
LIMIT/OFFSET
5.2 基础查询
-
select 字段名1,字段名2…from 表名;:多个字段的查询格式: -
select * from 表名;:所有字段的查询格式 -
select distinct 字段名... from 表名;:去除重复,distinct关键字一定要所有字段的最前面,如果有多个字段那么会先将多个字段联合,再去重
select查询出的字段可以进行数学运算
select 100*12;:两个操作数都为整数形,则做数学运算select "123"+10;:只有其中一方为字符型,试图将字符型数值转换为数值型,如果转换成功,则继续做加法运输select "john"+10;:如果转换失败,则将字符型数值转换为0select null+10;:只有其中一方为null,则结果肯定为null
5.3 条件查询
-
select 字段名1,字段名2…from 表名 where 条件查询语句;-
=
-
<>或!=
-
<
-
>
-
>=
-
<=
-
and或&&
-
or或||
-
-
select 字段 from 表名 where 条件字段 between 查询参数 and 查询参数;:between and 两个值之间,在使用的时候必须左小右大 -
select 字段 from 表名 where 条件字段 is not null;:is null 查询字段为null#等同于 SELECT * FROM user WHERE uid = null -
select 字段 from 表名 where 条件字段 is not null;:is not null 查询字段不为null#错误示范,不能够使用 SELECT * FROM user WHERE uid != null -
*SELECT 字段 FROM user WHERE 字段 IN (2,3,5);:In 后面的值不是区间,而是具体的值 -
SELECT 字段 FROM user WHERE 字段 NOT IN (2,3,5);:not in#查询包括2,3,5的数据,相当于or SELECT * FROM user WHERE uid = 2 or uid =3 or uid = 5 -
SELECT * FROM 表名 WHERE 列表 LIKE '模糊字眼+占位符+模糊字眼';:模糊查询- 占位符
- _:单个任意字符
- %:多个任意字符
- 占位符
5.4 排序查询
-
select 字段 from 表名 order by 排序字段1 排序方式1,排序字段2,排序方式2…..;-
asc:默认升序
-
desc:降序
-
如果有多个排序条件,则当前边的条件值一样时,才会判断第二个条件。
5.5 分组查询和分组函数
5.5.1分组函数
count(字段):计数count(*):不是统计某一个字段中数据的个数,而是统计总记录条数count(col):表示统计某一个字段中不为null的数据总数量
max(字段):计算最大值min(字段):计算最小值sum(字段):计算和avg(字段):计算平均值
5.5.2 分组查询
select 分组字段... , 聚合函数... from 表名 group by 分组字段..;
select sex,avg(math),count(id) from student where>70 group by sex
#错误语法
select money from 表名 where money> avg(money) //ERROR 1111 (HY000): Invalid use of group function
无效使用了分组函数?
原因sql语句中有一个语法规则,分组函数不可以直接使用在where子句中,因为sql语句的执行顺序,分组函数是在 group by之后执行的,而 group是在where 执行之后才会执行的
分组的查询细节
-
分组函数一般都会和group by 联合使用,并且任何一个分组函数都是在group by语句执行结束后才会执行的,当一条sql语句没有group by语句,整张表数据会自动成一组(相当于默认执行group by)
-
当一条语句中有group by,select后面只能跟分组函数和参与分组的字段
-
group by后面可以跟多个分组字段,相当于/理解为将多个字段组成在一起成为一个字段再分组
-
where和having的区别?
-
where在分组之前进行限定,如果不满足条件,则不参与分组。having在分组之后进行限定,如果不满足,则不会被查询出来。建议优先使用where过滤,再使用having,提高效率。
-
where后不可以跟聚合函数,having可以进行聚合函数判断。
select sex,avg(math),count(id) from student where>70 group by sex having count(id)>2; -
5.6 分页查询
-
select 字段 from 表名 limit 开始的索引,每页查询的条数; -
select 字段 from 表名 limit 5;:取前5条数据、
计算出开始索引的公式!
