







冯诺依曼结构主要思想
- 采用“存储程序”工作方式
- 计算机硬件系统由运算器、控制器、存储器、输入设备、输出设备组成
- 运算器应能进行算术运算、逻辑运算,控制器应能自动执行指令,存储器应能存放数据和指令,数据和指令形式上没有区别但计算机应能区分,操作人员可通过输入设备、输出设备使用计算机
- 计算机内以二进制形式表示指令和数据,指令由操作码和地址码两部分构成,由一串指令组成程序
ISA(Instruction Set Architecture)
- ISA是一种规约(Specification),规定了如何使用硬件
- 定义了一台计算机可执行的指令的集合,包括指令格式,针对每条指令计算机执行什么操作
- 规定了寄存器的个数、位数、名称、用途,统称为寄存器组的结构
- 规定了数据表示(Data Representation,即硬件能直接识别和处理的数据类型)
- 规定了寻址方式,包括最小寻址单元,寻址方式及其表示
- 规定了程序员可访问地址空间的大小
- 规定了操作数在存储空间存放时按照大端还是小端方式存放
- 规定了执行过程的控制方式,包括程序计数器、条件码定义等
- 规定了IO结构,包括IO连接方式,处理器存储器与IO设备间数据传送方式和格式,IO操作的状态等
- 规定了IO空间的编址方式,异常和中断机制,机器工作状态的定义和切换(如管态和目态),存储保护方式等
ISA、计算机组成、计算机实现的区别
- ISA是确定软硬件界面,确定计算机硬件可实现哪些功能,基于什么规则实现,计算机组成是ISA约束下的逻辑实现,计算机实现则是计算机组成的物理实现,落实到了选什么器件,设计什么逻辑电路,采用何种微组装技术
- 一种体系结构可以有多种计算机组成,一种计算机组成可以有多种计算机实现
- 例①:设计主存系统时,确定主存容量、编址方式、寻址范围等属于ISA;确定主存周期、是否采用并行、多模块交叉等属于计算机组成;确定存储芯片类型、电路设计、微组装技术等属于计算机实现
- 例②:设计指令集时,确定是否有乘法指令属于ISA;确定乘法指令使用乘法器实现还是用加法器经多步操作实现属于计算机组成;确定乘法器或加法器用什么器件或逻辑电路如何设计属于计算机实现
从源程序到可执行文件
第①步:用编辑软件得到hello.c文件
#include<stdio.h>
int main(){
printf("hello world\n");
}
第②步:将hello.c进行预处理、编译、汇编、链接,最终生成可执行目标文件
- 预处理阶段:预处理程序(cpp)对源程序中以字符#开头的命令进行处理。例如:将#include命令后面的.h文件内容嵌入到源程序文件。预处理程序的输出结果还是一个源程序文件。预处理程序的输出结果还是一个源程序文件,以.i为拓展名。
- 对应命令:gcc -E hello.c -o hello.i
- 编译阶段:编译程序(ccl)对预处理后的源程序进行编译,生成一个汇编语言源程序文件,以.s为拓展名
- 对应命令:gcc -S hello.i -o hello.s,或直接从.c文件得到:gcc -S hello.c -o hello.s
- 汇编阶段:汇编程序(as)将hello.s翻译成机器语言指令,生成一个可重定位目标文件(relocatable object file),以.o为拓展名,它是一种二进制文件(binary file),不可读的,用文本编辑器打开显示出来的是乱码
- 对应命令:gcc -c hello.s -o hello.o,或直接从.c文件得到:gcc -c hello.c -o hello.o
- 链接阶段:链接程序(ld)将多个可重定位目标文件和标准库函数合并为一个可执行目标文件(executable object file),简称可执行文件。在上例中:链接器将hello.o和标准库函数printf所在的可重定位目标模块printf.o合并,生成可执行文件hello
- 对应命令:gcc hello.o -o hello,或直接从.c文件得到:gcc hello.c -o hello
- 最终生成的可执行文件保存在磁盘上
ABI(Application Binary Interface,应用程序二进制接口)
- ABI是编译器和链接器遵守的一组规则,是在特定的ISA及特定的操作系统之上的应用程序生产所对应的机器级目标代码时必须遵循的约定
- 不符合ABI规范的目标程序,无法正确运行在根据该ABI规范提供的操作系统运行环境中
- 规定了过程调用时,参数和返回值如何传递,寄存器如何使用,栈帧如何建立和销毁
- 规定了系统调用时,参数和调用号如何传递,如何从用户态转换到操作系统内核
- 规定了目标文件的二进制格式
- 规定了库函数该如何使用
- 规定了各寄存器的用途
- 规定了程序的虚拟地址空间划分
- 规定了系统基本数据类型的宽度
计算机系统性能评价
吞吐率与响应时间
吞吐率(throughput)和响应时间(response time)是考量计算机系统性能的两个基本指标
- 吞吐率:单位时间内完成的工作量
- 响应时间:从作业提交到作业完成的时间
一般用执行时间(即响应时间)衡量计算机性能,即完成同样工作量所需时间最短的那台计算机就是性能最好的
一个程序的执行时间包括:①程序所含指令在CPU上执行的时间②磁盘访问时间③IO时间④操作系统调度与切换所需的额外开销
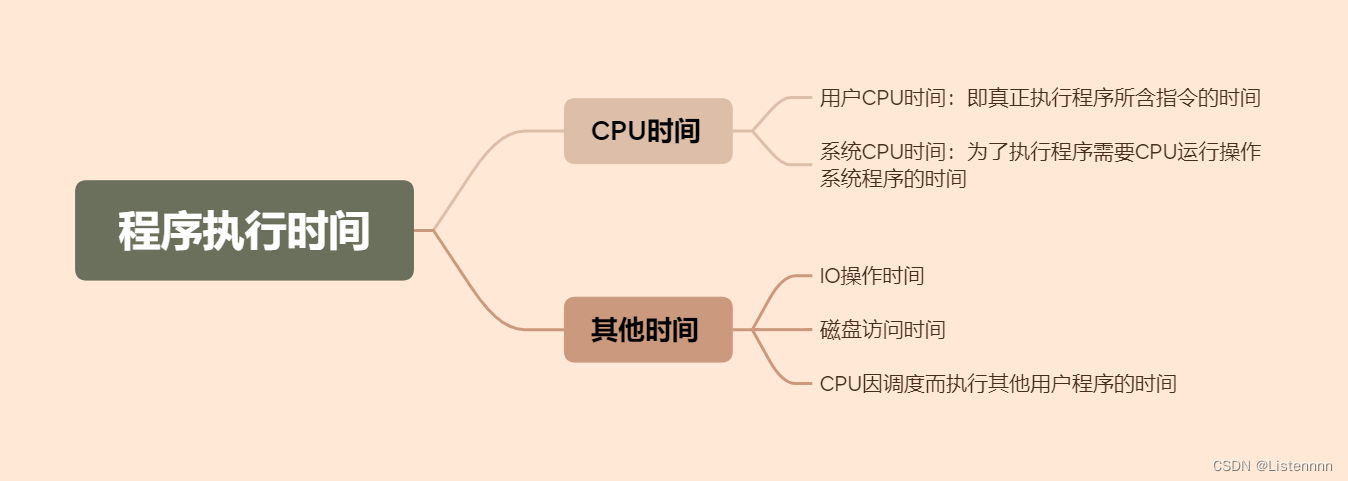
用户CPU时间
计算机系统性能主要考虑CPU性能,而CPU性能特指用户CPU时间,它是包含真正运行用户程序代码时的执行时间
在对用户CPU时间进行计算时,需要用到以下几个重要概念
- 时钟周期(clock cycle):CPU主脉冲信号的宽度。一条指令的执行时间包含一个或多个时钟周期,一个时钟周期内,CPU仅完成一个最基本动作。(CPU内部两个功能部件之间传递信息所需要的最短时间)
- 时钟频率(clock rate):CPU主脉冲信号的时钟频率。即时钟周期的倒数
- CPI(Clock cycles Per Instruction):执行一条指令所需要的时钟周期个数。对于某一条特定的指令而言,其CPI是一个确定的值。但是,对于某一个程序或一台机器而言,其CPI是一个平均值,表示该程序或该机器指令集中每条指令执行时平均需要多少时钟周期

