






摘要
近年来,深度神经网络在工业界和学术界都获得了成功,特别是在计算机视觉任务方面。深度学习的巨大成功主要是由于它的可扩展性,可以对大规模数据进行编码并操纵数十亿的模型参数。然而,在资源有限的设备(如手机和嵌入式设备)上部署这些繁琐的深度模型是一个挑战,这不仅是因为计算复杂度高,而且还需要大量存储。为此,各种模型压缩和加速技术已经被开发出来。作为模型压缩和加速的一个代表类型,知识提炼法可以有效地从一个大的教师模型中学习一个小的学生模型。它已经得到了社会各界快速增长的关注。本文从知识类别、训练方案、师生结构、蒸馏算法、性能比较和应用等方面对知识蒸馏进行了全面的调查。此外,还简要回顾了知识提炼的挑战,并讨论和提出了对未来研究的意见。
一、引言
在过去几年中,深度学习是人工智能领域许多成功的基础,包括计算机视觉(Krizhevsky等人,2012)、强化学习(Silver等人,2016;Ashok等人,2018;Lai等人,2020)和自然语言处理(Devlin等人,2019)的各种应用。在许多最新技术的帮助下,包括残差连接(He等人,2016,2020b)和批量归一化(Ioffe和Szegedy,2015),很容易在强大的GPU或TPU集群上训练具有数千层的非常深的模型。例如,在一个有数百万张图像的流行图像识别基准上训练ResNet模型只需要不到十分钟(Deng等人,2009;Sun等人,2019);训练一个强大的BERT模型用于语言理解不超过一个半小时(Devlin等人,2019;You等人,2019)。大规模的深度模型已经取得了压倒性的成功,然而巨大的计算复杂性和大量的存储需求使其在实时应用中的部署面临巨大挑战,尤其是在资源有限的设备上,如视频监控和自动驾驶汽车。
为了开发高效的深度模型,最近的工作通常侧重于: 1) 深度模型的有效构建块,包括深度可分离卷积,如 MobileNets (Howard et al., 2017; Sandler et al., 2018) 和 ShuffleNets ( Zhang et al., 2018a; Ma et al., 2018); 2)模型压缩和加速技术,分为以下几类(Cheng et al., 2018)。
• 参数修剪和共享:这些方法侧重于从深度神经网络中移除不重要的参数,而不会对性能产生任何显着影响。这一类进一步分为模型量化(Wu et al., 2016)、模型二值化(Courbariaux et al., 2015)、结构矩阵(Sindhwani et al., 2015)和参数共享(Han et al. , 2015; Wang 等人, 2019f).
• 低秩分解:这些方法通过使用矩阵和张量分解来识别深度神经网络的冗余参数(Yu 等人,2017 年;Denton 等人,2014 年)。
• Transferred compact convolutional filters:这些方法通过传输或压缩卷积滤波器来移除不重要的参数(Zhai 等人,2016)。
• 知识蒸馏 (KD):这些方法将知识从更大的深度神经网络中提取到一个小型网络中(Hinton 等人,2015 年)。
对模型压缩和加速的全面回顾超出了本文的范围。本文的重点是知识蒸馏,近年来越来越受到研究界的关注。大型深度神经网络以良好的性能取得了显着的成功,特别是在具有大规模数据的现实场景中,因为在考虑新数据时过度参数化提高了泛化性能(Zhang 等人,2018; Brutzkus 和 Globerson,2019 年;Allen-Zhu 等人,2019 年;Arora 等人,2018 年;Tu 等人,2020 年)。然而,由于设备的计算能力和内存有限,在移动设备和嵌入式系统中部署深度模型是一个巨大的挑战。为了解决这个问题,Bucilua 等人。(2006) 首先提出模型压缩,将信息从大型模型或模型集合转移到训练小型模型中,而不会显着降低准确性。完全监督的教师模型和使用未标记数据的学生模型之间的知识转移也被引入用于半监督学习(Urner 等人,2011)。从大模型中学习小模型后来被正式推广为知识蒸馏(Hinton et al., 2015)。在知识蒸馏中,小学生模型通常由大教师模型监督(Bucilua 等人,2006 年;Ba 和 Caruana,2014 年;Hinton 等人,2015 年;Urban 等人,2017 年)。主要思想是学生模型模仿教师模型以获得竞争性甚至更优的表现。关键问题是如何将知识从大型教师模型迁移到小型学生模型。基本上,知识蒸馏系统由三个关键组件组成:知识、蒸馏算法和师生架构。知识蒸馏的通用师生框架如图1所示。
 尽管在实践中取得了巨大成功,但关于知识蒸馏的理论或实证理解的著作并不多(Urner et al., 2011; Cheng et al., 2020; Phuong and Lampert, 2019a; Cho and Hariharan, 2019).具体来说,Urner 等人。 (2011) 证明了使用未标记数据从教师模型到学生模型的知识转移是 PAC (Probably Approximately Correct)可学习的。为了理解知识蒸馏的工作机制,Phuong 和 Lampert 获得了在深度线性分类器场景中学习蒸馏学生网络快速收敛的泛化边界的理论依据(Phuong 和 Lampert,2019a)。这个理由回答了学生学什么和学多快,并揭示了决定蒸馏成功的因素。成功的蒸馏依赖于数据几何、蒸馏目标的优化偏差和学生分类器的强单调性。程等。
尽管在实践中取得了巨大成功,但关于知识蒸馏的理论或实证理解的著作并不多(Urner et al., 2011; Cheng et al., 2020; Phuong and Lampert, 2019a; Cho and Hariharan, 2019).具体来说,Urner 等人。 (2011) 证明了使用未标记数据从教师模型到学生模型的知识转移是 PAC (Probably Approximately Correct)可学习的。为了理解知识蒸馏的工作机制,Phuong 和 Lampert 获得了在深度线性分类器场景中学习蒸馏学生网络快速收敛的泛化边界的理论依据(Phuong 和 Lampert,2019a)。这个理由回答了学生学什么和学多快,并揭示了决定蒸馏成功的因素。成功的蒸馏依赖于数据几何、蒸馏目标的优化偏差和学生分类器的强单调性。程等。
量化了从深度神经网络的中间层提取视觉概念,以解释知识蒸馏(Cheng 等人,2020)。 Ji & Zhu 从风险界限、数据效率和不完美教师的角度从理论上解释了广义神经网络上的知识蒸馏 (Ji and Zhu., 2020)。Cho 和 Hariharan 根据经验详细分析了知识蒸馏的功效(Cho 和 Hariharan,2019 年)。实证结果表明,由于模型容量差距,更大的模型可能不是更好的教师(Mirzadeh 等人,2020)。实验还表明,蒸馏会对学生的学习产生不利影响。 Cho 和 Hariharan(2019)未涵盖关于知识、蒸馏和师生之间的相互情感的不同形式的知识蒸馏的实证评估。还探索了知识蒸馏以进行标签平滑、评估教师的准确性以及获得最佳输出层几何形状的先验(Tang 等人,2020 年)。
模型压缩的知识蒸馏类似于人类学习的方式。受此启发,最近的知识蒸馏方法已经扩展到师生学习(Hinton et al., 2015)、相互学习(Zhang et al., 2018b)、辅助教学(Mirzadeh et al., 2020)、终身学习 (Zhai et al., 2019) 和自学 (Yuan et al., 2020)。大多数知识蒸馏的扩展都集中在压缩深度神经网络上。由此产生的轻量级学生网络可以轻松部署在视觉识别、语音识别和自然语言处理 (NLP) 等应用程序中。此外,知识蒸馏中从一个模型到另一个模型的知识转移可以扩展到其他任务,例如对抗性攻击(Papernot 等人,2016 年)、数据增强(Lee 等人,2019a;Gordon 和 Duh , 2019), 数据隐私和安全 (Wang et al., 2019a)。受模型压缩知识蒸馏的启发,知识转移的思想进一步应用于压缩训练数据,即数据集蒸馏,它将知识从大数据集中转移到小数据集中,以减少深度模型的训练负荷(Wang等人,2018c;Bohdal 等人,2020 年)。
在本文中,我们对知识蒸馏进行了全面的调查。本次调查的主要目标是:1)概述知识蒸馏,包括几种典型的知识、蒸馏和架构; 2) 回顾知识蒸馏的最新进展,包括算法和在不同现实场景中的应用; 3)解决一些障碍,并根据知识转移的不同角度,包括不同类型的知识、培训方案、蒸馏算法和结构以及应用程序,为知识蒸馏提供见解。最近,也有类似的知识蒸馏调查(Wang and Yoon., 2020),从不同角度呈现了师生视觉学习的综合进展及其挑战。与 (Wang and Yoon., 2020) 不同,我们的调查主要从知识类型、蒸馏方案、蒸馏算法、性能比较和不同应用领域的广泛角度关注知识蒸馏。
本文的组织结构如图 2 所示。
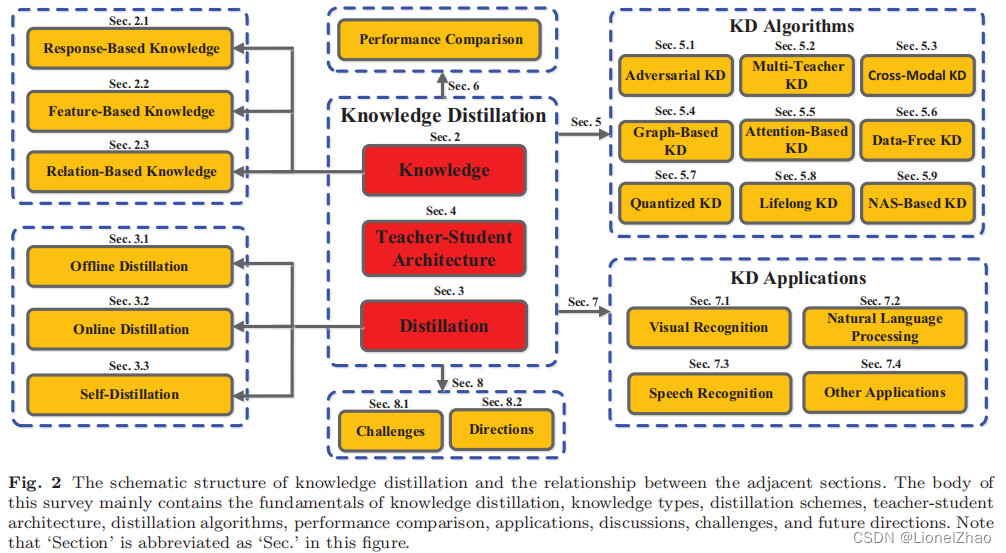
第 2 节和第 3 节分别总结了不同种类的知识和蒸馏。第 4 节阐述了关于知识蒸馏中师生结构的现有研究。第 5 节全面总结了最新的知识蒸馏方法。第 6 节报告了知识蒸馏的性能比较。知识蒸馏的许多应用在第 7 节中进行了说明。第 8 节讨论了知识蒸馏中具有挑战性的问题和未来的方向,并给出了结论
二、知识类型定义
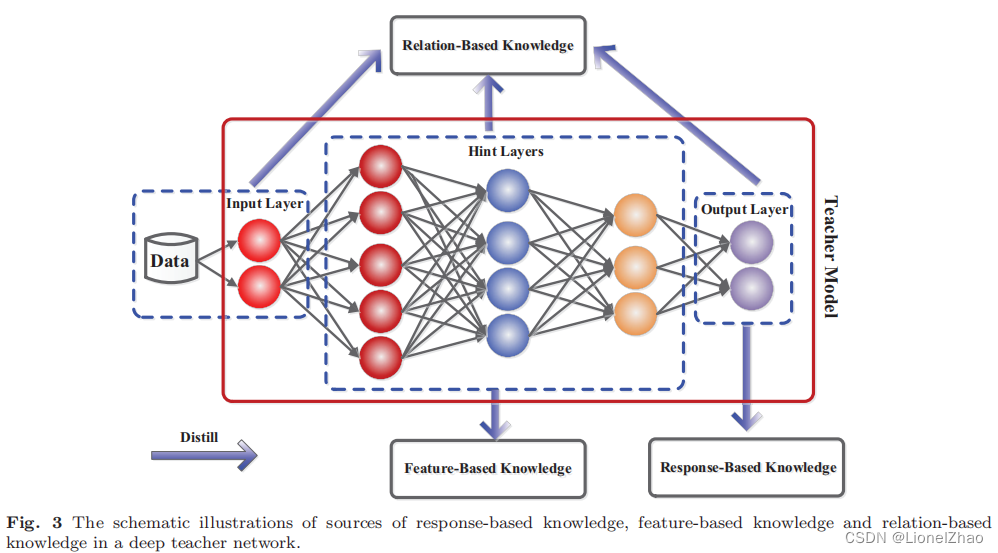
在知识蒸馏中,知识类型、蒸馏策略和师生架构在学生学习中起着至关重要的作用。在本节中,我们将重点关注不同类别的知识以进行知识蒸馏。普通知识蒸馏使用大型深度模型的logits作为教师知识(Hinton 等人,2015 年;Kim 等人,2018 年;Ba 和 Caruana,2014 年;Mirzadeh 等人,2020 年)。中间层的激活、神经元或特征也可以作为知识来指导学生模型的学习(Romero et al., 2015; Huang and Wang, 2017; Ahn et al., 2019; Heo et al., 2019c;Zagoruyko 和Komodakis,2017 年)。不同激活、神经元或样本对之间的关系包含教师模型学到的丰富信息(Yim 等人,2017 年;Lee 和 Song,2019 年;Liu 等人,2019g;Tung 和 Mori,2019 年;Yu 等人,2019 年)。此外,教师模型的参数(或层与层之间的连接)还包含另一个知识(Liu et al., 2019c)。我们在以下类别中讨论不同形式的知识:基于响应的知识、基于特征的知识和基于关系的知识。图 3 显示了教师模型中不同类别知识的直观示例。
