






关注了就能看到更多这么棒的文章哦~
AI from a legal perspective
By Jake Edge
September 26, 2023
OSSEU
ChatGPT translation
https://lwn.net/Articles/945504/
人工智能热潮已经来临,但围绕着这项技术仍然存在许多问题。其中一些涉及到法律问题,已经有诉讼在进行中,希望能得到澄清或者得到可能的赔偿。范·林伯格(Van Lindberg)是开源界中知名的律师;他来到2023年在西班牙毕尔巴鄂举行的Open Source Summit Europe,试图将当前的人工智能工作放入法律背景中。
林伯格首先介绍了自己;他已经涉足计算机法律领域大约25年了。在这段时间里,他还参与了开源工作(特别是作为Python软件基金会的前总法律顾问)。他自2008年以来也一直在研究人工智能问题,因此他现在在处理这些问题时处于一个良好的位置,因为"整个世界开始为人工智能疯狂"。

他询问观众是否主要认同自己是技术专业人员还是法律领域的成员;他说,观众的回应"不完全是一半一半",但他提到他会在演讲的不同部分令这两个群体都感到失望。他的技术描述有关当今人工智能中使用的技术可能对技术专业人员来说有些乏味,而他将谈论的案例可能已经为受过法律培训的人所熟知。但他说,好消息是人工智能和法律的交叉领域正在迅速发展,他的演讲对每个人都应该有新鲜内容。
在演讲中,他只会关注"生成式机器学习";他知道有关旧的人工智能研究,但"生成式机器学习是真正推动这一人工智能革命的东西"。从法律角度来看,这也更有趣且更具挑战性。他将关注过去五年内领域的进展,尽管他将要呈现的大部分内容来自过去三到四年的研究。
他的演讲是他在2023年早些时候发表的一篇论文的缩短版本。它涵盖了模型的训练和它们的推理,以及从美国法律角度的版权影响。演讲也将聚焦于美国法律,因为"当前很多行动发生在那里"。他还指出,有一篇以英国法律为重点的文章,感兴趣的读者可以查阅;到目前为止,他还没有找到一篇类似的研究从欧盟法律的角度来探讨这个问题。
Models
当涉及人工智能时,"模型"这个词被很多人误解,林伯格说。许多人认为它是"可以按照我的意愿执行操作的神奇黑盒子",但理解模型的真正含义、它们的工作原理以及它们的训练方式,对于"应用正确的法律分析"非常重要。他使用一个比喻试图给观众一个关于模型正在发生什么的"良好的心理图像"。
想象有人被聘为"艺术品检查员",负责检查卢浮宫博物馆的所有艺术品。当他被雇佣时,他对"艺术一无所知";他不知道什么是好艺术,什么是坏艺术,不知道不同类型的艺术,等等。他着手弥补这个知识的不足,通过测量与每件艺术品相关的一切来办到这一点:大小、重量、使用的材料、使用的颜色、创作日期和地点等等。他还测量一些随机的事物,比如艺术家名字中的音节数以及他们选择在哪个角落签名;他将所有这些信息记录在他的笔记本中(即数据库)。
随着时间推移,他开始觉得工作变得相当乏味,于是他发明了一个游戏:在测量之前,他将使用他已经知道的信息来猜测测量结果。起初,他的猜测非常糟糕,但在观察了成千上万,甚至数百万幅画作后,他的猜测开始变得更准确,然后变得更加准确。他可以在只有一点关于艺术品的信息作为起点的情况下,做出相当准确的猜测;他有效地识别了允许他做出这些准确猜测的隐藏模式。
这个比喻展示了模型训练的过程。它包括四个步骤:测量、预测、检查和更新,这些步骤被重复进行了数十亿次。当人们谈论模型的创建时,他们经常说这个过程是在"阅读"数据或"吸收所有这些内容";这在某种程度上是正确的,但并不完全准确。训练过程是提取数据的某些统计测量;它计算与这些测量和数据集相关的概率。