用户CPU时间度量公式(也称为CPU性能公式)中,时钟周期、指令条数、CPI三个因素是相互制约的。例如:更改指令集可以减少一个程序的指令条数,但同时可能引起CPU结构的调整,从而可能降低时钟频率
上述公式可以简写为:用户CPU时间 = IC ×CPI ×时钟周期时间
- 时钟周期时间:取决于硬件实现技术和计算机组成
- CPI:取决于计算机组成和指令集结构(此时CPI是平均CPI)
- IC:即总的指令条数,取决于指令集结构和编译技术
如何提高计算机系统性能
提高计算机性能可以通过如下方法:提升CPU主频,增加CPU核心数量,采用流水线技术,采用分支预测技术,优化cache技术,通过编译技术减少指令条数,将复杂度高的指令用等价的简单指令替换等等
增加晶体管可以增加硬件能够支持的指令数量,增加数字通路的位数,利用电路天然的并行性,从硬件层面更快地实现特定的指令
CPU主频确实容易提高,但CPU主频太高,功耗就高,功耗带来耗电和散热的问题。因此,在 CPU 里面,能够放下的晶体管数量和晶体管的“开关”频率也都是有限的
一个 CPU 的功率,可以用这样一个公式来表示:功耗 ~= 1/2 ×负载电容×电压的平方×开关频率×晶体管数量
没有办法无限制降低电压,电压太低会导致电路无法联通,因为不管用什么作为电路材料,都是有电阻的,而且低电压对于工艺的要求也变高了,成本也更贵
除了减少响应时间,也可通过多核CPU、流水线、分支预测等并行技术来提高吞吐率
经常性事件、Amdahl定律、程序的局部性原理
在计算机系统设计时,要以经常性事件为重点,对经常使用的部件进行优化设计,对经常使用的功能分配更多资源
这里有个Amdahl定律:加快某部件执行速度所能获得的系统性能加速比,受限于该部件的执行时间占系统中总执行时间的百分比
-
可改进比例:在改进前的系统中,可改进部分的执行时间在总的执行时间中所占的比例
-
部件加速比:可改进部分改进以后性能提高的倍数。即改进前所需的执行时间与改进后执行时间的比