开始的索引=(当前的页码-1)* 每页显示的条数
#每页显示3条记录
select *from 表名 limit 0,3; #第一页
select *from 表名 limit 3,3; #第二页
select *from 表名 limit 6,3; #第三页
5.7 数据处理函数
lower(col):查询出来转小写
upper(col):查询出来转大写
concat(col,col):将两个列的字符串的进行拼接
length(col):取长度
trim(字段/stirng):去空格
ifnull(col,预想值):如果col字段为null 那么就将该字段转换成一个预想值
DATE_FORMAT(now(),'%Y-%m-%d'):日期格式转换
case..when..then..when..then..else..end:看案例
select
ename,
job,
sal as oldsal,
(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as newsal
from
emp;
6、多表查询
笛卡尔积:若两张表进行连接查询的时候没有任何条件限制,最终的查询结果总数是两张表记录的乘积,该现象称为笛卡尔积
七总join理论:

6.1 起别名
select math as '字段别名1',english as '字段别名2' from 表名 as '表别名';
select math as '别名1',english as '别名2' from 表名;
起别名的细节
- as也可以省略不写,别名如果是中文需要用引号
- 所有的派生表必须有别名!要不然在子查询中就会报错
- 可以给表起别名,也可以给字段起别名
- 多表查询中起别名的好处
- 执行效率高
- 可读性好
- 多张表查询经常会出现相同字段的名称,此时就需要用添加表名,表明该字段是那一张表中的数据
6.2 多表查询的分类
6.2.1 内链接查询
定义:假设a和b表进行连接,使用内链接的话,凡是a表和b表能够匹配上的记录查询出来,这就是内链接。ab两张没有主副之分,两张都是平等的
6.2.1.1 隐式内连接(了解)
使用where条件消除无用数据
#查询员工和员工所在的部门
select
e.ename,d.dname
from
emp e, dept d
where
e.deptno = d.deptno
6.2.1.2显示内连接分为3种(掌握)
-
等值连接:表的连接条件和where过滤条件分离,语句结构更加的清晰
select 字段列表 from 表名1 [inner] join 表名2 on 连接条件 where 数据过滤条件
#查询员工和员工所在的部门 select e.ename,d.dname from emp e join dept d on e.deptno = d.deptno -
非等值连接
select 字段列表 from 表名1 [inner] join 表面2 on between and
#查询员工名和员工工资和员工工资等级 select e.name,e.sal,s.grade from emp e join salgrade s on e.sal between s.loasl and s.hisal -
自连接:把一张表当作两张表查询,自己连接自己
select 字段列表 from 表名1 别名1 [inner]join 表面1 别名2 on 连接条件
select e1.ename , e2.ename from emp e1 #员工表 join emp e2 #领导表 on e1.mgr = e2.empno
6.2.3 外连接查询
定义:假设a和b表进行连接,使用外链接的话,a表b表中有一张是主表,一张是副表。能够完全匹配的记录查询出来之外,将主表的数据无条件的全部查询出来,捎带着查询副表,当副表没有匹配的记录时,会自动模拟出null值与之匹配。
外连接的查询结果条数永远>=内连接的查询结果条数
-
select 字段列表 from 表1 left [outer] join 表2 on 条件;:会把左边表里的所有数据取出来,而右边表中的数据,如果有相等的就显示出来。 -
select 字段列表 from 表1 right [outer] join 表2 on 条件;:反之
6.2.4 内外连接多表查询案例
多张表如何连接:A表和B表先进行表连接,连接之后A表继续和C表连接,以此类推
#找出每一个员工,员工部门名称,员工等级,上级领导
select
e.ename
d.dname
s.grade
e1.ename
from
emp e
join
dept d
on
e.deptno = d.deptno
join
salgrande s
on
e.sal between s.losal and s.hisal
left join
emp e1
on
e.mgr = e1.empno;
6.2.5 子查询
查询中嵌套查询,称嵌套查询为子查询,将子查询结果作为主查询的数据再进行操作。
6.2.5.1 自查询可以出现在哪里
-
用在select后,作为要查询的数据
-
用在from后,将子查询的结果当作一张临时表(作为数据来源)
#查询出每一个部门的平均薪水,薪水等级 select t.*,s.grade from #先将每一个部门的平均工资查出 (select deptno,avg(sal) as avgsal from emp group by deptno) t join salgrade s on t.avgsal between s.losal and s.hisal -
用在where 和 Having后 作为过滤的条件,将子查询的结果当作条件进行判断
#查询最高的工资是多少,并查询员工信息工资等于最高工资的。 #第一步:查询平均工资 select max(salary) from emp; #第二步:拿到平均工资的值条件判断 select * from emp where salary=9000; #子查询:一条sql就完成这个操作。 select*from emp where emp.salary=(select Max(salary) from emp);
6.2.5.2 子查询的结果
-
单行单列
select * from emp where emp.salary<(select avg(salary)from emp);:子查询可以作为条件,使用运算符去判断。 -
多行单列
select*from emp where dept_id in(select id from dept where name=“财务部” or name=“市场部”);:子查询可以作为条件,使用运算符in来判断 -
多行多列
子查询可以作为一张虚拟表参与查询
6.3 联合查询
内链接是显示a表和b表on连接条件都有的部分 ,外链接是现实一个主表a全有的部分,副表b如果不满足on条件则用null替代。如果想要链接两张表,但是on条件不满足的话也都显示出来怎么办?