 1、基于响应的知识(Response-Based Knowledge)
1、基于响应的知识(Response-Based Knowledge)
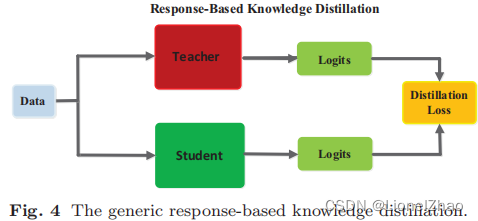
Response-based knowledge通常是指交织模型最后输出层的response。主要思想是直接模仿教师模型的最终预测。基于响应的知识蒸馏简单而有效地用于模型压缩,并已广泛用于不同的任务和应用程序。给定 logits z 向量作为深度模型最后一个完全连接层的输出,基于响应的知识的蒸馏损失可以表示为![]()
其中 LR(.) 表示 logits 的散度损失,zt 和 zs 分别是教师和学生的 logits。典型的基于响应的 KD 模型如图 4 所示。
基于响应的知识可用于不同类型的模型预测。例如,对象检测任务中的响应可能包含 logits 以及边界框的偏移量(Chen 等人,2017)。在语义标定任务中,例如人体姿势估计,教师模型的响应可能包括每个地标的热图(Zhang 等人,2019a)。最近,进一步探索了基于响应的知识,以将地面真值标签的信息作为条件目标来处理(Meng 等人,2019)。
最流行的基于响应的图像分类知识被称为软目标(Hinton 等人,2015 年;Ba 和 Caruana,2014 年)。具体来说,软目标是输入属于类别的概率,可以通过 softmax 函数估计为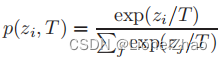
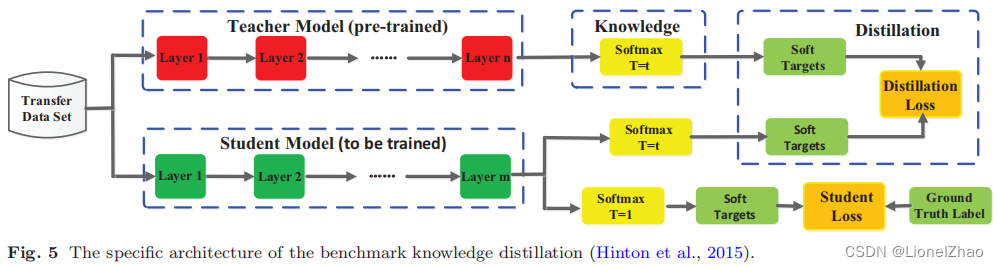
其中zi是第i类的logit,引入一个温度因子T来控制每个软目标的重要性。如 (Hinton et al., 2015) 所述,软目标包含来自教师模型的信息丰富的暗知识。因此,soft logits 的蒸馏损失可以改写为![]() 。通常,LR(p(zt, T), p(zs, T)) 通常采用 Kullback Leibler 散度损失。显然,优化方程式 (1) 或 (3) 可以使学生的 logits zs 与教师的 zt 匹配。为了便于理解基于响应的知识蒸馏,图 5 给出了普通知识蒸馏的基准模型,它结合了蒸馏和学生损失。请注意,学生损失始终定义为交叉熵loss LCE(y, p(zs, T = 1)) 在真实标签和学生模型的软逻辑之间。
。通常,LR(p(zt, T), p(zs, T)) 通常采用 Kullback Leibler 散度损失。显然,优化方程式 (1) 或 (3) 可以使学生的 logits zs 与教师的 zt 匹配。为了便于理解基于响应的知识蒸馏,图 5 给出了普通知识蒸馏的基准模型,它结合了蒸馏和学生损失。请注意,学生损失始终定义为交叉熵loss LCE(y, p(zs, T = 1)) 在真实标签和学生模型的软逻辑之间。
基于响应的知识的思想简单易懂,尤其是在“暗知识”的背景下。从另一个角度来看,软目标的有效性类似于标签平滑 (Kim and Kim, 2017) 或正则化器 (Muller et al., 2019; Ding et al., 2019)。然而,基于响应的知识通常依赖于最后一层的输出,例如软目标,因此无法解决来自教师模型的中间层监督,这对于使用非常深的表示学习非常重要神经网络(Romero 等人,2015 年)。由于软logits实际上是类概率分布,基于响应的知识蒸馏也仅限于监督学习。
2、基于特征的知识(Feature-Based Knowledge)
深度神经网络擅长随着抽象度的增加学习多层次的特征表示。这被称为表征学习(Bengio 等人,2013 年)。因此,最后一层的输出和中间层的输出,即特征图,都可以作为知识来监督学生模型的训练。具体来说,来自中间层的基于特征的知识是基于响应的知识的良好扩展,特别是对于更薄和更深的网络的训练。
中间表示首先在 Fitnets(Romero 等人,2015 年)中引入,以提供提示以改进学生模型的训练。主要思想是直接匹配教师和学生的特征激活。受此启发,提出了多种其他方法来间接匹配特征(Zagoruyko 和 Komodakis,2017 年;Kim 等人,2018 年;Heo 等人,2019c;Passban 等人,2021 年;Chen 等人, 2021 年;Wang 等人,2020b)。具体来说,Zagoruyko 和 Komodakis(2017)从原始特征图派生出一个“注意力图”来表达知识。注意图由 Huang 和 Wang (2017) 使用神经元选择性转移推广。 Passalis 和 Tefas (2018) 通过匹配特征空间中的概率分布来迁移知识。为了更容易转移教师知识,Kim 等人。 (2018) 引入了所谓的“因素”作为一种更易于理解的中间表示形式。为了减少教师和学生之间的表现差距,Jin 等人。 (2019) 提出了路线约束提示学习,它通过教师提示层的输出来监督学生。最近,Heo 等人(2019c) 提出使用隐藏神经元的激活边界进行知识转移。有趣的是,教师模型中间层的参数共享以及基于响应的知识也被用作教师知识(Zhou et al., 2018)。为了匹配老师和学生之间的语义,Chen 等人。 (2021) 提出了跨层知识蒸馏,它通过注意力分配为每个学生层自适应地分配适当的教师层。
通常,基于特征的知识转移的蒸馏损失可以表示为![]()
其中ft(x)和fs(x)分别是教师模型和学生模型中间层的特征图。变换函数 Φt(ft(x)) 和 Φs(fs(x)) 通常在教师和学生模型的特征图形状不同时应用。LF(.)表示用于匹配师生模型特征图的相似度函数。一个通用的基于特征的 KD 模型如图 6 所示。
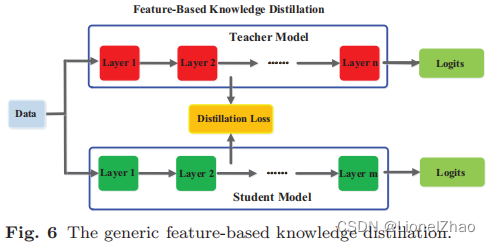
我们还在表 1 中从特征类型、源层和蒸馏损失的角度总结了不同类型的基于特征的知识。具体来说,L2(.)、L1(.)、LCE(.) 和 LMMD(.) 分别表示 l2-范数距离、l1-范数距离、交叉熵损失和最大平均差异损失。虽然基于特征的知识迁移为学生模型的学习提供了有利的信息,但如何有效地从教师模型中选择提示层和从学生模型中选择引导层仍有待进一步研究(Romero 等人,2015)。由于提示层和引导层的大小存在显着差异,因此还需要探索如何正确匹配教师和学生的特征表示。

3、基于连接的知识(Relation-Based Knowledge)
基于响应和基于特征的知识都使用教师模型中特定层的输出。基于关系的知识进一步探索了不同层或数据样本之间的关系。
为了探索不同特征图之间的关系,Yim 等人(2017)提出了解决方案流程(FSP),它由两层之间的 Gram 矩阵定义。 FSP 矩阵总结了特征图对之间的关系。它是使用两层特征之间的内积计算的。利用特征图之间的相关性作为蒸馏知识,提出了通过奇异值分解的知识蒸馏来提取特征图中的关键信息(Lee et al., 2018)。为了使用来自多个教师的知识,Zhang 和 Peng(2018)分别使用每个教师模型的逻辑和特征作为节点形成了两个图。具体来说,不同教师的重要性和关系在知识转移之前通过逻辑和表示图建模(Zhang 和 Peng,2018)。 Lee 和 Song (2019) 提出了基于多头图的知识蒸馏。图知识是通过多头注意力网络的任意两个特征图之间的数据内关系。为了探索成对提示信息,学生模型还模仿来自教师模型的成对提示层的互信息流(Passalis 等人,2020b)。一般来说,基于特征图关系的关系知识的蒸馏损失可以表示为![]()
其中 ft 和 fs 分别是教师和学生模型的特征图。从教师模型 ^ft 和 ˇft 以及学生模型 ^fs 和 ˇfs 中选择特征图对。 Ψt(.) 和 Ψs(.) 是来自教师和学生模型的特征映射对的相似函数。 LR1(.)表示教师特征图和学生特征图之间的相关函数。
传统的知识转移方法往往涉及个人知识的升华。教师的软目标直接蒸馏到学生身上。事实上,蒸馏后的知识不仅包含特征信息,还包含数据样本之间的相互关系(You et al., 2017; Park et al., 2019)。具体来说,刘等人。 (2019g) 通过实例关系图提出了一种稳健有效的知识蒸馏方法。实例关系图中传递的知识包含实例特征、实例关系和特征空间变换跨层。Park等 (2019)提出了一种关系知识蒸馏,它从实例关系中转移知识。基于流形学习的思想,学生网络是通过特征嵌入来学习的,它保留了教师网络中间层样本的特征相似性(Chen et al., 2021)。使用数据的特征表示将数据样本之间的关系建模为概率分布(Passalis 和 Tefas,2018;Passalis 等人,2020a)。教师和学生的概率分布与知识转移相匹配。 (Tung and Mori, 2019) 提出了一种保持相似性的知识蒸馏方法。特别是,由教师网络中输入对的相似激活产生的相似性保持知识被转移到学生网络中,并保留了成对相似性。彭等 (2019a) 提出了一种基于相关一致性的知识蒸馏方法,其中蒸馏出的知识既包含实例级信息,也包含实例之间的相关性。使用相关性同余进行蒸馏,学生网络可以学习实例之间的相关性。
如上所述,基于连接的知识的蒸馏损失可以表示为![]()
其中 (ti , tj ) ∈ Ft 和 (si , sj ) ∈ Fs,Ft 和 Fs 分别是教师和学生模型的特征表示集。 ψt(.) 和 ψs(.) 是 (ti , tj ) 和 (si , sj) 的相似函数。 LR2(.)是教师和学生特征表示之间的相关函数。一个典型的基于实例关系的 KD 模型如图 7 所示。

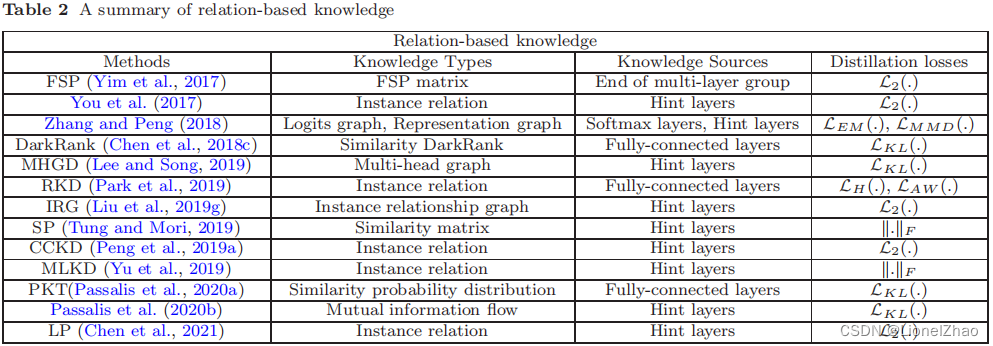
蒸馏知识可以从不同的角度进行分类,例如数据的结构化知识(Liu et al., 2019g; Chen et al., 2021; Peng et al., 2019a; Tung and Mori, 2019; Tian et al. , 2020),关于输入特征的特权信息 (Lopez-Paz et al., 2016; Vapnik and Izmailov, 2015)。基于关系的知识的不同净类别的总结如表 2 所示。具体来说,LEM (.)、LH(.)、LAW (.) 和 k.kF 是 Earth Mover 距离、Huber 损失、Angle-wise 损失和 Frobenius 范数,分别。尽管最近提供了一些类型的基于关系的知识,但是如何将特征图或数据样本中的关系信息建模为知识仍然值得进一步研究。
三、蒸馏策略
