







官方下载地址:DM达梦数据库产品下载
DM技术文档在线手册:DM-达梦技术文档
Windows 安装步骤参考文章:Windows环境安装达梦数据库
PS : 下载完成后,对应安装包路径中(dmdbms\doc)目录下存放了大量达梦数据库使用手册!
- 使用DM管理工具访问数据库:
下载完成后,在数据库安装包地址中 tool工具目录下包含数据库访问工具 manager
达梦数据库管理工具:
- 使用 disql 访问数据库:
DIsql 是 DM 数据库的一个命令行客户端工具,用来与 DM 数据库服务器进行交互,其存放在安装目录下的 bin文件下,可通过./disql username/password@ip:port 的方式进行连接数据库(ip和端口不写默认是localhost和5236):
- 在安装包下的工具目录中(**\dmdbms\tool 下)所有工具:
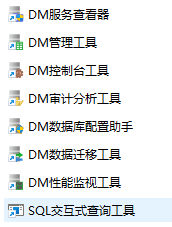
- 数据库配置助手:./dbca.sh就是一开始安装完了初始化数据库的工具,用于创建、删除数据库实例和服务的。
ps:这里需要注意的是起名字需要使用“-”的,在disql操作创建的对象时需要带上双引号进行转义。
- 服务查看器:./dmservice.sh 查看所有的服务以及属性,控制服务启停。
- 管理工具:./manager连接和操作数据库,相当于一个数据库连接工具,方便进行日常运
ps:这里也需要注意在创建新的对象时名字以及密码带有特殊字符的时候会需要转义。
- 控制台工具:./console数据库管理员可以完成服务器参数配置、管理 DM 服务、脱机备份与还原、查看系统信息、查看许可证信息等功能。
- 审计分析工具:./analyzer审计规则的创建与修改,审计记录的查看与导出。按照我们的需求创建审计规则和条件来筛选日志里符合条件的记录。
- 性能监视工具:./monitor监视服务器的活动和性能情况,并对系统参数进行调整的客户端工具,它允许系统管理员在本机或远程监视服务器的运行状况。主要包括:统计分析、性能监视、调优向导、预警警告四大功能。
- 迁移工具:./dts提供了主流大型数据库迁移到 DM、DM 到 DM、文件迁移到 DM 以及 DM 迁移到文件等功能。
- SQL交互式查询工具:打开是一个dos窗口,用于执行disql命令。
一、数据库用户(USER)
DM 数据库采用“三权分立”或“四权分立”的安全机制,将系统中所有的权限按照类型进行划分,为每个管理员分配相应的权限,管理员之间的权限相互制约又相互协助,从而使整个系统具有较高的安全性和较强的灵活性。
可在创建DM数据库是同建库参数 PRIV_FLAG (0标识三权,1标识四权)设置使用“三权分立”或“四权分立”安全机制。
使用“三权分立”安全机制时,将系统管理员分为数据库管理员(预设账号SYSDBA)、数据库安全员(预设账号SYSSSO)和数据库审计员(预设账号SYSAUDITOR)三种类型。
1.1 用户管理
- 创建用户:
CREATE USER [IF NOT EXISTS] <用户名> IDENTIFIED BY "密码"; - 查询用户:
查询当前用户信息:
SELECT * FROM user_users;
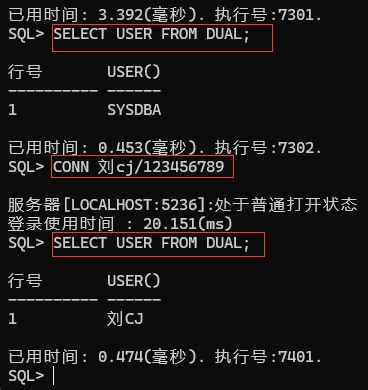
SELECT user FROM dual;
查询所有用户信息视图字典:
SELECT * FROM all_users;
SELECT * FROM dba_users;
-
切换当前用户:
conn 用户名/密码;(disql模式下使用)
-
退出登录:logout 或者 disconn 命令!
-
修改用户密码:
ALTER USER <用户名> IDENTIFIED BY 新密码; -
删除用户:
DROP USER [IF EXISTS] <用户名> CASCADE;
1.2 权限管理
用户权限有两类:数据库权限和对象权限。
数据库权限主要针对数据库对象的创建、删除、修改等。而对象权限主要是指对数据库对象中的数据的访问权限。
数据库权限一般由 SYSDBA、SYSAUDITOR 和 SYSSSO 指定,也可以由具有特权
的其他用户授予。对象权限一般由数据库对象的所有者授予用户,也可由 SYSDBA 用户指定,或者由具有该对象权限的其他用户授权。
DM 数据库用户可以通过动态视图 **V$AUTHORITIES **来查询当前数据库中的所有权限,对应字段 ID(权限主键)、NAME(权限名称)、TYPE(权限类型 1表示数据库权限 2表示对象权限)
- 权限的分配与回收
通过 GRANT 语句将权限( 包括数据库权限、对象权限以及角色权限) 分配给用户和角色,之后可以使用 REVOKE 语句将授出的权限再进行收回。
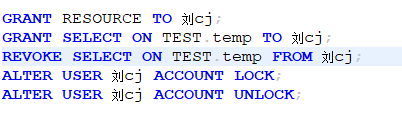
给用户授权:GRANT 权限信息 TO 用户名;
撤销用户权限:REVOKE 权限信息 FROM 用户名;
锁定/解锁用户:ALTER USER 用户姓名 ACCOUNT LOCK/UNLOCK;
- 查看达梦数据库运行状态:
SELECT status$,* FROM v$instance; - 查看数据库版本:
SELECT banner,* FROM v$version;
二、模式(SCHEMA)
用户的模式(SCHEMA) 指的是用户账号拥有的对象集(表、视图等),在概念上可将其看作是包含表、视图、索引和权限定义的对象。
一个用户可以创建多个模式,一个模式中的对象(表、视图等)可以被多个用户使用。 模式不是严格分离的,一个用户可以访问他所连接的数据库中有权限访问的任意模式中的对象。
系统为每一个用户自动创建了一个与用户名同名的模式作为该用户的默认模式(切换当前访问模式<font style="color:rgb(77, 77, 77);">SET SCHEMA "模式名";</font>),用户还可以用模式定义语句建立其它模式;
- 采用模式的原因:
- 允许多个用户使用同一个数据库而不会干扰其它用户;
- 把数据库对象组织成逻辑组,让它们更便于管理;
- 第三方的应用可以放在不同的模式中,这样可以避免和其它对象的名字冲突。模式类似于操作系统层次的目录,只不过模式不能嵌套。

查看当前所处模式: SELECT SESSION_USER;
询当前数据库中所有的模式列表:
SELECT * FROM SYSOBJECTS WHERE TYPE$='SCH';
-- SYSOBJECTS 是达梦数据库的系统表,存储了数据库中的所有对象信息。
-- TYPE$='SCH' 用于过滤出类型为模式(Schema)的对象。
三、达梦数据类型
3.1 字符数据类型
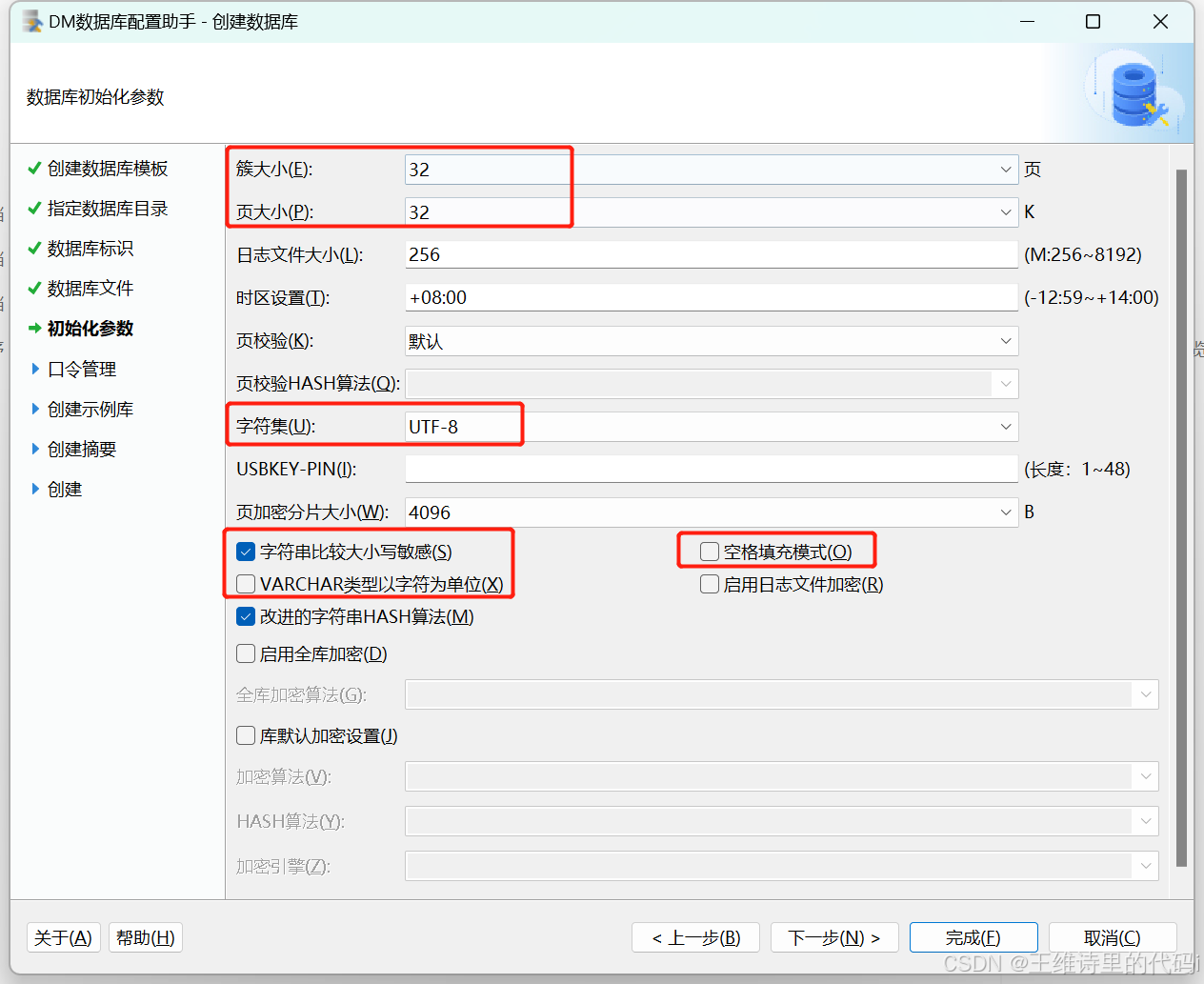
- 初始化参数
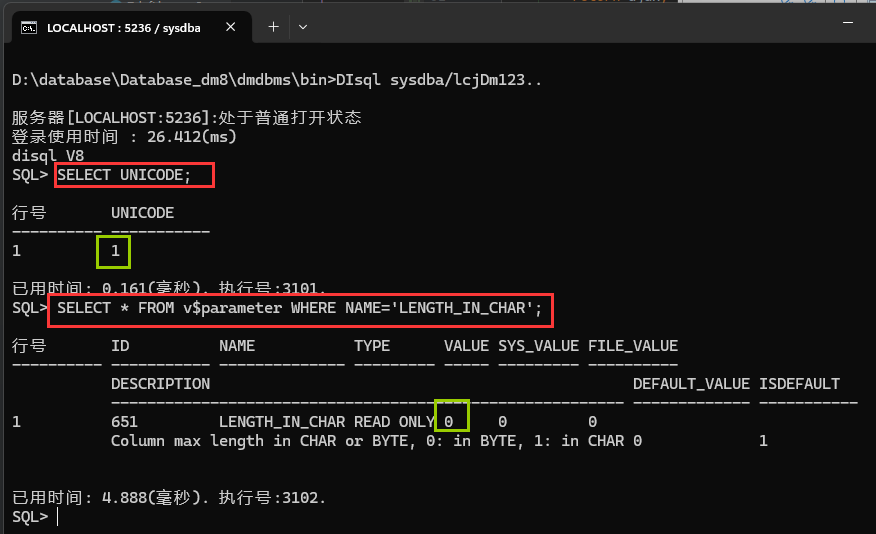
- LENGTH_IN_CHAR: 1代表以字符为单位进行存储,0代表以字节为单位进行存储 (默认为0以字节为单位进行存储)
- CHARSET/UNICODE_FLAG:字符集选项。取值:0 代表 GB18030,1 代表 UTF-8,2 代表韩文字符集 EUC-KR。默认为 0。
通过这两个参数组合使用,具体存储方案如下所示:
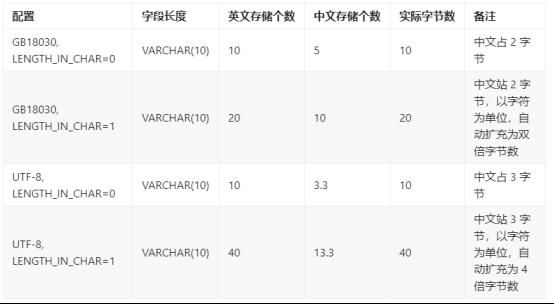
根据数据库初始化时的参数不同,字符串中能存储的汉字的个数也不相同,数据库一旦初始化完成,字符集就将无法修改。 通过语句查询数据库初始化参数:
- 创建数据库时 varchar类型以字符为单位
3.2 数值类型
- 精确数值数据类型:
NUMERIC、DECIMAL、DEC类型、NUMBER类型、、INTEGER 类型、INT 类型、BIGINT 类型、TINYINT 类型、BYTE 类型、SMALLINT 类型、BINARY 类型、VARBINARY 类型。
- 近似数值类型:
FLOAT 类型、DOUBLE 类型、REAL 类型、DOUBLE PRECISION 类型。
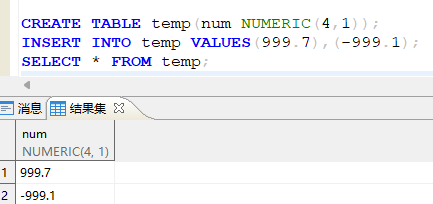
- NUMERIC [(精度[, 标度] )] :
MUNERIC 该数据类型用于存储零、正负定点数。 精度:精度是一个无符号整数,定义了总的数字数,精度范围是 1 至 38。标度:定义了小数点右边的数字位数。一个数的标度不应大于其精度,如果实际标度大于指定标度,那么超出标度的位数将会四舍五入省去。
3.3 时间日期类型
- 一般日期类型:
- DATE 类型包括 年、月、日信息;
- TIME 类型包括 时、分、秒信息;
- TIMESTAMP 类型 包括 年、月、日、时、分、秒 信息。
- 时间间隔数据类型:
DM数据库支持两类时间间隔类型:年-月 间隔类型 和 日-时 间隔类型,它们通过时间间隔限定符区分,前者结合了日期字段年和月,后者结合了时间字段日、时、分、秒。时间间隔数据类型所描述的值是有符号的。
3.4 多媒体数据类型
多媒体数据类型的字值由两种格式: 字符串格式、十六进制BINARY;
多媒体数据类型包括:
- TEXT / LONG / LONGVARCHAR 类型:变长字符串类型。其字符串的长度最大为 100G-1,用于存储长的文本串。
- IMAGE / LONGVARBINARY 类型:用于指明多媒体信息中的图像类型,长度最大为 100G-1 字节。
- BLOB 类型:用于指明变长的二进制大对象,长度最大为 100G-1 字节。
- CLOB 类型:用于指明变长的字母数字字符串,长度最大为 100G-1 字节。
- BFILE 类型:用于指明存储在操作系统中的二进制文件。
注:其中BLOB 和 IMAGE 类型的字段内容必须存储十六进制的数字串内容
四、达梦内置函数
4.1 数学相关函数:
-- 达梦数据库数值函数 --
-- 返回大于等于 n 的最小整数
SELECT CEIL(-15.6);
SELECT CEILING(15.6);
-- 返回小于等于 n 的最大整数值
SELECT FLOOR(-15.6);
-- ROUND(数值,小数位数,0/null则四舍五入) 数值类型进行四舍五入后的值,或直接进行截断后的值。
SELECT ROUND(12.452);
SELECT ROUND(14.116,2,1);
-- 截除小数点后数据
SELECT TRUNC(-41.23655,2);
SELECT TRUNCATE(1.325,1);
-- 求一个或多个数中最大的数
SELECT GREATEST(1.2,15,56,10,1.32);
SELECT GREAT (12,54);
-- 求一个或多个数中最小的一个。
SELECT LEAST(12,-4);
-- 返回一个[0,1]之间的随机浮点数。
SELECT RAND();
-- 正数返回1 负数返回-1
SELECT SIGN(-12);
-- 有一个参数为空则返回空,否则返回 n1 的值。
SELECT NANVL(84,12);
-- 类型转换类
-- 将数值类型的数据转化为 VARCHAR 类型输出
SELECT TO_CHAR(444);
SELECT TO_CHAR('453'+1);
-- 将 number、real 或 double 类型数值转换成 float 类型
SELECT TO_BINARY_FLOAT(23.25532333);
-- 将 number、real 或 float 类型数值转换成 double 类型
SELECT TO_BINARY_DOUBLE(12.6524133322);
-- 绝对值转换函数
SELECT ABS(-233);
- 随机生成id :
SELECT SYS_GUID(); - 字段求和并且转换类型
-- 1.通过 SUN(字段) 函数对字段进行求和
-- 2.然后 通过CAST( 数据 AS 转换类型) 对数据类型进行转换
CAST(SUM(字段) AS DECIMAL(20.2))
-- 这里的 DECIMAL(20.2) 类型 对应sqlserver中的 NUMERIC(20.2)类型! 总共有 20 位有效数字,其中有 2 位小数。
-- 达梦数据库中同样支持 NUMERIC 类型
CAST(SUM(字段) AS NUMERIC(20.2))
4.2 字符串函数
-- 达梦数据库字符串函数 --
-- 返回字符 char 对应的整数(ASCII 值)
SELECT ASCII('a');
-- 返回整数对应的字符
SELECT CHAR(120);
SELECT CHR(120);
SELECT NCHR(120);
-- 返回字符串 char 的长度,以字符作为计算单位,一个汉字作为一个字符计算。
SELECT CHAR_LENGTH('char测试');
SELECT CHARACTER_LENGTH('char测试 测试');
-- 返回给定字符串表达式的字符(而不是字节)个数,其中不包含尾随空格。
SELECT LEN('hi,你好 ');
--返回个数,其中包含尾随空格。
SELECT LENGTH('hi,你好 ');
SELECT LENGTHC('hi,你好 ');
SELECT LENGTH2('hi,你好 ');
SELECT LENGTH4('hi,你好 ');
-- 字符串 char 的长度,以字节作为计算单位
SELECT OCTET_LENGTH('大家好') "Length in bytes";
-- 比较两个字符串之间的差异,返回相同同一位置出现相同字符的个数。
SELECT DIFFERENCE('she', 'he');
-- 把字符串char1 从3开始后 1位 的字符 用char2 替换
-- 将字符串 char1 从 n1 的位置开始删除 n2 个字符,并将 char2 插入到 char1 中n1 的位置。
SELECT INS('char1',3,1,'char2');
SELECT INSERT('That is a cake',2,3, 'his') ;
SELECT INSSTR('That is a cake',2,3, 'his') ;
-- 返回字符串 char 最左边的 n 个字符组成的字符串
SELECT LEFT('HELLO WORLD',2);
SELECT LEFTSTR('HELLO WORLD', -2);
-- 返回字符串 char 在 str 中从位置 n 开始首次出现的位置。
SELECT LOCATE('man', 'The manager is a man', 10);
-- 返回 char 中从字符位置 m 开始的 n 个字符
SELECT SUBSTR('我们的计算机',3,4) "Subs";
SELECT SUBSTRB('我们的计算机',4,15);
-- 字符串顺序拼接
SELECT CONCAT('a','c','e');
-- 第一个字母改为大写
SELECT INITCAP('hello world');
-- 所有字母改为大写
SELECT UCASE('hello world');
SELECT UPPER('hello world');
-- 所有字母改为小写,不是字母的字符不受影响。
SELECT LCASE('ABC');
SELECT LOWER('ABC');
SELECT NLS_LOWER('AB CDe123');
-- 反转
SELECT REVERSE('abcd');
-- 将 VARCHAR、CLOB、TEXT 类型的数据转化为 VARCHAR 类型输出。
SELECT TO_CHAR('0110');
-- 返回 n1,n2 的比较结果,完全相等,返回 1;否则返回 0
SELECT TEXT_EQUAL('a', 'a');
SELECT BLOB_EQUAL(0xFFFEE, 0xFFFEE);
-- 判断表达式是否为NULL,为NULL返回1,否则返回0。
SELECT ISNULL('null');
SELECT ISNULL(null);
SELECT ISNULL(null,3);
SELECT IFNULL(NULL,3);
-- 将参数 value 转换为 type 类型返回。
SELECT CAST(100.5678 AS VARCHAR(8));
SELECT CAST(12345 AS char(5));
-- 【分组聚合函数】 无现有的!!!!
SELECT * FROM employees;
SELECT dept_id,
RTRIM(XMLAGG(XMLELEMENT(e, emp_name || ',')).EXTRACT('//text()').GetClobVal(),',') AS employees
FROM employees GROUP BY "dept_id";
-- 如果为true,返回 T 作为结果,否则返回 F。
SELECT if(TRUE,'T', 'F') result
-- 判断表达式是否为NULL,为NULL返回1,否则返回0。
SELECT ISNULL('null');
SELECT ISNULL(null);
SELECT ISNULL(null,3);
SELECT IFNULL(NULL,3);
-- 字符串替换函数
SELECT REPLACE('Hello World', ' ', '') AS NoSpaces;
- 去字符串空格函数:
-- 去除两边空格
SELECT TRIM(' Hello World ') AS TrimmedString;
-- 去除左边空格
SELECT LTRIM(' hi,你好 ');
-- 去除末尾空格
SELECT RTRIM(' hi,你好 ');
-- 去除中间空格数据
SELECT REPLACE('Hello World', ' ', '') AS NoSpaces;
-- 去除末尾空格后在计算长度!