select··· union selec···;:将两张表的查询结果合并并且去重
# 显示两张表连接的部分和未连接的部分
select * from tb1_emp a left join tb1_dept b on a.deptId = b.id 1.先用左连查出左边都有的部分
union 3.将两个表链接去重
select * from tb1_emp a right join tb1_dept b on a.deptId = b.id 2.先用右连查出左边都有的部分
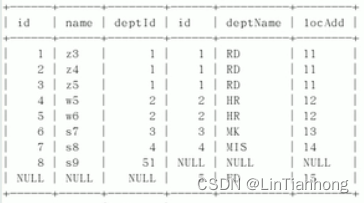
# 只显示两张表未连接的部分
select * from tb1_emp a left join tb1_dept b on a.deptId = b.id where b.id is null
union
select * from tb1_emp a right join tb1_dept b on a.deptId = b.id where a.id is null

七、约束
作用:对表中的数据进行限定,保证数据的正确性、有效性和完整性
分类:
- 主键约束:primary key
- 非空约束:not null
- 唯一约束:unique
- 外键约束:foreign key
7.1 非空约束
作用:值不能为NULL
# 创建表时添加约束
create table student(
id int;
#name不能为空
name varchar(20) not null
);
# 创建表完后,添加非空约束
alter table student modify name varcher(20) not null;
# 删除name的非空约束
alter table student modify name varcher(20);
7.2 唯一约束
作用:值不能重复
注意:在mysql中唯一约束限定的列的值可以有多个null
# 创建表时,添加唯一约束
create table student(
id int;
phone varchar(20) unique (添加唯一约束)
);
#删除唯一约束
alter table student drop index phone;
#在创建表后,添加唯一约束
alter table student modify phone varchar(20) unique;
7.3 主键约束
作用:值不能为空并且唯一
细节:一张表只能有一个字段为主键,主键就是表中记录的唯一标识
# 在创建表的时候,添加主键约束
create table 表名(
id int primary key,(给id添加主键约束)
name varchar(20)
);
# 删除主键
alter table 表名 modify id int;#错误
alter table 表名 drop primary key;
# 创建完表后,添加主键
alter table 表名 modify id int primary key;
7.4 自动增长
作用:如果某一列是数值类型的,使用 auto_increment 可以来完成值的自动增长,以1递增。
细节:如果给主键添加自动增长时,数据不能有为0的数值
# 在创建表时,添加主键约束,并且完成主键自增长
create table student(
id int primary key auto_increment,
name varchar(20)
);
#删除自动增长
alter table student modify id int;
# 添加自动增长
alter table 表名 modify id int auto_increment;
7.5 外键约束
作用:让表于表产生关系,从而保证数据的正确性。
注意:
- 外键值可以为null
- 子表的外键值不能随便写,必须要在父表关联的值中
- 外键字段引用其他表的某一个字段的时候,被引用的字段不一定要是主键,但是该字段至少具有unique约束
- 在建立约束后表和表的增删改查规则
- 删除数据的时候,先删除子表,再删除父表
- 添加数据的时候,先添加父表,再添加父表
- 创建表的时候,先创建父表,再创建子表
- 删除表的时候,先添加子表,再删除父表
#t_student中的classno字段引用t_class表中的cno字段。此时t_student就是子表,t_class是父表
#在创建表时,添加外键
#创建父表
create table t_class(
cno int,
#添加主键
primary key(cno),
cname varchar(20)
);
#创建子表
create table t_student(
sno int,
primary key(sno),
sname varchar(20),
classno int,
/*
foreign key(子表外键列) references t_class(父表字段)
*/
foreign key(classno) references t_class(cno)
);
#删除外键
alter table 表名 drop foreign key 外键名称;
#创建表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名称) references 主表名称(主表列名称);
7.6 级联操作
同生共死 你懂吗?
