






 本文探讨了传统数据库索引优化的局限性,提出引入机器学习技术的AIOps解决方案,通过模型训练和预测自动推荐索引,以应对大规模业务场景下的SQL优化挑战。着重介绍了模型的关键流程,包括SQL解析、统计特征提取和XGBoost模型的应用。未来规划涉及数据库的扩展和大模型技术的应用.
本文探讨了传统数据库索引优化的局限性,提出引入机器学习技术的AIOps解决方案,通过模型训练和预测自动推荐索引,以应对大规模业务场景下的SQL优化挑战。着重介绍了模型的关键流程,包括SQL解析、统计特征提取和XGBoost模型的应用。未来规划涉及数据库的扩展和大模型技术的应用.
一、课题背景
在老 DBA圈子里曾流传一句话,“研究数据库就是研究索引,索引用好了能解决 80% 的数据库问题”。这足以看出索引对于关系性数据库的重要性。
对于传统的业务 DBA 来说,其中一项重要的日常工作就是做 SQL 优化,而 SQL 优化中最主要的内容就是索引优化和语句的等价改造。
但是当业务和数据库规模都达到相当的程度时,比如每日产生上亿条慢查询时,再依赖人肉运维将不是个现实的选择。
在此前提下,数据库运维领域慢慢发展出了基于规则、代价的慢查询索引优化,这在一定程度上解放了人力,但仍旧存在一些不足,主要集中在特定规则无法满足多变的业务需求、也无法适应不同水平的开发人员所编写的各式各样的 SQL,而且用来进行代价估计的统计信息也不一定时时刻刻都是准确的。
鉴于上述,便有了此课题的由来,将机器学习的能力引入到原先需要依靠人肉运维的领域,也即——AIOps。
二、原理和关键流程
传统的 SQL 优化主要从两个角度出发:
-
根据 SQL 中使用的字段,及其条件、关联、聚合等用法,来判断是否以及如何创建索引,提高数据检索和处理效率;
-
分析语句的业务逻辑,然后在结构和语法上进行等价改写,或通过 Hint,指导解析器给出更优的执行计划。
本课题主要讨论第一种。
既然说到索引推荐,我们先回顾一下索引优化时的几个要点:
-
常用业务逻辑中会根据哪个或哪些字段做检索;
-
常用多表关联中使用到哪个或哪些字段;
-
表以及对应字段的统计信息,也就是数据的分布情况等统计特征。
前两点对于开发人员或者开发 DBA ,那些相对熟悉业务的人来说,问题不大,但对于运维 DBA 或者运维平台来说,这属于上难度了,需要事先去理解业务,或者通过筛选 TOP SQL 来做文本语义分析。
了解了上述过程,下面就可以介绍本课题所产出的工具了,原理上就是按照该流程进行设计的:

整个系统分为两部分:一是模型训练部分,属于离线部分,即上图左侧;二是预测推荐部分,用于在线给出推荐索引,即图中右侧。
其中通用的模块包括:
-
SQL 语法解析和语义特征提取
-
统计特征提取
-
索引组合生成以及滤除
-
特征工程
-
模型训练、优化等
下面对每个模块做一简略介绍。
2.1 语法解析&语义特征提取