然后,这些概率用于预测关于其他已知正确答案的训练数据的事物。这些预测与答案进行了比较检查。例如,对于类似ChatGPT的模型,它将使用现有文本中的下一个词来进行检查。对于"it was a dark and stormy X","night"将是高概率的完成词,而"elephant"将是极低概率的。根据检查结果,训练过程会更新其所有概率,以使其在下一次更有可能产生高概率的完成词。它会重复执行这个过程数百万次或数十亿次。
他说,这描述了"几乎任何类型的机器学习"的训练过程;不同之处在于训练的是什么类型的数据。其结果就是模型,它具有特定的架构,包括用于分解输入的机制、用于分析这些输入的方法,以及表示输出的方式。架构不是一种实现,而只是模型开发者头脑中存在的逻辑构建;使用诸如PyTorch之类的代码是模型架构的实现。
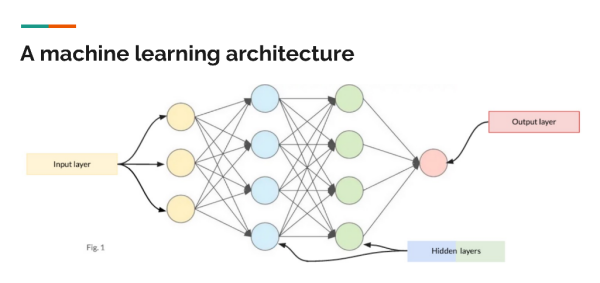
[机器学习架构]
架构有专门的输入、输出和一些对模型的推理(猜测)至关重要的隐藏层。它们的排列方式就像林伯格演示幻灯片中的那个人工神经网络一样。输入层将输入以某种方式转换为数字;输入可以是像素值、单词或日志文件中的值。"输入代表的内容并不重要",只要它被转化为有用的数字即可。然后,输出层将来自隐藏层的结果转化为模型的最终预测结果。
隐藏层有概率,通常称为"权重",与隐藏层中节点的输入和输出相关联。与金融模型不同,金融模型是确定性的,机器学习模型是"从一组输入到一组输出的概率映射"。他说,模型使用一种类似于贝叶斯定理的技术来进行概率计算;它"本质上是一个多十亿参数的贝叶斯计算"。磁盘文件中的权重只是一个大型的浮点值矩阵,对应于模型不同部分的概率。
他说,权重"只是一堆数字;它不具有创造性,也不具有表现力"。它们只是一个机械过程的结果。这一点很重要,因为它直接影响了法律可能会如何对待这些模型的性质。人们对人工智能应用的心理模型将指导他们对待机器学习模型的信仰;那些将其视为"神奇黑盒子"的人会赋予它"根本不存在的东西"。这可能会导致人们认为逻辑、情感和意图等因素在模型内部;实际上,模型只是"一个非常复杂的统计方程—仅此而已"。
Intellectual property
在考虑知识产权(IP)法如何适用于人工智能时,有几个机器学习过程的部分可能会涉及到知识产权法。它可能适用于训练过程、模型本身、架构和代码,或者输出;每一个都需要独立分析,以确定适用的法律。林伯格说:"输入和输出都不是那个中间的模型"。
当前围绕人工智能和知识产权的许多活动都涉及到一个问题,那就是在训练机器学习模型时可以使用多少受版权保护的材料。主要是艺术家,但也在一定程度上包括了程序员,会担心他们的作品被合并到这些模型中,而未给版权持有人付报酬。创作者提出的论点是,如果这些作品不存在,就没有办法训练模型,因此他们应该得到报酬。
但是他说,版权法并不保护对作品的每种使用,这些保护在欧洲、亚洲和美国基本上是相同的。美国版权法中有一些特定的动词:复制、创作衍生作品和表演;这些是唯一受版权保护的行为。所有其他用途要么不受版权保护,要么属于"合理使用";后者意味着它们已经被判定为不受版权保护。
"进行作品分析"是经典的合理使用之一;这种分析可以是对作品的摘要、评论或批评。因此,在读一本书并在《纽约时报》等报纸上做评论是对受版权保护作品的合法使用。同样,对受版权保护作品进行文本分析以收集统计信息或文体信息不是版权法所反对的行为,它是对作品的合理使用。