在本节中,我们讨论教师和学生模型的蒸馏方案(即训练方案)。根据教师模型是否与学生模型同步更新,知识蒸馏的学习方案可以直接分为三大类:离线蒸馏、在线蒸馏和自蒸馏,如图8所示。
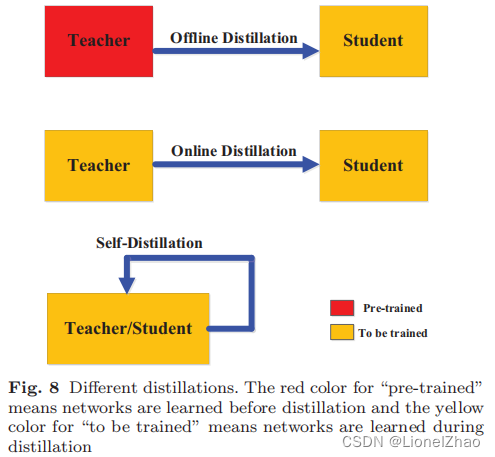
1、离线蒸馏
大多数以前的知识蒸馏方法都是离线工作的。在vanilla knowledge distillation (Hinton et al., 2015) 中,知识从预训练的教师模型转移到学生模型中。因此,整个训练过程分为两个阶段,即: 1)大教师模型首先在一组训练样本上进行训练,然后进行蒸馏; 2)teacher模型用于提取logits或中间特征形式的知识,然后在蒸馏过程中用于指导student模型的训练。
离线蒸馏的第一阶段通常不作为知识蒸馏的一部分进行讨论,即假设教师模型是预定义的。很少关注教师模型结构及其与学生模型的关系。因此,离线方法主要侧重于改进知识迁移的不同部分,包括知识设计(Hinton et al., 2015; Romero et al., 2015)和匹配特征或分布匹配的损失函数(Huang和 Wang,2017 年;Passalis 和 Tefas,2018 年;Zagoruyko 和 Komodakis,2017 年;Mirzadeh 等人,2020 年;Li 等人,2020d;Heo 等人,2019b;Asif 等人,2020 年)。离线方法的主要优点是简单易行。例如,教师模型可能包含一组使用不同软件包训练的模型,这些软件包可能位于不同的机器上。可以提取知识并将其存储在缓存中。
离线蒸馏方法通常采用单向知识转移和两阶段训练过程。然而,复杂的高容量教师模型和巨大的训练时间是无法避免的,而离线蒸馏中学生模型的训练通常在教师模型的指导下是高效的。而且,大老师和小学生之间的能力差距始终存在,学生往往在很大程度上依赖于老师。
2、在线蒸馏
尽管离线蒸馏方法简单有效,但离线蒸馏中的一些问题引起了研究界越来越多的关注(Mirzadeh et al., 2020)。为了克服离线蒸馏的局限性,提出了在线蒸馏以进一步提高学生模型的性能,尤其是在没有大容量高性能教师模型的情况下(Zhang et al., 2018b; Chen et al., 2020a).在线蒸馏中,教师模型和学生模型同时更新,整个知识蒸馏框架是端到端可训练的。
已经提出了多种在线知识蒸馏方法,特别是在过去几年中(Zhang et al., 2018b; Chen et al., 2020a; Xie et al., 2019; Anil et al., 2018; Kim et al. , 2019b;Zhou 等人,2018 年;Walawalkar 等人,2020 年;Wu 和 Gong,2021 年;Zhang 等人,2021a)。具体来说,在深度相互学习中 (Zhang et al., 2018b),多个神经网络以协作的方式工作。在训练过程中,任何一个网络都可以作为学生模型,其他模型可以作为老师。为了提高泛化能力,通过使用软逻辑集成来扩展深度互学习(Guo et al., 2020)。陈等。 (2020a) 进一步将辅助同伴和组长引入深度相互学习中,以形成一组多样化的同伴模型。为了降低计算成本,Zhu 和 Gong(2018)提出了一种多分支架构,其中每个分支表示一个学生模型,不同的分支共享同一个骨干网络。 Kim 等人没有使用 logits 的集合。 (2019b) 引入了一个特征融合模块来构建教师分类器。谢等。 (2019) 用廉价的卷积运算替换了卷积层以形成学生模型。阿尼尔等。 (2018) 采用在线蒸馏来训练大规模分布式神经网络,并提出了一种称为协同蒸馏的在线蒸馏变体。并行共蒸馏训练具有相同架构的多个模型,并且任何一个模型都是通过转移其他模型的知识来训练的。最近,提出了一种在线对抗性知识蒸馏方法,由鉴别器使用来自类别概率和特征图的知识同时训练多个网络(Chung 等人,2020)。最近通过使用 GAN 生成不同的示例来设计对抗性共蒸馏(Zhang 等人,2021a)。
在线蒸馏是一种具有高效并行计算的单阶段端到端训练方案。然而,现有的在线方法(例如,相互学习)通常无法解决在线环境中的高能力教师问题(教师模型的精度往往没有直接训练那样具有高精度而且模型本身并不能像离线蒸馏那样设置的比较大),这使得进一步探索在线环境中师生模型之间的关系成为一个有趣的话题。
3、自蒸馏
在自我蒸馏中,教师和学生模型使用相同的网络(Zhang 等人,2019b;Hou 等人,2019;Zhang 和 Sabuncu,2020;Yang 等人,2019b;Lee 等人, 2019a;Phuong 和 Lampert,2019b;Lan 等人,2018 年;Xu 和 Liu,2019 年;Mobahi 等人,2020 年)。这可以看作是在线蒸馏的一个特例。具体来说,张等人。 (2019b) 提出了一种新的自蒸馏方法,将网络较深部分的知识蒸馏到较浅的部分。与 (Zhang et al., 2019b) 中的自蒸馏类似,提出了一种用于车道检测的自注意蒸馏方法 (Hou et al., 2019)。该网络利用其自身层的注意力图作为其较低层的蒸馏目标。快照蒸馏 (Yang et al., 2019b) 是自蒸馏的一种特殊变体,其中网络(教师)早期阶段的知识被转移到其后期阶段(学生)以支持监督训练同一网络内的进程。为了通过早期退出进一步减少推理时间,Phuong 和 Lampert (2019b) 提出了基于蒸馏的训练方案,其中早期退出层试图在训练期间模仿后期退出层的输出。最近,在 (Mobahi et al., 2020) 中对自蒸馏进行了理论分析,并在 (Zhang and Sabuncu, 2020) 中通过实验证明了其改进的性能。
此外,最近提出了一些有趣的自蒸馏方法(Yuan et al., 2020; Yun et al., 2020; Hahn and Choi, 2019)。具体来说,Yuan 等人。提出了基于标签平滑正则化分析的无教师知识蒸馏方法(Yuan et al., 2020)。 Hahn 和 Choi 提出了一种新的自我知识蒸馏方法,其中自我知识由预测概率而不是传统的软概率组成(Hahn 和 Choi,2019)。这些预测概率由训练模型的特征表示定义。它们反映了特征嵌入空间中数据的相似性。云等。提出了类明智的自我知识蒸馏,以匹配类内样本和同一源内具有相同模型的增强样本之间训练模型的输出分布(Yun 等人,2020)。此外,Lee 等人提出的自蒸馏。(2019a) 被用于数据增强,增强的自我知识被提炼到模型本身。还采用自蒸馏来逐个优化具有相同架构的深度模型(教师或学生网络)(Furlanello 等人,2018 年;Bagherinezhad 等人,2018 年)。每个网络都使用教师学生优化来提炼先前网络的知识。
此外,从人类师生学习的角度,也可以直观地理解线下、线上和自我升华。离线蒸馏意味着知识渊博的老师教给学生知识;线上蒸馏,师生共同学习;自我蒸馏是指学生自己学习知识。而且,就像人类的学习一样,这三种升华可以结合起来,因各自的优势而相互补充。例如,自蒸馏和在线蒸馏都可以通过多知识转移框架适当地集成(Sun 等人,2021)。
四、师生结构
在知识蒸馏中,师生架构是形成知识迁移的通用载体。换句话说,教师到学生的知识获取和蒸馏的质量也取决于如何设计师生网络。就人类的学习习惯而言,我们希望学生能找到合适的老师。因此,要在知识蒸馏中很好地完成对知识的捕获和提取,如何选择或设计合适的师生结构是一个非常重要但又很棘手的问题。最近,teacher 和 student 的模型设置在蒸馏时几乎都是预先固定的,大小和结构不变,很容易造成模型容量差距。然而,如何特别设计教师和学生的体系结构以及为什么他们的体系结构由这些模型设置决定的几乎是缺失的。在本节中,我们将讨论教师模型和学生模型结构之间的关系,如图 9 所示。
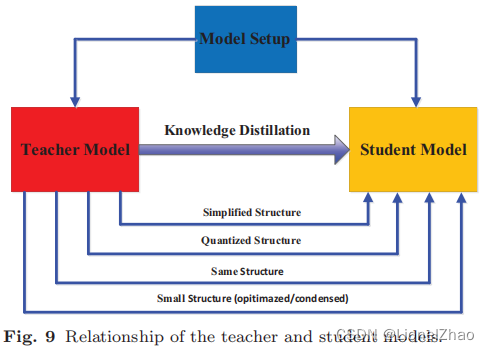
知识蒸馏以前被设计用来压缩深度神经网络的集合 (Hinton et al., 2015)。深度神经网络的复杂性主要来自两个维度:深度和宽度。通常需要将知识从更深更广的神经网络迁移到更浅更薄的神经网络(Romero 等人,2015)。学生网络通常被选择为:1)教师网络的简化版本,层数更少,每层的通道也更少(Wang et al., 2018a; Zhu and Gong, 2018; Li et al., 2020d) ;或 2) 保留网络结构的教师网络的量化版本(Polino 等人,2018 年;Mishra 和 Marr,2018 年;Wei 等人,2018 年;Shin 等人,2019 年);或 3) 具有高效基本操作的小型网络 (Howard et al., 2017; Zhang et al., 2018a; Huang et al., 2017);或 4)具有优化的全球网络结构的小型网络(Liu et al., 2019i; Xie et al., 2020; Gu and Tresp, 2020);或 5) 与老师相同的网络(Zhang 等人,2018b;Furlanello 等人,2018;Tarvainen 和 Valpola,2017)。
大型深度神经网络和小型学生神经网络之间的模型容量差距会降低知识转移的效果(Mirzadeh 等人,2020 年;Gao 等人,2021 年)。为了有效地将知识转移到学生网络,已经提出了多种方法来控制模型复杂性的降低(Zhang et al., 2018b; Nowak and Corso, 2018; Crowley et al., 2018; Liu et al. , 2019a,i;Wang 等人,2018a;Gu 和 Tresp,2020)。具体来说,Mirzadeh 等人 (2020) 引入了一个教师助理来缓解教师模型和学生模型之间的训练差距。残差学习进一步缩小了差距,即使用辅助结构来学习残差(Gao et al., 2021)。另一方面,最近的几种方法也侧重于最小化学生模型和教师模型的结构差异。例如,Polino 等人。 (2018) 将网络量化与知识蒸馏相结合,即学生模型是教师模型的小型量化版本。 Nowak 和 Corso (2018) 提出了一种结构压缩方法,该方法涉及将多层学习的知识转移到单层。王等 (2018a) 在保留感受野的同时,逐步进行从教师网络到学生网络的块级知识转移。在在线环境中,教师网络通常是学生网络的集合,其中学生模型彼此共享相似的结构(或相同的结构)(Zhang 等人,2018b;Zhu 和 Gong,2018;Furlanello 等人, 2018 年;Chen 等人,2020a)。