-
推论:如果只针对整个任务的一部分进行改进和优化,那么所获得的加速比不超过1/(1-可改进比例)

此外,充分利用Cache技术也能提高性能,Cache基于程序的局部性原理
- 时间局部性:程序中某条指令一旦执行,则不久后该指令很可能再次被执行
- 空间局部性:一旦程序访问了某个存储单元,则不久后其附近的存储单元也很可能被访问
MIPS
最早用来衡量计算机性能的指标是每秒钟完成单个运算指令的条数,当时大多数指令的执行时间差不多,大体都与加法指令相当,故加法指令的速度有一定的代表性。指令速度所用的计量单位为MIPS(Millon Instruction Per Second),含义是平均每秒钟执行多少百万条指令。

MIPS反映机器执行定点指令的速度,而用来表示浮点操作速度的指标是MFLOPS (Million Floating-point Operations Per Second),浮点运算实际上包括了所有涉及小数的运算,在某类应用软件中常常出现,比整数运算更费时间。现今大部分的处理器中都有浮点运算器。因此每秒浮点运算次数所量测的实际上就是浮点运算器的执行速度。而最常用来测量每秒浮点运算次数的基准程序(benchmark)之一是Linpack- 一个MFLOPS(megaFLOPS)每秒一佰万(=10^6)次的浮点运算
- 一个GFLOPS(gigaFLOPS)每秒拾亿(=10^9)次的浮点运算
- 一个TFLOPS(teraFLOPS)每秒万亿(=10^12)次的浮点运算
- 一个PFLOPS(petaFLOPS)每秒千万亿(=10^15)次的浮点运算
- 一个EFLOPS(exaFLOPS)每秒百亿亿(=10^18)次的浮点运算
因为不同机器的指令集不同,程序由不同的指令混合而成,指令使用的频度动态变化,所以MIPS不能说明性能的好坏
基准程序(benchmarks)
基准程序(benchmarks)是进行计算机性能评测的一种重要工具,基准程序是专门用来进行性能评价的一组程序,通过在不同机器上运行相同的基准程序来比较运行时间,从而评价其性能。1988年,5家公司(Sun, MIPS, HP, Apollo, DEC)联合提出的SPEC(Standard Performance Evaluation Corporation,标准性能评估组织)测试程序集是应用最广泛,也是最全面的性能评测基准程序集
计算机系统的并行性
并行性:计算机系统在同一时刻或者同一时间间隔内进行多种运算或操作
提高并行性有三种途径:
- 时间重叠:轮流重叠的使用同一套硬件的各个部分。如流水线
- 资源重复:重复设置硬件资源。如阵列处理机、多体存储器
- 资源共享:一种软件方法,按时间顺序轮流使用同一套硬件。如多道程序、分时系统
CISC与RISC
CISC:Complex Instruction Set Computer,复杂指令集计算机
- 设计目标:增加指令功能,把功能尽可能交给硬件实现
特点:
- 指令种类多,不定长
- 寻址方式多
- 控制器大多采用微程序实现
- 有专用指令完成特定功能,处理特殊任务效率高
- 各种指令使用频度相差大,执行时间相差大
- 指令功能复杂,规整性不好,不利于采用流水线技术提高性能
RISC:Reduced Instruction Set Computer,精简指令集计算机
- 设计目标:只选取使用频度最高的指令,并补充一些最有用的指令
特点
- 指令种类少,定长
- 寻址方式少
- 控制器大多采用硬布线实现
- 只有load和store指令才能访存,其余操作都在寄存器间进行
- CPU中寄存器数量很多
- 强调编译器的优化作用,利于充分利用流水线提高性能
指令集结构设计涉及哪些内容
- 指令集功能设计:主要有RISC和CISC两种方向
- 寻址方式的设计:根据使用频度,设置必要的寻址方式,如何在指令中表示寻址方式(操作码编码指定?为每个操作数设置一个地址描述符?)
- 操作数类型和大小:确定数据表示及其字长,如何在指令中确定操作数类型(操作码编码指定?为每个数据设置一个标识?)
- 指令集格式的设计:有变长编码格式(目标代码少,译码难)、定长编码格式(目标代码多,译码简单)、混合型编码格式(兼顾前两者,妥协折中)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









