







目录
🥕jsoup简介🥕
一款Java 的HTML解析器, 可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
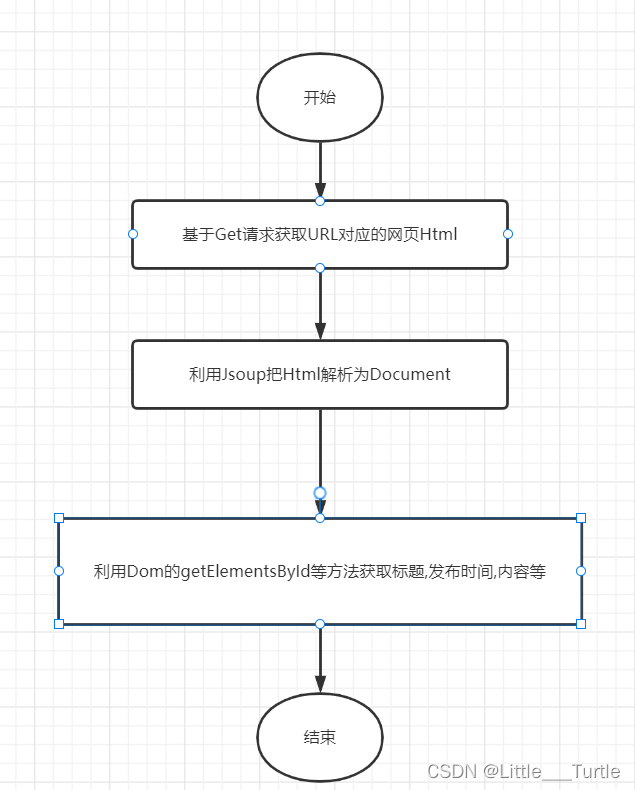