SELECT LENGTH(LTRIM(' hi,你好 '));
- 判空函数 ISNULL、IFNULL 的使用
注意: ISNULL() 函数中可以只携带一个参数,但是 IFNULL(参数1,参数2) 就必须携带连个参数数据!
-- 判断表达式是否为NULL,为NULL返回1,否则返回0。
SELECT ISNULL('null');
SELECT ISNULL(null);
SELECT ISNULL(null,3);
SELECT IFNULL(NULL,3);
4.3 类型转换函数
-- 将参数 value 转换为 type 类型返回。
SELECT CAST(100.5678 AS VARCHAR(8));
SELECT CAST(12345 AS char(5));
- IIF 判断函数的替换
达梦数据库和人大金仓数据库中,IIF() 函数并不存在(存在 if(条件,‘true值’, ‘false值’)函数)。
也可以使用 CASE 语句来实现条件判断。CASE 是 SQL 标准的一部分,因此在多种数据库中都适用。
示例代码:
SELECT
CASE
--达梦数据库中支持 1为true 0为false
WHEN COUNT(1) THEN 'true'
ELSE 'false'
END AS RESULT
FROM ACT_RU_TASK WHERE ID_='004236ae-fd6b-11ec-b195-ecb1d7b4def0';
4.4 日期函数
select now(); -- 2024-06-25 09:51:35.051000
select current_date(); -- 2024-06-25
SELECT SYSDATE();
-- 时间格式
select to_char(now(),'yyyy');
select to_char(now(),'mm');
SELECT TO_CHAR(SYSDATE, 'YYYYMMDD');
select EXTRACT(YEAR from current_date);
select CAST(EXTRACT(month from current_date)AS INTEGER)
TO_CHAR(GETDATE(),'YYYY-MM-DD HH24:MI:SS')
4.5 其它类型
- 关于字符串的拼接方式
在DM数据库的SQL语句中,数据库之间进行拼接时,不能像 SQLSERVER 数据库一样直接使用 + ' '+ 的形式来拼接,而是采用 || 来进行拼接:
select gz.GSDM, gz.LBMC
-- 不支持直接使用 + 的形式来拼接数据
-- , (gz.LBDM + ' ' + gz.LBMC) as LB
, (gz.LBDM || gz.LBMC) as LB
, (gz.LBDM || ' ' || gz.LBMC) as LB2
, cast(sum(gz.SJTS) as NUMERIC(20, 2)) as SJTS
from GZ_GZDATA gz
group by gz.GSDM, gz.LBDM, gz.LBMC, gz.FFND, gz.FFYF, gz.FFYCS
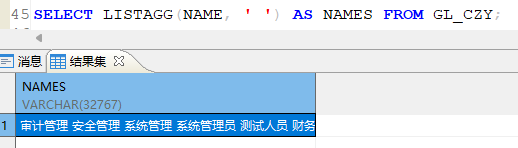
- 将查询结果中的值合并为一个字符串
使用函数 LISTAGG(字段名称,' 连接方式 '); 类似sqlserver中的 FOR XML PATH('') 语法
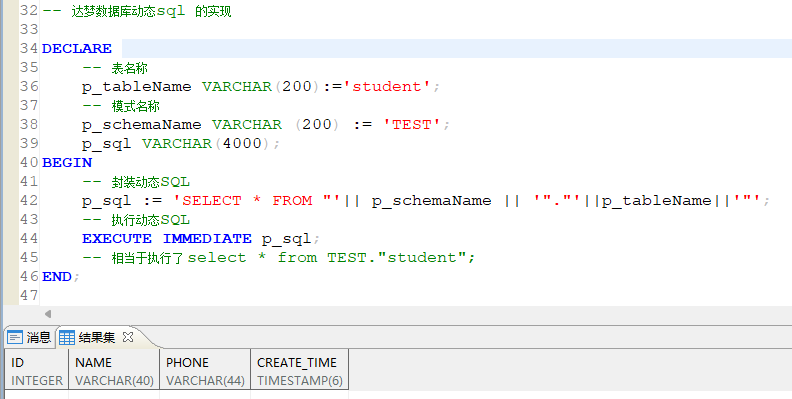
- 达梦数据动态SQL的实现
在达梦数据库中,您可以使用 EXECUTE IMMEDIATE 执行动态 SQL。
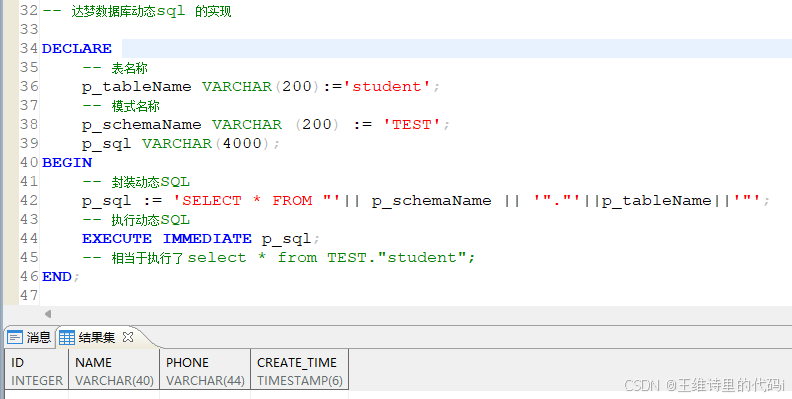
五、达梦数据库表操作
5.1 创建表格
- 创建基本表
语法和Mysql没用区别!唯一注意是 关键字采用的是 “关键字” ( Mysql 中关键字采用的是关键字 ),字符串采用的是’ 字符串 '!
CREATE TABLE product_class(
product_class_id INT PRIMARY KEY,
product_class_name VARCHAR(50) NOT NULL
);
CREATE TABLE product(
product_id INT PRIMARY KEY,
product_name VARCHAR(20) NOT NULL,
product_class_id INT NOT NULL FOREIGN KEY REFERENCES product_class(product_class_id),
product_price DOUBLE NOT NULL
);
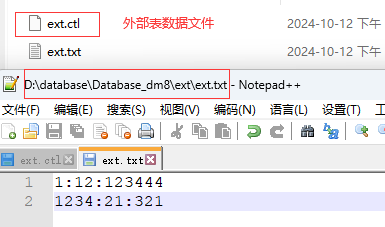
- 创建外部表
-
创建外部数据文件:xx.txt 文件,并输入数据内容:
-
创建数据控制文件:xx.ctl 文件,并输入文件内容:
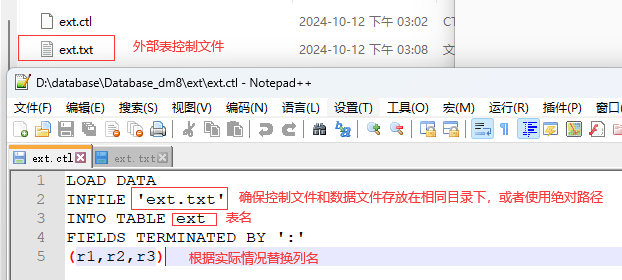
-
进入数据库中,创建外部表目录
使用语句进行创建CREATE DIRECTORY 目录名称 AS '外部表文件目录地址';
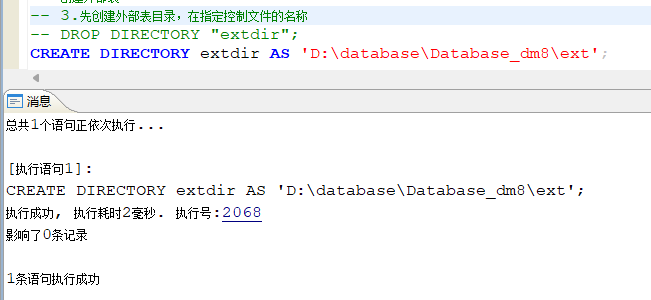
-
创建外部表并查询数据结果:
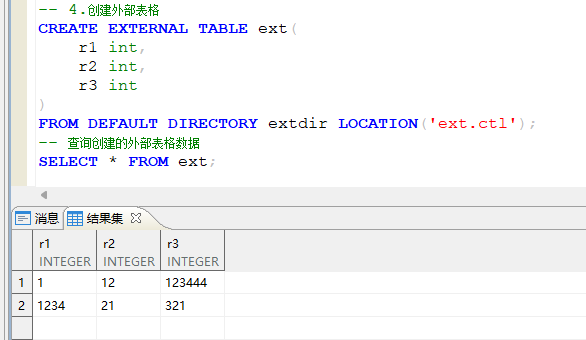
5.2 其它表操作
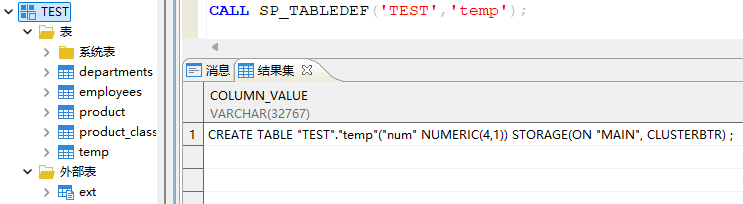
-
查看表结构:
CALL SP_TABLEDEF('模式名','表名');
-
TRUNCATE 语句删除所有表记录:TRUNCATE TABLE 表名;
-
删除表格:DROP TABLE 表名;
-
禁用/启用 表约束:
禁用表约束:ALTER TABLE 表明 DISABLE CONSTRATINT 约束名
启用表约束:ALTER TABLE 表明 ENABLE CONSTRATINT 约束名
5.3 临时表 TEMPORARY_TABLE
临时表在需要缓冲结果集中很有用,因为它是通过运行多个 DML 操作构建的。
临时表数据仅在事务或 会话期间存在。临时表中的数据是会话私有的。每个会话只能看到和修改自己的数据。
可以创建全局临时表 GLOBAL ( 表定义是持久的,表数据是临时的 ) 或者 局部临时表 LOCAL(默认,表定义和表数据都是临时的,会在会话退出后被删除)。简单来看全局临时表定义是持久的(除非显示的去删除它),而表数据是临时的,而本地临时表的表定义和表数据都是临时的,会在会话退出后被删除。
- 全局临时表 (GLOBAL TEMPORARY TABLE)
事务提交时删除行:当事务提交时,表中的所有行都会被删除,但表结构仍然存在。
会话结束时删除表:如果需要删除整个表结构,可以使用 DROP TABLE 语句。
- 局部临时表 (LOCAL TEMPORARY TABLE) (达梦数据库中不支持)
会话结束时删除表:当会话结束时,表结构及其所有数据都会被自动删除。
不需要手动删除表结构:局部临时表会在会话结束后自动清理,因此不需要手动删除。

- 临时表事务控制
临时表在一个事务块结束时的行为由** ON COMMIT **控制。三种选项:
- PRESERVE ROWS
表示在事务提交时,临时表中的数据将保持不变,直到会话结束。是本地临时表采用的默认行为。
适用于需要在同一会话中多次使用数据且想要保留数据的场景。这样一来,即使多次提交事务,数据依然可以被访问。
- DELETE ROWS
在每个事务块结束时,将删除临时表中的所有行数据。这是全局临时表的默认行为。
适用于需要在每个事务中处理数据但不需要在事务间保留数据的场景。即每个事务独立使用数据。
- DROP
在当前事务块结束时将删除临时表。
- 创建全局临时表
全局临时表是存储在磁盘上的永久数据对象。全局临时表的定于对所有会话都是可见的,但是全局临时表中的数据
只对向表中插入数据的会话可见。
语法;CREATE GLOBAL TEMPORARY/TEMP TABLE....
示例:
-- 创建局部临时表格
CREATE GLOBAL TEMPORARY TABLE TEMP_TABLE(
ID INTEGER,
NAME VARCHAR(400)
)ON COMMIT DELETE ROWS;
-- 插入数据到临时表中
INSERT INTO TEMP_TABLE (ID,NAME) SELECT ID,NAME FROM GL_CZY;
-- 查询临时表中的数据:
SELECT * FROM TEMP_TABLE;
-- 使用游标查询临时表中的数据:
DECLARE
TEMP_TABLE_CURSOR CURSOR IS SELECT * FROM TEMP_TABLE;
P_ID INTEGER;
P_NAME VARCHAR(500);
BEGIN
OPEN TEMP_TABLE_CURSOR;
LOOP
FETCH TEMP_TABLE_CURSOR INTO P_ID,P_NAME;
EXIT WHEN TEMP_TABLE_CURSOR%NOTFOUND;
SELECT P_ID AS "ID值", P_NAME AS "名称";
END LOOP;
CLOSE TEMP_TABLE_CURSOR;
END;
-- 删除创建的临时表
DROP TABLE TEMP_TABLE;
- 判断临时表是否存在:
-- 判断临时表是否存在!
BEGIN
IF EXISTS (
SELECT * FROM ALL_TABLES
WHERE TABLE_NAME='TEMP_TABLE' AND OWNER=(SELECT USER FROM DUAL)
)
THEN
SELECT '该表存在执行删除!';
EXECUTE IMMEDIATE 'DROP TABLE TEMP_TABLE';
ELSE
SELECT '该表不存在!';
EXECUTE IMMEDIATE'
CREATE GLOBAL TEMPORARY TABLE TEMP_TABLE(
ID INTEGER,
NAME VARCHAR(400)
)ON COMMIT DELETE ROWS;
';
END IF;
END;
示例代码:
DECLARE
P1 INT := 999;
P2 VARCHAR(200) := '小明';
BEGIN
-- 检查临时表是否存在
IF EXISTS (
SELECT 1 FROM ALL_TABLES
WHERE TABLE_NAME = 'TEMP_TABLE' AND OWNER = (SELECT USER FROM DUAL)
)
THEN
-- 表存在,执行删除
EXECUTE IMMEDIATE 'DELETE FROM TEMP_TABLE';
ELSE
-- 表不存在,创建临时表
EXECUTE IMMEDIATE '
CREATE GLOBAL TEMPORARY TABLE TEMP_TABLE (
id INT PRIMARY KEY,
name VARCHAR(100)
) ON COMMIT PRESERVE ROWS';
END IF;
-- 使用临时表
EXECUTE IMMEDIATE 'INSERT INTO TEMP_TABLE (id, name) VALUES (555, ''Alice''), (2222, ''Bob''), (' || P1 || ', ''' || P2 || ''')';
EXECUTE IMMEDIATE 'SELECT * FROM TEMP_TABLE';
END;
PS: 在达梦数据库中,PL/SQL 块的语法与 Oracle 数据库类似,但达梦数据库并不直接支持在 SQL 语句中混合使用 DDL(数据定义语言)和 PL/SQL 块的方式。
CREATE GLOBAL TEMPORARY TABLE 和 DROP TABLE 是 DDL 语句,而 BEGIN … END; 是 PL/SQL 块。这两者不能直接在同一个 SQL 语句中混合使用。
这就导致了 适配国产化数据库中,之前使用sqlserver数据库创建的 复杂嵌套sql语句没办法依旧使用临时表的方案来适配,需要将创建临时表、操作临时表和删除临时表分开定义。 这导致需要调整Service层接口调用的代码来调用多个接口分开执行!
如果不想改变原本Server层的代码结构,或者必须在 mybatis 的一个SELECT 标签中执行插入和查询。也可以在达梦中创建存储过程来解决上面问题,在数据库层面通过存储过程来实现,然后在 MyBatis 中调用这个存储过程。
5.4 临时表平替方案(WITH tableName AS)
在达梦数据库(DM Database)中,WITH 子句用于定义一个临时表(也称为 Common Table Expressions, CTE),可以在随后的查询中引用这个临时表。WITH 子句使得查询更加模块化和易读,尤其是在涉及复杂的嵌套查询时。
以下是 WITH 子句的基本用法示例:
WITH tempTable AS (
SELECT 列1, 列2, ...
FROM 表
WHERE 条件
)
SELECT *
FROM tempTable;
还可以在同一个 WITH 子句中定义多个 CTE,每个 CTE 用逗号分隔。
WITH
tempTable1 AS (
SELECT id, name, salary
FROM employees
WHERE department = '研发部'
),
tempTable2 AS (
SELECT id, name, salary
FROM employees
WHERE department = '销售部'
)
SELECT id, name, salary
FROM tempTable1
UNION ALL
SELECT id, name, salary
FROM tempTable2;
示例代码:
-- 测试Dm临时表的 平替方案 使用~
DECLARE
P1 VARCHAR := 'user1';
P2 VARCHAR := 'user2';
BEGIN
WITH
TABLE1 AS (
SELECT * FROM GL_CZY
),
TABLE2 AS (
SELECT * FROM PUBZYXX
)
SELECT 'TEST1表中数据' AS A,CZYCODE AS CODE ,NAME
FROM TABLE1 WHERE NAME= P1
UNION ALL
SELECT 'TEST2表中数据' AS A,ZYDM AS CODE ,ZYXM AS NAME
FROM TABLE2 WHERE ZYXM = P2;
END;
六、索引(INDEX)
创建索引会增加数据库系统开销,创建数据库索引注意一下几点:
- 经常用于查询的字段创建索引
- 经常用于连接的字段创建索引
- 经常需要根据范围来查询的列上创建索引
- 尽量不要在数据量很少的表上创建索引
- 尽量不要在数据取值区分度很小的列上创建缩影,如“性别”;
6.1 创建索引
-
创建普通索引
CREATE INDEX 索引名称 ON 表名称(字段名称); -
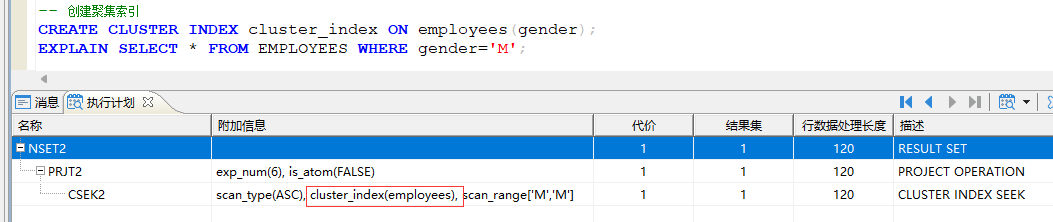
创建聚集索引:
CREATE CLUSTER INDEX 索引名称 ON 表名称(字段名称);
-
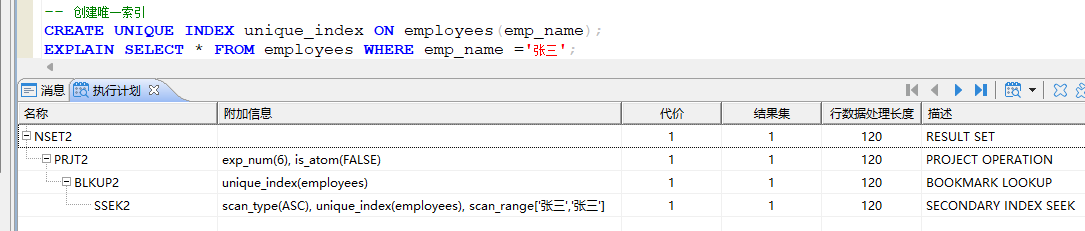
创建唯一索引:
CREATE UNIQUE INDEX 索引名称 ON 表名(字段名);
-
创建位图索引(位图索引与聚合索引不能构建在同一张表上):
CREATE BITMAP INDEX 索引名称 ON 表名称(字段);
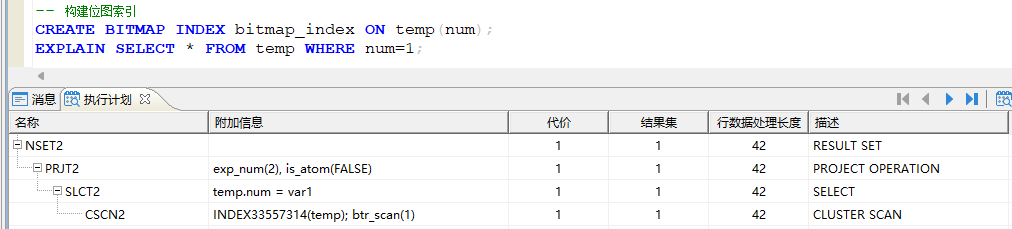
6.2 索引其它操作
-
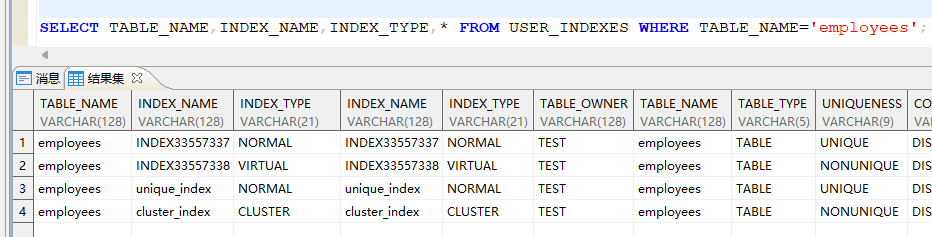
查看创建的索引:
通过字典表 **user_indexes **查看已创建索引的名称和类型。
SELECT table_name,index_name,index_type FROM USER_INDEXES WHERE index_name='索引名称';
-
删除索引:
DROP INDEX 索引名称;
6.3 索引管理指南
- 在插入数据后在创建索引
一般情况下,在插入或者加载数据之后,再为表创建索引会更有效率。因为数据库必须在插入每一行数据时更新索引,导致插入效率降低。
- 适合创建索引的表和列:
若干适合表和列创建索引的指导原则,可以通过下面原则来决定合适为表创建索引:
-
如果需要经常地检索大表中的少量的行,就为查询键创建索引;
-
为了改善多个表的连接的性能,可为连接列创建索引;
-
主键和唯一键自动具有索引,在外键上很多情况下也创建索引;
选择表中的索引列时可以参考以下几点原则,越多符合越适合作为索引列:
-
列中的值相对比较唯一;
-
取值范围大,适合建立索引 (适合普通索引);
-
列包含许多空值,但是查询通常会选择所有具有值的行。
反之,以下情况不应创建索引
- 如果该表频繁的进行 DML 操作,不应建立索引,或者建立少量索引;
- 有很多重复值的列,一般不建议作为索引列;
- 太小的表,不用建立索引,也没有必要。
- 排序索引列改善性能
在CREATE INDEX 语句中列的排序会影响查询的性能,通常将最常用的列放在最前面。
查询中有多个字段时,应创建组合索引,组合索引中当两个或者多个字段是等值查询时,索引列前后关系就无关紧要。
- 限制每个表的索引数量
表的索引数量是没有限制的,但是索引越多,修改表数据的开销就越大,占用的磁盘空间也越大。当插入或删除行时,表上的所有索引都要被更改;更改一个列时,包含该列的所有索引也要被更改。
- 删除不再需要的索引
当不在需要索引时,应及时将其清除。一方面能避免修改表数据的额外索引开销,另一方面也能减少 磁盘空间占用。
七、触发器(TRIGGER)
触发器(TRIGGER)定义当某些与数据库有关的事件发生时,数据库应该采取的操作。
只有具有创建触发器权限的用户或dba用户可以创建触发器,所以要想使用触发器必须具有创建触发器的权限(可以通过dba用户授予),执行触发器不需要授权,由系统自动触发执行。
触发器 trigger 语法:
CREATE [OR REPLACE] TRIGGER 触发器名称
-- 对触发器进行加密,其他人看不到触发器定义代码
[WITH ENCRYPTION]
-- 触发器执行时机,其中INSTEAD OF表示执行将替换原始操作,且不支持UPDATE触发
< BEFORE \ AFTER \ INSTEAD OF>
-- 触发事件,DML操作,可以用OR同时设置多个时机。
<INSERT \ DELETE \ UPDATE>
-- OF可以指定列名
[OF 字段名] ON 表名
-- 指明该触发器是元组级触发器(即行级)默认为表级
[FOR EACH ROW\STATEMENT]
BEGIN
触发器触发后执行的sql...
