







图的表示:
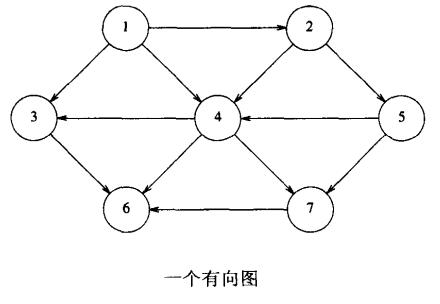
邻接矩阵表示法:
对于上面一个有向图的一种简单的表示方法是使用二维数组,称为邻接矩阵表示法。
如果是无向图,对于每条边(u, v),将二维数组元素arr[u][v]值设置为true;否则该数组元素为false;
如果是有向图,对于每条边(u, v),将二维数组元素arr[u][v]值设置为该边的权重;否则该数组元素设置为一个很大的数值或是一个很小的数组(根据具体情景设置);
虽然邻接矩阵表示法比较简单,但是需要的空间比较大,适合于稠密类型的图。
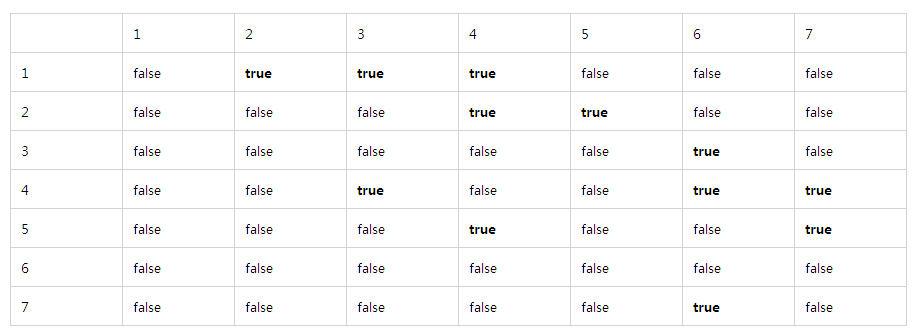
邻接表表示法:
另一种表示方法是使用邻接表表示法,该方法适合于稀疏类型的图。

其实左边的数组也可以不用,如果有需要的话可以加上用来保存各个顶点的信息。一般实现的话根据右边链表数组的顺序就可以知道每个顶点对应的链表。
图中节点的数据结构:
//图节点信息
typedef struct Node{
int edge_num;//边号
int src;//源点
int vertex;//自身
int weight;//边的权重
}Node; 图的邻接表表示法的类接口:
/*******************************************************
* 类名称: 邻接表图
********************************************************/
class Graph{
private:
int edge_num;//图边的个数
int vertex_num;//图的顶点数目
list<Node> * graph_list;//邻接表
public:
Graph(){}
Graph(char* graph[], int edgenum);
~Graph();
void print();//以邻接表的形式打印图信息
private:
vector<int> get_graph_value(char* graph[], int columns);//获得每条边的数据
void addEdge(char* graph[], int columns);
};测试函数:
1、读取图文件中的数据,图中的数据格式为下面所示:
0,0,1,1
1,0,2,2
2,0,3,1
/****************************************************************
* 函数名称:read_file
* 功能描述: 读取文件中的图的数据信息
* 参数列表: buff是将文件读取的图信息保存到buff指向的二维数组中
* spec是文件中图最大允许的边的个数
* filename是要打开的图文件
* 返回结果:无
*****************************************************************/
int read_file(char ** const buff, const unsigned int spec, const char * const filename)
{
FILE *fp = fopen(filename, "r");
if (fp == NULL)
{
printf("Fail to open file %s, %s.\n", filename, strerror(errno));
return 0;
}
printf("Open file %s OK.\n", filename);
char line[MAX_LINE_LEN + 2];
unsigned int cnt = 0;
while ((cnt < spec) && !feof(fp))
{
line[0] = 0;
fgets(line, MAX_LINE_LEN + 2, fp);
if (line[0] == 0) continue;
buff[cnt] = (char *)malloc(MAX_LINE_LEN + 2);
strncpy(buff[cnt], line, MAX_LINE_LEN + 2 - 1);
buff[cnt][4001] = 0;
cnt++;
}
fclose(fp);
printf("There are %d lines in file %s.\n", cnt, filename);
return cnt;
}2、释放刚才读取的文件中的图的数据信息
/****************************************************************
* 函数名称:release_buff
* 功能描述: 释放刚才读取的文件中的图的数据信息
* 参数列表: buff是指向文件读取的图信息
* valid_item_num是指图中边的个数
* 返回结果:void
*****************************************************************/
void release_buff(char ** const buff, const int valid_item_num)
{
for (int i = 0; i < valid_item_num; i++)
free(buff[i]);
}3、主测试函数
int main(int argc, char *argv[])
{
char *topo[5000];
int edge_num;
char *demand;
int demand_num;
char *topo_file = argv[1];
edge_num = read_file(topo, 5000, topo_file);
if (edge_num == 0)
{
printf("Please input valid topo file.\n");
return -1;
}
Graph G(topo, edge_num);//创建一个图对象G
G.print();//以邻接表的形式打印图信息
release_buff(topo, edge_num);
return 0;
}图的邻接表表示法类的源代码:
#ifndef GRAPH_H
#define GRAPH_H
#include <list>
#include <iostream>
#include <vector>
#include <stdlib.h>
#include <string.h>
#include <algorithm>
#include <iterator>
#include <stdio.h>
#include <errno.h>
#include <unistd.h>
#include <signal.h>