🥑爬取案例-网易新闻🥑
爬取成功
温馨提示:需要爬取网易新闻全部资源 需要二次爬取文章链接(爬第一次的链接后再爬取获取作者 时间 图片) 如果是网易自己的文章可成功爬取 对于网易导入的外部资源链接无法处理(网页结构无法预判)
2022-09-29 20:27:48.321 INFO 11176 --- [ main] com.demo.article.utils.HtmlParseUtil : 文章Article(pkId=null, articleName=助力中阿全面战略伙伴关系谱写新篇章, articleAuthor=央视网, gmtCreate=2022-09-29T19:02:45, articleUrl=https://www.163.com/news/article/HIF2VTOA000189FH.html, articleShowPic=https://nimg.ws.126.net/?url=http%3A%2F%2Fcms-bucket.ws.126.net%2F2022%2F0929%2F12707880j00riyxc1001wc000m800e1c.jpg&thumbnail=660x2147483647&quality=80&type=jpg)
2022-09-29 20:27:48.321 INFO 11176 --- [ main] com.demo.article.utils.HtmlParseUtil : 文章Article(pkId=null, articleName=“构筑中华民族共有精神家园”, articleAuthor=中国 新闻网, gmtCreate=2022-09-29T17:07:17, articleUrl=https://www.163.com/news/article/HIESCG7A000189FH.html, articleShowPic=https://nimg.ws.126.net/?url=http%3A%2F%2Fcms-bucket.ws.126.net%2F2022%2F0929%2F5e65fcc1j00riyrzn0039c000p0018gc.jpg&thumbnail=660x2147483647&quality=80&type=jpg)
2022-09-29 20:27:48.321 INFO 11176 --- [ main] com.demo.article.utils.HtmlParseUtil : 文章Article(pkId=null, articleName=片仓凤美:通过花艺与中国年轻人分享快乐, articleAuthor=人民网, gmtCreate=2022-09-29T17:41:59, articleUrl=https://www.163.com/news/article/HIEUC25B000189FH.html, articleShowPic=https://static.ws.126.net/163/f2e/product/post_nodejs/static/logo.png)
2022-09-29 20:27:48.321 INFO 11176 --- [ main] com.demo.article.utils.HtmlParseUtil : 文章Article(pkId=null, articleName=节前市场探物价:粮油价格稳定 蔬菜鸡蛋价格回落, articleAuthor=新华社客户端, gmtCreate=2022-09-29T16:38:36, articleUrl=https://www.163.com/news/article/HIEQO06H000189FH.html, articleShowPic=https://nimg.ws.126.net/?url=http%3A%2F%2Fcms-bucket.ws.126.net%2F2022%2F0929%2F069a37c3j00riyqnw0013c000b4008cc.jpg&thumbnail=660x2147483647&quality=80&type=jpg)
2022-09-29 20:27:48.321 INFO 11176 --- [ main] com.demo.article.utils.HtmlParseUtil : 文章Article(pkId=null, articleName=好邻居金不换(国际论坛), articleAuthor=人民网, gmtCreate=2022-09-29T06:08:21, articleUrl=https://www.163.com/dy/article/HIDMLUTN0514R9M0.html, articleShowPic=)🥒项目目录介绍🥒
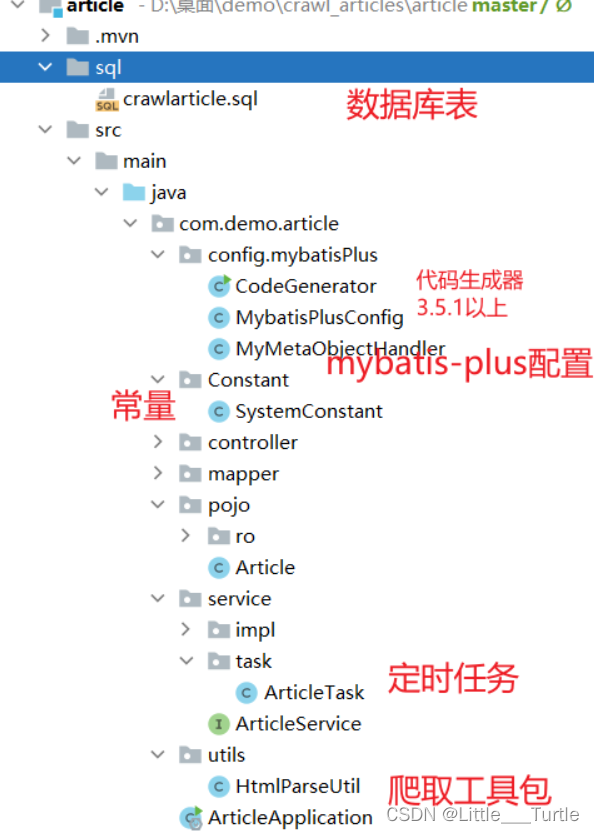
🥬项目详细讲解🥬
🥰爬取网页资源🥰
🥐为了更好的理解 快速用在自己的项目中🥐
🥙专门拍摄了一期视频讲解🥙
🍵B站视频🍵
🐎源码的分享🐎
🦌视频简介中(Gitee)🦌
🫖制作不易 望大家给个三连支持呀🫖

🥦部分代码演示🥦
//获取文章作者
String articleSource = articleContext.getElementsByClass("post_info").eq(SystemConstant.NUM_ZERO).text();
//如果文章中获取不了具体信息 说明不是网易文章 可直接跳过
if (ObjectUtil.isEmpty(articleSource)) {
continue;
}
//2022-08-01 12:01:14 来源: 央视新闻客户端 北京 举报 截取出文章作者
String author = StrUtil.sub(articleSource, 24, -6);
//文章发表时间
LocalDateTime gmtModified = DateUtil.parseLocalDateTime(StrUtil.sub(articleSource, 0, 19), SystemConstant.DATE_FORMAT_YYYY_MM_DD_HH_MM_SS);
//获取文章图片
Element content = articleContext.getElementById("content");















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