END;
7.1 触发器的分类
7.1.1表级触发器:
表级触发器都是基于表中数据的触发器,它通过针对相应表对象的插入/删除/修改等 DML 语句触发。
- 示例1:创建AFTER 触发器:向表A插入数据的同时向表B也插入数据
-- 创建 AFTER 触发器
CREATE OR REPLACE TRIGGER in_student_in_user
AFTER INSERT ON student
FOR EACH ROW
BEGIN
-- 向学生表中插入数据时,同时也向用户表中插入相应的信息;
INSERT INTO users(id,name) VALUES(:NEW.ID,:NEW.NAME);
END;
-- 测试触发器
INSERT INTO student VALUES(1,'zhangSan','133144',SYSDATE);
PS: **:NEW** 和 **:OLD**** **的作用:
- NEW 只出现在 INSERT 和 UPDATE 时;在 INSERT 时 NEW 表示新插入的行数据,UPDATE 时 NEW 表示要替换的新数据。
- OLD 只出现在 UPDATE 和 DELETE 时;在UPDATE 时 OLD 表示要被更改的原数据行,DELETE 时 OLD 表示要被删除的数据。
- 示例2:创建BEFORE,向表A插入数据时,修改数据 ID值
-- 创建触发器 before
CREATE OR REPLACE TRIGGER insertBe
BEFORE INSERT ON student
FOR EACH ROW
BEGIN
:NEW.id = :NEW.id +1;
END;
INSERT INTO student(id,name,phone) VALUES (2,'Before','123456');
- 示例3:创建 INSTEAD OF 触发器:
该触发器在动作触发的时候,替换原始操作,INSTEAD OF 允许建立在视图上,并且只支持行级触发。
-- 创建表视图,用于测试 INSTEAD触发器
CREATE VIEW v_student AS SELECT * FROM student;
-- 创建 instead of 触发器
CREATE OR REPLACE TRIGGER instead_test
INSTEAD OF UPDATE ON v_student
BEGIN
-- 替换原来的操作
INSERT INTO v_student VALUES(:NEW.id,'instead','133144',SYSDATE());
END;
-- 测试触发器
UPDATE v_student set id=1 where id=3;
7.1.2 时间触发器
时间触发器属于一种特殊的事件触发器,可以定义一些有规律性执行的、定点执行的任务。
- 示例:创建时间触发器,定时输出数据
-- 时间触发器:
CREATE OR REPLACE TRIGGER time_trigger
AFTER TIMER ON DATABASE
FOR EACH 1 DAY FOR EACH 1 MINUTE
BEGIN
PRINT SYSDATE()+'时间触发器!';
END
7.2 触发器管理 TRIGGER
-
查看触发器:
查看当前用户所拥有的触发器:SELECT * FROM USER_TRIGGERS;
查看当前用户有权限访问的触发器:SELECT * FROM ALL_TRIGGERS;
查看当前数据库全部触发器:SELECT * FROM DBA_TRIGGERS; -
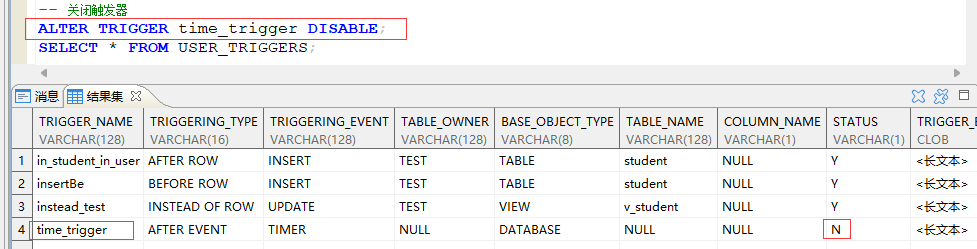
开关触发器:
每个触发器创建成功后都自动处于允许状态 (ENABLE),当不想被触发,但是又不想删除这个触发器。这时,可将其设置关闭触发器 (DISABLE)
ALTER TRIGGER 触发器名称 <DISABLE / ENABLE>;
- 删除触发器:
DROP TRIGGER [ IF EXISTS ] 触发器名称;
八、视图(VIEW)
视图是关系数据库系统提供给用户以多种角度观察数据库中数据的重要机制,它简化了用户数据模型,提供了逻辑数据独立性,实现了数据共享和数据的安全保密
CREATE [OR REPLACE] VIEW [<模式名>.]<视图名称>
AS <查询说明>
物化视图可以用于数据复制(Data Replication),也可用于数据仓库缓存结果集以此来提升复杂查询的性能
8.1 视图的分类
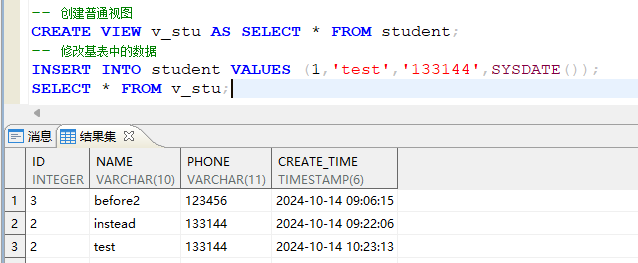
- 简单视图:
视图可以通俗的理解为用户通过定义自己所特定需求而提前写好的sql语句,视图中的数据来自基表(查询语句所查询的一张表或多张表),基表数据改变视图数据也跟着改变。
- 复杂视图
由两张或两张以上的表导出时可以称作是复杂视图,复杂视图不允许直接 DML,也就是说复杂视图不允许更新!
- 物理视图
数据要单独存储,占用磁盘空间,规划表空间。物化视图的数据来自于基表,基表发生的变化,物化视图可以根据更新方式来进行数据更新,更新方式可分为手动(默认)和自动,自动又分成快速(fast)、完全(complete)、选择(force)、不更新(never)!
8.2 视图管理
- 查看用户创建的视图:
SELECT VIEW_NAME,TEXT,* FROM USER_VIEWS; - 删除视图:
DROP VIEW 视图名称;
九、变量的声明与使用
9.1 达梦中变量的使用语法
在达梦数据库中,关于变量的设置贵如下:
DECLARE variable1 VARCHAR(20) ; [ variable2 INT;]
[直接赋值 variable3 INT:= 5;]
BEGIN
variable1 := 变量赋值;
[variable1 := 变量赋值;]
其它Sql语句
END
在sql中 对声明的变量进行赋值时,采用的是SELECT … INTO 关键字 来进行赋值; 或者是直接使用 := 对变量进行赋值;示例:
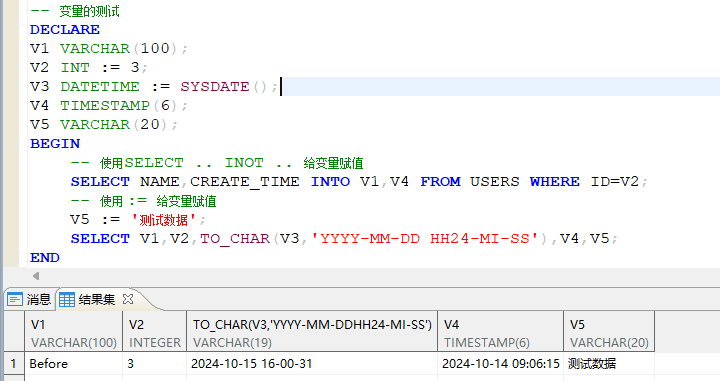
ps:其它赋值方式
通常情况下,在 PL/SQL 语言的标准用法中,应该使用** := 来给变量赋值**。然而,达梦数据库的实现可能允许某些习惯上不常见的语法,比如达梦数据库对 SET 的支持。
但这并不是标准 PL/SQL 的常规做法。为了保持代码的规范,建议使用 := 进行赋值,这样能提高代码的可读性和可维护性。
示例: 使用 SET 为变量赋值!
P_DATE VARCHAR(20) :='';
BEGIN
IF P_DATE IS NULL OR P_DATE ='' THEN
-- SET P_DATE = REPLACE(TO_CHAR(SYSDATE,'YYYYMMDD'),'-','');
P_DATE := REPLACE(TO_CHAR(SYSDATE,'YYYYMMDD'),'-','');
END IF;
SELECT P_DATE AS "TIME";
END;
9.2 PL\SQL(达梦)中异常捕获
BEGIN
-- 语句块中的异常捕获
EXCEPTION
--处理没有数据找到的异常!
WHEN NO_DATA_FOUND THEN
[执行其它SQl.....]
--处理其它异常
WHEN OTHERS THEN
--重新抛出异常,或返回一个特定的错误值
RAISE;
END
9.3 PL\SQL(达梦)事务使用
BEGIN
-- 开启事务
SAVEPOINT transactionName
BEGIN
[执行其它sql...]
-- 使用异常捕获
EXCEPTION
WHEN OTHERS THEN
-- 发生异常后执行事务的回滚
ROLLBACK TO transactionName;
-- 可以抛出异常 RAISE;
END;
-- 提交事务
COMMIT;
END
示例代码1:
DECLARE
p_hasaccesstoken INT := 0;
p_accesstoken VARCHAR2(1000);
p_accesstoken_date VARCHAR2(30);
v_tran_error INT:=0;
v_errmsg VARCHAR(500) := '';
BEGIN
--设置传入参数数据:
--accesstoken := :accesstoken;
--accesstoken_date := :accesstoken_date;
p_accesstoken := 'AA';
p_accesstoken_date := 'DD';
-- 开始事务
SAVEPOINT setwxqyhaccesstiken;
BEGIN
SELECT COUNT(1) INTO p_hasaccesstoken FROM WXSP_GZZD_ACCESSTOKEN WHERE THREELOGINTYPE = 'wxqyh';
IF p_hasaccesstoken <=0 THEN
INSERT INTO WXSP_GZZD_ACCESSTOKEN (ID,ACCESSTOKEN,ACCESSTOKEN_DATE,THREELOGINTYPE)
VALUES (SYS_GUID(),p_accesstoken,p_accesstoken_date,'wxqyh');
ELSE
UPDATE WXSP_GZZD_ACCESSTOKEN SET ACCESSTOKEN=p_accesstoken,ACCESSTOKEN_DATE = p_accesstoken_date
WHERE THREELOGINTYPE='wxqyh';
END IF;
--模拟抛出异常
--RAISE NO_DATA_FOUND;
-- 异常捕获
EXCEPTION
WHEN OTHERS THEN
v_tran_error := v_tran_error + 1;
v_errmsg := '设置企业微信access_token发生异常!';
ROLLBACK TO setwxqyhaccesstiken;
END;
-- 提交事务!
COMMIT;
SELECT v_tran_error ERRCODE,v_errmsg ERRMSG;
SELECT * FROM WXSP_GZZD_ACCESSTOKEN;
END;
示例代码2:
declare
P_PHONE varchar(100) := '13595205638'; --#{phone};
P_LOGINYZM varchar(100) := '1234'; --#{loginyzm};
P_SAVETIME varchar(20) := '123456'; --#{savetime};
P_INVALIDTIME varchar(20) :='20'; --#{invalidtime};
P_TRAN_ERROR int := 0;
BEGIN
-- 开启事务
SAVEPOINT transactionTemp;
BEGIN
insert into gzzd_wxlogin_yzm(ID,phone,savetime,invalidtime,loginyzm)
values(SYS_GUID(),P_PHONE,P_SAVETIME,P_INVALIDTIME,P_LOGINYZM);
-- 手动模拟异常发生(违反列[ID]非空约束)
--insert into gzzd_wxlogin_yzm(ID,phone,savetime,invalidtime,loginyzm) VALUES(NULL,NULL,NULL,NULL,NULL);
-- 异常捕获( 放在事务内部,否则执行完毕之后最后的输出语句不会执行 )
EXCEPTION
WHEN OTHERS THEN
P_TRAN_ERROR := P_TRAN_ERROR+1;
END;
-- 判断事务执行情况
IF(P_TRAN_ERROR > 0) THEN
ROLLBACK TO transactionTemp;
ELSE
COMMIT;
END IF;
-- 查询结果
SELECT P_TRAN_ERROR;
END;
9.4 数据未找到(-7065)异常处理
在 DQL 语句中使用 INTO 关键字为变量进行赋值,如下:
DECLARE v1 VARCHAR(100);
BEGIN
SELECT field1 INTO v1 FROM table1 WHERE ...条件...;
-- 其它 DQL 语句!
END;
当使用 SELECT … INTO 语句进行变量赋值时,如果没有查询到数据,会报错并返回 “-7065: 数据未找到” 的错误(异常)信息。

而在 SQLSERVER 中,出现未查询到数据时,会默认将NULL 赋值给对应变量,而不是抛出异常信息!
为了避免这种情况,可以采取以下几种方法进行处理:
- 使用 EXISTS 先判断数据是否存在
在执行 SELECT … INTO 之前,可以先检查数据是否存在,确保赋值时不会出现错误。示例:
DECLARE v1 VARCHAR(100);
BEGIN
IF EXISTS (SELECT 1 FROM table1 WHERE ...条件...) THEN
SELECT field1 INTO v1 FROM table1 WHERE ...条件...
ELSE
v1 := NULL; -- 或者给这个变量赋其他默认值
END IF;
-- 其它 DQL 语句!
END;
- 使用异常处理
在 PL/SQL 块中包装查询语句,并使用异常处理来捕获没有数据的情况:
DECLARE v1 VARCHAR(100);
BEGIN
SELECT field1 INTO v1 FROM table1 WHERE ...条件...;
-- 使用异常捕获
EXCEPTION
WHEN NO_DATA_FOUND
THEN v1 := NULL; -- 或者给这个变量赋其他默认值
-- 其它 DQL 语句!
END;
十、PL/SQL的控制结构
目前达梦数据库支持 PL/SQL的控制结构,主要由三种:选择结构、循环结构、跳转结构。
10.1 选择结构
选择结构主要包含 IF语句和 CASE语句;
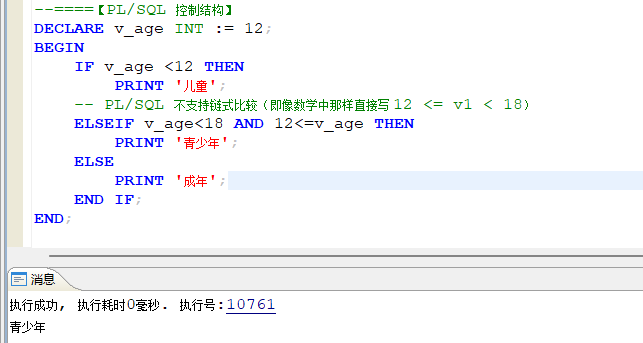
- IF语句 选择结构:
IF condition1 THEN statements1
[ELSEIF condition2 THEN statements2;]
......
[ELSE statements;]
END IF;
IF语句中的条件语句(condition部分) 是一个布尔类型变量或者表达式,取值只能是 true、false、null 。
PS: 在PL/SQL 块中编写 condition 的条语句时,需要注意PL/SQL中是不支持链式编程的,需要使用 AND 或者 OR 来连接多个条件后组成condition。
示例代码:
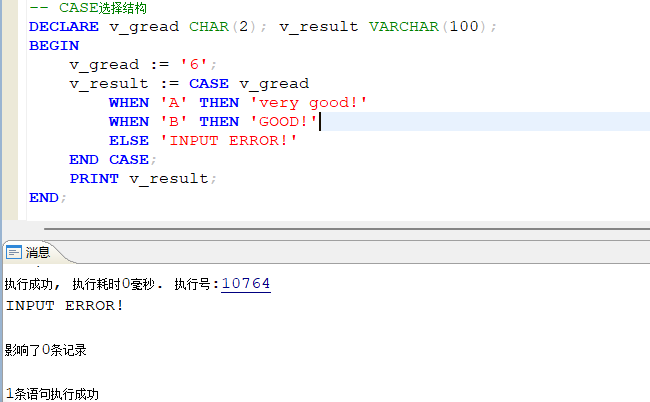
- CASE语句 选择结构:
CASE test_value
WHEN V1 THEN statements1
WHEN V2 THEN statements2
......
[ELSE statements]
END CASE;
该选择结构,对应不同的条件,返回不同的结果,示例代码如下:
方式二:
CASE WHEN 布尔类型
THEN 为真时的值
ELSE 为假时的值
END [CASE];
-- 这里末尾可以不加CASE 即可实现 CASE语句块的结束!
-- 在kingbaseEs数据库中 END 后面不支持使用 CASE,所以这里为了代码一致就采用 END 后面不添加 CASE!
示例2:
DECLARE
P_DATE VARCHAR(20) :='';
p_boole int :=1;
BEGIN
IF P_DATE IS NULL OR P_DATE ='' THEN
--SET P_DATE = REPLACE(TO_CHAR(SYSDATE,'YYYYMMDD'),'-','');
P_DATE := REPLACE(TO_CHAR(SYSDATE,'YYYYMMDD'),'-','');
END IF;
SELECT P_DATE AS "TIME",
CASE WHEN p_boole THEN '值为1' ELSE '值为2' END AS "判断值";
END;
10.2 循环结构
循环结构主要用到的有** LOOP 基本循环**、WHILE循环、FOR循环语句。
- LOOP循环 基本用法:
LOOP
循环体内执行的语句;
EXIT [WHEN condition]; -- 退出循环的条件
END LOOP;
- WHILE循环 语法:
WHILE condition LOOP
循环体内执行的语句;
END LOOP;
- FOR循环 基本语法:
FOR loop_counter IN [REVERSE] low_bound..high_bound LOOP
-- 循环体代码
END LOOP;
- loop_counter:循环控制变量PL/SQL 会自动声明它的类型。它将在每次循环中取值。
- REVERSE:这是可选的关键词,如果指定了 REVERSE,则循环会从 high_bound 开始递减到 low_bound。
- low_bound:循环的下限。
- high_bound:循环的上限。
[退出循环操作] :在 PL/SQL 中,循环结构会使用 EXIT 语句来退出循环。可以通过设置特定条件来控制何时退出循环。(在SQLSERVER数据库中 ,跳出循环使用的关键字为 break )!
- 使用 LOOP … END LOOP 跳出循环!
DECLARE
v_counter INT := 0;
BEGIN
LOOP
v_counter := v_counter + 1;
SELECT ('Counter: ' || v_counter);
-- 当计数达到5时退出循环
IF v_counter = 5 THEN
EXIT; -- 退出循环
END IF;
END LOOP;
END;
- 使用 WHILE … LOOP 跳出循环!
DECLARE
v_counter INT := 0;
BEGIN
WHILE v_counter < 5 LOOP
v_counter := v_counter + 1;
SELECT ('Counter: ' || v_counter);
-- 还可以使用 EXIT 语句退出,比如根据某个条件
IF v_counter = 3 THEN
EXIT; -- 强制退出循环
END IF;
END LOOP;
END;
- 使用 FOR … LOOP 跳出循环!
DECLARE
v_total INT := 0;
BEGIN
FOR i IN 1..10 LOOP
v_total := v_total + i;
-- 当总计达到15时退出循环
IF v_total >= 15 THEN
EXIT; -- 退出循环
END IF;
END LOOP;
SELECT ('Total: ' || v_total);
END;
10.3 跳转结构
条状结构使用的是 GOTO语句;基本语法如下:
LABEL_NAME(标签名)
...
GOTO LABEL_NAME
GOTO跳转语句,有一定限制:
块(BLOCK) 内可以跳转,内层块可以跳到外层块,但外层块不能跳到内层中;
IF语句不能跳入,不能从循环体外跳入循环体内。不能从子程序外部跳到子程序中;
十一、存储过程/存储函数:
11.1 存储过程(PROCEDURE)
- 存储过程的创建:
CREATE OR REPLACE PROCEDURE 存储过程名称(
参数1 IN 参数1类型,
参数2 OUT 参数2类型
) AS
BEGIN
-- 存储过程的主体
-- 可以包含 SQL 语句、变量定义等
[EXCEPTION
-- 异常处理 (可以省略...)