最近,深度可分离卷积已被广泛用于为移动或嵌入式设备设计高效的神经网络 (Chollet, 2017; Howard et al., 2017; Sandler et al., 2018; Zhang et al., 2018a; Ma等人,2018 年)。受神经架构搜索(或 NAS)成功的启发,通过搜索基于有效元操作或块的全局结构,小型神经网络的性能得到进一步提高(Wu 等人,2019 年;Tan 等人,2019 年)。 ,2019 年;Tan 和 Le,2019 年;Radosavovic 等人,2020 年)。此外,动态搜索知识转移机制的想法也出现在知识蒸馏中,例如,使用强化学习以数据驱动的方式自动删除冗余层(Ashok 等人,2018 年) ),并在给定教师网络的情况下搜索最佳学生网络(Liu 等人,2019i;Xie 等人,2020;Gu 和 Tresp,2020)。
大多数以前的工作都侧重于设计教师和学生模型的结构或它们之间的知识转移方案。为了使小学生模型很好地匹配大教师模型以提高知识蒸馏性能,自适应的师生学习架构是必要的。
最近,知识蒸馏中的神经结构搜索的想法,即在教师模型的指导下联合搜索学生结构和知识转移,将是未来研究的一个有趣主题。
五、蒸馏算法
知识迁移的一个简单但非常有效的想法是直接匹配基于响应的知识、基于特征的知识(Romero et al., 2015; Hinton et al., 2015)或特征空间中的表示分布( Passalis 和 Tefas,2018)在教师模型和学生模型之间。已经提出了许多不同的算法来改进在更复杂的设置中传输知识的过程。在本节中,我们回顾了最近提出的知识蒸馏领域内用于知识转移的典型类型的蒸馏方法。
1、对抗蒸馏
在知识蒸馏中,教师模型很难从真实的数据分布中完美学习。同时,学生模型的容量很小,无法准确模仿教师模型(Mirzadeh et al., 2020)。是否有其他方法可以训练学生模型以模仿教师模型?最近,对抗性学习因其在生成网络(即生成对抗网络或 GAN)中的巨大成功而受到广泛关注(Goodfellow 等人,2014 年)。具体来说,GAN 中的鉴别器估计样本来自训练数据分布的概率,而生成器则试图使用生成的数据样本来欺骗鉴别器。受此启发,许多对抗性知识蒸馏方法被提出,使师生网络能够更好地理解真实的数据分布(Wang et al., 2018e; Xu et al., 2018a; Micaelli and Storkey, 2019;Xu et al., 2018b;Liu et al., 2018;Wang et al., 2018f;Chen et al., 2019a;Shen et al., 2019d;Shu et al., 2019;Liu et al., 2020a ;Belagiannis 等人,2018 年)。
如图 10 所示,基于对抗性学习的蒸馏方法,尤其是那些使用 GAN 的方法,可以分为以下三大类。在第一类中,训练对抗生成器生成合成数据,这些数据要么直接用作训练数据集(Chen et al., 2019a; Ye et al., 2020),要么用于扩充训练数据集(Liu et al., 2018),如图10(a)所示。此外,Micaelli 和 Storkey (2019) 利用对抗生成器生成用于知识转移的硬示例。通常,在这种基于 GAN 的 KD 类别中使用的蒸馏损失可以表示为![]()
其中 Ft(.) 和 Fs(.) 分别是教师和学生模型的输出。 G(z) 表示生成器 G 在给定随机输入向量 z 的情况下生成的训练样本,LG 是一种蒸馏损失,用于强制预测和真实概率分布之间的匹配,例如,交叉熵损失或 Kullback -Leibler (KL) 散度损失。为了使学生与老师匹配,在第二类中引入了一个鉴别器,通过使用逻辑 (Xu et al., 2018a,b) 或特征 (Wang et al., 2018a,b) 来区分来自学生和老师模型的样本。 2018f),如图 10(b)所示。具体来说,Belagiannis 等人。 (2018) 使用未标记的数据样本来形成知识转移。 Shen 等人使用了多个鉴别器。 (2019d)。此外,Shu 等人使用了一种有效的中间监督,即压缩知识。 (2019) 以减轻教师和学生之间的能力差距。 Wang 等人提出的代表性模型。 (2018f) 属于这一类,可以表示为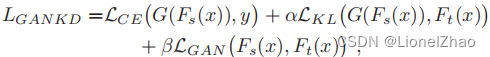
其中 G 是学生网络,LGAN (.) 表示生成对抗网络中使用的典型损失函数,使学生和教师之间的输出尽可能相似。在第三类中,对抗性知识蒸馏以在线方式进行,即教师和学生在每次迭代中共同优化(Wang et al., 2018e; Chung et al., 2020),如图所示在图 10 (c) 中。此外,使用知识蒸馏来压缩 GAN,学习的小型 GAN 学生网络通过知识转移模仿更大的 GAN 教师网络(Aguinaldo 等人,2019 年;Li 等人,2020c)。
综上所述,从上述对抗性蒸馏方法中可以得出以下三个要点: GAN 是通过教师知识迁移来增强学生学习能力的有效工具;联合 GAN 和 KD 可以生成有价值的数据,以提高 KD 性能并克服无法使用和无法访问的数据的局限性; KD 可用于压缩 GAN。
2、多教师蒸馏
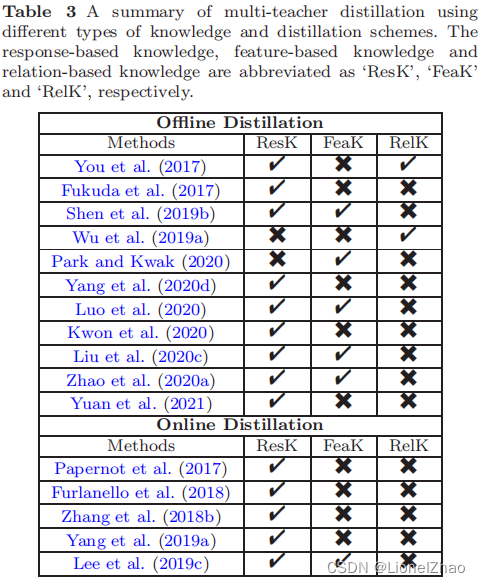
不同的教师架构可以为学生网络提供各自有用的知识。在训练学生网络期间,可以将多个教师网络单独或整体用于蒸馏。在典型的师生框架工作中,教师通常有一个大模型或一个大模型的集合。要从多个教师那里转移知识,最简单的方法是使用所有教师的平均反应作为监督信号(Hinton et al., 2015)。最近提出了几种多教师知识蒸馏方法(Sau 和 Balasubramanian,2016;You 等,2017;Chen 等,2019b;Furlanello 等,2018;Yang 等,2019a;Zhang 等等,2018b;Lee 等,2019c;Park 和 Kwak,2020;Papernot 等,2017;Fukuda 等,2017;Ruder 等,2017;Wu 等,2019a;Yang 等。 , 2020d;Vongkulbhisal 等人,2019 年;Zhao 等人,2020a;Yuan 等人,2021 年)。多教师蒸馏的通用框架如图 11 所示。
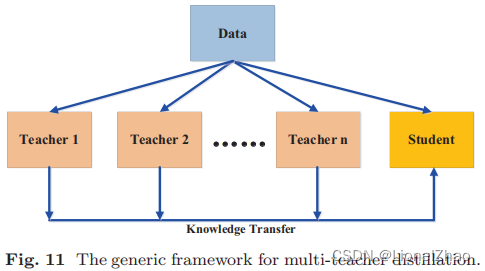
事实证明,多个教师网络对于通常使用逻辑和特征表示作为知识的学生模型的训练是有效的。除了所有教师的平均对数外,You 等人。(2017) 进一步结合了中间层的特征,以鼓励不同训练样本之间的差异。为了同时利用 logits 和中间特征,Chen 等人。 (2019b) 使用了两个教师网络,其中一位教师将基于反应的知识传授给学生,另一位教师将基于特征的知识传授给学生。福田等。 (2017) 在每次迭代时从教师网络池中随机选择一名教师。为了从多个教师那里转移基于特征的知识,将额外的教师分支添加到学生网络中以模仿教师的中间特征(Park 和 Kwak,2020;Asif 等人,2020)。重生网络以逐步的方式处理多个教师,即第 t 步的学生被用作第 t + 1 步学生的教师(Furlanello 等人,2018),类似的想法可以在 (Yang et al., 2019a) 中找到。为了有效地进行知识转移并探索多位教师的力量,已经提出了几种替代方法来模拟多位教师,方法是向给定教师添加不同类型的噪声(Sau 和 Balasubramanian,2016 年)或使用随机噪声块和跳过连接(Lee 等人,2019c)。使用具有特征集成的多个教师模型,设计了知识融合(Shen et al., 2019a; Luo et al., 2019; Shen et al., 2019b; Luo et al., 2020)。通过知识融合,可以重用许多公开可用的训练有素的深度模型作为教师。更有趣的是,由于多教师蒸馏的特殊性,其扩展被用于通过知识适应进行领域适应(Ruder et al., 2017),并保护数据的隐私和安全(Vongkulbhisal et al ., 2019 年;Papernot 等人,2017 年)。
表 3 显示了使用不同类型知识和蒸馏方案的典型多教师蒸馏方法的总结。通常,多教师知识蒸馏可以提供丰富的知识并定制通用的学生模型,因为来自不同类型的知识不同的老师。但是,如何有效整合多位教师的不同类型的知识还需要进一步研究。
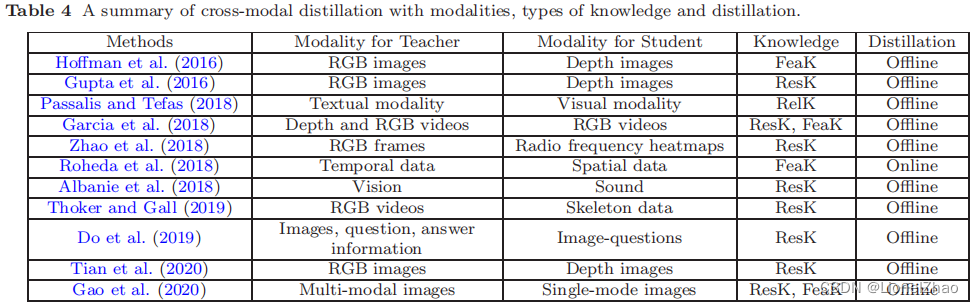
3、跨模式蒸馏
某些模式的数据或标签在训练或测试期间可能不可用(Gupta 等人,2016 年;Garcia 等人,2018 年;Zhao 等人,2018 年;Roheda 等人,2018 年;Zhao 等人,2020b ).出于这个原因,在不同模式之间转移知识很重要。下面回顾几个使用跨模态知识迁移的典型场景。
Gupta 等人给定了一个在一种模态(例如 RGB 图像)上预训练的教师模型,该模型具有大量注释良好的数据样本。 (2016) 将知识从教师模型转移到学生模型,使用新的未标记输入模式,例如深度图像和光流。具体来说,所提出的方法依赖于涉及两种模式的未标记配对样本,即 RGB 和深度图像。教师从 RGB 图像中获得的特征随后用于学生的监督训练(Gupta 等人,2016 年)。配对样本背后的想法是通过成对样本注册来传输注释或标签信息,并已广泛用于跨模态应用(Albanie et al., 2018; Zhao et al., 2018; Thoker and Gall , 2019).为了通过墙壁或遮挡图像执行人体姿势估计,Zhao 等人。 (2018) 使用同步无线电信号和相机图像。知识在基于无线电的人体姿态估计的模态之间传递。 Thoker 和 Gall (2019) 从两种模式中获得了配对样本:RGB 视频和骨架序列。这些对用于将在 RGB 视频上学到的知识转移到基于骨架的人类动作识别模型。为了提高仅使用 RGB 图像的动作识别性能,Garcia 等人。 (2018) 对附加模态(即深度图像)进行交叉模态蒸馏,以生成 RGB 图像模态的幻觉流。田等。 (2020) 引入了对比损失来跨不同模式传递成对关系。为了改进目标检测,Roheda 等人。 (2018) 提出了使用 GAN 在缺失和可用模型之间进行跨模态蒸馏。跨模式蒸馏的通用框架如图 12 所示。
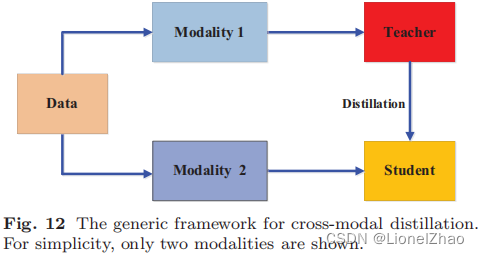
