







1 准备数据
-
建立索引 shop(名字随意)
POST /shop/_mapping { "properties": { "id": { "type": "long" }, "age": { "type": "integer" }, "username": { "type": "keyword" }, "nickname": { "type": "text", "analyzer": "ik_max_word" }, "money": { "type": "float" }, "desc": { "type": "text", "analyzer": "ik_max_word" }, "sex": { "type": "byte" }, "birthday": { "type": "date" }, "face": { "type": "text", "index": false } } } -
录入数据
POST /shop/_doc/1001 { "id": 1001, "age": 18, "username": "imoocAmazing", "nickname": "慕课网", "money": 88.8, "desc": "我在慕课网学习java和前端,学习到了很多知识", "sex": 0, "birthday": "1992-12-24", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1002 { "id": 1002, "age": 19, "username": "justbuy", "nickname": "周杰棍", "money": 77.8, "desc": "今天上下班都很堵,车流量很大", "sex": 1, "birthday": "1993-01-24", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1003 { "id": 1003, "age": 20, "username": "bigFace", "nickname": "飞翔的巨鹰", "money": 66.8, "desc": "慕课网团队和导游坐飞机去海外旅游,去了新马泰和欧洲", "sex": 1, "birthday": "1996-01-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1004 { "id": 1004, "age": 22, "username": "flyfish", "nickname": "水中鱼", "money": 55.8, "desc": "昨天在学校的池塘里,看到有很多鱼在游泳,然后就去慕课网上课了", "sex": 0, "birthday": "1988-02-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1005 { "id": 1005, "age": 25, "username": "gotoplay", "nickname": "ps游戏机", "money": 155.8, "desc": "今年生日,女友送了我一台play station游戏机,非常好玩,非常不错", "sex": 1, "birthday": "1989-03-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1006 { "id": 1006, "age": 19, "username": "missimooc", "nickname": "我叫小慕", "money": 156.8, "desc": "我叫凌云慕,今年20岁,是一名律师,我在琦䯲星球做演讲", "sex": 1, "birthday": "1993-04-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1007 { "id": 1007, "age": 19, "username": "msgame", "nickname": "gamexbox", "money": 1056.8, "desc": "明天去进货,最近微软处理很多游戏机,还要买xbox游戏卡带", "sex": 1, "birthday": "1985-05-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1008 { "id": 1008, "age": 19, "username": "muke", "nickname": "慕学习", "money": 1056.8, "desc": "大学毕业后,可以到imooc.com进修", "sex": 1, "birthday": "1995-06-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1009 { "id": 1009, "age": 22, "username": "shaonian", "nickname": "骚年轮", "money": 96.8, "desc": "骚年在大学毕业后,考研究生去了", "sex": 1, "birthday": "1998-07-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1010 { "id": 1010, "age": 30, "username": "tata", "nickname": "隔壁老王", "money": 100.8, "desc": "隔壁老外去国外出差,带给我很多好吃的", "sex": 1, "birthday": "1988-07-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1011 { "id": 1011, "age": 31, "username": "sprder", "nickname": "皮特帕克", "money": 180.8, "desc": "它是一个超级英雄", "sex": 1, "birthday": "1989-08-14", "face": "https://www.imooc.com/static/img/index/logo.png" } POST /shop/_doc/1012 { "id": 1012, "age": 31, "username": "super hero", "nickname": "super hero", "money": 188.8, "desc": "BatMan, GreenArrow, SpiderMan, IronMan... are all Super Hero", "sex": 1, "birthday": "1980-08-14", "face": "https://www.imooc.com/static/img/index/logo.png" }
2 使用 QueryString 查询
查询[字段]包含[内容]的文档
GET /shop/_doc/_search?q=desc:慕课网
GET /shop/_doc/_search?q=nickname:慕&q=age:25
3 DSL
3.1 match - 查询
全文检索
POST /shop/_search
{
"query": {
"match": {
"desc": "慕课网"
}
}
}
3.2 exists - 判断某个字段是否存在
exists可以理解为SQL中的exists函数,就是判断是否存在该字段。
POST /shop/_search
{
"query": {
"exists": {
"field": "desc"
}
}
}
3.3 match_all - 查询所有与分页
可以查询集群所有索引库的信息,包括一些隐藏索性库的信息。
3.3.1 在索引中查询所有的文档
GET /shop/_doc/_search
或者指定返回属性
POST /shop/_doc/_search
{
"query": {
"match_all": {}
},
"_source": ["id", "nickname", "age"]
}
-
Head 可视化操作

3.3.2 分页查询
默认查询是只有10条记录,可以通过分页来展示
POST /shop/_doc/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 10
}
POST /shop/_doc/_search
{
"query": {
"match_all": {}
},
"_source": [
"id",
"nickname",
"age"
],
"from": 5,
"size": 5
}
-
Head 可视化操作