WHERE 异常名称 THEN
-- 处理逻辑]
END 存储过程名称;
存储过程创建示例:
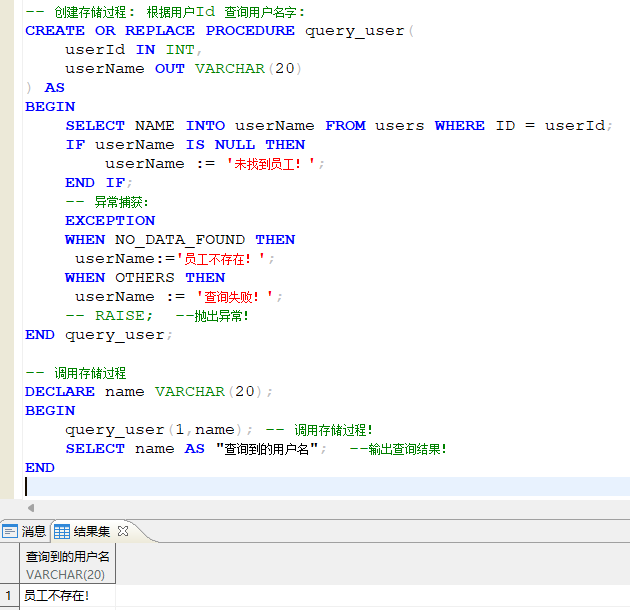
在执行存储过程时,如果存储过程中含有返回值,则需要创建一个对应类型的变量来接收执行逻辑的返回数据,然后该变量会返回到调用的地方!
- 存储过程的管理:
- 查看存储过程:
SELECT * FROM user_procedures WHERE object_name = '存储过程名称'; - 存储过程的修改:
创建时使用 OR REPLACE .... - 存储过程的删除:
DROP PROCEDURE 存储过程名称;
十一、存储过程/存储函数:
11.1 存储过程(PROCEDURE)
- 存储过程的创建:
CREATE OR REPLACE PROCEDURE 存储过程名称(
参数1 IN 参数1类型,
参数2 OUT 参数2类型
) AS
BEGIN
-- 存储过程的主体
-- 可以包含 SQL 语句、变量定义等
[EXCEPTION
-- 异常处理 (可以省略...)
WHERE 异常名称 THEN
-- 处理逻辑]
END 存储过程名称;
存储过程创建示例:
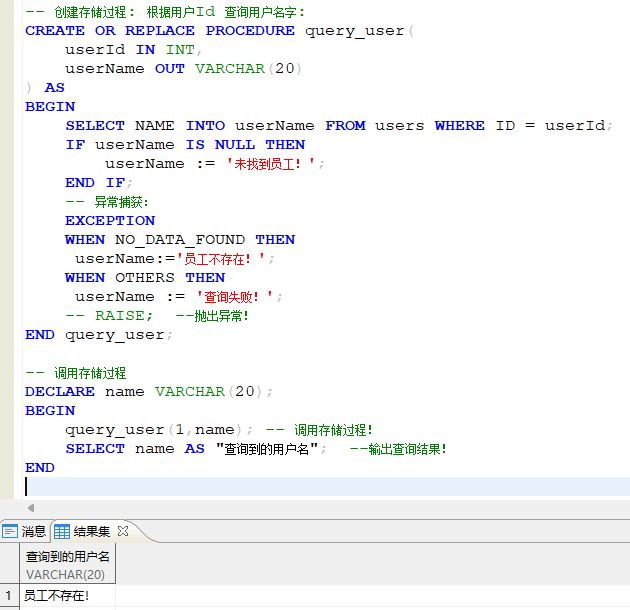
在执行存储过程时,如果存储过程中含有返回值,则需要创建一个对应类型的变量来接收执行逻辑的返回数据,然后该变量会返回到调用的地方!
- 存储过程的管理:
- 查看存储过程:
SELECT * FROM user_procedures WHERE object_name = '存储过程名称'; - 存储过程的修改:
创建时使用 OR REPLACE .... - 存储过程的删除:
DROP PROCEDURE 存储过程名称;
11.2 存储函数(FUNCTION)
- 存储函数的创建:
-- 存储函数-FUNCTION 定义模板:
CREATE OR REPLACE FUNCTION 函数名称(
参数1 IN 参数1类型,
参数2 IN 参数2类型
)RETURN 返回值类型 AS
-- 局部变量的声明
变量1 变量类型;
BEGIN
-- 函数主体逻辑,可包含一些 SQL 查询或其它逻辑,将结果赋值给变量
RETURN 变量1; --返回最终结果!
-- 异常捕获模块(可以省略.... )
[
EXCEPTION
WHEN NO_DATA_FOUND THEN --处理没有数据找到的异常!
RETURN NULL;
WHEN OTHERS THEN --处理其它异常
RAISE; --重新抛出异常,或返回一个特定的错误值
]
END 函数名;
存储函数示例:
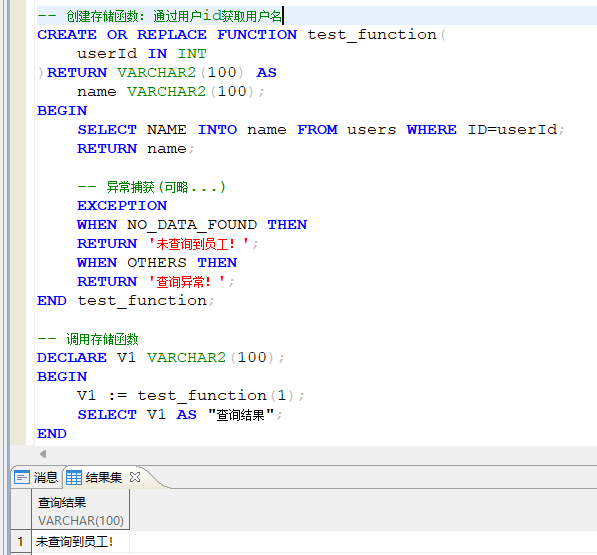
- 存储函数的管理:
- 删除操作:
DROP FUNCTION 函数名; - 查询存储函数:
SELECT * FROM user_procdures WHERE object_type ='FUNCTION';
查询方法和存储过程PROCEDURE 都是存储在同一张表中的,只是两种类型不同:
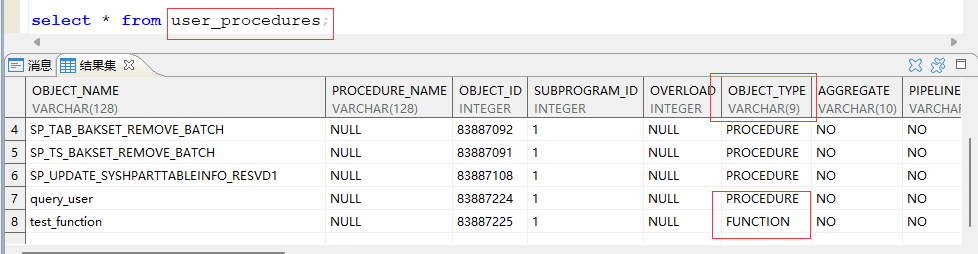
- 通过 user_source 视图来查看存储函数的源代码:
SELECT text,* FROM user_source;
十二、游标 CURSOR
游标是SQL的一个内存工作区,由系统或用户以变量的形式定义。游标的作用就是将从数据库中提取的数据块,临时存储到计算机内存中进行处理,从而提高数据处理速度,最后将处理结果显示出来或最终写回数据库,提高数据处理的效率。
达成梦数据库中的游标分为静态游标和动态游标,其中静态游标又可分为显式游标和隐式游标。
12.1 静态游标
静态游标是只读游标,它总是按照打开游标时的原样显示结果集,在编译时就能确定静态游标使用的查询。
- 隐式游标
每当用户在执行一个 DML语( INSERT、UPDATE、DELETE ) 或者是 SELECT…INTO… 语句时,DMSQL 程序都会自动声明一个隐式游标并管理这个游标。隐式游标不必专门去声明,数据库会自动为我们完成:定义、打开、取值、关闭等操作!
隐式游标的名称为"SQL",用户可以通过隐式游标获取语句执行的一些信息。达梦数据库中每个游标都有 %FOUND、%NOTFOUND、%ISOPEN、%ROWCOUNT 四个属性,对应 隐式游标,这四个属性的意义如下:
- %FOUND:语句是否修改或者查询到了记录,是返回true,否返回false;
- %NOTFOUND :语句是否未能成功修改或者查询到记录,是返回true,否返回false;
- %ISOPEN:游标是否打开。由于系统在执行完语句之后会自动关闭隐式游标,因此隐式游标的 %ISOPEN属性永远为 FALSE;
- %ROWCOUNT:DML 语句执行后影响的行数,或者是 select…into 语句返回的行数。
示例1:隐式游标的 %FOUND 属性,使用示例:
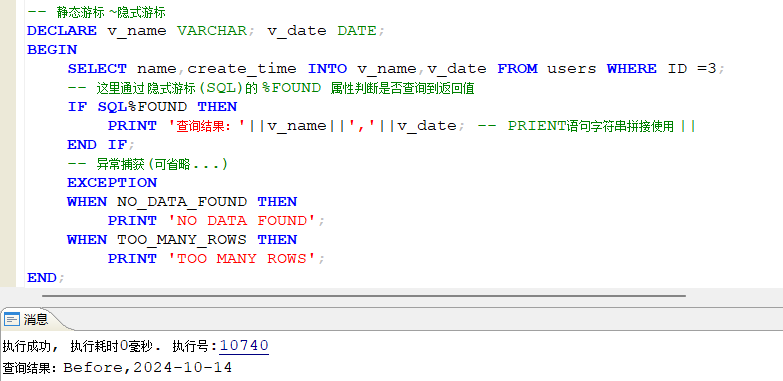
隐式游标使用上较为方便,省去了游标定义、打开、关闭等操作,但是使用场景上有局限性,程序中限于 INSERT、UPDATE、DELETE、SELECT…INTO 等语句。
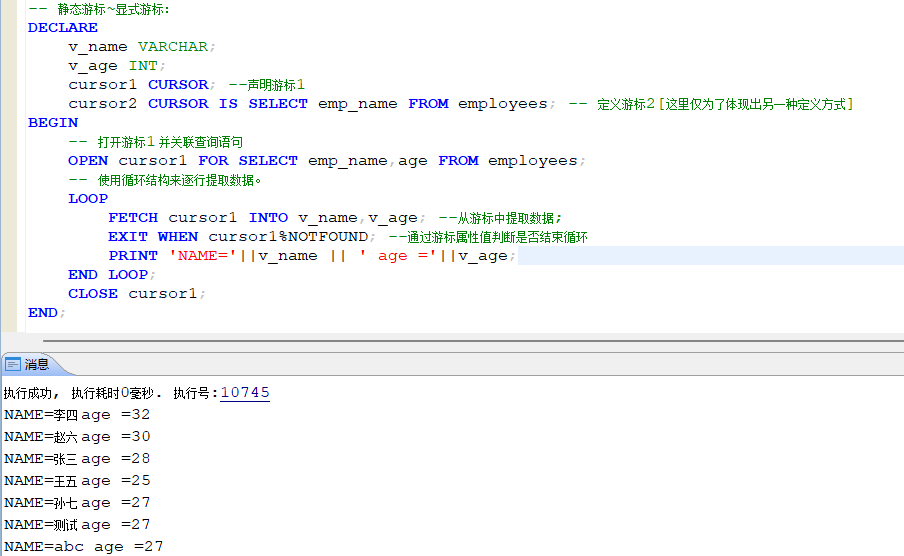
- 显式游标
显式游标指向一个查询语句执行后的结果集区域。当需要处理返回多条记录的查询时,应显式地定义游标以处理结果集地每一行。
使用显式游标一般步骤:
1. 定义游标:在程序的声明部分定义游标,声明游标及其关联的查询语句;
2. 打开游标:执行游标关联的语句,将查询结果装入游标的工作区,将游标定位到结果集的第一行之前;
3. 拔动游标:根据应用需求将游标位置移动到结果集的合适位置;
4. 关闭游标:游标使用完后关闭,以释放其占有的资源。
-- 1.声明游标
DECLARE 游标名 CURSOR FOR/IS 查询语句;
-- 2.打开游标
OPEN 游标名;
-- 3.提取数据
FETCH 游标名 INTO 变量1,变量2,...;
-- 4.关闭游标
CLOSE 游标名;
-- 5.释放游标(游标在 CLOSE 后会自动释放资源。DEALLOCATE CURSOR 一般用于动态游标,或者在需要显式释放游标资源的情况下使用。)
DEALLOCATE CURSOR 游标名;
示例:显式游标的使用例子:
- UNION 关键字的使用示例:
ps: UNION ALL 关键字可以解决 mapping.xml 文件中无法创建使用临时表的问题,采用 UNION ALL 关键字方案解决!!!
PS:UNION 是一种用于合并两个或多个 SELECT 语句结果集的操作符。使用 UNION 时,要求每个 SELECT 语句必须返回相同数量的列,并且对应的列数据类型要兼容。
在达梦数据库(DM)和人大金仓数据库(KingbaseES)中,UNION 操作的语法与 SQL Server 中是相同的。可以使用** UNION** 或 UNION ALL 来合并两个或多个 SELECT 语句的结果集。以下是使用 UNION 的基本示例和注意事项。
-- UNION 默认会去掉重复的记录
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2;
-- 如果你想保留所有记录(包括重复的),可以使用 UNION ALL!
SELECT column1, column2 FROM table1
UNION ALL
SELECT column1, column2 FROM table2;
-- *注意:第一条查询语句末尾不要加;直接连接 UNION 关键字!!
示例代码:
DECLARE
p_assignee VARCHAR(255);
BEGIN
-- 声明游标
DECLARE cur CURSOR FOR
SELECT USER_ID_ AS ASSINGEE FROM ACT_HI_IDENTITYLINK WHERE USER_ID_ IS NOT NULL AND
PROC_INST_ID_ = 'fa15d3c8-09bc-11ee-a8da-ecb1d7b4def0'
-- UNION 是一种用于合并两个或多个 SELECT 语句结果集的操作符。使用 UNION 时,要求每个 SELECT 语句必须返回相同数量的列,并且对应的列数据类型要兼容。
UNION
SELECT CAST(CZYID AS VARCHAR(255)) AS ASSINGEE FROM GL_CZY_ROLE WHERE ROLEID ='443';
BEGIN
-- 打开游标
OPEN cur;
-- 提取数据
FETCH cur INTO p_assignee;
-- 处理数据: 可以使用 WHILE 循环来逐行处理数据,直到游标中的数据处理完毕。
WHILE(cur%FOUND) LOOP
SELECT p_assignee,(cur%FOUND) AS "结果1",(cur%NOTFOUND) AS "结果2";
FETCH cur INTO p_assignee;
END LOOP;
SELECT p_assignee,(cur%FOUND) AS "最后一次结果1",(cur%NOTFOUND) AS "最后一次结果2";
-- 关闭游标
CLOSE cur;
END;
END;
扩展:可以观察 %FOUND 和 %NOTFOUND 值的变变化 利用到 WHILE 循环中处理数据!


- 游标中退出循环操作
在游标中,使用了WHILE 循环来逐行处理数据时,当满足要求需要退出游标时,可以使用 EXIT 关键字进行退出操作(在sqlserver数据库中使用的是 break 关键字)!
示例代码如下:
-- 创建游标
DECLARE cursorQueryLastAssignee CURSOR IS
SELECT ASSIGNEE_ FROM ACT_HI_TASKINST WHERE PROC_INST_ID_ = 'P_PROCINSTID' ORDER BY START_TIME_ DESC;
BEGIN
-- 打开游标
OPEN cursorQueryLastAssignee;
-- 提取数据
FETCH cursorQueryLastAssignee INTO P_LASTASSIGNEE;
--使用 while循环 处理数据
WHILE(cursorQueryLastAssignee%FOUND)LOOP
P_I := P_I +1;
SELECT P_LASTASSIGNEE,P_I;
IF(P_I =1 AND P_LASTASSIGNEE IS NOT NULL) THEN
EXIT; -- 使用 EXIT 退出循环
END IF;
FETCH cursorQueryLastAssignee INTO P_LASTASSIGNEE;
END LOOP;
-- 关闭游标!
CLOSE cursorQueryLastAssignee;
END;
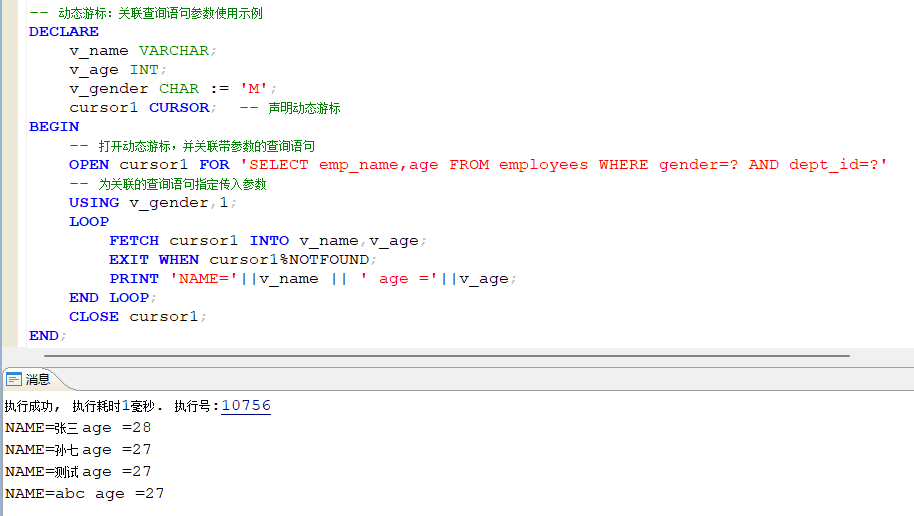
12.2 动态游标
动态游标指,在声明部分只是先声明一个游标类型的变量,并不指定其关联的查询语句,在执行部分打开游标时才指定查询语句。动态游标的使用主要在定义和打开时与显式游标不同。 上例中的 cursor1 就是一个动态游标,cursor2是一个显式游标。
动态游标关联的查询语句还可以带有参数数据,参数以"?" 指定,同时在打开游标语句中使用USING 子句指定参数,且参数的个数和类型与语句中的"?"必须匹配。
示例:动态游标参数使用示例:
十三、SpringBoot 集成DM数据库
13.1 项目引入Jar包(两种方式)
目前在 Maven 中央仓库中并没用 达梦数据库驱动的依赖可以下载,只能通过手动方式将 jar包 对应的 驱动Jar包引入到项目中。
在安装完达梦数据库后,在安装路径下 (**\dmdbms\drivers\jdbc) 可以找到对应的 Jar 包:
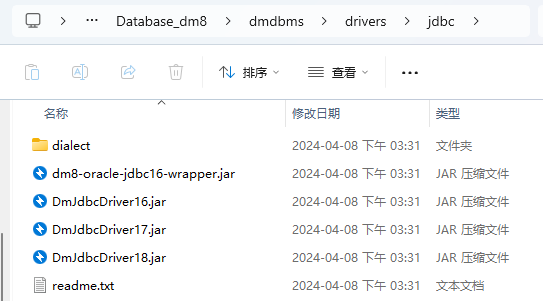
对应 JDK 版本对应使用 Jar包 如下,拿到对应的 Jar 包后,将Jar包导入到项目中:
/***************************************
- 达梦8 JDBC驱动版本说明
/***************************************
DmJdbcDriver16 对应 Jdk1.6 及以上环境
DmJdbcDriver17 对应 Jdk1.7 及以上环境
DmJdbcDriver18 对应 Jdk1.8 及以上环境
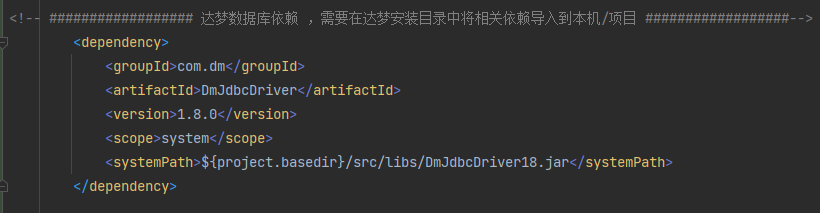
- 方式一 :将Jar包放入项目目录中,pom文件直接引用:
- 在项目的根目录下创建 lib 文件夹,将对应版本的Jar包放入
- 在项目的pom 文件中 导入达梦数据库驱动
- 方式二: 通过Maven 命令将Jar包安装到本地仓库后,在通过pom文件引用:
- 在cmd窗口( 或者在 IDEA中操作 )使用命令将 Jar 安装到本地仓库:
使用命令:mvn install:install-file -DgroupId=com.dm -DartifactId=DmJdbcDriver -Dversion=1.8.0 -Dpackaging=jar -Dfile=D:\database\Database_dm8\dmdbms\drivers\jdbc\DmJdbcDriver18.jar
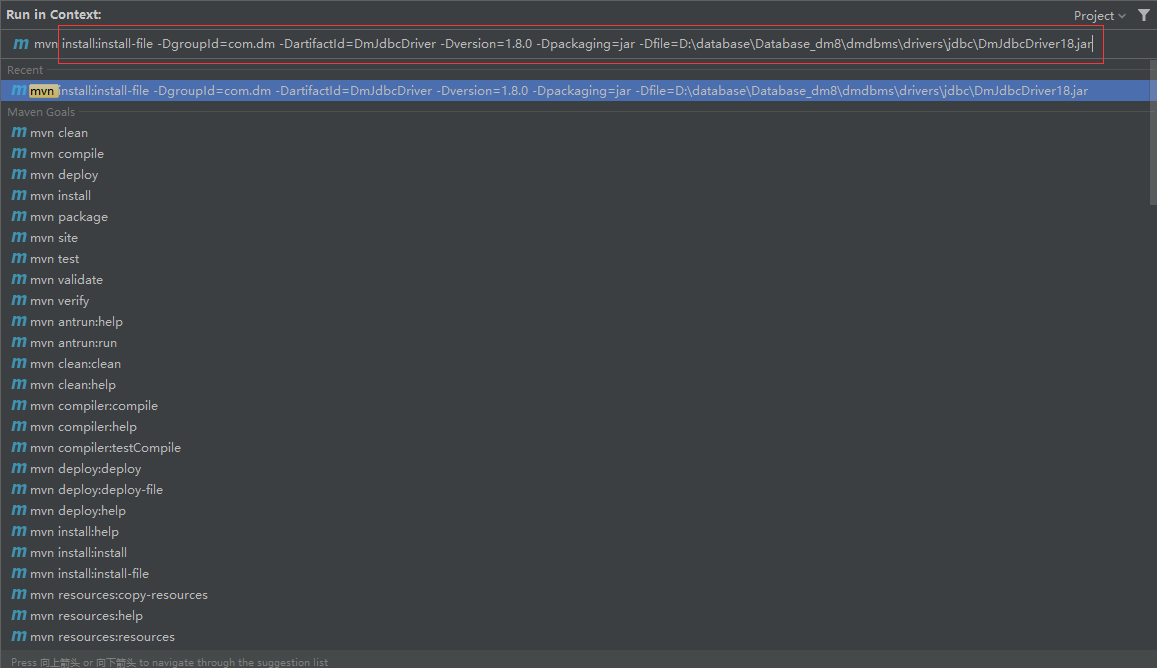
PS: -Dfile 是Jar 包所在位置,需要切换为自己的jar包存放位置!