此外,Do 等人。 (2019) 提出了一种基于知识蒸馏的视觉问答方法,其中以图像-问题-答案为输入的三线性交互教师模型的知识被提炼到以图像-问题为输入的双线性交互学生模型的学习中。 Passalis 和 Tefas(2018)提出的概率知识蒸馏也用于从文本模态到视觉模态的知识迁移。霍夫曼等人。(2016) 提出了一种基于跨模态蒸馏的模态幻觉架构,以提高检测性能。此外,这些跨模型蒸馏方法还在多个领域之间传递知识(Kundu et al., 2019; Chen et al., 2019c; Su and Maji, 2017)。
不同模态、知识类型和蒸馏方案的跨模态蒸馏总结如表4所示。具体可以看出,知识蒸馏在跨模态场景下的视觉识别任务中表现良好。然而,当存在模态差距时,跨模态知识转移是一项具有挑战性的研究,例如,不同模态之间缺少配对样本。
4、基于图的蒸馏
大多数知识蒸馏算法侧重于将个体实例知识从教师转移到学生,而最近提出了一些方法来使用图形探索数据内关系(Chen 等人,2021 年;Zhang 和 Peng,2018 年;Lee 和宋,2019;朴等,2019;姚等,2020;马和梅,2019;侯等,2020)。这些基于图的蒸馏方法的主要思想是:1)以图作为教师知识的载体;或2)用图来控制教师知识的消息传递。基于图的蒸馏的通用框架如图 13 所示。如第 2.3 节所述,基于图的知识属于基于关系的知识。在本节中,我们介绍了基于图的知识和基于图的消息传递蒸馏算法的典型定义。

具体来说,在(Zhang 和 Peng,2018)中,每个顶点代表一个自我监督的教师。然后使用 logits 和中间特征构建两个图,即 logits 图和表示图,以将知识从多个自我监督的教师转移到学生。在(Chen et al., 2021)中,图被用来维护高维空间中样本之间的关系。然后使用建议的局部保留损失函数进行知识转移。 Lee 和 Song (2019) 使用多头图分析数据内关系,其中顶点是 CNN 中不同层的特征。Park等(2019) 直接传输数据样本的相互关系,即匹配教师图和学生图之间的边。 Tung 和 Mori (2019) 使用相似矩阵来表示教师和学生模型中输入对激活的相互关系。学生的相似度矩阵与教师的相似度矩阵相匹配。此外,彭等人 (2019a) 不仅匹配了基于响应和基于特征的知识,还使用了基于图的知识。在 (Liu et al., 2019g) 中,实例特征和实例关系分别建模为图的顶点和边。
有几种方法不是使用基于图的知识,而是使用图来控制知识转移。具体来说,罗等人 (2018) 考虑了从源域中合并特权信息的方式差异。引入称为蒸馏图的有向图来探索不同模态之间的关系。每个顶点代表一种模态,边表示一种模态与另一种模态之间的连接强度。南等人。 (2019) 提出了一种基于双向图的多样化协作学习,以探索多样化的知识转移模式。姚等 (2020) 引入了 GNN 来处理基于图的知识的知识转移。此外,使用知识蒸馏,图卷积教师网络的拓扑语义作为拓扑感知知识被转移到图卷积学生网络中(Yang 等人,2020b)基于图的蒸馏可以转移信息结构数据知识。然而,如何正确地构建图来对数据的结构知识进行建模仍然是一个具有挑战性的研究。
5、基于注意力的蒸馏
由于注意力可以很好地反映卷积神经网络的神经元激活,因此在知识蒸馏中使用一些注意力机制来提高学生网络的性能(Zagoruyko and Komodakis, 2017; Huang and Wang, 2017; Srinivas and Fleuret, 2018 年;克劳利等人,2018 年;宋等人,2018 年)。在这些基于注意力的 KD 方法中(Crowley 等人,2018 年;Huang 和 Wang,2017 年;Srinivas 和 Fleuret,2018 年;Zagoruyko 和 Komodakis,2017 年),定义了不同的注意力转移机制,用于将知识从教师网络提炼到学生网络。注意力转移的核心是为神经网络层中的特征嵌入定义注意力图。也就是说,关于特征嵌入的知识是使用注意力图函数来传递的。与注意力图不同,Song 等人提出了一种不同的注意力知识蒸馏方法。 (2018)。注意机制用于分配不同的置信度规则(Song 等人,2018)。
6、无数据蒸馏
已经提出了一些无数据 KD 方法来克服因隐私、合法性、安全性和机密性问题而导致的数据不可用问题(Chen 等人,2019a;Lopes 等人,2017 年;Nayak 等人,2019 年;Micaelli 和 Storkey) ,2019 年;Haroush 等人,2020 年;Ye 等人,2020 年;Nayak 等人,2021 年;Chawla 等人,2021 年)。正如“无数据”所暗示的那样,没有训练数据。相反,数据是新生成的或综合生成的。
具体来说,在(Chen 等人,2019a;Ye 等人,2020;Micaelli 和 Storkey,2019;Yoo 等人,2019;Hu 等人,2020)中,传输数据由 GAN 生成。在提出的无数据知识蒸馏方法(Lopes 等人,2017)中,通过使用教师网络的层激活或层谱激活来重构用于训练学生网络的传输数据。殷等。 (2020) 提出了 DeepInversion,它使用知识蒸馏生成合成图像以进行无数据知识传输。纳亚克等人。(2019) 提出了不使用现有数据的零样本知识蒸馏。传输数据是通过使用教师网络的参数对 softmax 空间建模来生成的。事实上,(Micaelli and Storkey, 2019; Nayak et al., 2019) 中的目标数据是通过使用教师网络的特征表示中的信息生成的。与零样本学习类似,通过将教师模型中的知识提取到学生神经网络中,设计了一种具有少样本学习的知识蒸馏方法(Kimura 等人,2018 年;Shen 等人,2021 年)。教师使用有限的标记数据。此外,还有一种称为数据蒸馏的新型蒸馏,类似于无数据蒸馏(Radosavovic et al., 2018; Liu et al., 2019d; Zhang et al., 2020d)。在数据蒸馏中,使用从教师模型生成的未标记数据的新训练注释来训练学生模型。
总之,无数据蒸馏中的合成数据通常是由预训练教师模型的特征表示生成的,如图 14 所示。尽管无数据蒸馏在以下情况下显示出巨大的潜力在数据不可用的情况下,这仍然是一个非常具有挑战性的任务,即如何生成高质量的多样化训练数据以提高模型的泛化能力。

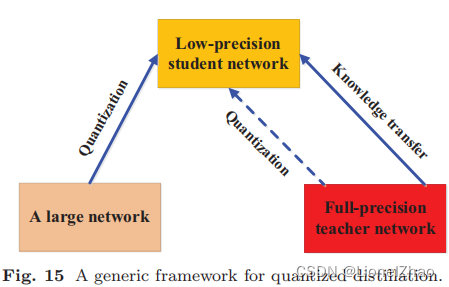
7、量化蒸馏
网络量化通过将高精度网络(例如 32 位浮点)转换为低精度网络(例如 2 位和 8 位)来降低神经网络的计算复杂度。同时,知识蒸馏旨在训练一个小模型以产生与复杂模型相当的性能。
在师生框架中使用量化过程提出了一些 KD 方法 (Polino et al., 2018; Mishra and Marr, 2018; Wei et al., 2018; Shin et al., 2019; Kim et al., 2019a) ).量化蒸馏方法的框架如图 15 所示。
具体来说,Polino 等人 (2018) 提出了一种量化蒸馏方法,将知识转移到权重量化的学生网络。在 (Mishra and Marr, 2018) 中,提出的量化 KD 被称为“学徒”。高精度教师网络将知识传输到小型低精度学生网络。为了确保小型学生网络准确地模仿大型教师网络,全精度教师网络首先在特征图上进行量化,然后将知识从量化教师网络转移到量化学生网络(Wei 等人,2016 年) , 2018).金等人。 (2019a) 提出了量化感知知识蒸馏,它基于量化学生网络的自学和教师和学生网络的知识转移共同研究。此外,Shin 等人。 (2019) 使用蒸馏和量化对深度神经网络进行了实证分析,同时考虑了知识蒸馏的超参数,例如教师网络的大小和蒸馏温度。最近,与上述量化蒸馏方法不同,自蒸馏训练方案旨在提高量化深度模型的性能,其中教师共享学生的模型参数(Boo 等人,2021)。
8、终身蒸馏
终身学习,包括持续学习、持续学习和元学习,旨在以与人类相似的方式学习。它积累了以前学到的知识,并将学到的知识迁移到未来的学习中(Chen 和 Liu,2018)。知识蒸馏提供了一种有效的方法来保存和转移学到的知识,而不会造成灾难性的遗忘。最近,越来越多基于终身学习的 KD 变体被开发出来(Jang et al., 2019; Flennerhag et al., 2019; Peng et al., 2019b; Liu et al., 2019e; Lee 等人,2019b;Zhai 等人,2019 年;Zhou 等人,2020 年;Shmelkov 等人,2017 年;Li 和 Hoiem,2017 年;Caccia 等人,2020 年)。 (Jang et al., 2019; Peng et al., 2019b; Liu et al., 2019e; Flennerhag et al., 2019) 中提出的方法采用元学习。张等人。 (2019) 设计的元传输网络可以确定在师生架构中传输什么以及传输到哪里。 Flennerhag 等人。
(2019) 提出了一个名为 Leap 的轻量级框架,用于通过将环知识从一个学习过程转移到另一个学习过程来对任务流形进行元学习。彭等 (2019b) 为少样本图像识别设计了一种新的知识转移网络架构。该架构同时结合了来自图像和先验知识的视觉信息。刘等人(2019e) 提出了用于图像检索的语义感知知识保存方法。从图像模态和语义信息中获得的教师知识被保存和传输。
此外,为了解决终身学习中的灾难性遗忘问题,全局蒸馏 (Lee et al., 2019b)、基于知识蒸馏的终身 GAN (Zhai et al., 2019)、多模型蒸馏 (Zhou et al., 2020) ) 和其他基于 KD 的方法(Li 和 Hoiem,2017 年;Shmelkov 等人,2017 年)已被开发用于提取学到的知识并教授学生网络处理新任务。
9、基于 NAS 的蒸馏
神经架构搜索 (NAS) 是最流行的自动机器学习(或 AutoML)技术之一,旨在自动识别深度神经模型并自适应地学习适当的深度神经结构。在知识蒸馏中,知识迁移的成功不仅取决于老师的知识,还取决于学生的架构。然而,大教师模型和小学生模型之间可能存在容量差距,使学生很难从老师那里学好。为了解决这个问题,神经架构搜索已被采用以在基于 oracle 的 (Kang et al., 2020) 和架构感知知识蒸馏 (Liu et al., 2019i) 中找到合适的学生架构。此外,知识蒸馏被用来提高神经架构搜索的效率,例如 AdaNAS (Macko et al., 2019)、具有蒸馏架构知识的 NAS (Li et al., 2020a)、教师引导的架构搜索或 TGSA (Bashivan et al., 2019) 和一次性 NAS (Peng et al., 2020)。在 TGSA 中,每个架构搜索步骤都被引导来模仿教师网络的中间特征表示。有效地搜索了学生的可能结构,并且教师有效地监督了特征迁移。