using namespace std;
#define MAX_VERTEX_NUM 600
//图节点信息
typedef struct Node{
int edge_num;//边号
int src;//源点
int vertex;//自身
int weight;//边的权重
}Node;
/*******************************************************
* 类名称: 邻接表图
********************************************************/
class Graph{
private:
int edge_num;//图边的个数
int vertex_num;//图的顶点数目
list<Node> * graph_list;//邻接表
public:
Graph(){}
Graph(char* graph[], int edgenum);
~Graph();
void print();//以邻接表的形式打印图信息
private:
vector<int> get_graph_value(char* graph[], int columns);//获得每条边的数据
void addEdge(char* graph[], int columns);
};
/*************************************************
函数名称:print
功能描述:将图的信息以邻接表的形式输出到标准输出
参数列表:无
返回结果:无
*************************************************/
void Graph::print()
{
cout << "******************************************************************" << endl;
//for(int i = 0 ; i < MAX_VERTEX_NUM; ++i){
for(int i = 0 ; i < vertex_num; ++i){
if(graph_list[i].begin() != graph_list[i].end()){
cout << i << "-->";
for(list<Node>::iterator it = graph_list[i].begin(); it != graph_list[i].end(); ++it){
cout << (*it).vertex << "(边号:" << (*it).edge_num << ",权重:" << (*it).weight << ")-->";
}
cout << "NULL" << endl;
}
}
cout << "******************************************************************" << endl;
}
/*************************************************
函数名称:get_graph_value
功能描述:将图的每一条边的信息保存到一个数组中
参数列表: graph:指向图信息的二维数组
columns:图的第几条边
返回结果:无
*************************************************/
vector<int> Graph::get_graph_value(char* graph[], int columns)
{
vector<int> v;
char buff[20];
int i = 0, j = 0, val;
memset(buff, 0, 20);
while((graph[columns][i] != '\n') && (graph[columns][i] != '\0')){
if(graph[columns][i] != ','){
buff[j] = graph[columns][i];
j++;
}
else{
j = 0;
val = atoi(buff);
v.push_back(val);
memset(buff, 0, 20);
}
i++;
}
val = atoi(buff);
v.push_back(val);
return v;
}
/*************************************************
函数名称:addEdge
功能描述:将图的每一条边的信息加入图的邻接表中
参数列表:graph:指向图信息的二维数组
columns:图的第几条边
返回结果:无
*************************************************/
void Graph::addEdge(char* graph[], int columns)
{
Node node;
vector<int> v = get_graph_value(graph, columns);
node.edge_num = v[0];
node.src = v[1];
node.vertex = v[2];
node.weight = v[3];
if(node.vertex > vertex_num)
vertex_num = node.vertex;
//要考虑重复的边,但是边的权重不一样
for(list<Node>::iterator it = graph_list[node.src].begin(); it != graph_list[node.src].end(); ++it){
if((*it).vertex == node.vertex){
if((*it).weight > node.weight){
(*it).weight = node.weight;
}
return;
}
}
graph_list[node.src].push_back(node);
}
/*************************************************
函数名称:构造函数
功能描述:以邻接表的形式保存图的信息,并保存必须经过的顶点
参数列表:graph:指向图信息的二维数组
edgenum:图的边的个数
返回结果:无
*************************************************/
Graph::Graph(char* graph[], int edgenum)
{
edge_num = edgenum;
vertex_num = 0;
graph_list = new list<Node>[MAX_VERTEX_NUM+1];
for(int i = 0; i < edgenum; ++i){
addEdge(graph, i);
}