- 安装完成后,项目pom文件中直接引用 数据库依赖:
<dependency>
<groupId>com.dm</groupId>
<artifactId>DmJdbcDriver</artifactId>
<version>1.8.0</version>
</dependency>
13.2 项目中的yaml配置
项目中的 yaml 文件配置有两种写法,第一种是 ip+port/模式名称 ,第二种是 ip+port?schema=模式名。
spring:
datasource:
driverClassName: dm.jdbc.driver.DmDriver
url: jdbc:dm://127.0.0.1:5236/模式名 #?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8
username: username
password: password
数据源地址中的 模式名 为对应DM数据库中的模式名称,根据自己实际情况指定模式名称,模式不可使用-连字符,最好使用下划线进行连接!
连接地址一点要注意填写的模式名是哪一个,如果链接中没用注明链接模式时,系统会默认链接到用户名相同的模式下!
在查询非当前模式下的所属表时,查询语句中需要加上对应的模式名称SELECT * FROM 模式名.表名;,同时还需要保证当前登录用户具有该模式的对应权限!
13.3 在JDBC中使用DM(扩展)
利用JDBC 驱动程序进行编程的一般步骤为:
- 获取 java.sql.Connection对象
利用 DriverManager 或者数据库源来建立同数据库的连接。
- 创建 java.sql.Statement 对象。这里也包含了 java.sql.PreparedStatement 和 java.sql.CallableStatement对象。
利用连接对象的创建语句对象的方法来创建。在创建过程中根据需要来设置结果集的属性。
- 操作数据库
操作数据库分为两种情况,更新操作和查询操作;查询操作执行完成后会得到一个 java.sql.ResultSet 对象。可以操作该对象来获得指定列的信息。
- 释放资源
操作完成之后,用户需要释放系统资源,主要是关闭结果集、关闭语句对象,释放连接。 虽然这些动作 JDBC 驱动程序会自动执行,但由于Java语言的特点,这个过程比较慢(需要等到Java进行垃圾回收时才进行)。
示例代码:
package com.gzzd.test;
import org.junit.Test;
import org.springframework.boot.test.context.SpringBootTest;
import java.sql.*;
/**
* @ClassName : TestJDBC_DM
* @Description : 测试JDBC连接达梦数据库
* @Author : AD
*/
@SpringBootTest
public class TestJDBCConnectDM {
/** 定义DM JDBC驱动串 */
String jdbcString = "dm.jdbc.driver.DmDriver";
/** 定义 DM URL 连接串 (TEST为模式名称) */
String urlString ="jdbc:dm://localhost:5236/TEST";
/** 定义连接用户名 */
String userName = "SYSDBA";
/** 定义连接用户口令 */
String password = "lcjDm123..";
/** 定义连接对象 */
Connection conn = null;
/**
* Description: 加载 JDBC 驱动
*/
public void loadJdbcDriver() throws SQLException {
try {
System.out.println("加载 JDBC 驱动...");
Class.forName(jdbcString);
} catch (ClassNotFoundException e) {
throw new SQLException("Load JDBC Driver Error : " + e.getMessage());
}
}
/**
* Description: 连接 DM 数据库
*/
public void connect() throws SQLException{
try {
System.out.println("连接 DM 数据库...");
conn = DriverManager.getConnection(urlString, userName, password);
} catch (SQLException e) {
throw new SQLException("Connect to DM Server Error : " + e.getMessage());
}
}
/**
* Description: 断开 DM 数据库连接
*/
public void disConnect() throws SQLException{
try {
System.out.println("断开 DM 数据库连接...");
if (conn!= null) {
conn.close();
}
} catch (SQLException e) {
throw new SQLException("DisConnect to DM Server Error : " + e.getMessage());
}
}
/**
* Description: 查询员工信息测试方法
* */
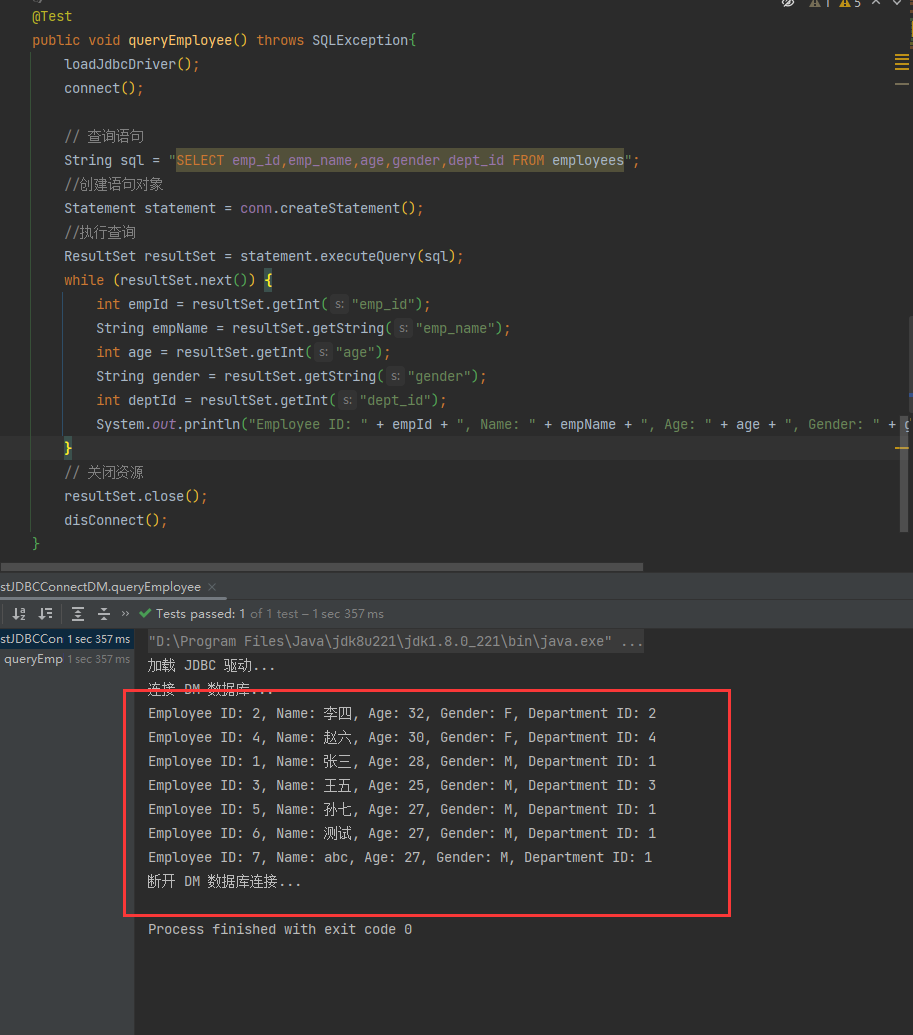
@Test
public void queryEmployee() throws SQLException{
loadJdbcDriver();
connect();
// 查询语句
String sql = "SELECT emp_id,emp_name,age,gender,dept_id FROM employees";
//创建语句对象
Statement statement = conn.createStatement();
//执行查询
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
int empId = resultSet.getInt("emp_id");
String empName = resultSet.getString("emp_name");
int age = resultSet.getInt("age");
String gender = resultSet.getString("gender");
int deptId = resultSet.getInt("dept_id");
System.out.println("Employee ID: " + empId + ", Name: " + empName + ", Age: " + age + ", Gender: " + gender + ", Department ID: " + deptId);
}
// 关闭资源
resultSet.close();
disConnect();
}
}
执行查询功能结果示例:
十四、数据迁移步骤
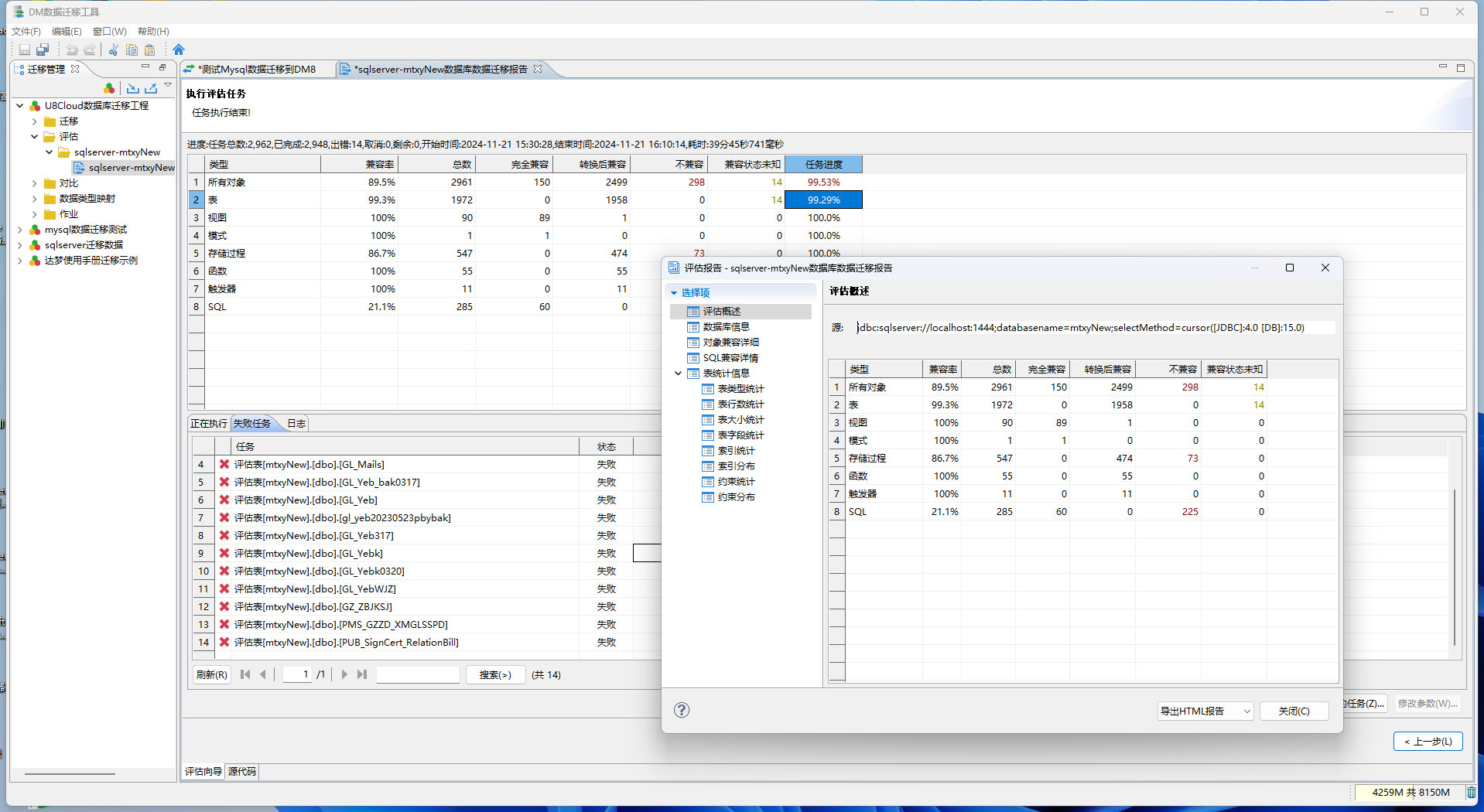
达梦数据库进行数据迁入时,直接使用数据库自带的 DM数据迁移工具。达梦8 是包含这个功能的。
可在迁移项目未开始前预评估Oracle、SQLServer、DB2、MySQL等主流数据库的对象(触发器,函数、存储过程等)、SQL语句向DM数据库迁移工作量一一用户可通过评估报告即可准确了解迁移项目工作量!
通过迁移报告的结果,可以手动调整不兼容的sql,并进行校验操作!
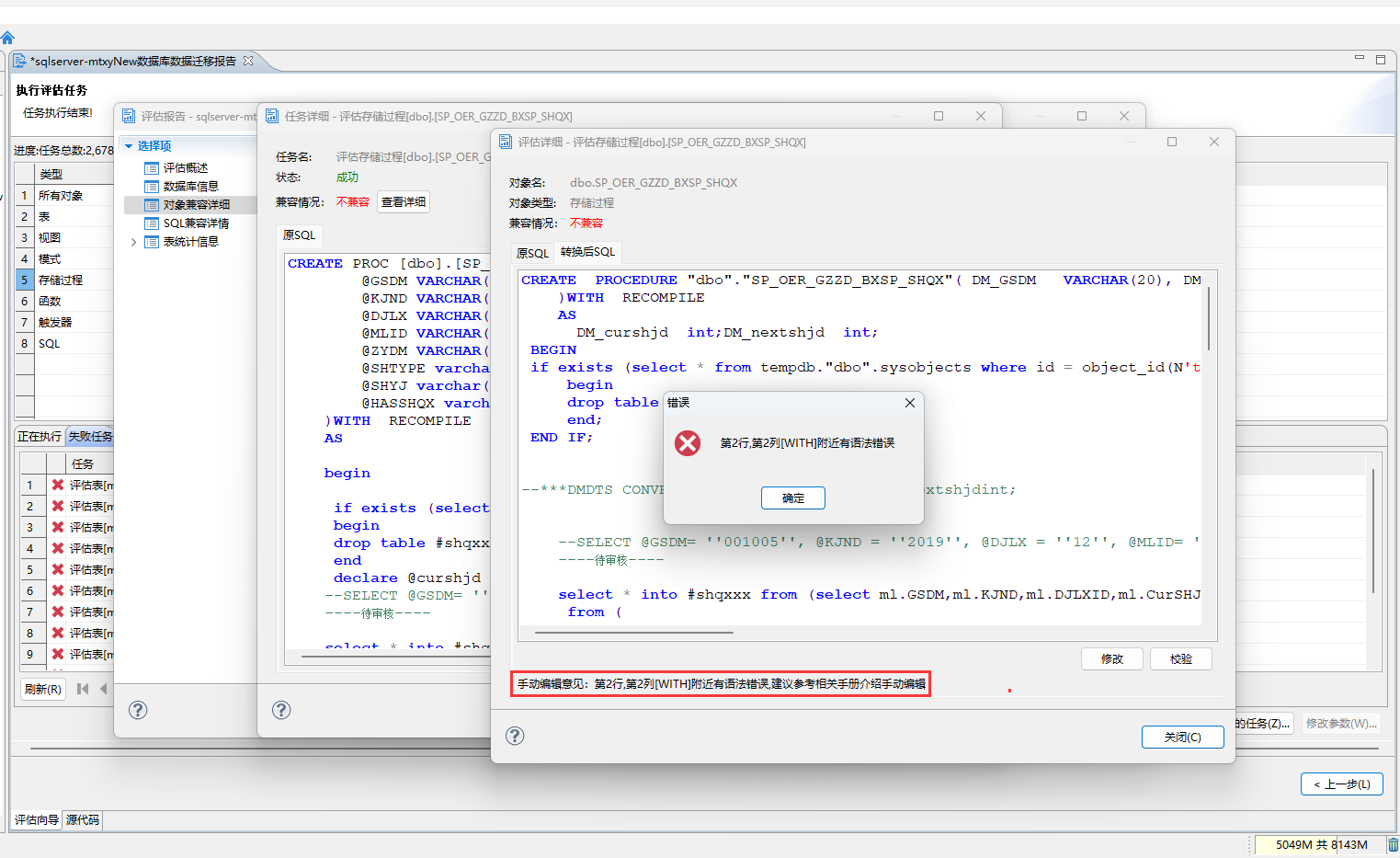
- 在 SQL 评估阶段不兼容的对象不需要勾选,待其它对象迁移完成后,再手动修改和导入这些不兼容的对象。
- 如果数据量较大,可以选着先迁移表结构定义相关内容,再迁移数据,最后迁移索引。
14.1 从Mysql中迁移数据
- 1、创建迁移工程
打开DM数据库管理工具,在迁移管理中新建工程;然后在新创建工程内迁移文件夹中创建迁移组 和 迁移。
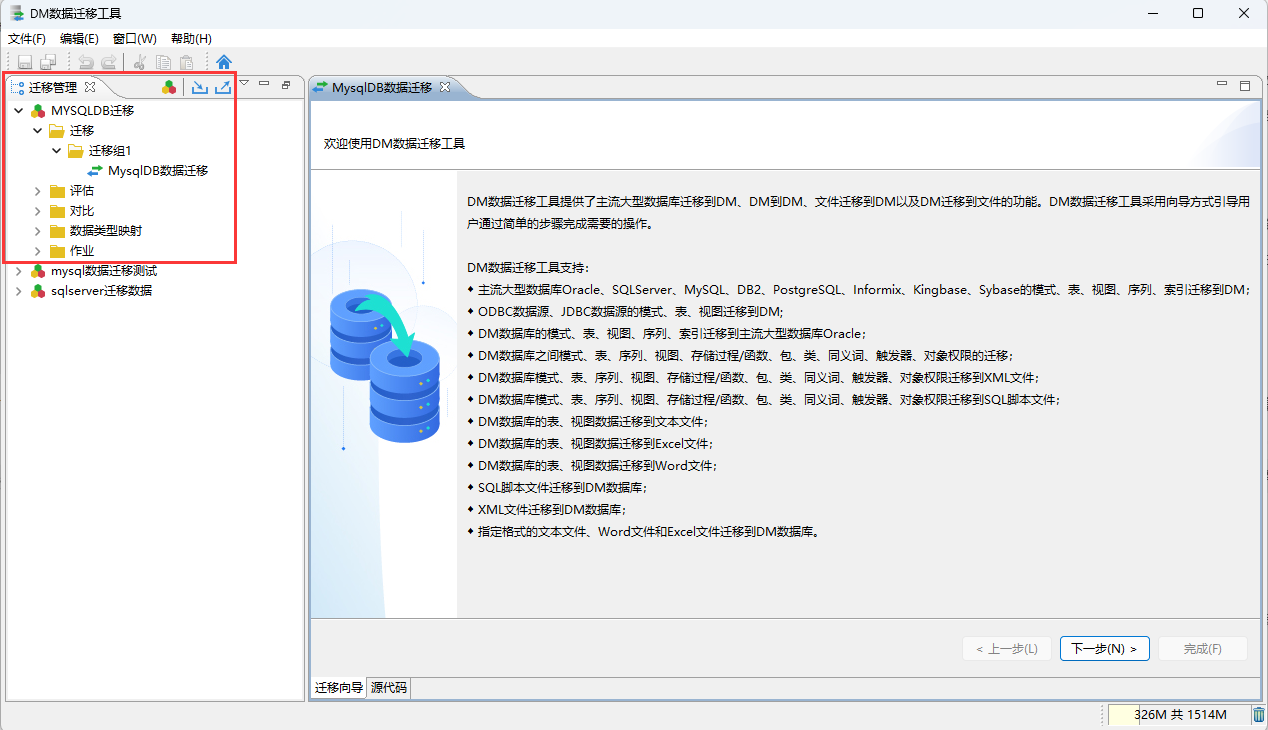
创建完成之后点击下一步!