业界已有不少成熟且广泛使用的工具,比如大名鼎鼎的 ANTLR。但出于投入产出和项目整体考虑,本课题在该模块中选用 python 的 sqlparse 包实现。
sqlparse 是一个无验证的 SQL 解析器,它支持解析、拆分和格式化SQL语句。其官方网址为https://sqlparse.readthedocs.io/en/latest/,想要深入了解学习的可以直接阅读源码,这个项目源码的可读性还不错,注释很细致。
其中包含 4 个主要的模块级别函数:split,format,parse,parsestream,以及三个很关键的基类:Token,TokenList 和 Statement。具体描述和用法就不在本文赘述,有许多资料可供参考。
接下来,要实现根据给定的 SQL 语句解析得到具有一定语义特征的关键字段,特征包括:WHERE、JOIN、聚合函数、ORDER BY、GROUP BY,以及常见的等值和范围查询等等。
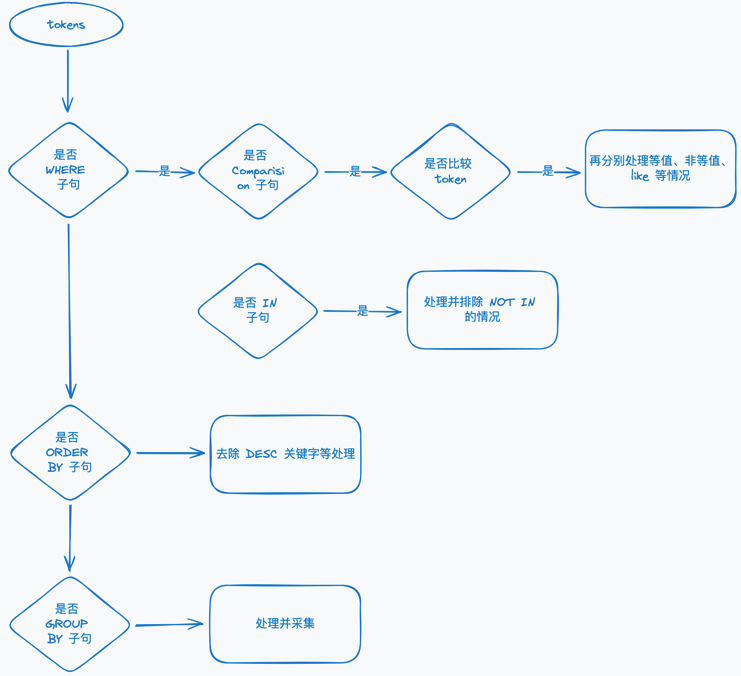
下图简单说明了解析后的 SQL(即 Tokens),如何根据不同语义提取所需要的字段的大致流程。
2.2 统计特征提取
上面完成了 SQL 语句的解析,得到了语句相关的表(table)和列(column),并且通过分析,获取了语义特征信息。
但光有这些是不够的,毕竟由此进行枚举和排列组合得到的单列及多列索引会很多,仅仅通过语义特征去进行模型训练,可以预想到的准确率并不会太高。所以接下来我们要做的就是通过访问数据库元数据,来提取表、列的统计特征。
再进行索引优化时,DBA 通常会关注以下指标:
-
表的「总行数」
-
列的「类型」
-
列的「空值个数」
-
列的「不同值个数」
-
以及列的「选择性」等等
当然还可以根据需要扩充统计特征,只要能辅助判断创建索引的必要性,就可以纳入特征向量的构建中来。
以 MySQL 为例,其统计信息是指数据库通过采样、统计出来的表、索引的相关信息,例如,表的记录数、聚集索引 page 个数、字段的 Cardinality 等等。MySQL 在生成执行计划时,需要根据索引的统计信息进行估算,计算出最低代价(或者说是最小开销)的执行计划。当然,其它数据库统计信息的概念也是相似的,甚至可能相比 MySQL 来说会更丰富、更完善。
MySQL 的持久化统计信息存储在 mysql.innodb_index_stats 和 mysql.innodb_table_stats 中,非持久化的统计信息存储在内存中,本文暂时不涉及。
对于 MySQL 8.0,官方才推出了直方图(histogram),直方图数据存放在 information_schema.column_statistics 这个系统表下,每行记录对应一个字段的直方图,以json格式保存。同时,新增了一个参数 histogram_generation_max_mem_size 来配置建立直方图内存大小。