他说,Google Books诉讼对正在针对人工智能工作提起的诉讼就与此非常相关。Google Books是搜索巨头创建的书籍索引,通过扫描实体书籍而创建,这是由Authors Guild提出的侵犯版权的诉讼的目标。最终确定Google Books是合理使用,部分原因是搜索索引不是书本本身的替代品;版权旨在保护创作者免受他人在市场竞争中使用他们的作品的行为。
目前的诉讼支持者指出,生成式人工智能正在创建与原始作品竞争的作品,至少在潜在上是这样。但他说:"版权是关于一个可以被侵犯(infringed)的作品的,一个非常具体的作品";版权不保护"你对市场的看法,以及你在市场上相应地生产作品的能力"。
目前尚未裁决这些人工智能案件,但他在论文中所提出的观点是,这些模型实际上与Google Books所做的相同。模型的训练只是采集了大量的测量数据,而模型产生的结果并不是对作品本身的竞争。他相信法院将认为模型是对作品的合理使用,但"没有人能确定这一点"。
然而,有一个棘手的问题:当其中一个模型生成与其输入完全相同的文本或图像时会发生什么?"答案是:那是侵权的。"很明显,可以从人工智能模型生成侵犯版权的输出。他认为模型本身会被认定为合理使用,"输出的产物,也许会被判定为合理使用,也许不会"。这完全取决于具体的输出结果。
Lindberg表示,从这些模型生成侵犯版权的输出非常容易;一种简单的方式是去使用一个图像生成模型,并给它一个像"Iron Man"这样的提示。在美国和其他地方,一个足够详细的角色可以受到版权保护;这意味着版权覆盖的范围不仅限于特定的书籍、电影或图像。因此,将这样的提示用于图像生成人工智能将创建一个"完全新的Iron Man图片,绝对侵犯版权—100%”。
代码,与英语等自然语言相比,自由度较低,至少看起来更容易被复制。由于缺乏自由度,模型中的概率会趋于使输出更频繁地看起来像一些输入代码,而不是文本中所看到的频率。模型本身并没有记住代码,但它"记住了如何重新创建它,这是一种复制的方式"。因此,这些输出可能会侵犯版权。
事实证明,更多的训练输入会导致更少的侵权输出。一项试图生成侵权输出的研究能够从使用了9万张训练图像的模型中找到108张复制的输出图像。但当他们将相同的技术应用于一个完整规模(full-scale)图像模型时,找到的复制图像数量接近零。
Lawsuits
他展示了一个包含五起已提起诉讼的幻灯片;前四起(v. GitHub、Stability AI、OpenAI和Meta)都由同一家美国律师事务所提起作为集体诉讼。另一起,Getty Images v. Stability AI,在德拉华州和英国都提起诉讼;两者都集中在Stable Diffusion上,但与其他的案件都不一样。
至少在OSSEU的参与者中,最重要的案例可能是Doe v. GitHub;它针对的是GitHub Copilot工具,这是一个基于人工智能的代码自动补全工具。这个案件不同寻常,因为它被宣传为一起版权诉讼(copyright suit),但没有声称侵犯版权(assert copyright infringement)。在整个诉讼中都没有提到说"你复制了我们的东西"的主张。相反,有指控称GitHub删除了版权信息,因此输出产物是不公平竞争(unfair competition),并且所有的输出都必然是输入的衍生作品。
他说,这个诉讼对"衍生作品(derivative work)"的概念有点粗糙;在法律意义上,这意味着从一个作品中复制了特定的表达到另一个作品中。相反,诉讼主张一切都源自输入,因此一切都是衍生作品。GitHub已经提交了驳回诉讼的动议,部分原因是没有声称侵犯版权;还有其他论点,但并未提到任何跟直接复制有关的。他认为这是因为原告找不到侵权的证据。