六、性能对比
知识蒸馏是一种出色的模型压缩技术。通过捕获教师知识并在教师学生学习中使用蒸馏策略,它提供了轻量级学生模型的有效性能。最近,许多知识蒸馏方法专注于提高性能,尤其是在图像分类任务中。在本节中,为了清楚地展示知识蒸馏的有效性,我们总结了一些典型的 KD 方法在两个流行的图像分类数据集上的分类性能。这两个数据集是 CIFAR10 和 CIFAR100(Krizhevsky 和 Hinton,2009),分别由 10 类和 100 类的 32×32 RGB 图像组成。两者都有 50000 张训练图像和 10000 张测试图像,并且每个类都有相同数量的训练图像和测试图像。为了公平比较,KD方法的实验分类精度结果(%)直接来自相应的原始论文,如CIFAR10的表5和CIFAR100的表6所示。我们报告了使用不同类型的知识、蒸馏方案和教师/学生模型结构时不同方法的性能。具体来说,括号中的准确率是教师和学生模型的分类结果,它们是单独训练的。需要注意的是,DML (Zhang et al., 2018b)、DCM (Yao and Sun, 2020) 和 KDCL (Guo et al., 2020) 的准确率对是在线蒸馏后教师和学生的表现。
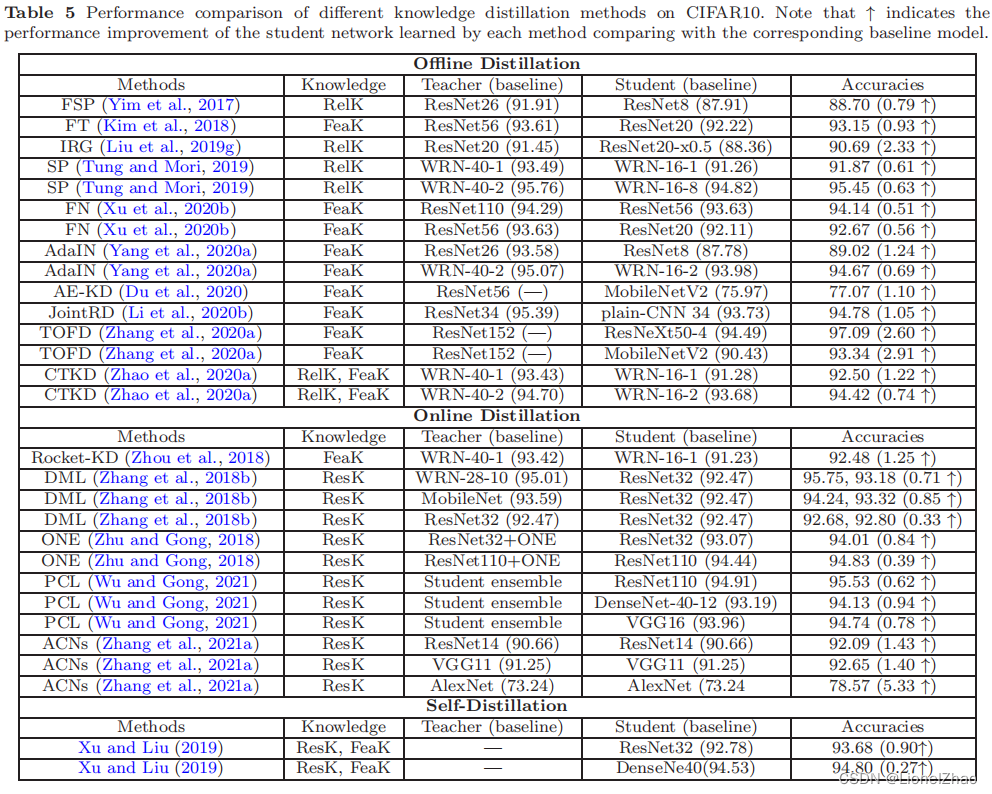

从表 5 和表 6 中的性能比较,可以总结出几个观察结果: • 可以在不同的深度模型上实现知识蒸馏。
• 不同深度模型的模型压缩可以通过知识蒸馏来实现。
• 通过协作学习进行在线知识提炼(Zhang et al., 2018b; Yao and Sun, 2020)可以显着提高深度模型的性能。
• 自我知识蒸馏(Yang et al., 2019b; Yuan et al., 2020; Xu and Liu, 2019; Yun et al., 2020)可以很好地提高深度模型的性能。
• 离线和在线蒸馏方法通常分别传输基于特征的知识和基于响应的知识。
• 轻量级深度模型(学生)的性能可以通过高容量教师模型的知识转移来提高。
通过对不同知识蒸馏方法的性能比较,可以很容易地得出结论,知识蒸馏是一种有效且高效的深度模型压缩技术。
七、应用
作为深度神经网络压缩和加速的有效技术,知识蒸馏已广泛应用于人工智能的不同领域,包括视觉识别、语音识别、自然语言处理(NLP)和推荐系统。此外,知识蒸馏还可以用于其他目的,例如数据隐私和防御对抗性攻击。本节简要回顾知识蒸馏的应用。
1、视觉识别
在过去的几年中,各种知识蒸馏方法已被广泛用于不同视觉识别应用中的模型压缩。具体来说,大多数知识蒸馏方法之前都是为图像分类开发的(Li 和 Hoiem,2017;Peng 等,2019b;Bagherinezhad 等,2018;Chen 等,2018a;Wang 等,2019b) ; Mukherjee et al., 2019; Zhu et al., 2019)然后扩展到其他视觉识别应用,包括人脸识别(Luo et al., 2016; Kong et al., 2019; Yan et al., 2019 ; Ge et al., 2018; Wang et al., 2018b, 2019c; Duong et al., 2019; Wu et al., 2020; Wang et al., 2017; Zhang et al., 2020b; Wang et al., 2020b),图像/视频分割(He et al., 2019; Mullapudi et al., 2019; Dou et al., 2020; Liu et al., 2019h; Siam et al., 2019; Hou et al., 2020; Bergmann 等人,2020),动作识别(Luo 等人,2018;Hao 和 Zhang,2019;Thoker 和 Gall,2019;Garcia 等人,2018;Wang 等人,2019e;Wu 等人,2019b) ; Zhang et al., 2020c; Cui et al., 2020), object detection (Li et al., 2017; Shmelkov et al., 2017; Cun and Pun, 2020; Wang et al., 2019d; Huang et al. ., 2020;魏等,2018;洪与于,2019; Chawla et al., 2021)、车道检测(Hou et al., 2019)、行人重识别(Wu et al., 2019a)、行人检测(Shen et al., 2016)、面部标志检测(Dong and Yang , 2019), pose estimation (Nie et al., 2019; Zhang et al., 2019a; Zhao et al., 2018), video captioning (Pan et al., 2020; Zhang et al., 2020f), person search ( Munjal 等人,2019;Zhang 等人,2021c),图像检索(Liu 等人,2019e),阴影检测(Chen 等人,2020c),显着性估计(Li 等人,2019),深度估计(Pilzer 等人,2019 年;Ye 等人,2019 年)、视觉里程计(Saputra 等人,2019 年)、文本到图像合成(Yuan 和 Peng,2020 年;Tan 等人,2021 年)、视频分类(Zhang 和 Peng,2018 年;Bhardwaj 等人,2019 年)、视觉问答(Mun 等人,2018 年;Aditya 等人,2019 年)和异常检测(Bergmann 等人,2020 年)。由于分类任务中的知识蒸馏是其他任务的基础,我们简要回顾了具有挑战性的图像分类设置(例如人脸识别和动作识别)中的知识蒸馏。
现有的基于 KD 的人脸识别方法不仅注重高效部署,还注重具有竞争力的识别精度 (Luo et al., 2016; Kong et al., 2019; Yan et al., 2019; Ge et al., 2018; Wang等,2018b、2019c;Duong 等,2019;Wang 等,2017、2020b;Zhang 等,2020b)。具体来说,在 (Luo et al., 2016) 中,来自教师网络顶层提示层的选定信息神经元的知识被转移到学生网络中。为知识转移设计了一种丢失提示层特征表示的教师加权策略,以避免教师的错误监督(Wang 等人,2018b)。通过使用以前的学生网络来初始化下一个学生网络,设计了一种递归知识蒸馏方法(Yan et al., 2019)。由于大多数人脸识别方法执行开放集识别,即测试集上的类/身份对于训练集是未知的,人脸识别标准通常是正样本和负样本的特征表示之间的距离度量,例如,角度损失in (Duong et al., 2019) 和相关的嵌入损失 (Wu et al., 2020)。
为了提高低分辨率人脸识别的准确性,知识蒸馏框架是通过使用高分辨率人脸教师和低分辨率人脸学生之间的架构开发的,用于模型加速和改进的分类性能(Ge et al., 2018; Wang et al ., 2019c;Kong 等人,2019 年;Ge 等人,2020 年)。具体来说,Ge 等人。 (2018) 提出了一种选择性知识蒸馏方法,其中用于高分辨率人脸识别的教师网络通过稀疏图优化将其信息丰富的面部特征选择性地传输到用于低分辨率人脸识别的学生网络中。在 (Kong et al., 2019) 中,跨分辨率人脸识别是通过设计一个统一人脸幻觉和异构识别子网的分辨率不变模型实现的。为了获得高效且有效的低分辨率人脸识别模型,采用学生和教师网络之间的多核最大平均差异作为特征损失(Wang 等人,2019c)。此外,基于 KD 的人脸识别可以通过改变知识蒸馏中的损失扩展到人脸对齐和验证(Wang et al., 2017)。
最近,知识蒸馏已成功用于解决复杂的图像分类问题(Zhu et al., 2019; Bagherinezhad et al., 2018; Peng et al., 2019b; Li and Hoiem, 2017; Chen et al., 2018a;Wang 等人,2019b;Mukherjee 等人,2019)。对于不完整、模糊和冗余的图像标签,提出了通过自蒸馏和标签级数的标签精炼模型来学习用于复杂图像分类的软的、信息丰富的、集体的和动态的标签(Bagherinezhad 等人,2018 年)。为了解决 CNN 在各种图像分类任务中的灾难性遗忘问题,提出了一种 CNN 的无遗忘学习方法,包括知识蒸馏和终身学习,以识别新的图像任务并保留原始任务(Li 和霍伊姆,2017 年)。为了提高图像分类的准确性,Chen 等人。 (2018a) 提出了基于特征图的 GAN 知识蒸馏方法。它将知识从特征图转移给学生。使用知识蒸馏,为图像分类器设计了一个视觉解释和诊断框架,该框架统一了用于解释的师生模型和用于诊断的深度生成模型(Wang 等人,2019b)。类似于基于 KD 的低分辨率人脸识别,Zhu 等人。 (2019) 提出了用于低分辨率图像分类的深度特征蒸馏,其中学生的输出特征与教师的输出特征相匹配。
如第 5.3 节所述,师生结构的知识蒸馏可以迁移和保存跨模态知识。可以成功实现其跨模态任务场景下高效有效的动作识别(Thoker 和 Gall,2019;Luo 等,2018;Garcia 等,2018;Hao 和 Zhang,2019;Wu 等,2019b;张等人,2020c)。这些方法是时空模态蒸馏的示例,具有用于动作识别的不同知识转移。示例包括相互师生网络(Thoker 和 Gall,2019)、多流网络(Garcia 等,2018)、时空蒸馏密集连接网络(Hao 和 Zhang,2019)、图蒸馏(Luo 等,2018) ) 和多教师到多学生网络 (Wu et al., 2019b; Zhang et al., 2020c)。在这些方法中,轻量级学生可以从教师存储的多种模态中提取和共享知识信息。
我们总结了基于蒸馏的视觉识别应用的两个主要观察结果,如下所示。
• 知识蒸馏为各种不同的视觉识别任务提供高效且有效的师生学习,因为轻量级学生网络可以在高容量教师网络的指导下轻松训练。
• 由于灵活的师生架构和知识迁移,知识蒸馏可以充分利用复杂数据源中不同类型的知识,例如跨模态数据、多领域数据和多任务数据以及低分辨率数据.
