







Java爬取深圳新房备案价
这是我做好效果,一共分3个页面
1、列表;2、统计;3、房源表
列表
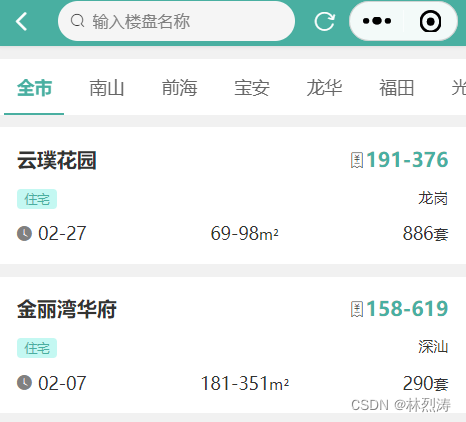
价格分析页面
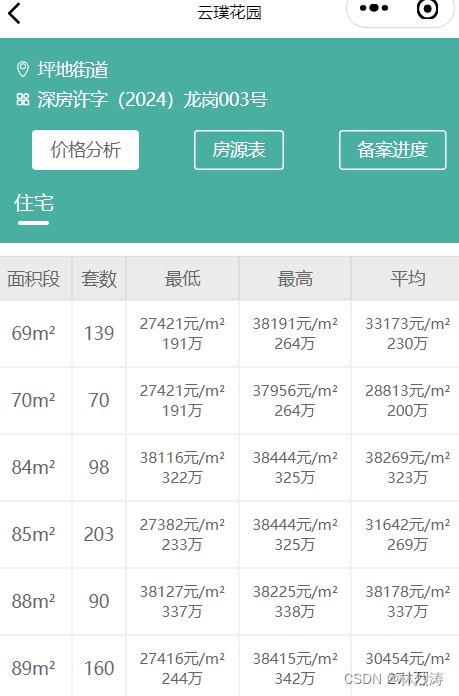
房源页面

一、如何爬取
第一步:获取深圳新房备案价
链接是:http://zjj.sz.gov.cn/ris/bol/szfdc/index.aspx
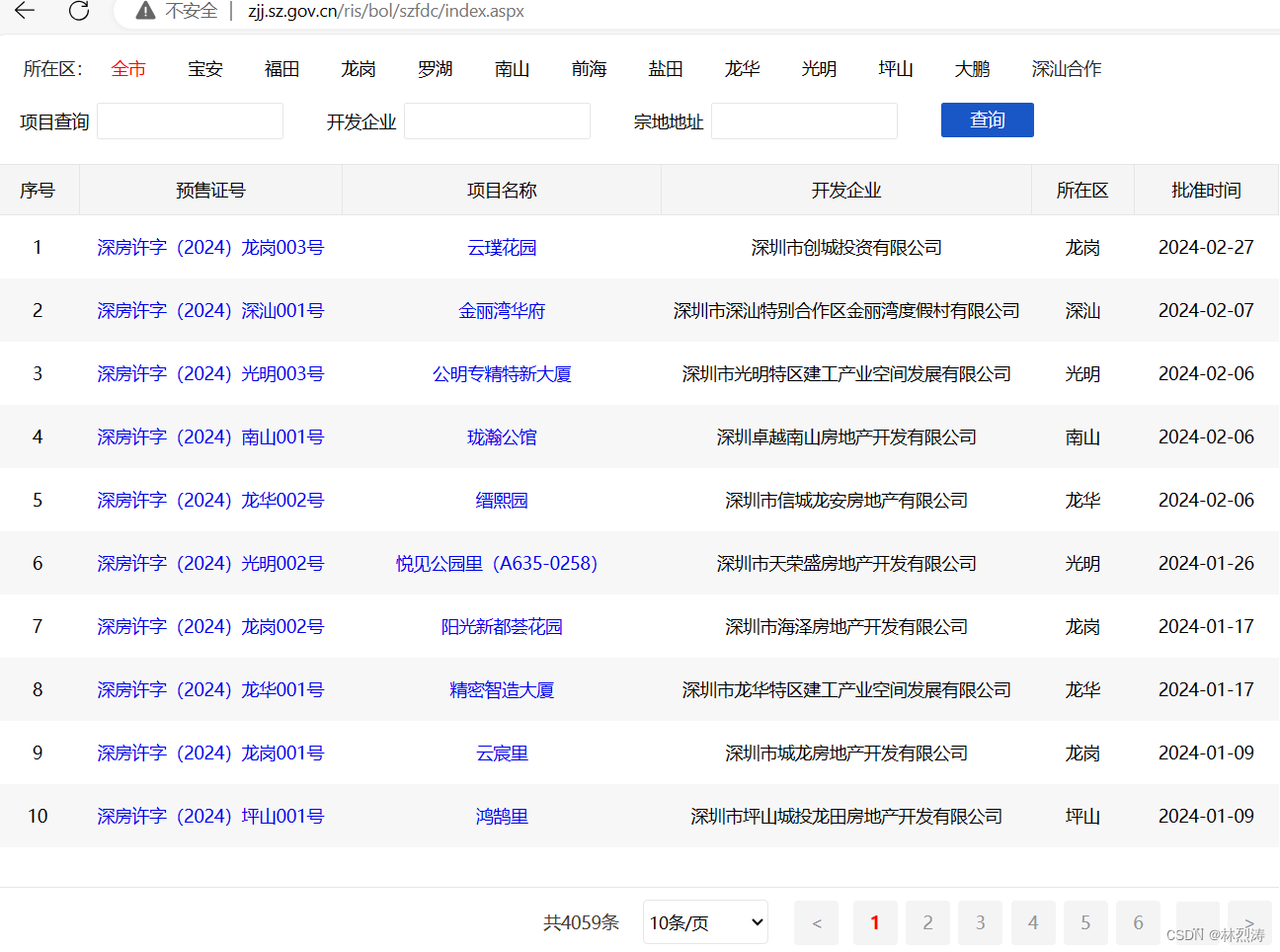
第二步:通过楼盘名查询获取明细
链接:http://zjj.sz.gov.cn:8004/
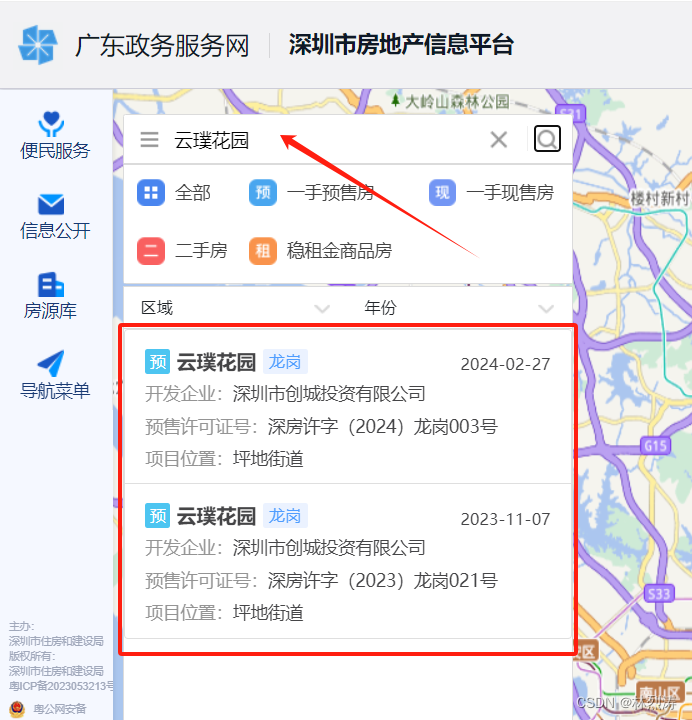
点 更多详情
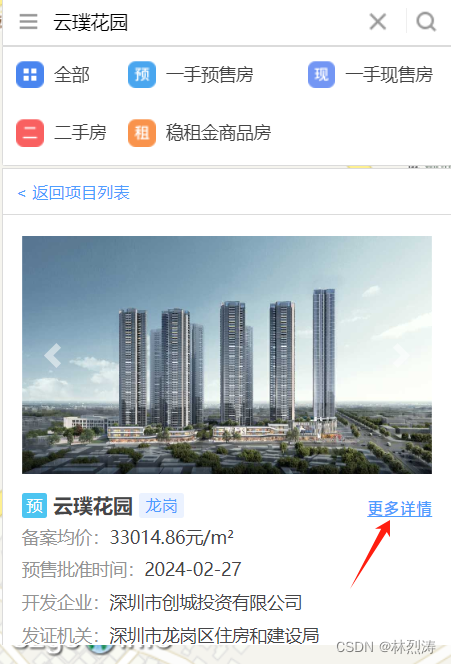
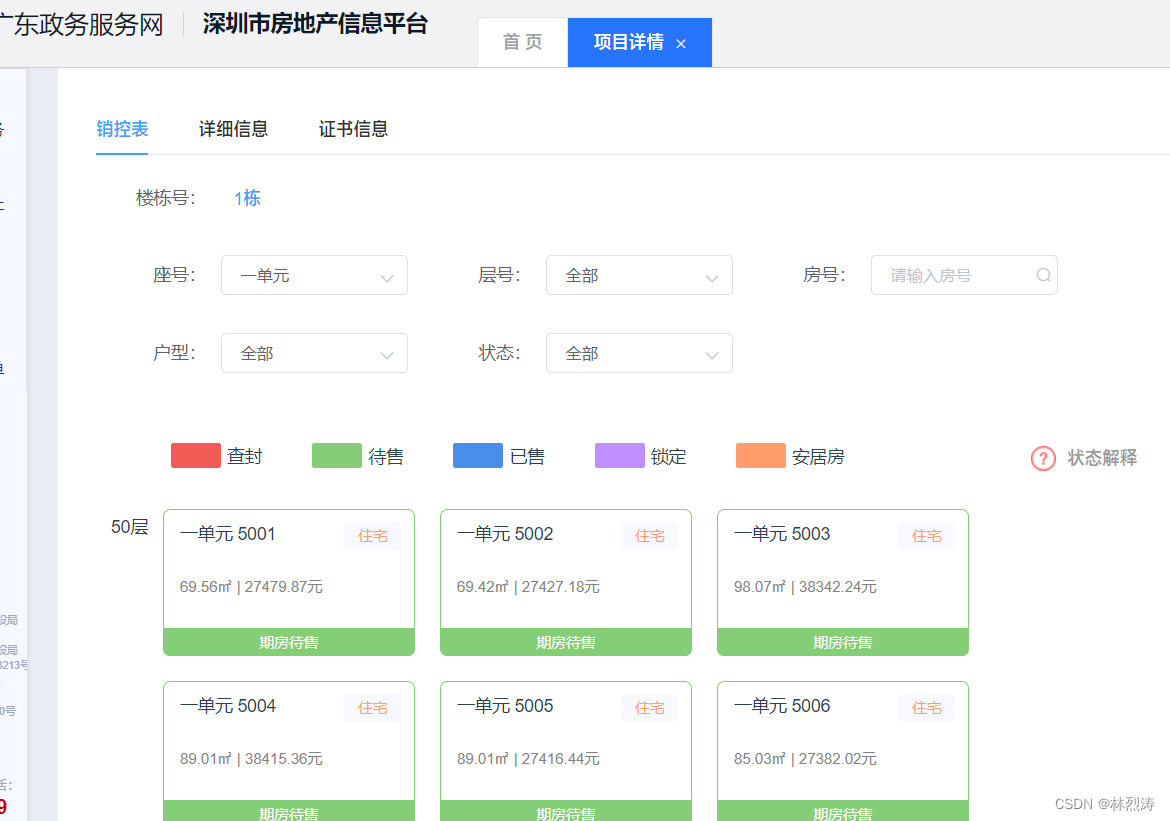
获取到具体明细
数据库建立
爬取到的数据存放在mysql数据里面,建立自己新房价格数据。
第一个表:主列表设计 命名 t_fcProject
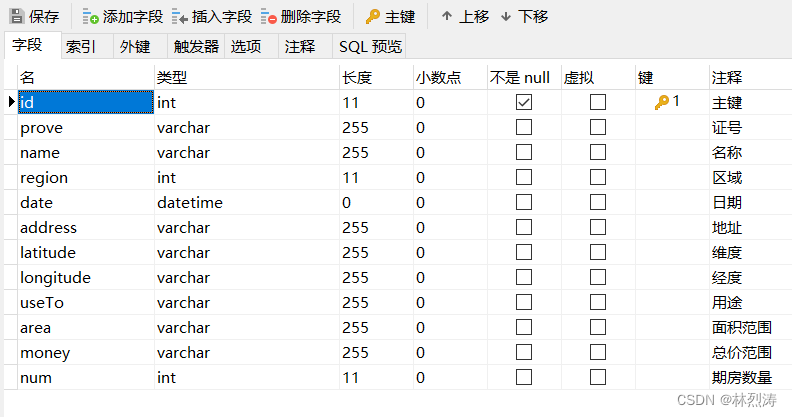
数据效果:

第二个表:楼栋 命名t_fcFloor