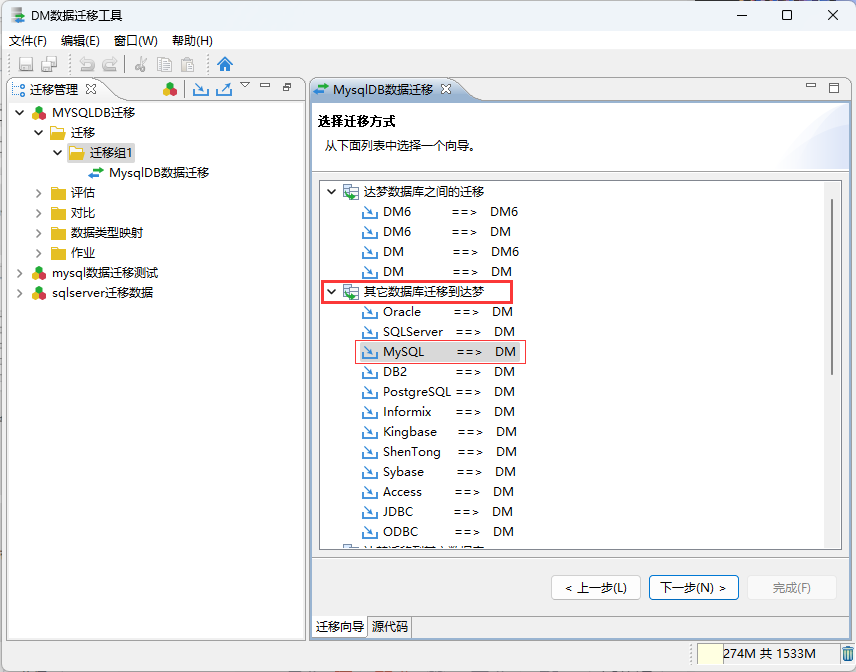
- 2、选择迁移方式为MySQL
- 3、配置数据源MySQL 信息
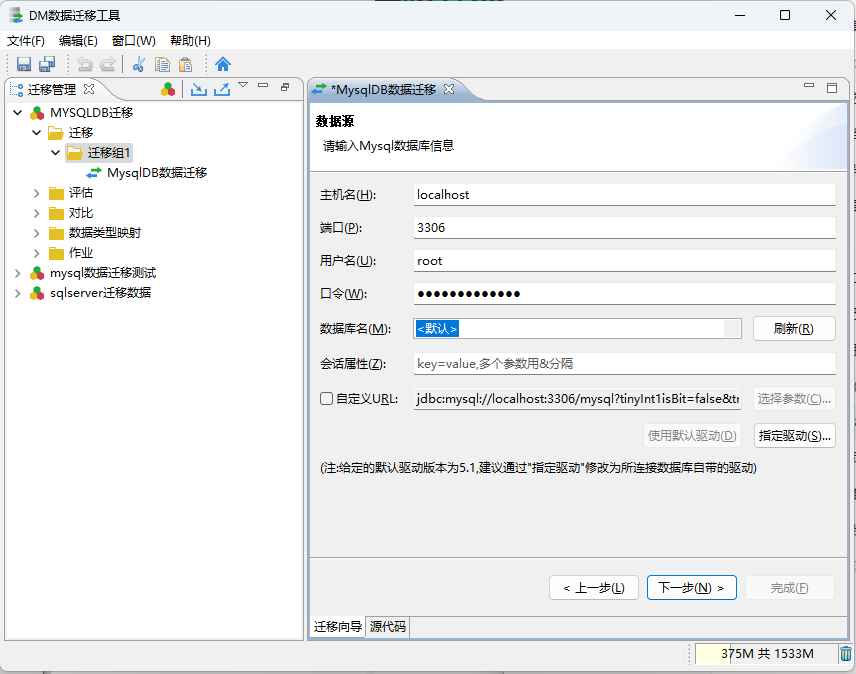
根据自己的MySQL版本判断需不需要自己指定Mysql的l连接驱动包;若
不需要即可忽略此步骤;若需要指定其它版本的连接驱动包的,可以通过 Maven Repository Maven仓库 中搜索下载后在引用 即可!
数据库驱动名:com.mysql.jdbc.Driver #数据库驱动类名
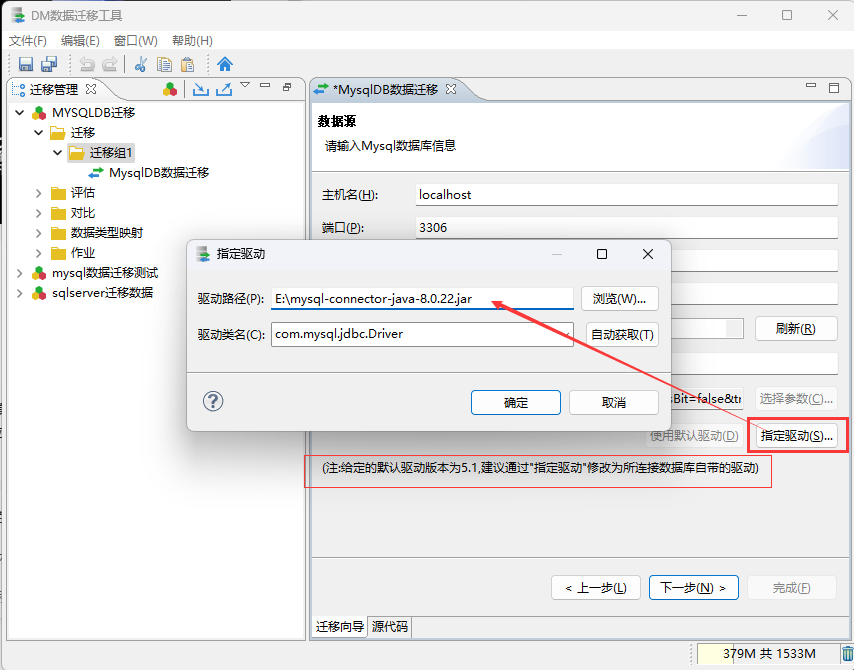
在填入连接相关地址信息、用户名、密码之后,正常情况下是可以读取出所连接的Mysql数据源中对应的数据库,同时这里可以选择对应需要迁移到达梦数据库中的库对象! ( 如果连接失败,就尝试上一步中的 替换驱动)
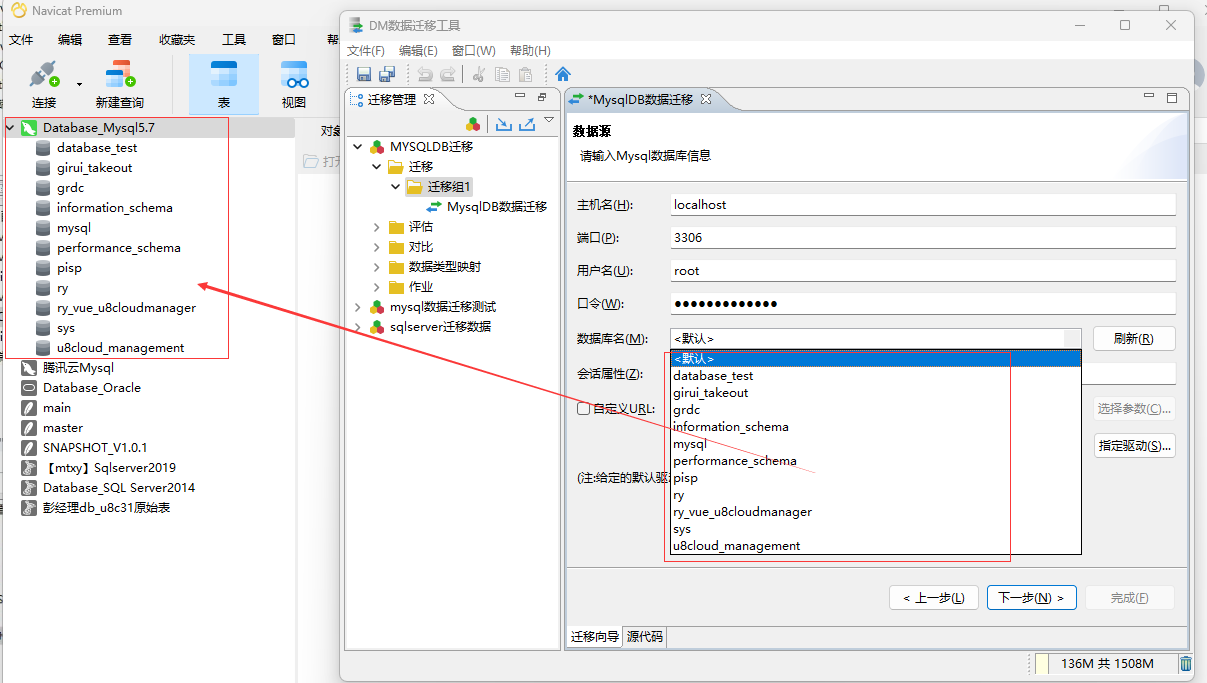
数据源URL: jdbc:mysql://localhost:3306/<databaseName>?tinyInt1isBit=false&transformedBitIsBoolean=false
- 4、配置目的源信息(达梦数据库连接信息配置)
在这之前,可以创建一个模式或者用户,在新用户的对应模块下存放 Mysql 迁移过来的数据。这样便于数据的管理和使用。

填写达梦数据库相关配置信息:
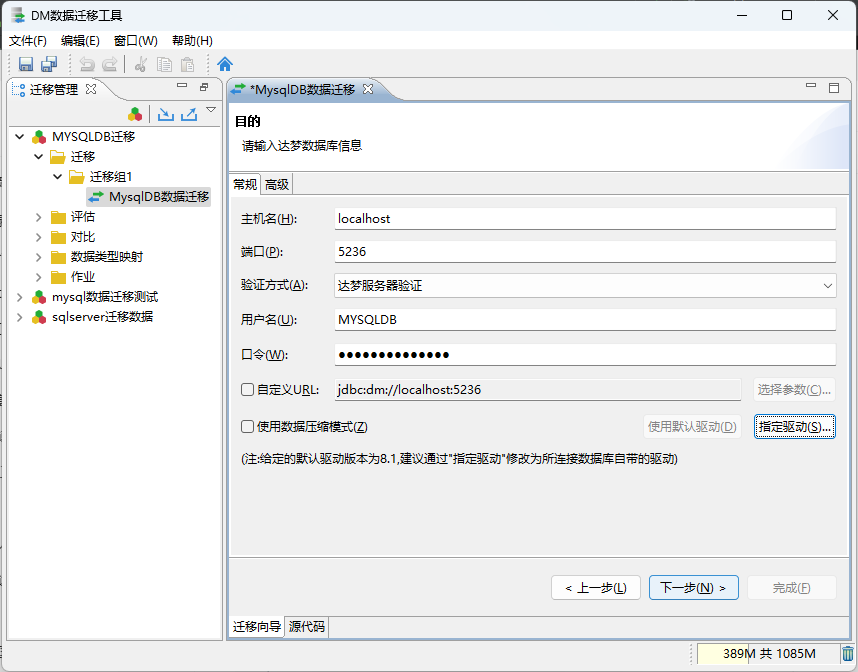
这里也可以自定义指定 达梦数据库 的连接驱动:
其中达梦数据库的驱动Jar,存放在达梦数据库安装路径下的 \drivers\jdbc 目录中!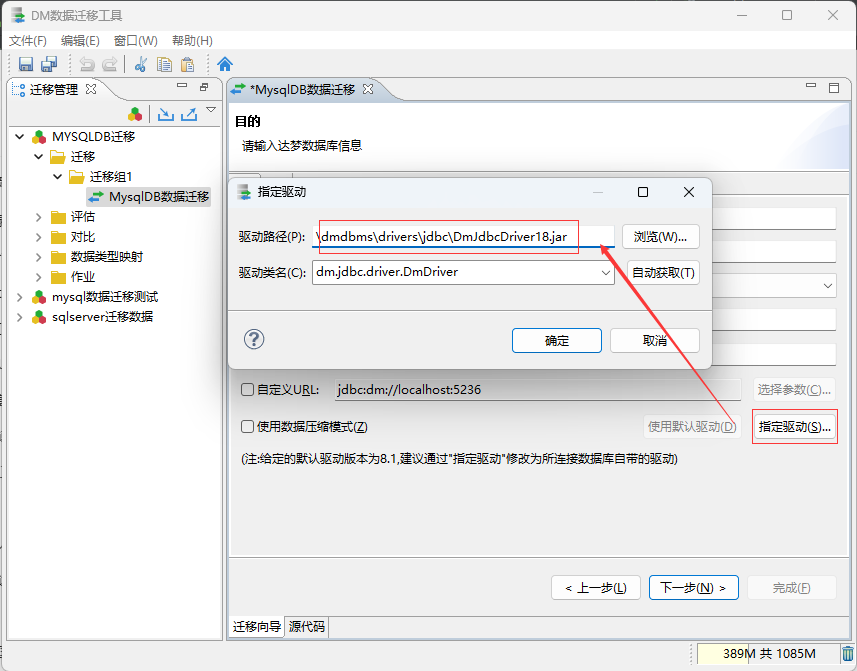
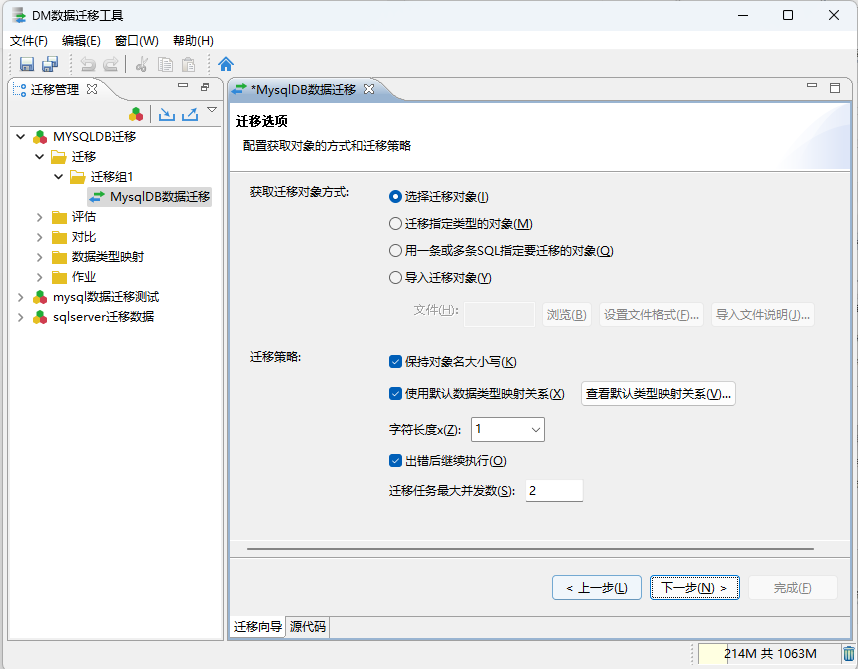
- 5、迁移策略信息配置
- 6、指定迁移数据信息
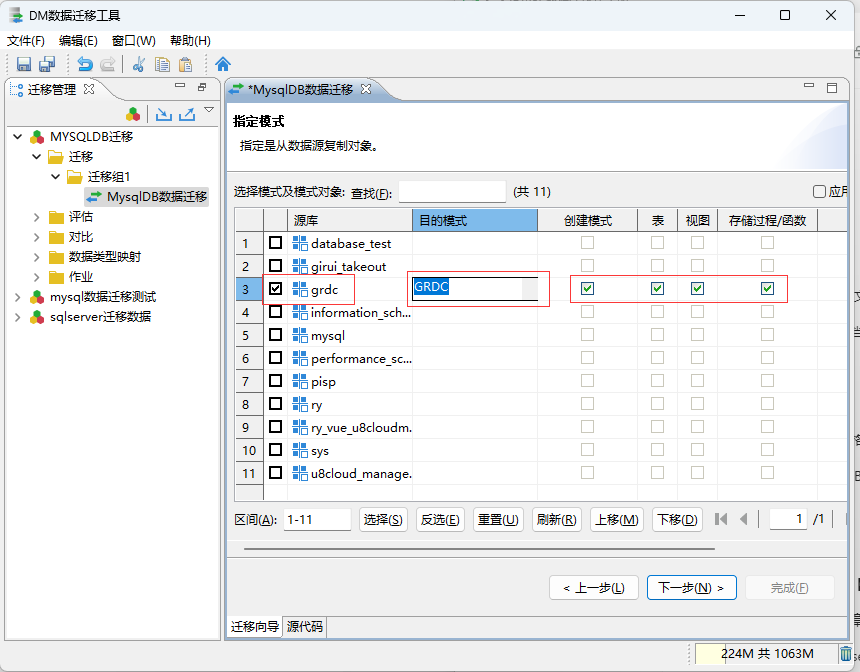
这里通过迁移工具,选择Mysql数据源中,需要迁移的数据表格; 同时选择需要迁移到达梦数据库的哪个模式中 等信息!
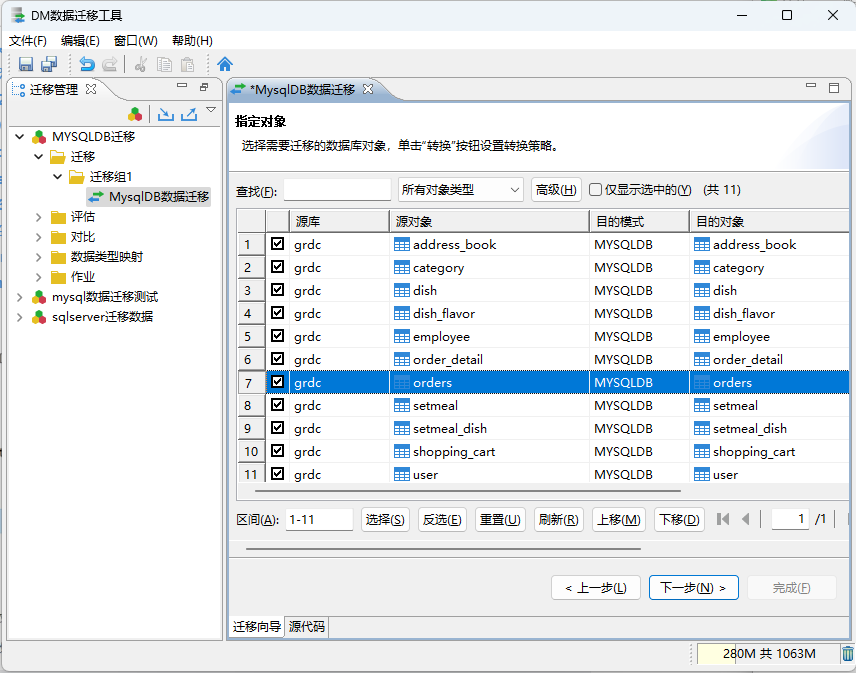
确定好模式后,下一步选择数据源库中需要迁移的源对象(表):
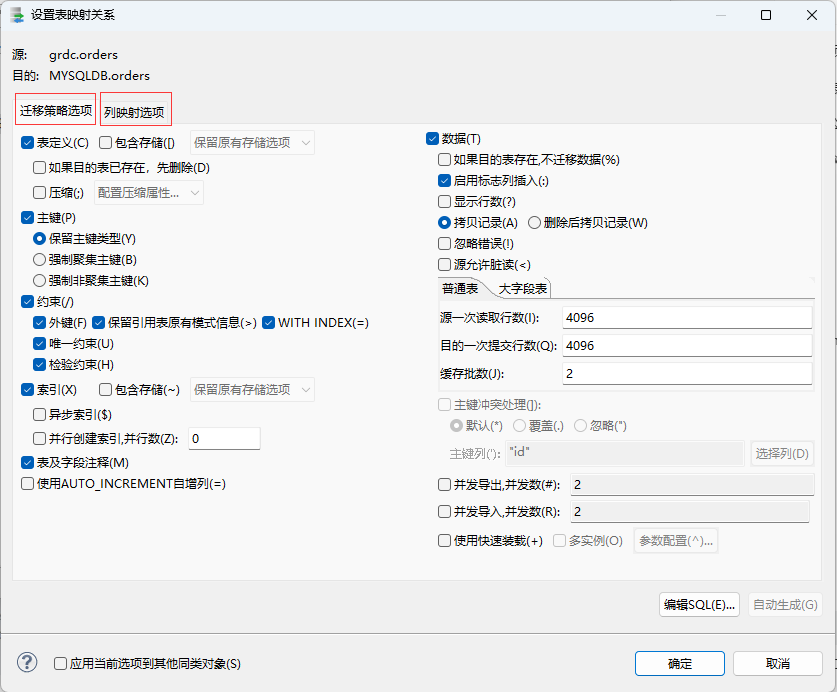
这里 还可以调整目标对象名称,即将数据源迁移过来后重新命名,以及调整 每个源对象中的 迁移策略选项 和 列映射选项信息:
- 7、执行迁移操作,审阅迁移任务
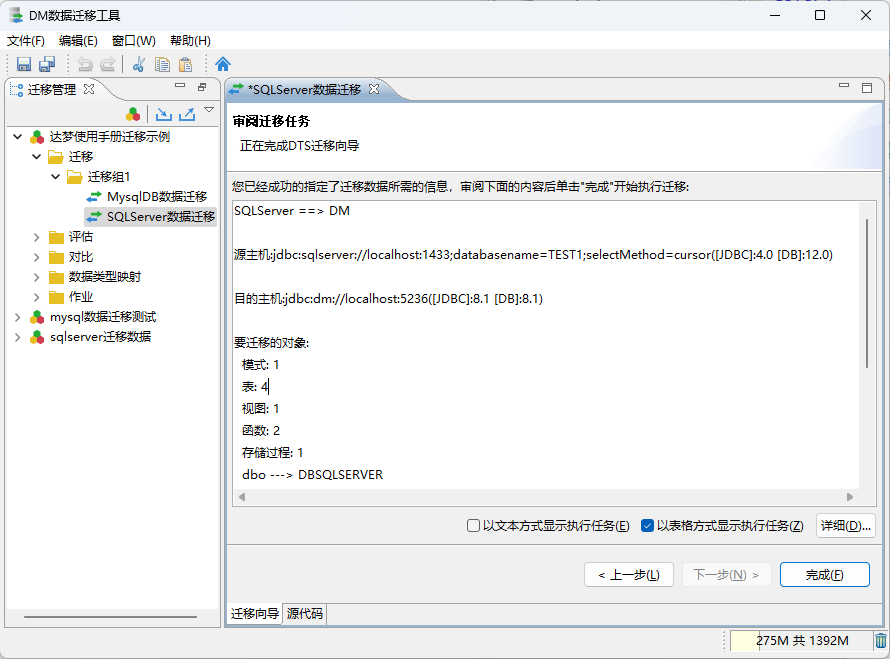
将所有信息配置完毕后,执行迁移操作!