2、NLP
BERT等传统语言模型结构复杂繁琐,非常耗时耗资源。知识蒸馏在自然语言处理(NLP)领域得到广泛研究,以获得轻量级、高效和有效的语言模型。越来越多的 KD 方法被提出来解决众多的 NLP 任务(Liu et al., 2019b; Gordon and Duh, 2019; Haidar and Rezagholizadeh, 2019; Yang et al., 2020d; Tang et al., 2019; Hu等人,2018 年;Sun 等人,2019 年;Nakashole 和 Flauger,2017 年;Jiao 等人,2020 年;Wang 等人,2018d;Zhou 等人,2019a;Sanh 等人,2019 年;Turc 等人., 2019;Arora 等,2019;Clark 等,2019;Kim 和 Rush,2016;Mou 等,2016;Liu 等,2019f;Hahn 和 Choi,2019;Tan 等,2019 ;Kuncoro 等人,2016 年;Cui 等人,2017 年;Wei 等人,2019 年;Freitag 等人,2017 年;Shakeri 等人,2019 年;Aguilar 等人,2020 年;Fu 等人,2021 年; Yang 等人,2020d;Zhang 等人,2021b;Chen 等人,2020b;Wang 和 Du,2021)。使用 KD 的现有 NLP 任务包含神经机器翻译 (NMT)(Hahn 和 Choi,2019;Zhou 等人,2019a;Li 等人,2021;Kim 和 Rush,2016;Gordon 和 Duh,2019;Tan 等人。 , 2019;Wei 等,2019;Freitag 等,2017;Zhang 等,2021b),文本生成(Chen 等,2020b;Haidar 和 Rezagholizadeh,2019),问答系统(Hu 等,2019)。 , 2018; Wang et al., 2018d; Arora et al., 2019; Yang et al., 2020d), 事件检测 (Liu et al., 2019b), 文档检索 (Shakeri et al., 2019), 文本识别 (王和杜,2021)等。在这些基于 KD 的 NLP 方法中,大多数属于自然语言理解(NLU),而这些 NLU 的 KD 方法中有许多被设计为任务特定的蒸馏(Tang et al., 2019; Turc et al., 2019) ; Mou 等人,2016 年)和多任务蒸馏(Liu 等人,2019f;Yang 等人,2020d;Sanh 等人,2019;Clark 等人,2019)。在下文中,我们描述了 KD 的神经机器翻译研究工作,然后在 NLU 中扩展了一个典型的多语言表示模型,该模型名为双向编码器表示来自 transformers(或 BERT)(Devlin 等人,2019 年)。
在自然语言处理中,神经机器翻译是最热门的应用。然而,现有的具有竞争性能的 NMT 模型非常多。为了获得轻量级的 NMT,有许多用于神经机器翻译的扩展知识蒸馏方法 (Hahn and Choi, 2019; Zhou et al., 2019a; Kim and Rush, 2016; Gordon and Duh, 2019; Wei et al., 2019) ;Freitag 等人,2017 年;Tan 等人,2019 年)。最近,周等人。 (2019a) 凭经验证明了基于 KD 的非自回归机器翻译 (NAT) 模型的更好性能在很大程度上取决于其容量和通过知识转移提取的数据。Gordon and Duh (2019) 从数据增强和正则化的角度解释了序列级知识蒸馏的良好性能。在 (Kim and Rush, 2016) 中,有效的词级知识蒸馏被扩展到 NMT 序列生成场景中的序列级一级。
序列生成学生模型模仿教师的序列分布。为了克服多语言多样性,Tan 等人。 (2019) 提出了多教师蒸馏,其中处理双语对的多个个体模型是教师,多语言模型是学生。为了提高翻译质量,多个 NMT 模型的集成作为教师使用数据过滤方法监督学生模型 Freitag 等人。 (2017)。为了提高机器翻译和机器阅读任务的性能,(Wei et al., 2019) 提出了一种新的在线知识蒸馏方法,它解决了训练过程的不稳定性和每个验证集上性能下降的问题。在此在线 KD 中,训练期间评估最佳的模型被选为教师,并由任何后续更好的模型进行更新。如果下一个模型表现不佳,则当前的教师模型将对其进行指导。
BERT 作为一种多语言表示模型,在自然语言理解方面备受关注(Devlin et al., 2019),但它也是一些不易部署的深度模型的累赘。为了解决这个问题,提出了几种使用知识蒸馏的 BERT 轻量级变体(称为 BERT 模型压缩)(Sun 等人,2019 年;Jiao 等人,2020 年;Tang 等人,2019 年;Sanh 等人,2019 年; Wang et al., 2020a; Liu et al., 2020b; Fu et al., 2021)。
孙等。 (2019) 提出了用于 BERT 模型压缩 (BERT-PKD) 的患者知识蒸馏,用于情感分类、释义相似性匹配、自然语言推理和机器阅读理解。在 patient KD 方法中,来自 teacher 提示层的 [CLS] token 的特征表示被转移到 student。为了加速语言推理,Jiao 等人。 (2020) 提出了 TinyBERT,即两阶段变压器知识蒸馏。它包含一般领域和特定任务的知识蒸馏。对于句子分类和匹配,Tang 等人。 (2019) 提出了从 BERT 教师模型到双向长短期记忆网络 (BiLSTM) 的特定任务知识提炼。在 (Sanh et al., 2019) 中,设计了一个名为 DistilBERT 的轻量级学生模型,该模型具有与 BERT 相同的通用结构,并在 NLP 的各种任务上进行了学习。在 (Aguilar et al., 2020) 中,通过内部蒸馏使用大型教师 BERT 的内部表示,提出了一个简化的学生 BERT。
此外,下面展示了一些具有不同视角的典型 NLP KD 方法。对于问答,为了提高机器阅读理解的效率和鲁棒性,Hu 等人。(2018)提出了一种注意力引导的答案蒸馏方法,该方法融合了通用蒸馏和答案蒸馏以避免混淆答案。对于任务特定的蒸馏(Turc 等人,2019),研究了知识蒸馏的性能以及紧凑学生模型的预训练、蒸馏和微调之间的相互作用。所提出的预训练蒸馏在情感分类、自然语言推理、文本蕴含方面表现良好。
对于自然语言理解背景下的多任务蒸馏,Clark 等人。 (2019) 提出了基于重生神经网络的单多重生蒸馏 (Furlanello et al., 2018)。单一任务的教师教一个多任务的学生。对于多语言表示,知识蒸馏在双语词典归纳的多语言词嵌入之间转移知识(Nakashole 和 Flauger,2017)。对于低资源语言,知识转移在多语言模型的集合中是有效的(Cui et al., 2017)。
关于自然语言处理的知识蒸馏的几个观察总结如下。
• 知识蒸馏提供高效且有效的轻量级语言深度模型。大容量教师模型可以从大量不同种类的语言数据中迁移丰富的知识来训练一个小型学生模型,使学生能够快速高效地完成许多语言任务。
• 考虑到来自多语言模型的知识可以相互转移和共享,师生知识转移可以轻松有效地解决许多多语言任务。
• 在深度语言模型中,序列知识可以有效地从大型网络转移到小型网络中。
3、语音识别
在语音识别领域,深度神经声学模型以其强大的性能引起了人们的关注和兴趣。然而,越来越多的实时语音识别系统部署在计算资源有限且响应时间快的嵌入式平台上。最先进的深度复杂模型无法满足此类语音识别场景的要求。为了满足这些要求,知识蒸馏被广泛研究并应用于许多语音识别任务。有许多用于设计用于语音识别的轻量级深度声学模型的知识蒸馏系统(Chebotar 和 Waters,2016 年;Wong 和 Gales,2016 年;Chan 等人,2015 年;Price 等人,2016 年;Fukuda 等人,2017 年;Bai等,2019;Ng 等,2018;Albanie 等,2018;Lu 等,2017;Shi 等,2019a;Roheda 等,2018;Shi 等,2019b;Gao 等al.,2019;Ghorbani 等,2018;Takashima 等,2018;Watanabe 等,2017;Shi 等,2019c;Asami 等,2017;Huang 等,2018;Shen 等., 2018 年;Perez 等人,2020 年;Shen 等人,2019c;Oord 等人,2018 年;Kwon 等人,2020 年;Shen 等人,2020 年)。特别是,这些基于 KD 的语音识别应用具有口语识别(Shen et al., 2018, 2019c, 2020)、音频分类(Gao et al., 2019; Perez et al., 2020)、文本独立说话人识别(Ng et al., 2018)、语音增强 (Watanabe et al., 2017)、声学事件检测 (Price et al., 2016; Shi et al., 2019a,b)、语音合成 (Oord et al., 2018) ) 等等。
大多数现有的语音识别知识蒸馏方法,使用师生架构来提高声学模型的效率和识别准确性(Chan et al., 2015; Watanabe et al., 2017; Chebotar and Waters, 2016; Shen et al., 2019c;Lu et al., 2017;Shen et al., 2018, 2020;Gao et al., 2019;Shi et al., 2019c,a;Perez et al., 2020)。使用递归神经网络 (RNN) 来保存来自语音序列的时间信息,来自教师 RNN 声学模型的知识被转移到一个小型学生 DNN 模型中(Chan 等人,2015 年)。通过组合多种声学模式获得更好的语音识别准确度。具有不同个体训练标准的不同 RNN 的集合旨在通过知识转移来训练学生模型(Chebotar 和 Waters,2016)。学习的学生模型在 5 种语言的 2,000 小时大词汇量连续语音识别 (LVCSR) 任务中表现良好。为了加强口语识别 (LID) 模型对短话语的泛化,将基于长话语的教师网络的特征表示知识转移到基于短话语的学生网络中,该网络可以区分短话语并在基于短时间话语的 LID 任务 (Shen et al., 2018)。为了进一步提高基于短话语的 LID 的性能,提出了一种交互式师生在线蒸馏学习来增强短话语特征表示的性能(Shen 等人,2019c)。通过将教师对较长话语的内部表征知识提取到学生对短话语的表征知识中,也可以提高 LID 在短话语上的表现(Shen et al., 2020)。
同时,对于音频分类,开发了一种多级特征蒸馏方法,并采用对抗性学习策略来优化知识迁移(Gao et al., 2019)。为了提高噪声鲁棒性语音识别,知识蒸馏被用作语音增强的工具(Watanabe 等人,2017)。在 (Perez et al., 2020) 中,提出了一种视听多模态知识蒸馏方法。知识从关于视觉和听觉数据的教师模型转移到关于音频数据的学生模型。从本质上讲,这种蒸馏在教师和学生之间共享跨模态知识(Perez 等人,2020 年;Albanie 等人,2018 年;Roheda 等人,2018 年)。为了进行有效的声学事件检测,提出了一种同时使用知识蒸馏和量化的量化蒸馏方法(Shi 等人,2019a)。量化蒸馏将知识从具有更好检测精度的大型 CNN 教师模型转移到量化的 RNN 学生模型中。