3.4 term - 精确查询
term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed 的字符串(未经分析的文本数据类型)
3.4.1 term精确搜索与match分词搜索
搜索的时候会把用户搜索内容,比如“慕课网强大”作为一整个关键词去搜索,而不会对其进行分词后再搜索
POST /shop/_doc/_search
{
"query": {
"term": {
"desc": "慕课网"
}
}
}
对比
POST /shop/_doc/_search
{
"query": {
"match": {
"desc": "慕课网"
}
}
}
-
注:match会对
慕课网慕课网先进行分词(其实就是全文检索),在查询,而term则不会,直接把
作为一个整的词汇去搜索。
-
head 可视化操作对比:

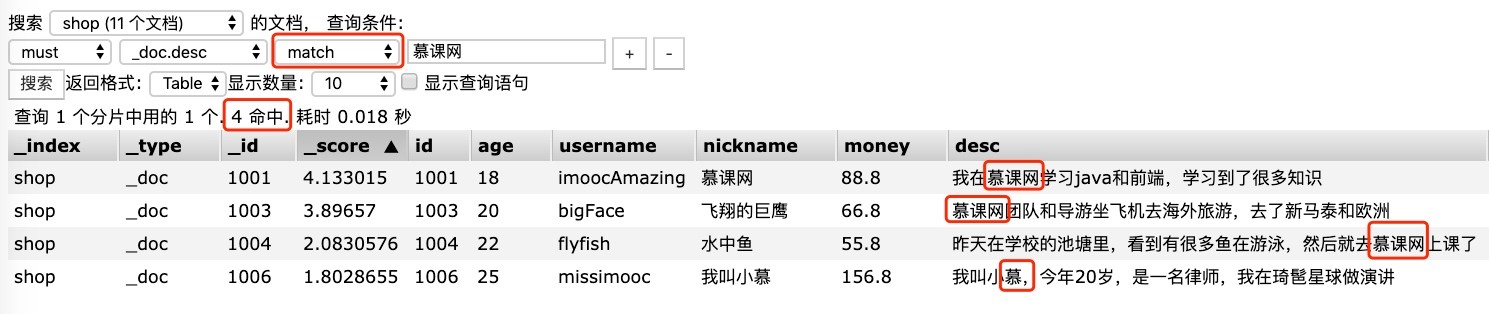
3.4.2 terms 多个词语匹配检索
相当于是tag标签查询,比如慕课网的一些课程会打上前端/后端/大数据/就业课这样的标签,可以完全匹配做类似标签的查询
POST /shop/_doc/_search
{
"query": {
"terms": {
"desc": ["慕课网", "学习", "骚年"]
}
}
}
3.5 match_phrase
match:分词后只要有匹配就返回,match_phrase:分词结果必须在text字段分词中都包含,而且顺序必须相同,而且必须都是连续的。(搜索比较严格)
slop:允许词语间跳过的数量
POST /shop/_doc/_search
{
"query": {
"match_phrase": {
"desc": {
"query": "大学 毕业 研究生",
"slop": 2
}
}
}
}
3.6 match(operator)/ids
3.6.1 match 扩展
-
operator
- or:搜索内容分词后,只要存在一个词语匹配就展示结果
- and:搜索内容分词后,都要满足词语匹配
POST /shop/_doc/_search { "query": { "match": { "desc": "慕课网" } } } # 等同于 { "query": { "match": { "desc": { "query": "xbox游戏机", "operator": "or" } } } } # 相当于 select * from shop where desc='xbox' or|and desc='游戏机' -
minimum_should_match: 最低匹配精度,至少有[分词后的词语个数]x百分百,得出一个数据值取整。举个例子:当前属性设置为
70,若一个用户查询检索内容分词后有10个词语,那么匹配度按照 10x70%=7,则desc中至少需要有7个词语匹配,就展示;若分词后有8个,则 8x70%=5.6,则desc中至少需要有5个词语匹配,就展示。minimum_should_match 也能设置具体的数字,表示个数
POST /shop/_doc/_search { "query": { "match": { "desc": { "query": "女友生日送我好玩的xbox游戏机", "minimum_should_match": "60%" } } } }
3.6.2 根据文档主键ids搜索
GET /shop/_doc/1001
查询多个
POST /shop/_doc/_search
{
"query": {
"ids": {
"type": "_doc",
"values": ["1001", "1010", "1008"]
}
}
}
3.7 multi_match/boost
3.7.1 multi_match - 多字段查询
满足使用match在多个字段中进行查询的需求
POST /shop/_doc/_search
{
"query": {
"multi_match": {
"query": "皮特帕克慕课网",
"fields": ["desc", "nickname"]
}
}
}
3.7.2 boost - 权重
权重,为某个字段设置权重,权重越高,文档相关性得分就越高。通畅来说搜索商品名称要比商品简介的权重更高。
POST /shop/_doc/_search
{
"query": {
"multi_match": {
"query": "皮特帕克慕课网",
"fields": ["desc", "nickname^10"]
}
}
}
nickname^10 代表搜索提升10倍相关性,也就是说用户搜索的时候其实以这个nickname为主,desc为辅,nickname的匹配相关度当然要提高权重比例了。
3.8 bool - 布尔查询
可以组合多重查询
-
must:查询必须匹配搜索条件,譬如 and
-
should:查询匹配满足1个以上条件,譬如 or
-
must_not:不匹配搜索条件,一个都不要满足
-
实操1:
POST /shop/_doc/_search { "query": { "bool": { "must": [ { "multi_match": { "query": "慕课网", "fields": ["desc", "nickname"] } }, { "term": { "sex": 1 } }, { "term": { "birthday": "1996-01-14" } } ] } } } POST /shop/_doc/_search { "query": { "bool": { "should(must_not)": [ { "multi_match": { "query": "学习", "fields": ["desc", "nickname"] } }, { "match": { "desc": "游戏" } }, { "term": { "sex": 0 } } ] } } } -
实操2:
POST /shop/_doc/_search { "query": { "bool": { "must": [ { "match": { "desc": "慕" } }, { "match": { "nickname": "慕" } } ], "should": [ { "match": { "sex": "0" } } ], "must_not": [ { "term": { "birthday": "1992-12-24" } } ] } } } -
Head 可视化组合查询