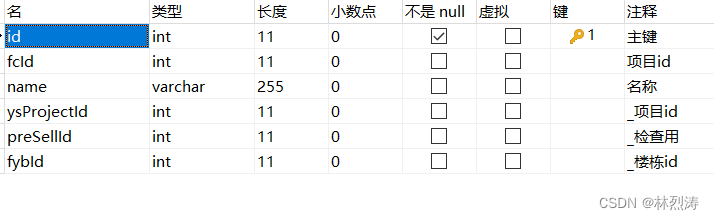
数据效果:
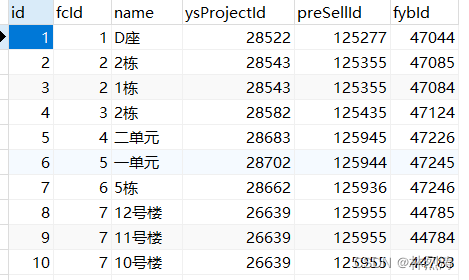
第三表:单元 命名:fcBranch
数据效果:
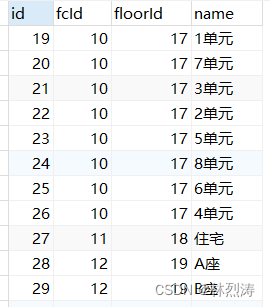
第四表:具体到房 命名:t_fcHouse
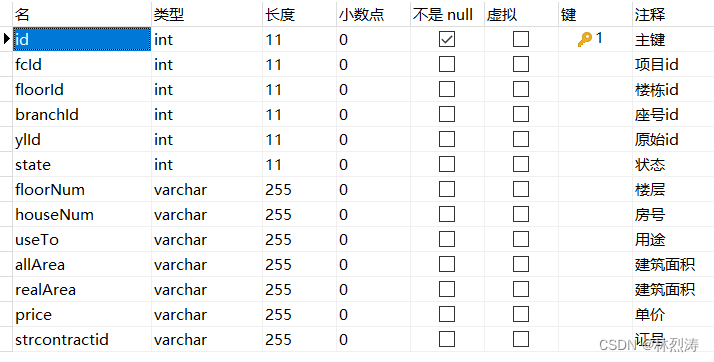
数据效果:
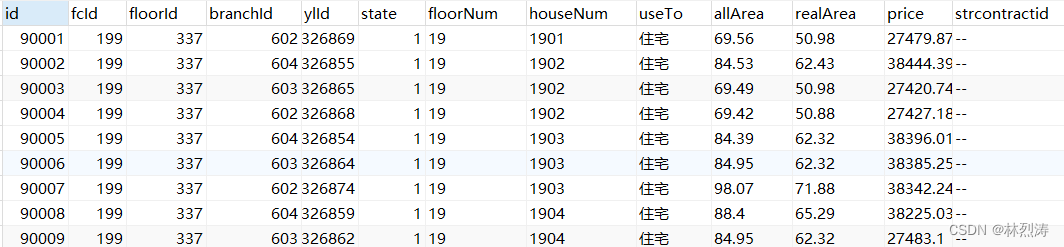
第五表:数据统计 命名:t_fcAnalyse
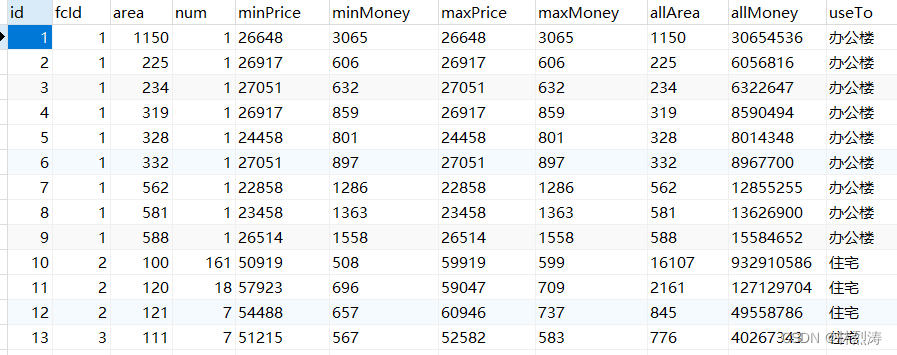
数据效果:
java代码
用到的是springboot,这里展示是service层
解析一下代码意思:
获取最新的时间,获取官网页面10条项目
日期相同则,比较取证号是否存在;日期不相同,比较是否在日期之前。
private List<FcProject> getListIndex() {
//获取最新时间 从redis获取,获取不到从数据库获取
Object o = redisUtil.get("checkFc");