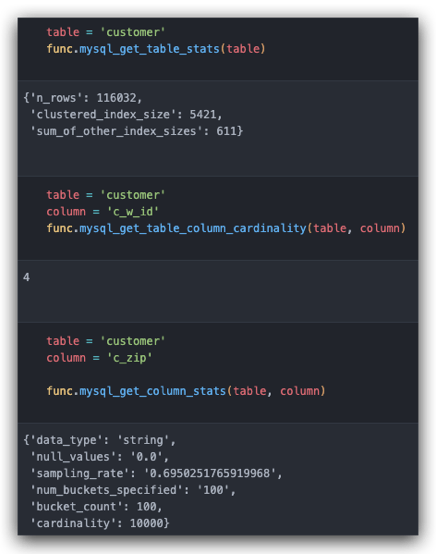
基于以上信息,可以实现统计特征的提取,如下图所示,分别为:获取表统计信息、获取指定字段 cardinality、获取指定字段直方图信息。
2.3 索引组合
在索引相关的特征提取完之后,到设计特征向量之前,还有一步需要处理,就是如何生成完整的候选索引组合,其中包括单列索引和复合索引。
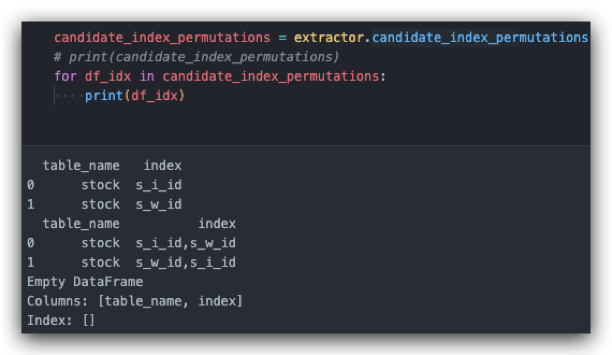
对于单个 SQL,其中每个表的访问只能使用该表其中一条索引。所以需要针对该 SQL 涉及到的所有表,以及每个表在该 SQL 中的所有具有语义特征的字段进行收集,再进行排列,得到单列、双列、三列索引(注:当前暂时不考虑 >3 列的索引推荐)。
下图展示了不同索引组合的输出:
2.4 特征工程&建模
特征,就是目标对象自身拥有的,或者可以通过加工计算得来的属性。对于一个候选索引(准确地讲,就是某个表的字段组合)来说,前面已经介绍了其两大类特征:「语义特征」和「统计特征」。接下来就要基于此进行特征向量的构建。
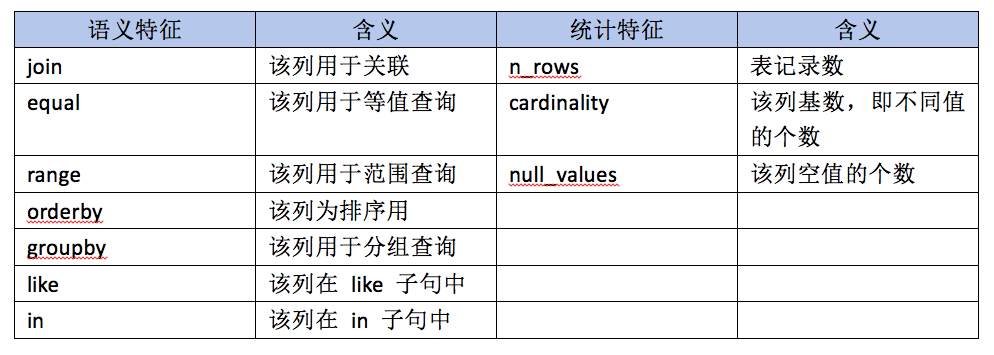
以上列出了本课题中使用到的具体特征维度,当然也可以根据自身需要进行扩展。至于多列索引的特征,需要将每个列的特征拼在一起,同时需要注意按顺序拼接,因为(col1,col2) 和 (col2,col1)是完全不同的两个索引,索引推荐对字段顺序是敏感的。
分别针对单列、两列和三列候选索引(字段组合)进行特征向量构建后,需要进行正负样本的标记,即:针对某个查询 Q1,涉及表 A 和表 B,其中 A 表生成的候选索引中,为查询 Q1中使用到的索引标记为正样本(tag=1),其余候选索引均标记为负样本(tag=0)。这样,就为推荐模型准备好训练集。
2.5 模型训练和预测
前面准备好的训练集还需要进行一些预处理,包括空值处理、全 0 行预清除、数据类型标准化等等。由于单列和多列索引的特征维度不同(即字段个数不同),不能进行模型混用,需要分开训练和预测。本课题最终选用 XGBoost 二分类模型,离线训练好的模型的可以通过 joblib 包保存为二进制文件,并于在线模块导入后进行预测。当然,真正是否推荐并且采纳系统给出的索引时,还可以在模测环境进行实测验证,每次验证以及用户的反馈得到的信息,又可以存回训练数据集用来迭代模型,用于提高预测准确率。
三、未来规划
目前该课题的工程实现还只支持 MySQL 数据库,后续需要扩展到其它关系型数据库,如 openGauss 等。
另外,大模型技术的兴起,也越来越被业界认可,尤其在问答领域。鉴于此也可以尝试将开源大模型微调并接入索引推荐工作流中,为用户提供更便捷的使用体验。
作者:中国工商银行软件开发中心广州技术部


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