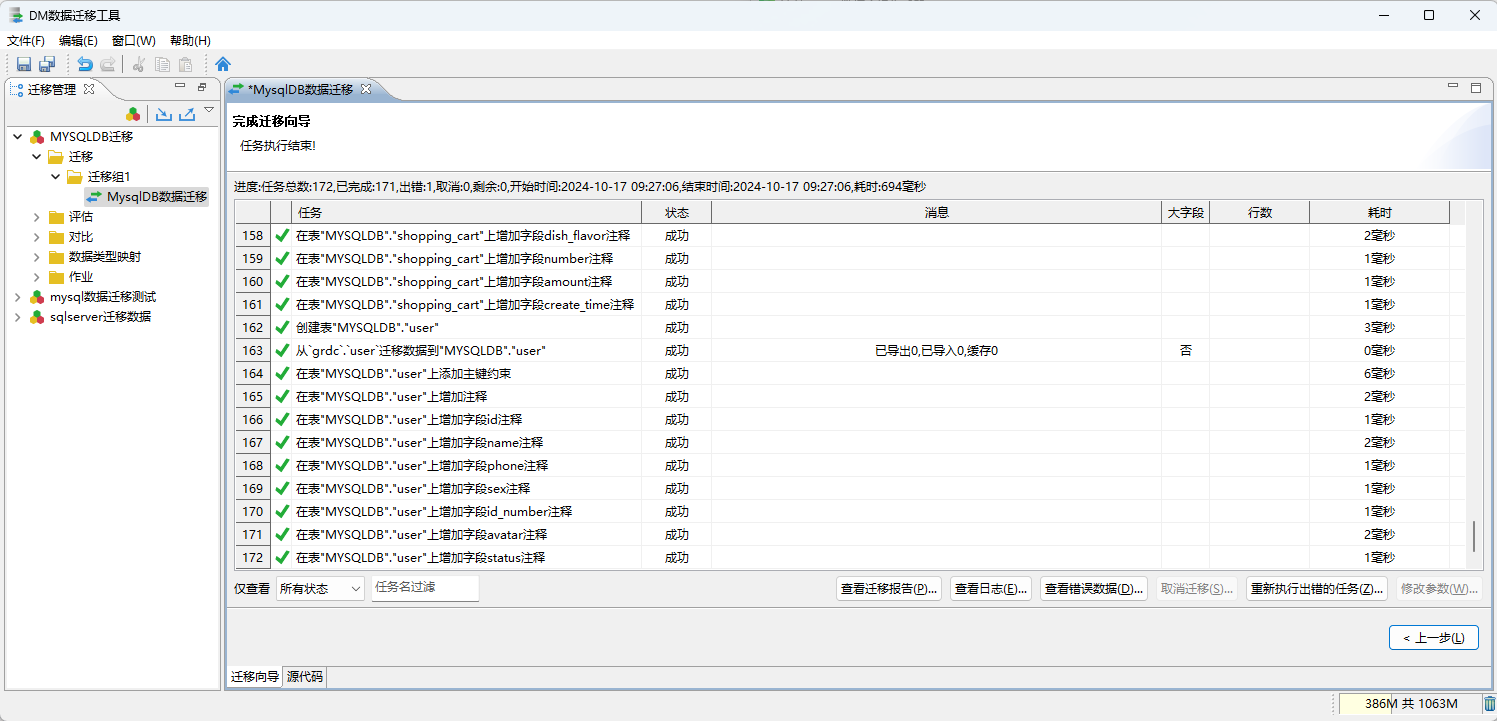
迁移完成后,需要查看进度中的迁移日志报告,可能在迁移中会出现迁移失败的表数据 ( 设置了出现错误继续执行 )。
通过执行日志查询错误原因,一般情况下都是字段兼容\长度等问题导致导入数据的格式问题;然后重新进行迁移,且只选择迁移失败的表格,同时调整其 迁移策略 和 列映射选项等信息来规避迁移中出现的错误!
14.2 从SqlServer中迁移数据
从SqlServer中迁移数据,与从MySQL中迁移数据 ,在达梦的数据迁移工具中的操作大体步骤是一样的。
另外还需要单独对 SQL Server 数据库的配置管理器进行相关的设置操作!
14.2.1 SQL Server配置管理器
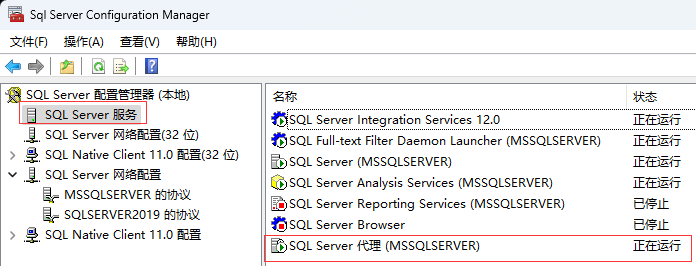
- 开启代理:
SQL Server 服务代理服务启动运行起来!
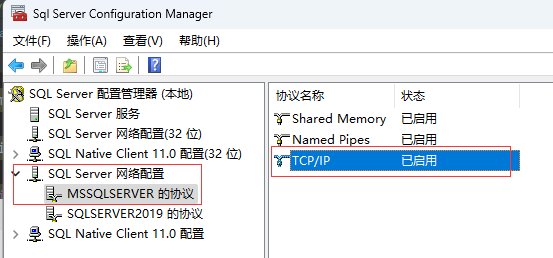
- 开启MSSQLSERVER的TCP/IP协议
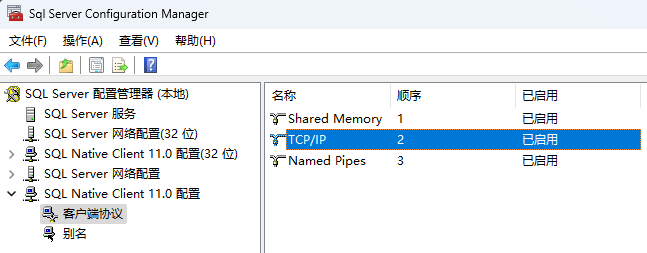
- 检查客户端协议开启
- 在服务中重启 SQL Server 服务
我这里是因为按照了两个版本的 SQL Server 数据库 ,所有会出现对应的两个服务~~

14.2.2 达梦数据库迁移工具
完成了上面对 SQL Server 的像个配置后,后面的步骤就在 达梦数据迁移工具中完成。
在迁移之前先在 达梦数据库管理工具中,创建一个模式或者用户,用于存放即将迁移的数据信息:

后续过程中的操作步骤 和 在Mysql中迁移数据步骤一致,相同操作的地方就不再赘述:
- 打开达梦数据库迁移工具,创建新的工程、模式和迁移
- 迁移方式的选择:
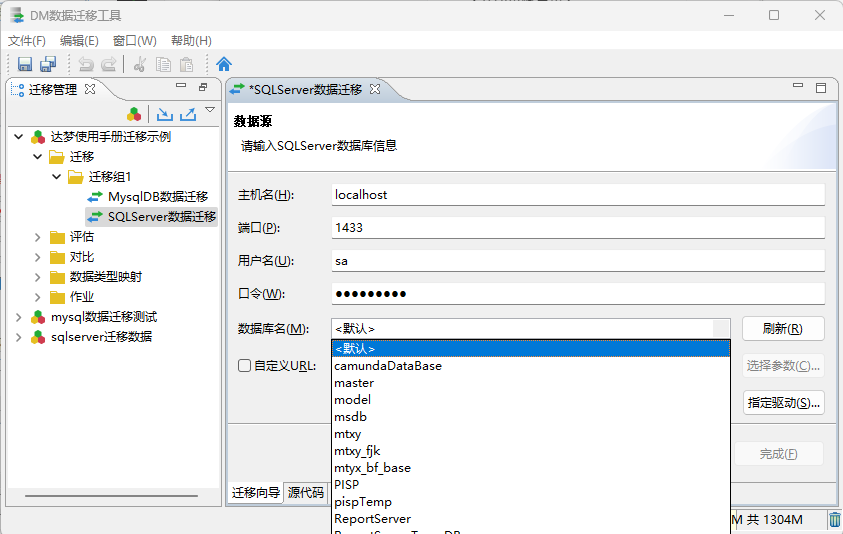
- SQL Server 数据源连接
配置完SQL Server 的信息后刷新即可连接目标到数据源。
SQL Server数据源URL:sqlserver配置 URL: jdbc:sqlserver://localhost:1433;databasename=PISP;selectMethod=cursor
- 连接目的源(达梦数据库)
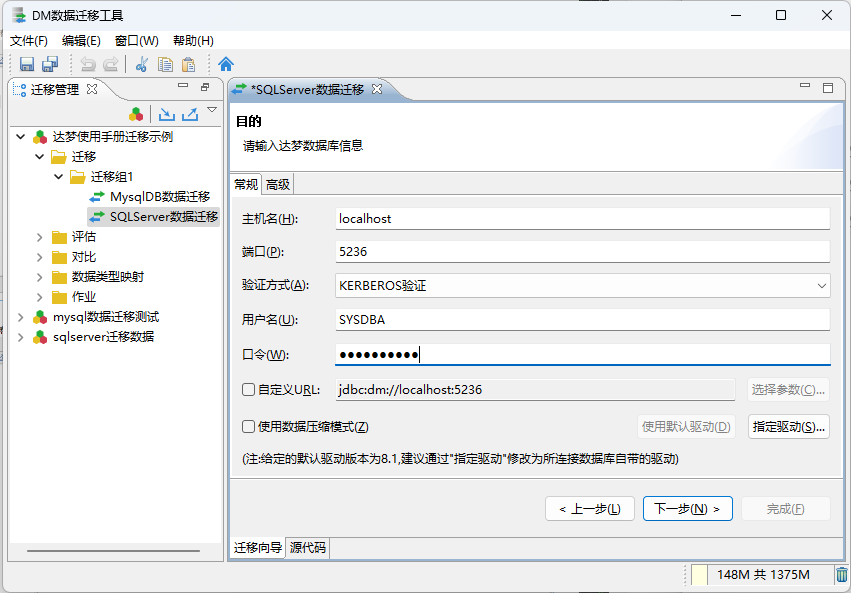
5.迁移策略信息配置
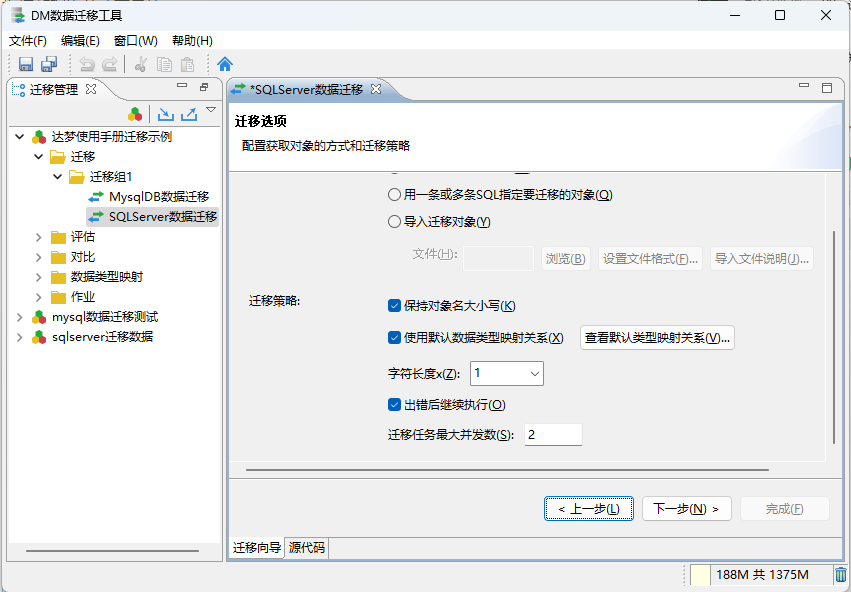
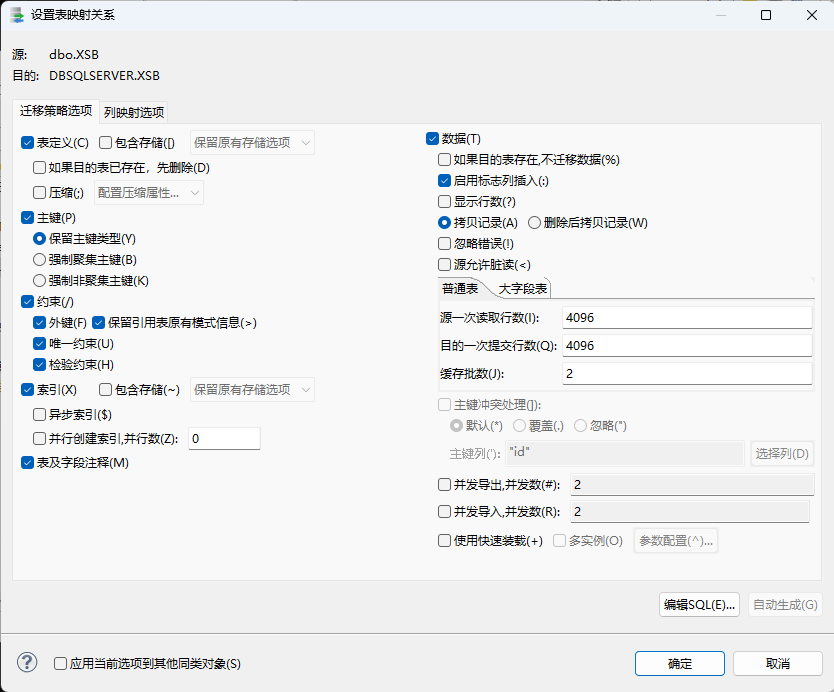
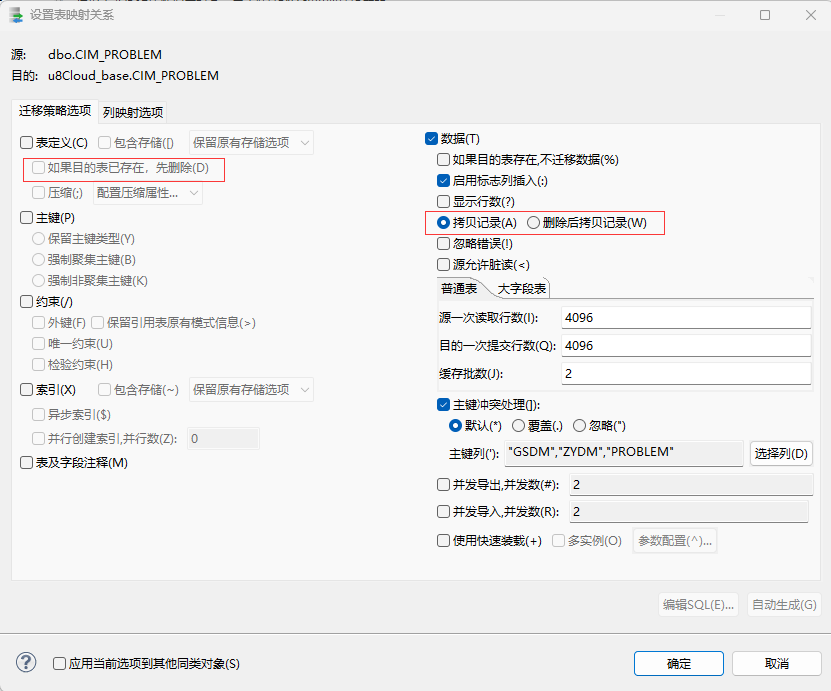
注1:迁移数据时这里的保持对象大小写选项! 建议是不要勾选,否则在数据库对象迁移后,对象是区分大小写的。
例如保持对象大小写迁移了一张表"AaBbCc",那么在查询该表时,就必须要使用 双引号 “AaBbCc” 来查询该表来保持对应名称一致才能查询到对应表格!
如果不保持对象名大小写,在达梦中默认会全部转换为大写名称(人大金仓数据库是默认保存为小写)!在查询对象时,就不需要添加双引号来查询对象,无论使用大写、小写、大小写名称都能查询到对应的对象数据!
对象大小写问题可看 15.1 小结!
注2:当数据迁移过程出,出现数据转换错误的问题时,如果当前表的字段非常多,很难定位到具体的长度问题所在位置时! 可以通过自定义配置类型映射关系来临时解决数据迁移字段长度不符合的问题!
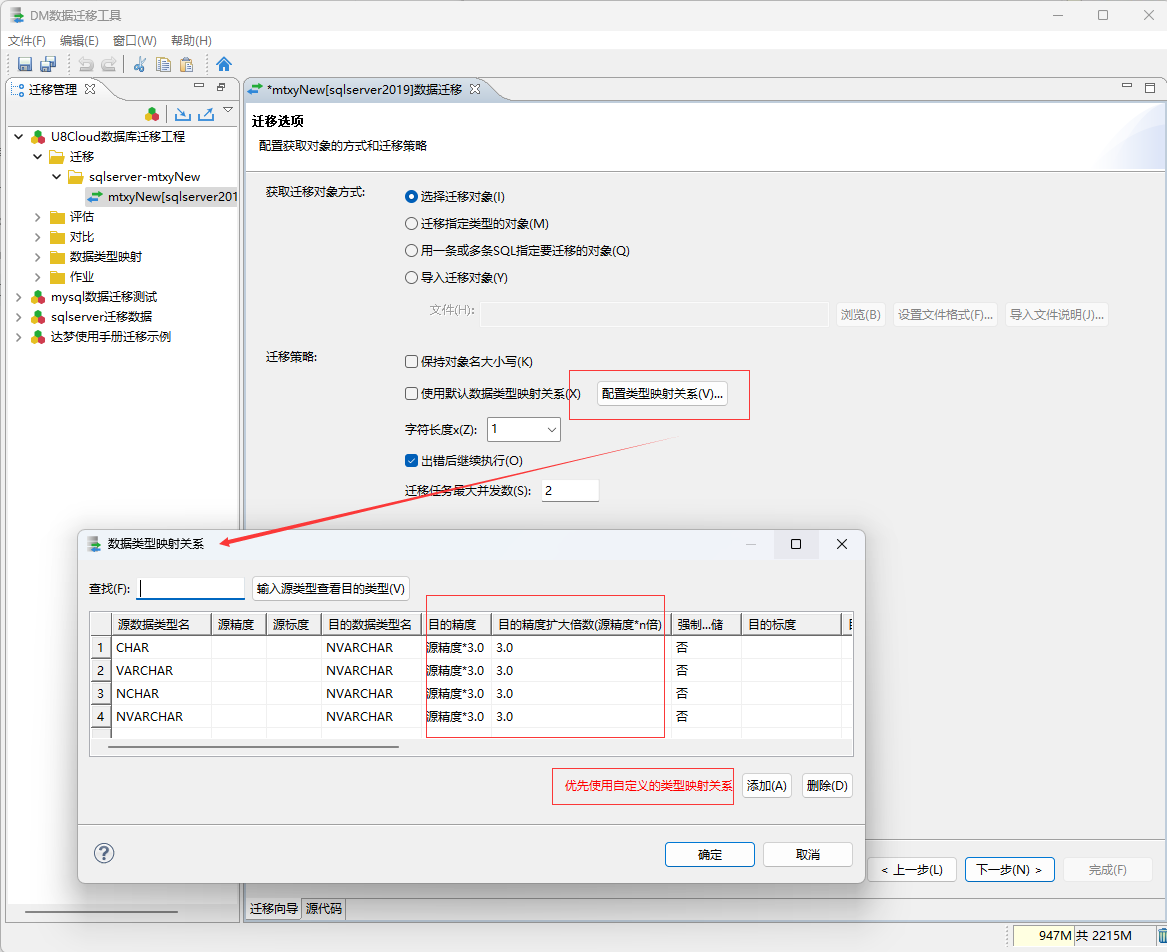
- 指定迁移数据信息:
源模式列中,选择SQL Server 数据源所以选库中的指定源模式下的数据;
目的模式,选择出达梦数据库中需要迁移入数据的模式;
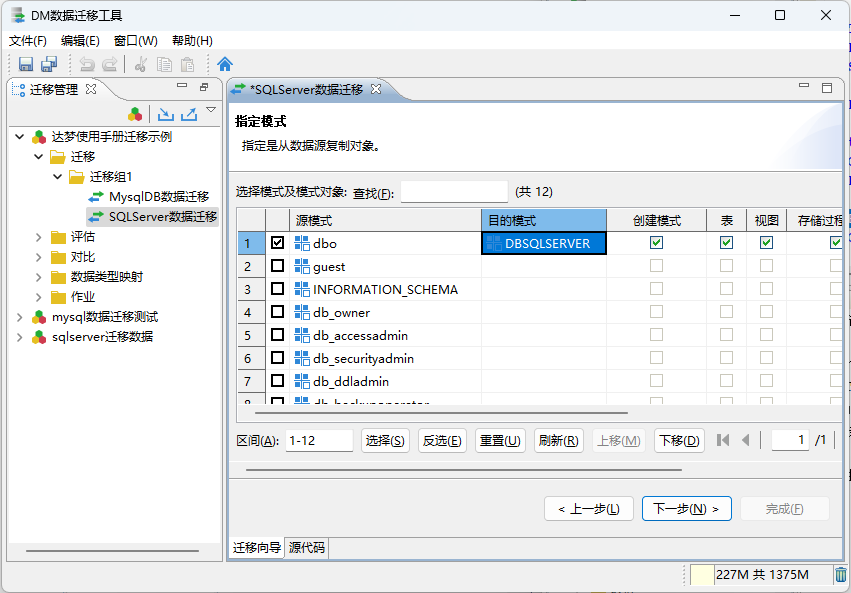
确定好数据源的数据库模式 和 要迁移进入的达梦数据库模式之后,下一步;
这里就可以对迁移数据源中对应数据库模式下的所有数据进行筛选迁移。
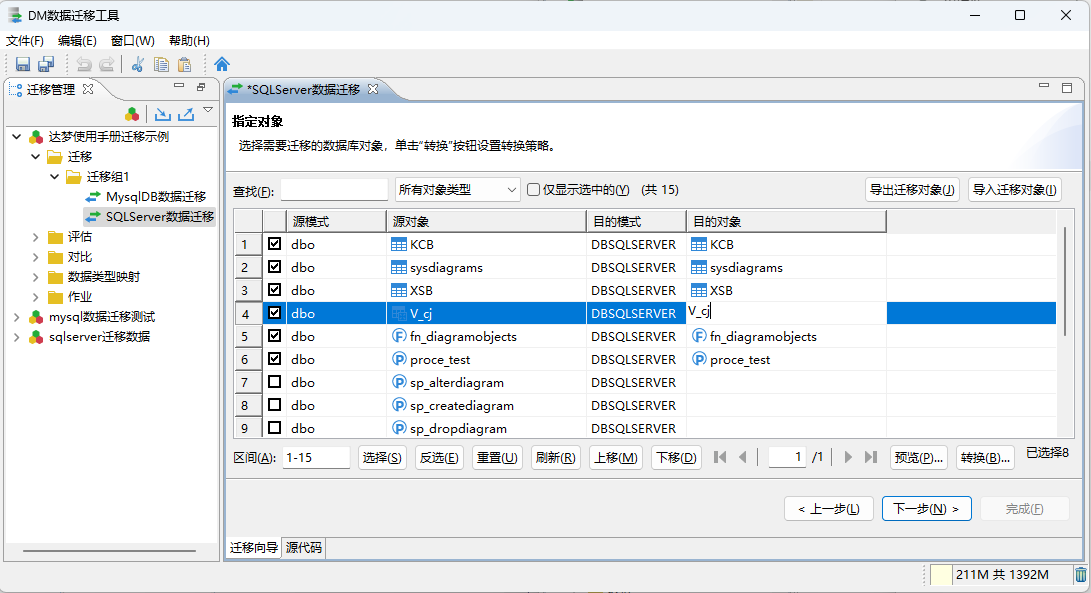
双击目标对象栏名字,可以自定义迁移后对象的名称!