-
为指定词语加权
特殊场景下,某些词语可以单独加权,这样可以排得更加靠前。
POST /shop/_doc/_search { "query": { "bool": { "should": [ { "match": { "desc": { "query": "律师", "boost": 18 } } }, { "match": { "desc": { "query": "进修", "boost": 2 } } } ] } } }
3.9 post_filter - 过滤器
对搜索出来的结果进行数据过滤。不会到es库里去搜,不会去计算文档的相关度分数,所以过滤的性能会比较高,过滤器可以和全文搜索结合在一起使用。post_filter元素是一个顶层元素,只会对搜索结果进行过滤。不会计算数据的匹配度相关性分数,不会根据分数去排序,query则相反,会计算分数,也会按照分数去排序。
使用场景:
- query:根据用户搜索条件检索匹配记录
- post_filter:用于查询后,对结果数据的筛选
实操:查询账户金额大于80元,小于160元的用户。并且生日在1998-07-14的用户
- gte:大于等于
- lte:小于等于
- gt:大于
- lt:小于(除此以外还能做其他的match等操作也行)
POST /shop/_doc/_search
{
"query": {
"match": {
"desc": "慕课网游戏"
}
},
"post_filter": {
"range": {
"money": {
"gt": 60,
"lt": 1000
}
}
}
}
3.10 sort - 排序
es的排序同sql,可以desc也可以asc。也支持组合排序。
-
实操:
POST /shop/_doc/_search { "query": { "match": { "desc": "慕课网游戏" } }, "post_filter": { "range": { "money": { "gt": 55.8, "lte": 155.8 } } }, "sort": [ { "age": "desc" }, { "money": "desc" } ] } -
对文本排序
由于文本会被分词,所以往往要去做排序会报错,通常我们可以为这个字段增加额外的一个附属属性,类型为keyword,用于做排序。
-
创建新的索引
POST /shop2/_mapping { "properties": { "id": { "type": "long" }, "nickname": { "type": "text", "analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword" } } } } } -
插入数据
POST /shop2/_doc { "id": 1001, "nickname": "美丽的风景" } POST /shop2/_doc { "id": 1002, "nickname": "漂亮的小哥哥" } POST /shop2/_doc { "id": 1003, "nickname": "飞翔的巨鹰" } POST /shop2/_doc { "id": 1004, "nickname": "完美的天空" } POST /shop2/_doc { "id": 1005, "nickname": "广阔的海域" } -
排序
POST /shop2/_doc/_search { "sort": [ { "nickname.keyword": "desc" } ] }
-
3.11 highlight - 高亮显示
POST /shop/_doc/_search
{
"query": {
"match": {
"desc": "慕课网"
}
},
"highlight": {
"pre_tags": ["<span>"],
"post_tags": ["</span>"],
"fields": {
"desc": {}
}
}
}
3.12 prefix - 前缀
根据前缀去查询
POST /shop/_doc/_search
{
"query": {
"prefix": {
"desc": "imo"
}
}
}
3.13 fuzzy - 模糊搜索
模糊搜索,并不是指的sql的模糊搜索,而是用户在进行搜索的时候的打字错误现象,搜索引擎会自动纠正,然后尝试匹配索引库中的数据。
POST /shop/_doc/_search
{
"query": {
"fuzzy": {
"desc": "imoov.coom"
}
}
}
# 或多字段搜索
POST /shop/_doc/_search
{
"query": {
"multi_match": {
"fields": [ "desc", "nickname"],
"query": "imcoc supor",
"fuzziness": "AUTO"
}
}
}
POST /shop/_doc/_search
{
"query": {
"multi_match": {
"fields": [ "desc", "nickname"],
"query": "演说",
"fuzziness": "1"
}
}
}
3.14 wildcard - 占位符查询
占位符查询。
-
?:1个字符
-
:1个或多个字符
POST /shop/_doc/_search { "query": { "wildcard": { "desc": "*oo?" } } } { "query": { "wildcard": { "desc": "演*" } } } -
官文:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html















 2642
2642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