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date d1 = new Date();
if (o != null) {
try {
d1 = dateFormat.parse(o.toString());
} catch (Exception e) {
System.out.println("日期转化失败1");
}
} else {
d1 = fcProjectMapper.queryNewDate();
redisUtil.setValue("checkFc", dateFormat.format(d1));
}
//获取官方页面 最新10条
String url = "http://zjj.sz.gov.cn/ris/bol/szfdc/index.aspx";
Document doc = Jsoup.parse(httpsUtil.doGetHtml(url));
Elements trs = doc.select("table").select("tr");
List<FcProject> list = new ArrayList<>();
for (int i = 1; i < trs.size() - 1; i++) {
Elements tds = trs.get(i).select("td");
//1-5 date 2023-11-24
String dateStr = tds.get(5).text();
//string => date
Date d2 = null;
try {
d2 = dateFormat.parse(dateStr);
} catch (Exception e) {
System.out.println("日期转化失败2");
}
//日期相同则,比较取证号是否存在;日期不相同,比较是否在日期之前。
if (d2 != null) {
boolean isPass=false;
//日期相同
if (d2.equals(d1)) {
//判断取证号是否存在
isPass=fcProjectMapper.queryByProve(tds.get(1).text())==null;
} else if (d2.after(d1)) {
//是否在日期之前
isPass=true;
}
if(isPass){
FcProject fcProject = new FcProject();
//1-1 prove
fcProject.setProve(tds.get(1).text());
//1-2 name
fcProject.setName(tds.get(2).text());
//1-4 region 龙岗
String region = tds.get(4).text();
fcProject.setRegion(regionStrToInt(region));
//日期
fcProject.setDate(d2);
ThrowException.illegal(fcProjectMapper.insertSelective(fcProject) < 1, "添加失败");
list.add(0, fcProject);
}
}
}
//删除redis日期
if(!list.isEmpty()){
redisUtil.del("checkFc");
}
return list;
}
获取到有新项目之后,则有楼盘名称和取证号
通过楼盘名查询到具体地址,为了避免还用了取证号做一下对比,相同才取
把具体地址解析成 经纬度(在小程序就可以直接跳转地图形式做准备)
获取楼栋
private void handleAll(Integer id, String name, String prove) {
//请求接口--查询项目
Map<String, Object> mapProject = getProjectMap( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