级联操作有两种:级联删除(on delete cascade)、级联更新(on update cascade)
alter table 表名 add constraint 外键名称
foreign key(外键字段名称) references 主表名称(主表列名称) on update cascade on delete cascade;
八、事务
10.1 事务的基本介绍
事务只和DML语句相关,如果一个包含多个步骤的业务操作,被事物管理,那么这些操作要么同时成功,要么同时失败。
start transaction;:开启事务
rollback;:回滚
commit;:提交
10.2 数据库的事务提交
10.2.1 事务提交的两种方式
自动提交:mysql就是自动提交的,只要执行一条DML(增删改)语句会自动提交一次事务。
手动提交:Oracle数据库默认是手动提交事务,需要先开启事务,再提交
10.2.2 修改事务的默认提交方式
-
select @@autocommit;: 查看事务的默认提交方法:- 1:代表自动提交
- 0:代表手动提交
-
set @@autocommit=0;:修改默认提交方法
10.3 事务的四大特征
- 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败。
- 持久性:当事务提交或回滚后,数据库会持久化的保存数据。
- 隔离性:多个事务之间,相互独立。
- 一致性:事务操作前后,数据总量不变。
10.4 事务的隔离级别(了解)
多个事务之间隔离的,相互独立的。但是如果多个事务操作同一批数据,则会引发一些问题,设置不同的隔离级别就可以解决这些问题
10.4.1存在问题:
-
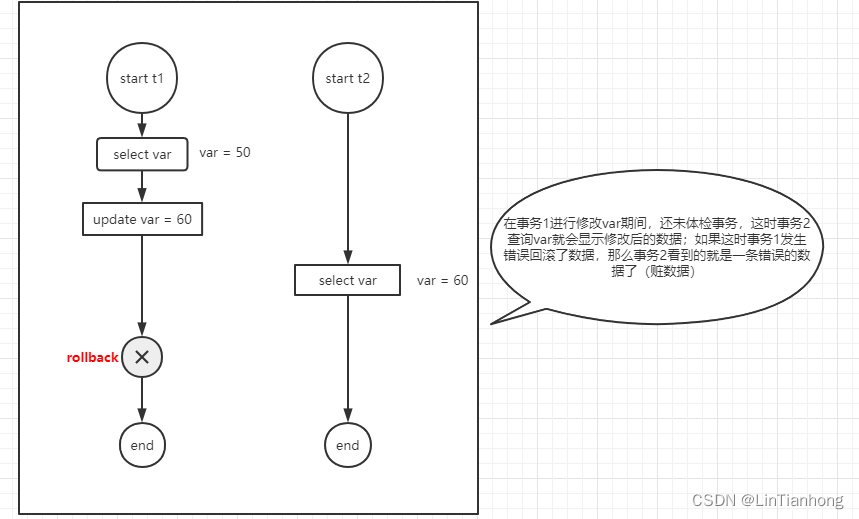
脏读:一个修改数据的事务正在执行修改但是这个修改事务还未提交,这时有另一个读取数据的事务也请求了这个数据,这时这个读取事务可以读取到修改事务还未提交的数据。这就是“脏数据”。
-
不可重复读(虚读):在同一个事务中,两次读取到的数据不一样。意思是:事务A查询了表C,此时事务A还未提交,这时事物B对表C进行了修改操作并且提交了事物。当修改后,事务A又查询了一次表C,这时候在同一个事务A中的两次查询结果就不一样了
-
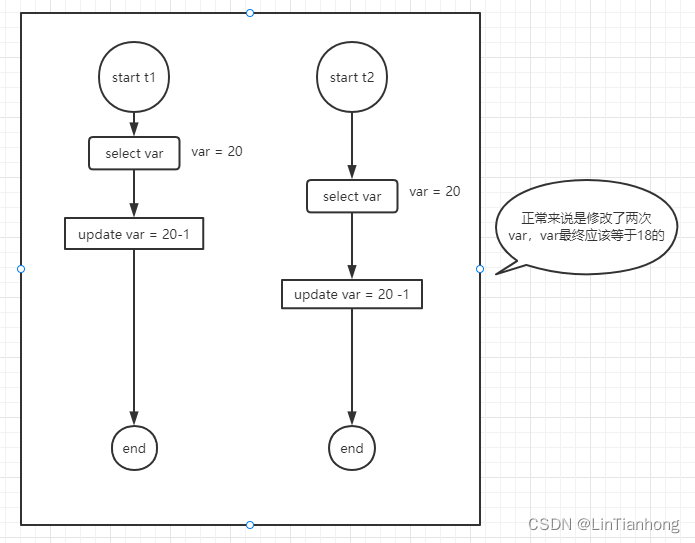
丢失修改:事物1和事物2都要修改A数据(假设A数据为20),因为他们从表中读取到的A数据都是20,事物1和事物2都进行了-1操作,所以当两个事物都修改结束后A数据还为19;但是我们所期望的A数据应该是18。
-
幻读:一个事务操作(DML)数据表中所有记录,另一个事务添加了一条数据,则第一个事务查询不到自己的修改。
10.4.2 隔离级别
- read uncommitted:读未提交
- 产生的问题:脏读、不可重复读、幻读
- read committed:读已提交(Oracle默认)
- 产生的问题:不可重复读、幻读
- repeatable read:可重复读(MySQL默认)
- 产生的问题:幻读
- serializable:串行化
- 可以解决所有的问题
设置隔离级别:隔离级别其实就是用过锁机制实现的,数据库给用户提供了隔离级别从小到大安全性越来越高,但是效率越来越低
select @@tx_isolation;:数据库查询隔离级别set global transaction isolation level 级别字符串;:数据库设置隔离级别
九、约束
什么是索引?
索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