vertex_num++;
}
/*************************************************
函数名称:析构函数
功能描述:释放动态分配的内存
参数列表:无
返回结果:无
*************************************************/
Graph::~Graph()
{
delete[] graph_list;
}
#endif
测试函数的源代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include <time.h>
#include <sys/timeb.h>
#include <errno.h>
#include <unistd.h>
#include <signal.h>
#include <stdio.h>
#include "graph.h"
#define MAX_LINE_LEN 4000
int read_file(char ** const buff, const unsigned int spec, const char * const filename);
void release_buff(char ** const buff, const int valid_item_num);
int main(int argc, char *argv[])
{
char *topo[5000];
int edge_num;
char *demand;
int demand_num;
char *topo_file = argv[1];
edge_num = read_file(topo, 5000, topo_file);
if (edge_num == 0)
{
printf("Please input valid topo file.\n");
return -1;
}
Graph G(topo, edge_num);//创建一个图对象G
G.print();//以邻接表的形式打印图信息
release_buff(topo, edge_num);
return 0;
}
/****************************************************************
* 函数名称:read_file
* 功能描述: 读取文件中的图的数据信息
* 参数列表: buff是将文件读取的图信息保存到buff指向的二维数组中
* spec是文件中图最大允许的边的个数
* filename是要打开的图文件
* 返回结果:无
*****************************************************************/
int read_file(char ** const buff, const unsigned int spec, const char * const filename)
{
FILE *fp = fopen(filename, "r");
if (fp == NULL)
{
printf("Fail to open file %s, %s.\n", filename, strerror(errno));
return 0;
}
printf("Open file %s OK.\n", filename);
char line[MAX_LINE_LEN + 2];
unsigned int cnt = 0;
while ((cnt < spec) && !feof(fp))
{
line[0] = 0;
fgets(line, MAX_LINE_LEN + 2, fp);
if (line[0] == 0) continue;
buff[cnt] = (char *)malloc(MAX_LINE_LEN + 2);
strncpy(buff[cnt], line, MAX_LINE_LEN + 2 - 1);
buff[cnt][4001] = 0;
cnt++;
}
fclose(fp);
printf("There are %d lines in file %s.\n", cnt, filename);
return cnt;
}
/****************************************************************
* 函数名称:release_buff
* 功能描述: 释放刚才读取的文件中的图的数据信息
* 参数列表: buff是指向文件读取的图信息
* valid_item_num是指图中边的个数
* 返回结果:void
*****************************************************************/
void release_buff(char ** const buff, const int valid_item_num)
{
for (int i = 0; i < valid_item_num; i++)
free(buff[i]);
}
测试用例0:
0,0,1,1
1,0,2,2
2,0,3,1
3,2,1,3
4,3,1,1
5,2,3,1
6,3,2,1
7,3,0,1测试用例1:
0,0,13,15
1,0,8,17
2,0,19,1
3,0,4,8
4,1,0,4
5,2,9,19
6,2,15,8
7,3,0,14
8,3,11,12
9,4,1,15
10,4,5,17
11,5,8,18
12,5,9,14
13,5,6,2
14,6,17,4
15,7,13,1
16,7,16,19
17,8,6,1
18,8,12,17
19,9,14,11
20,10,12,1
21,11,7,12
22,11,4,7
23,12,14,5
24,13,17,12
25,13,4,2
26,14,19,9
27,15,10,14
28,15,18,2
29,16,8,1
30,17,9,14
31,17,19,3
32,17,18,10
33,18,15,8
34,18,3,8
35,19,18,12
36,2,3,20
37,3,5,20
38,5,7,20
39,7,11,20
40,11,13,20
41,17,11,20
42,11,19,20
43,17,5,20
44,5,19,20运行结果:
root@linux_ever:~/linux_ever/algorithm/graph_ch9# ls
case0 case1 graph.h testGraph testGraph.cpp
root@linux_ever:~/linux_ever/algorithm/graph_ch9# ./testGraph ./case0/topo.csv
Open file ./case0/topo.csv OK.