第二个案例是Andersen v. Stability AI,他认为该案例在推理中使用了不恰当的类比。该案称AI基于图像创建工具Stable Diffusion "本质上是21世纪的拼贴工具";论点是该模型将一切都分解为像素,然后使用这些像素创建拼贴,因此输出是衍生作品。该案也有一个驳回动议,听起来基本上所有的案件都将被驳回,至少是初步驳回。两名主要原告没有注册其使用的作品的版权,而第三名原告的作品因不符合质量标准而从模型的最新版本中移除了。。
第一个集合中的最后两个案例涉及GPT4和LLaMA模型,它们是基于文本的。在这两个案例中,其中一名主要原告是作家和喜剧演员Sarah Silverman。这些诉讼提出了侵犯版权的主张,但方式有趣,他说。与其展示两个文本,一个受版权保护,一个生成的,然后展示后者从前者复制的地方,这些诉讼采取了不同的路径。
诉状显示,向AI工具请求对Silverman的作品进行摘要的结果是…对她的作品的摘要。这意味着,诉讼辩称,"作品必须在其中某个地方,只是我们不知道如何取出来"。但是,Lindberg注意到,创建摘要是作为对作品的合理使用而受到保护的。在他的分析中,第一个集合中的所有四个案例"都不是好的法律工作";实际上,如果你想保护作者和艺术家,你应该希望这些诉讼被迅速驳回。
他认为,Getty Images的案件更有趣。它们也是侵犯版权的案件,但这些案件发现生成的图像"非常类似"于输入的图像。Stable Diffusion模型还学会了Getty Images的水印是一个重要元素,因此它忠实地复制它们,至少在某种程度上。"它正在创建这些外观糟糕的带有糟糕版本Getty Images水印的照片。"他认为Getty Images最有力的论点是Stable Diffusion在使用水印时侵犯了其商标。"这个论点可能会胜利,但请注意这不是版权的论点。"
Copyrightable?
关于人工智能的另一个有趣问题是,它的输出是否可以受版权保护。尽管英国版权办公室表示这些输出可以受版权保护,但美国版权办公室目前表示它们不能受版权保护。这个美国的裁决是针对Zarya of the Dawn AI绘制的漫画书作出的;它确定了其中的AI创建图像不受版权保护。
Lindberg协助作者Kris Kashtanova创建了一份回应,是针对版权办公室在发现作品是AI生成的之后撤销了先前颁发的版权所进行的回应。版权办公室表示,作者对AI生成的输出没有足够的控制权,也就无权获得版权;需要有大量人类控制输出的工作,才能使其有资格获得版权。Kashtanova决定不对这一判决进行上诉,但Lindberg正在处理另一起类似的案件。
这一裁决还意味着,例如Copilot的输出目前在美国不符合版权保护的条件。他认为版权办公室正在类似摄影版权历史上的情况一样"快速重走一遍老路";最初摄影作品不符合版权保护,然后如果在拍摄照片时进行了足够的工作(例如灯光、服装),那么摄影作品就符合版权保护。最终决定所有摄影作品都符合版权保护,他认为模型输出也会发生同样的情况;我们目前处于"要求得有足够多的人工工作"阶段,但版权办公室也正在就此事寻求意见。
在这个时候,演讲的时间已经不多了。显然,Lindberg还有一些其他他想要提出的话题,但40分钟的时间不足以让他完成。他能够讲到的话题对技术人员和法律领域的人来说都提供了一些有用的信息。
全文完
LWN 文章遵循 CC BY-SA 4.0 许可协议。
欢迎分享、转载及基于现有协议再创作~
长按下面二维码关注,关注 LWN 深度文章以及开源社区的各种新近言论~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