MySQL在查询方面主要就是两种方式,全表扫描、根据索引检索
9.1 什么条件会考虑给字段添加索引呢?
- 数据量庞大(到底有多么庞大算庞大,这个需要测试,因为每一个硬件环境不同)
- 该字段经常出现在where的后面,以条件的形式存在,也就是说这个字段总是被扫描。
- 该字段很少的DML(insert delete update)操作。(因为DML之后,索引需要重新排序。)
建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。建议通过主键查询,建议通过unique约束的字段进行查询,效率是比较高的。
9.2 索引的分类
单一索引:一个字段上添加索引。
复合索引:两个字段或者更多的字段上添加索引。
主键索引:主键上添加索引。
唯一性索引:具有unique约束的字段上添加索引。
在MySQL当中,主键上,以及unique字段上都会自动添加索引的!!!!
9.3 创建索引
-
create index 索引名 on emp(字段);:创建索引 -
drop index 索引名 on emp;:删除索引 -
explain select * from emp where ename = 'KING';:查看select语句是否有用到索引
9.4 索引的失效
- 使用左模糊查询
- 使用or的时候会失效,如果使用or那么要求or两边的条件字段都要有索引才会走索引检索。如果其中一边有一个字段没有索引,那么另一个字段上的索引也会失效,所以这就是为什么不建议使用or的原因。
- 在where当中索引列参加了运算,索引失效。
- 在where当中索引列使用了函数
十、DCL:数据库管理员
create user ‘用户名’@‘主机名’ identified by ‘密码’;:添加用户
drop user ‘用户名’@‘主机名’;:删除用户
update user set password = password(‘新密码’)where user =‘用户名’;:修改用户密码方式一
set password for ‘用户名’@‘主机名’=password(‘新密码’);:修改用户密码方式二
10.1 mysql中忘记了root用户的密码
#需要管理员身份运行cmd
net stop mysql #停止mysql服务,
mysqld - -skip-grant -tables #使用无验证方式启动mysql服务
#打开新的cmd窗口,直接输入mysql命令,回车,就可以登入成功
use mysql;
update user set password=password(‘你的新密码’) where user=‘root’;
#打开任务管理器,手动结束mysqld.exe的进程
#启动mysql服务
#使用新密码登入。
10.2 查询用户
use mysql;:切换到mysql数据库
select*from user;:查询user表
通配符:%表示可以在任意主机使用用户登入数据库
10.3 权限管理
show grants for ‘用户名’@‘主机名’;:查询权限
grant 权限列表 on 数据库名.表名 to ‘用户名’@‘主机名’;:授于权限
grant all on *.* to ‘用户名’@‘主机名’;:赋予超级权限
revoke 权限列表 on 数据库.表名 from ‘用户名’@‘主机名’;:撤销权限
















 6694
6694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