与大多数现有的传统帧级 KD 方法不同,序列级 KD 在某些语音识别序列模型中表现更好,例如连接时间分类 (CTC) (Wong and Gales, 2016; Takashima et al., 2018; Huang等人,2018 年)。在 (Huang et al., 2018) 中,序列级 KD 被引入到联结时间分类中,以匹配教师模型训练中使用的输出标签序列和蒸馏中使用的输入语音帧。在 (Wong and Gales, 2016) 中,研究了语音识别性能对帧级和序列级师生训练的影响,并提出了一种新的序列级师生训练方法。 teacher ensemble 是通过使用序列级组合而不是帧级组合来构建的。为了提高基于单向 RNN 的 CTC 的实时语音识别性能,基于双向 LSTM 的 CTC 教师模型的知识通过帧级 KD 和序列级 KD(高岛等人,2018 年)。
此外,知识蒸馏可用于解决语音识别中的一些特殊问题(Bai et al., 2019; Asami et al., 2017; Ghorbani et al., 2018)。为了克服数据稀缺时 DNN 声学模型的过度拟合问题,知识蒸馏被用作一种正则化方式,在源模型的监督下训练自适应模型(Asami 等人,2017)。最终的自适应模型在三个真实声学域上取得了更好的性能。为了克服非母语语音识别性能的下降,通过从多个特定口音的 RNN-CTC 模型中提取知识来训练高级多口音学生模型(Ghorbani 等人,2018 年)。本质上,(Asami et al., 2017; Ghorbani et al., 2018) 中的知识蒸馏实现了跨领域的知识转移。为了解决将外部语言模型(LM)融合到序列到序列模型(Seq2seq)以进行语音识别的复杂性,采用知识蒸馏作为将LM(教师)集成到Seq2seq模型(学生)的有效工具(Bai 等人,2019 年)。经过训练的 Seq2seq 模型可以降低序列到序列语音识别中的字符错误率。
总之,对基于知识蒸馏的语音识别的几个观察可以总结如下。
• 轻量级学生模型可以满足语音识别的实时响应、有限资源利用和高识别准确率等实际需求。
• 由于语音序列的时间属性,许多师生架构都建立在RNN 模型之上。一般来说,RNN 模型被选为教师,它可以很好地保存时间知识并将其从真实声学数据转移到学生模型。
• 序列级知识蒸馏可以很好地应用于性能良好的序列模型。
事实上,帧级 KD 总是使用基于响应的知识,而序列级 KD 通常从教师模型的提示层迁移基于特征的知识。
• 使用师生知识迁移的知识蒸馏可以轻松解决多口音和多语言语音识别等应用中的跨域或跨模态语音识别。
4、其他应用
充分和正确地利用外部知识,例如用户评论或图像,对深度推荐模型的有效性起着非常重要的作用。降低深度推荐模型的复杂度并提高效率也是非常必要的。最近,知识蒸馏已成功应用于深度模型压缩和加速的推荐系统(Chen et al., 2018b; Tang and Wang, 2018; Pan et al., 2019)。在(Tang 和 Wang,2018)中,知识蒸馏首先被引入推荐系统并称为排名蒸馏,因为推荐被表示为排名问题。陈等。 (2018b) 提出了一种用于有效推荐的对抗性知识蒸馏方法。教师作为正确的评论预测网络监督学生作为用户项目预测网络(生成器)。学生的学习是通过师生网络之间的对抗性适应来调整的。与 (Chen et al., 2018b; Tang and Wang, 2018) 中的蒸馏不同,Pan 等人。
(2019) 通过知识蒸馏为推荐系统设计了一个增强的协同降噪自动编码器 (ECAE) 模型,以从用户反馈中捕获有用的知识并减少噪音。统一的 ECAE 框架包含一个生成网络、一个再训练网络和一个蒸馏层,用于传输知识并减少来自生成网络的噪声。
利用知识蒸馏与师生架构的自然特性,知识蒸馏被用作解决深度模型的对抗性攻击或扰动的有效策略(Papernot 等人,2016 年;Ross 和 Doshi-Velez,2018 年;Goldblum 等人al., 2020; Gil et al., 2019) 以及由于隐私、保密和安全问题导致的数据不可用问题 (Lopes et al., 2017; Papernot et al., 2017; Wang et al., 2019a;Bai 等人,2020 年;Vongkulbhisal 等人,2019 年)。具体而言,教师网络的强大输出可以通过蒸馏来克服对抗样本的扰动(Ross and Doshi-Velez, 2018; Papernot et al., 2016)。为了避免泄露私人数据,多名教师访问敏感或未标记数据的子集并监督学生(Papernot 等人,2017 年;Vongkulbhisal 等人,2019 年)。为了解决隐私和安全问题,训练学生网络的数据是通过无数据蒸馏使用教师网络的层激活或层谱激活生成的(Lopes 等人,2017)。为了保护数据隐私和防止知识产权盗版,Wang 等人。 (2019a) 通过知识蒸馏提出了一个私有模型压缩框架。学生模型适用于公共数据,而教师模型适用于敏感数据和公共数据。这种隐私知识蒸馏采用隐私损失和批量损失来进一步提高隐私性。为了考虑隐私和性能之间的折衷,Bai 等人。 (2020) 通过一种新颖的分层知识蒸馏开发了一种少镜头网络压缩方法,每类样本很少。
当然,知识蒸馏还有其他特别有趣的应用,比如神经架构搜索(Macko et al., 2019; Bashivan et al., 2019),深度神经网络的可解释性(Liu et al., 2018b) ) 和联邦学习(Bistritz 等人,2020 年;Lin 等人,2020 年;Seo 等人,2020 年;He 等人,2020a)。
八、结论和讨论
近年来,知识蒸馏及其应用引起了广泛关注。在本文中,我们从知识、蒸馏方案、师生体系结构、蒸馏算法、性能比较和应用等角度对知识蒸馏进行了全面的回顾。下面,我们讨论知识蒸馏的挑战,并对知识蒸馏的未来研究提供一些见解。
1、挑战
对于知识蒸馏,关键是1)从老师那里提取丰富的知识,2)将老师的知识迁移到指导学生的训练中。因此,我们从以下几个方面讨论知识蒸馏的挑战:知识的质量、蒸馏的类型、师生体系结构的设计、知识蒸馏背后的理论。
大多数 KD 方法利用不同类型知识的组合,包括基于响应、基于特征和基于关系的知识。因此,重要的是要了解每种知识类型的影响,并了解不同种类的知识如何以互补的方式相互帮助。例如,基于响应的知识与标签平滑和模型正则化具有相似的动机(Kim 和 Kim,2017 年;Muller 等人,2019 年;Ding 等人,2019 年);基于特征的知识通常用于模仿教师的中间过程,基于关系的知识用于捕获不同样本之间的关系。为此,在统一且互补的框架中对不同类型的知识进行建模仍然具有挑战性。例如,来自不同提示层的知识可能对学生模型的训练有不同的影响:1)基于响应的知识来自最后一层; 2) 来自更深层提示/引导层的基于特征的知识可能会受到过度正则化的影响 (Romero et al., 2015)。
如何将丰富的知识从教师传授给学生是知识升华的关键步骤。现有的蒸馏方法一般可分为离线蒸馏、在线蒸馏和自蒸馏。离线蒸馏通常用于从复杂的教师模型迁移知识,而教师模型和学生模型在在线蒸馏和自蒸馏的设置中具有可比性。为了提高知识转移的效率,应进一步研究模型复杂度与现有蒸馏方案或其他新型蒸馏方案之间的关系 (Sun et al., 2021)。
目前,大多数 KD 方法都侧重于新型知识或蒸馏损失函数,导致对师生架构的设计研究不足(Nowak 和 Corso,2018;Crowley 等,2018;Kang 等,2020; Liu 等人,2019i;Ashok 等人,2018 年;Liu 等人,2019a)。事实上,除了知识和蒸馏算法之外,教师和学生的结构之间的关系也显着影响知识蒸馏的性能。例如,一方面,最近的一些工作发现,由于教师模型和学生模型之间的模型能力差距,学生模型从一些教师模型中学到的东西很少(Zhang et al., 2019b; Kang et al. , 2020);另一方面,从一些关于神经网络容量的早期理论分析来看,浅层网络能够学习与深度神经网络相同的表示(Ba 和 Caruana,2014)。因此,设计有效的学生模型或构建合适的教师模型仍然是知识蒸馏中具有挑战性的问题。
尽管有大量的知识蒸馏方法和应用,但对知识蒸馏的理解包括理论解释和实证评估仍然不足(Lopez-Paz 等,2016;Phuong 和 Lampert,2019a;Cho 和 Hariharan,2019) ).例如,蒸馏可以被视为一种利用特权信息进行学习的形式(Lopez-Paz 等人,2016 年)。线性教师和学生模型的假设使得能够通过蒸馏研究学生学习特征的理论解释(Phuong 和 Lampert,2019a)。此外,Cho 和 Hariharan(2019)对知识蒸馏的有效性进行了一些实证评估和分析。然而,对知识蒸馏的泛化性,尤其是如何衡量知识质量或师生架构质量的深入理解,仍然非常困难。
2、未来方向
为了提高知识蒸馏的性能,最重要的因素包括什么样的师生网络架构,从教师网络中学到什么样的知识,以及从哪里蒸馏到学生网络中。
深度神经网络的模型压缩和加速方法通常分为四类,即参数剪枝和共享、低秩分解、转移紧凑卷积滤波器和知识蒸馏(Cheng 等人,2018)。在现有的知识蒸馏方法中,只有少数相关工作讨论了知识蒸馏与其他各种压缩方法的结合。例如,量化知识蒸馏,可以看作是一种参数剪枝方法,将网络量化集成到师生架构中(Polino et al., 2018; Mishra and Marr, 2018; Wei et al., 2018)。因此,为了学习在便携式平台上部署的高效和有效的轻量级深度模型,通过知识蒸馏和其他压缩技术的混合压缩方法是必要的,因为大多数压缩技术需要重新训练/微调过程。此外,如何确定应用不同压缩方法的正确顺序将是未来研究的一个有趣课题。
除了用于深度神经网络加速的模型压缩外,知识蒸馏还可以用于其他问题,因为知识转移在师生架构上的自然特性。最近,知识蒸馏已应用于数据隐私和安全(Wang et al., 2019a)、深度模型的对抗性攻击(Papernot et al., 2016)、跨模态(Gupta et al., 2016)、多个领域(Asami 等人,2017),灾难性遗忘(Lee 等人,2019b),加速深度模型学习(Chen 等人,2016),神经架构搜索效率(Bashivan 等人。 ,2019)、自我监督(Noroozi 等,2018)和数据增强(Lee 等,2019a;Gordon 和 Duh,2019)。另一个有趣的例子是,从小型教师网络到大型学生网络的知识转移可以加速学生的学习(Chen 等人,2016 年)。这与普通的知识蒸馏非常不同。大型模型从未标记数据中学习到的特征表示也可以通过蒸馏来监督目标模型 (Noroozi et al., 2018)。为此,将知识蒸馏扩展到其他目的和应用可能是一个有意义的未来方向。
知识蒸馏的学习类似于人类的学习。将知识迁移推广到经典和传统的机器学习方法是可行的(Zhou et al., 2019b; Gong et al., 2018; You et al., 2018; Gong et al., 2017)。例如,基于知识蒸馏的思想,传统的两阶段分类可以很好地转化为单一教师单一学生问题(Zhou et al., 2019b)。此外,知识蒸馏可以灵活地部署到各种优秀的学习方案中,例如对抗性学习(Liu et al., 2018)、自动机器学习(Macko et al., 2019; Fakoor et al., 2020)、标签噪声过滤学习 (Xia et al., 2018)、终身学习 (Zhai et al., 2019) 和强化学习 (Ashok et al., 2018; Xu et al., 2020c; Zhao and Hospedales, 2020)。因此,将知识蒸馏与其他学习方案相结合以应对未来的实际挑战将很有用。














 41
41











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