There are 8 lines in file ./case0/topo.csv.
******************************************************************
0-->1(边号:0,权重:1)-->2(边号:1,权重:2)-->3(边号:2,权重:1)-->NULL
2-->1(边号:3,权重:3)-->3(边号:5,权重:1)-->NULL
3-->1(边号:4,权重:1)-->2(边号:6,权重:1)-->0(边号:7,权重:1)-->NULL
******************************************************************
root@linux_ever:~/linux_ever/algorithm/graph_ch9# ./testGraph ./case1/topo.csv
Open file ./case1/topo.csv OK.
There are 45 lines in file ./case1/topo.csv.
******************************************************************
0-->13(边号:0,权重:15)-->8(边号:1,权重:17)-->19(边号:2,权重:1)-->4(边号:3,权重:8)-->NULL
1-->0(边号:4,权重:4)-->NULL
2-->9(边号:5,权重:19)-->15(边号:6,权重:8)-->3(边号:36,权重:20)-->NULL
3-->0(边号:7,权重:14)-->11(边号:8,权重:12)-->5(边号:37,权重:20)-->NULL
4-->1(边号:9,权重:15)-->5(边号:10,权重:17)-->NULL
5-->8(边号:11,权重:18)-->9(边号:12,权重:14)-->6(边号:13,权重:2)-->7(边号:38,权重:20)-->19(边号:44,权重:20)-->NULL
6-->17(边号:14,权重:4)-->NULL
7-->13(边号:15,权重:1)-->16(边号:16,权重:19)-->11(边号:39,权重:20)-->NULL
8-->6(边号:17,权重:1)-->12(边号:18,权重:17)-->NULL
9-->14(边号:19,权重:11)-->NULL
10-->12(边号:20,权重:1)-->NULL
11-->7(边号:21,权重:12)-->4(边号:22,权重:7)-->13(边号:40,权重:20)-->19(边号:42,权重:20)-->NULL
12-->14(边号:23,权重:5)-->NULL
13-->17(边号:24,权重:12)-->4(边号:25,权重:2)-->NULL
14-->19(边号:26,权重:9)-->NULL
15-->10(边号:27,权重:14)-->18(边号:28,权重:2)-->NULL
16-->8(边号:29,权重:1)-->NULL
17-->9(边号:30,权重:14)-->19(边号:31,权重:3)-->18(边号:32,权重:10)-->11(边号:41,权重:20)-->5(边号:43,权重:20)-->NULL
18-->15(边号:33,权重:8)-->3(边号:34,权重:8)-->NULL
19-->18(边号:35,权重:12)-->NULL
******************************************************************
输出结果的每一行的第一列表示各个顶点的标号。
比如:
0-->13(边号:0,权重:15)-->8(边号:1,权重:17)-->19(边号:2,权重:1)-->4(边号:3,权重:8)-->NULL
上面表示,顶点0到13的边的边号为0,权重为15。顶点0到顶点8的边的边号为1,权重为17。顶点0到顶点19的边的边号为2,权重为1。顶点0到顶点4的边的边号为3,权重为8。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