双击源对象中的名字 可以对元对象的映射关系进行设置,其中包括 迁移策略的设置 和 列映射选项的配置!
- 执行迁移操作,审阅迁移任务
可以通过迁移日志,查询执行失败的日志,然后在重新调整对应模式下表对象的映射关系或者列映射的设置,来解决迁移失败的原因:
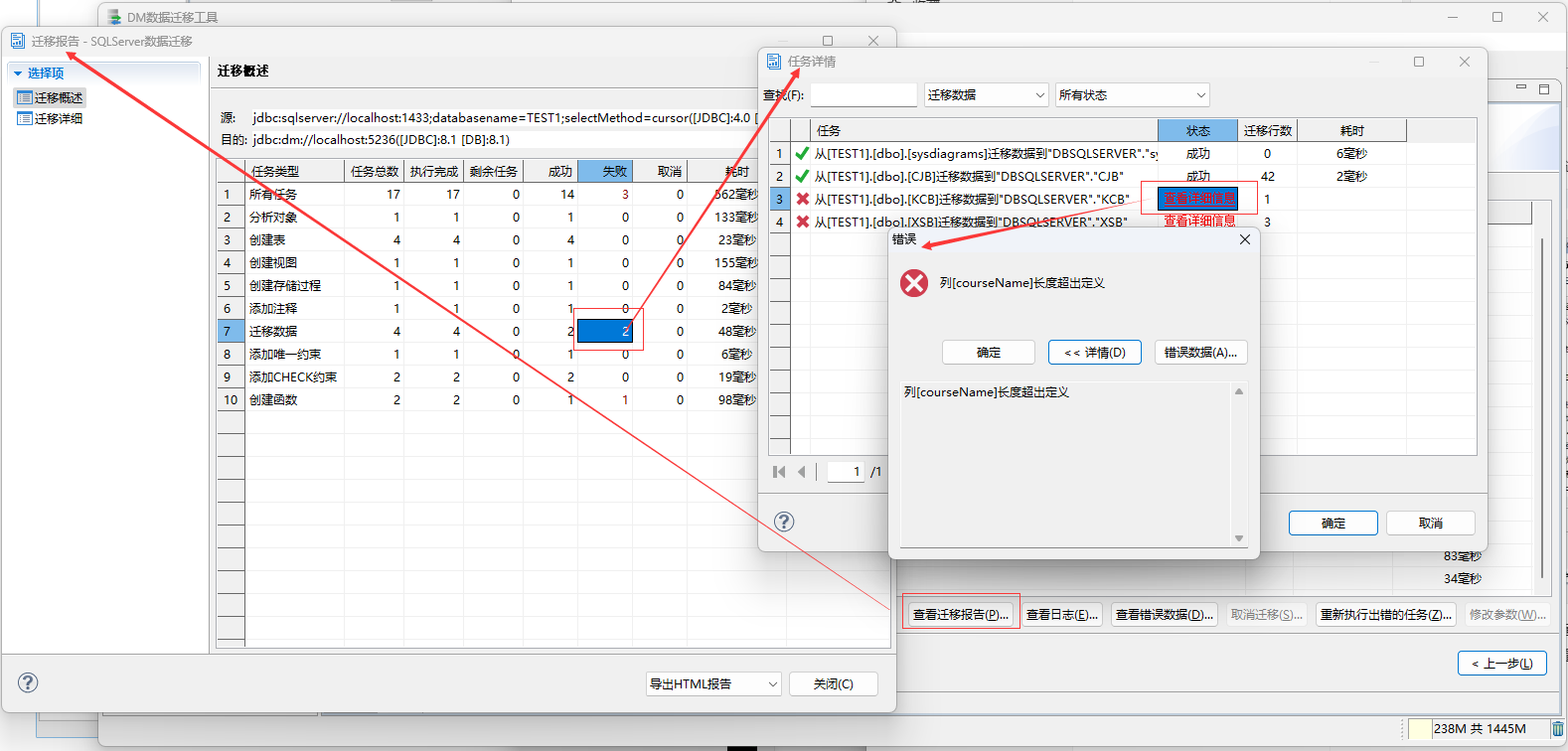
调整迁移失败的表对象与目的源之间的映射关系之后重新执行迁移:
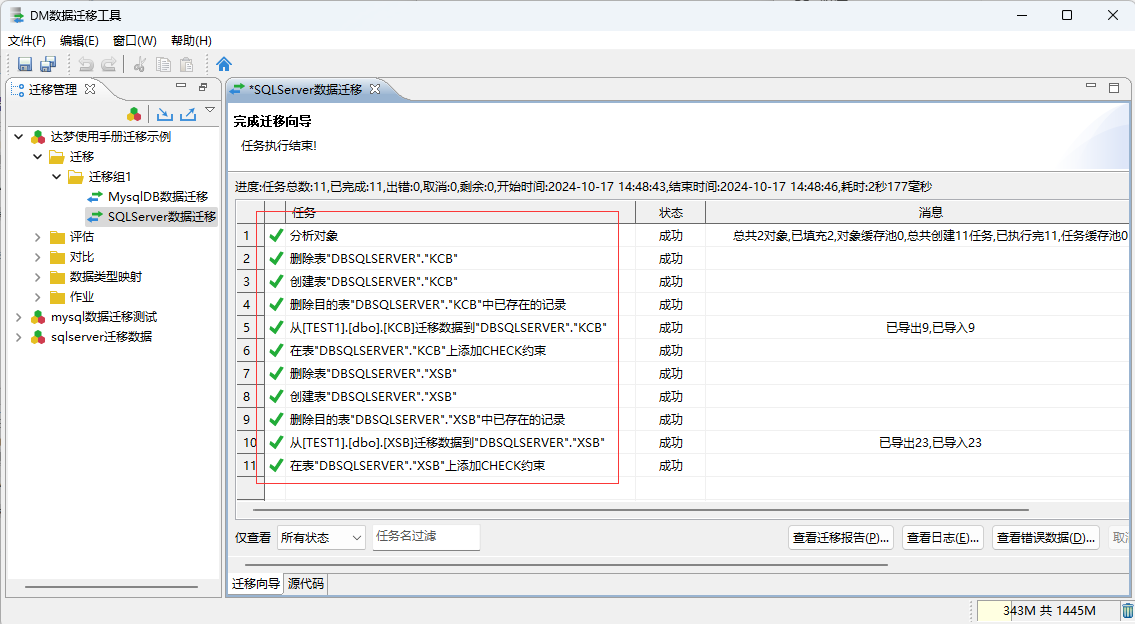
- 达梦数据库迁移工具连接SQL Server数据源异常错误 解决办法:
报错信息:The server selected protocol version TLS10 is not accepted by client preferences [TLS13, TLS12]"。
ClientConnectionId:6d7ab5a0-69ea-411a-af7c-5c6b86d9d6ce
解决办法:找到本地环境中的 JDK 文件夹下/jre/lib/security 文件夹中的 jva.security 文件:

14.3 迁移失败数据的处理
- 表数据迁移失败的情况
这种情况大多数是由于表结构问题导致的(非空约束、字符长度等问题),导致后续表数据迁入失败!
- 根据表数据迁移错误信息,重新调整表格定义结构
- 然后进行二次迁移,需要注意在迁移时,就不要在迁移表结构,只需要迁移表格数据即可!
十五、其它注意点(持续更新):
15.1 大小写敏感设置问题
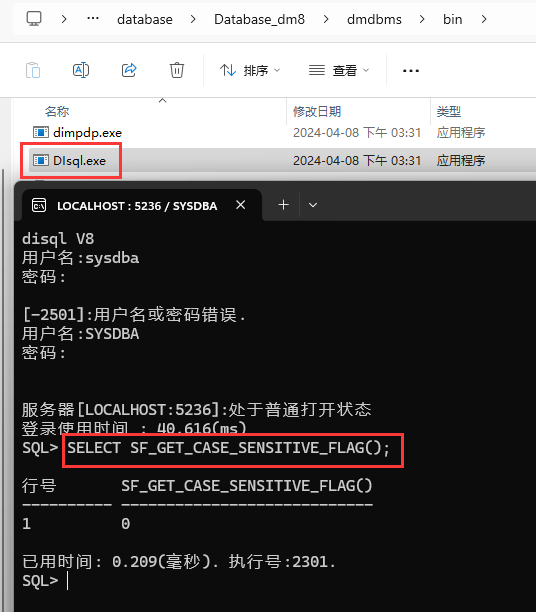
大小写敏感参数:CASE_SENSITIVE,初始化一旦设定是不能更改的! 通过语句 SELECT SF_GET_CASE_SENSITIVE_FLAG() 查询属性值;对应属性值的含有为: 1为大小写敏感,0为大小写不敏感;
- 初始化实例为大小写敏感库
- 如果不对 表名/列名 添加 “” ,那么表名都会自动转换为大写形式;
- 如果对 表名/列名 添加 “”,会固定书写时的大、小写形式,书写时采取的是小写形式,那么就定型为小写形式,其他不添加” "的则自动转换为大写形式,无论书写时采取的是大写形式或小写形式;
- 同名的数据库对象,如果大小写不同,那么则为两个不同的对象,字段同样如此;
- 一个表中,允许存在同名且不同大小写形式的字段;
- DML或DDL操作不带双引号则默认是大写,指定字段小写需要加上双引号。
- 初始化实例大小写不敏感库
- 无论对不对表名或列名添加" ",表名和列名的大小写形式不会发生变化,大写形式就是大写形式,小写形式就是小写形式;
- 不允许存在同名的数据库对象,即使大小写不同,默认也只能存在一个;
- 一个表中,也不允许相同的字段名,即使大小写不同;
- 查询时,’ '和" "界定符不区分大小写,界定符中的查询或过滤条件即使是大写或小写,都可以查询到预期的结果集。
15.2 系统兼容性设置
(暂时没测试出来实际作用效果~)
在达梦数据库的安装包目录下的Tool文件夹中打开 DM控制台工具进行设置:
打开实例配置,找到兼容性相关参数 COMPATIBLE_MODE 参数项目进行修改:

是否兼容其他数据库模式。0:不兼容,1:兼容SQL92标准,2:兼容ORACLE,3:兼容MS SQL SERVER,4:兼容MYSQL,5:兼容DM6,6:部分兼容TERADATA,7:部分兼容PostgreSQL。
15.3 SqlServer数据迁移注意问题
- 存储过程中 **WITH RECOMPILE **不支持
WITH RECOMPILE 选项的作用是指示 SQL Server 在每次执行存储过程时都重新编译该过程的执行计划。在达梦数据库中,创建存储过程时并没有直接对应于 SQL Server 的 WITH RECOMPILE 选项。
- IDENTITY( 类型,起始值,增量值) 函数的兼容性
SQL Server 中,IDENTITY 函数用于创建自增列:
SELECT *, XH = IDENTITY(INT, 1, 1) FROM ...
由于达梦数据库不支持直接在查询中使用 IDENTITY,可以采用以下方式实现:
-- 创建序列
CREATE SEQUENCE seq_xh START WITH 1 INCREMENT BY 1;
-- 查询并生成自增列
SELECT t.*, seq_xh.NEXTVAL AS XH FROM your_table t;
-- [方式二 使用 ROW_NUMBER() ]
SELECT ROW_NUMBER() OVER (ORDER BY your_sort_column) AS XH,t.* FROM your_table t;
15.4 字段值空格问题
ps: 这里主要是用于和人大金仓数据库做对比! 两个国产数据库在空字符串’‘的处理上是有所区别的!需要注意两者之间的区别!否则在做国产数据库适配时,SQL语句会出现问题! 关于人大金仓数据库空字符串’’ 的处理移至 人大金仓总结中去查看!
15.4.1 关于字段为 ‘’ 空字符串时的情况
- 当表格中某个字段数据为‘’空字符串时 (这里将表users的NAME 字段 设置为’')
-- 将表users的NAME 字段 设置为''
UPDATE "users" SET NAME='' WHERE ID=1;
- 使用** 字段=null **和 **字段=‘’ 和 IS NULL **作为条件的查询 :
-- 使用 字段=null 和 字段='' 和 IS NULL 作为条件的查询
SELECT * FROM "users" WHERE NAME='';
SELECT * FROM "users" WHERE NAME=NULL;
SELECT * FROM "users" WHERE NAME IS NULL;
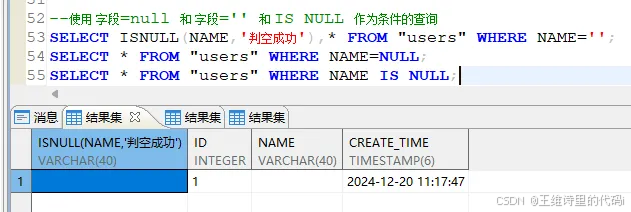
- 结论:
当字段为’'空字符串时,
- 使用** 字段=‘’ **可以查询到对应的数据! 只能使用 字段=‘’ 来匹配到数据!
- 使用 **字段=NULL **则查询不到对应数据!
- 使用 字段 IS NULL 也查询不到数据!
- ISNULL 判空函数也不能判空成功!
ps: 达梦数据库中 空字符串’’ 就是空字符串 ,NULL 就是 NULL 两个不等价,这一点与人大金仓不同!
15.4.2 关于字段为 NULL 空时的情况
- 设置 NAME 字段为空字符串NULL;
-- 将表users的NAME 字段 设置为NULL
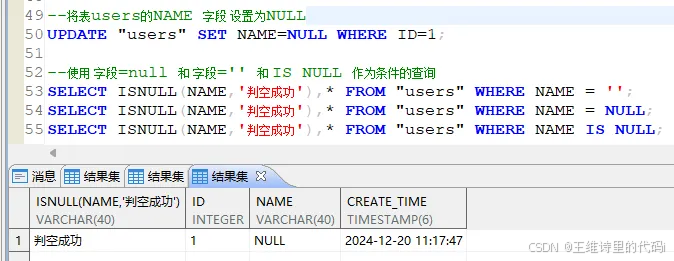
UPDATE "users" SET NAME=NULL WHERE ID=1;
- 使用** 字段=null **和 **字段=‘’ 和 IS NULL **作为条件的查询 :
-- 使用 字段=null 和 字段='' 和 IS NULL 作为条件的查询
SELECT ISNULL(NAME,'判空成功'),* FROM "users" WHERE NAME = '';
SELECT ISNULL(NAME,'判空成功'),* FROM "users" WHERE NAME = NULL;
SELECT ISNULL(NAME,'判空成功'),* FROM "users" WHERE NAME IS NULL;
- 结论:
当字段为空NULL时,
- 使用** 字段=‘’ **查询不到对应数据!
- 使用 **字段=NULL **则查询不到对应数据!
- 使用 字段 IS NULL 可以查询到对应数据!只能使用 字段 IS NULL 来匹配到数据!
- ISNULL 判空函数判空成功!
达梦中,空字符串不等价与 NULL ;且 当字段为NULL时,使用 字段=NULL 也无法查询到数据,只能使用 字段 IS NULL(这一点与人大金仓数据库相同)!
如果一个字段为 NULL,直接使用 字段 = 变量 这样的条件进行查询,即使变量也是 NULL,查询结果也不会返回包含 NULL 的记录。这是因为 NULL 表示未知值或不存在值,任何与 NULL 的比较(包括自身)都会返回 FALSE。
15.4.3 关于字段为’ '空格字符串的情况
- 设置 NAME 字段为空字符串’ ';
-- 将表users的NAME 字段 设置为NULL
UPDATE "users" SET NAME=' ' WHERE ID=1;
- 通过 字段=‘(对应空格数量)’ ,通过 TRIM(字段) 可以查询到数据
-- 通过 字段='(对应空格数量)' ,通过 TRIM(字段) 可以查询到数据
SELECT ISNULL(TRIM(NAME),'判空成功'),* FROM "users" WHERE NAME = ' ';
SELECT ISNULL(TRIM(NAME),'判空成功'),* FROM "users" WHERE TRIM(NAME) = '';
-- IS NULL 查询不出数据
-- SELECT ISNULL(TRIM(NAME),'判空成功'),* FROM "users" WHERE TRIM(NAME) IS NULL;
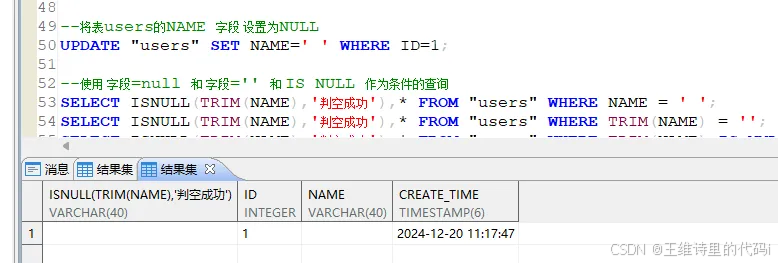
当字段为 ‘空格’ 空格字符串时,通过指定空格进行条件查询, 或者 TRIM(字段) 去空函数处理后 在于’’ 空字符串进行条件查询是能够查询到数据的! 但是与NULL就没有任何查询关系了!
15.4.4 达梦中总结
在达梦数据库中’‘空字符串 与 NULL 不是相同的(这一点与人大金仓中有区别)! 达梦中空字符串’’ 也是一个字符串数据,而不是NULL(在人大金仓数据库中会转换为NULL)。
注意:
- 字段为NULL时,WHERE 条件中的查询语句 也只能使用 ‘字段 IS NULL’ 才能查询出数据,直接使用 字段=NULL 是无效的!(与人大金仓相同)
- 由于达梦中的’’ 与 NULL 并不相同,所以在编写SQL语句时,我们在对字段进行判空的时候,也需要额外添加TRIM(字段)与’'空字符串的判断比较!而在人大金仓数据库中,则不需要在额外添加字段于空字符串的判断!
15.5 达梦数据库二进制数据导致Thymeleaf渲染异常!
15.5.1 导致项目中Thymeleaf 异常原因
- 异常信息描述
在项目适配国产数据库时,当项目切换为人大金仓数据库 和 SqlServer数据库时都能正常执行该方法!仅在使用达梦数据库时 会导致项目出现 Thymeleaf 异常!
mapper层能够正常访问达梦数据库 且 正常查询到数据内容。将查询数据 return 响应给前端时就出现了 Thymeleaf 报错异常!
- 项目中异常信息
[16:11:48] [ERROR] [org.thymeleaf.TemplateEngine.process(TemplateEngine.java:1136)] [THYMELEAF][XNIO-1 task-6] Exception processing template "wxsplogin": Error resolving template [wxsplogin], template might not exist or might not be accessible by any of the configured Template Resolvers org.thymeleaf.exceptions.TemplateInputException: Error resolving template [wxsplogin], template might not exist or might not be accessible by any of the configured Template Resolvers
at org.thymeleaf.engine.TemplateManager.resolveTemplate(TemplateManager.java:869) ~[thymeleaf-3.0.11.RELEASE.jar:3.0.11.RELEASE]
at org.thymeleaf.engine.TemplateManager.parseAndProcess(TemplateManager.java:607) ~[thymeleaf-3.0.11.RELEASE.jar:3.0.11.RELEASE]
at org.thymeleaf.TemplateEngine.process(TemplateEngine.java:1098) [thymeleaf-3.0.11.RELEASE.jar:3.0.11.RELEASE]
at org.thymeleaf.TemplateEngine.process(TemplateEngine.java:1072) [thymeleaf-3.0.11.RELEASE.jar:3.0.11.RELEASE]
at org.thymeleaf.spring5.view.ThymeleafView.renderFragment(ThymeleafView.java:362) [thymeleaf-spring5-3.0.11.RELEASE.jar:3.0.11.RELEASE]
at org.thymeleaf.spring5.view.ThymeleafView.render(ThymeleafView.java:189) [thymeleaf-spring5-3.0.11.RELEASE.jar:3.0.11.RELEASE]
- Thymeleaf 异常原因
通过使用不同数据源访问接口,对比响应数据的差异得出的得出存储二进制数据的字段导致thymeleaf报错:
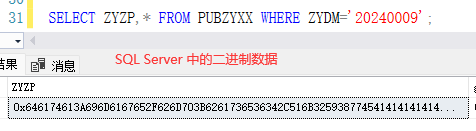
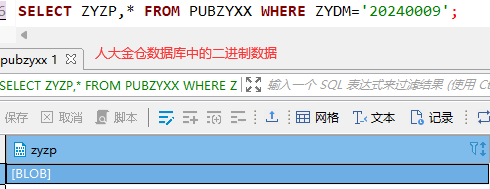
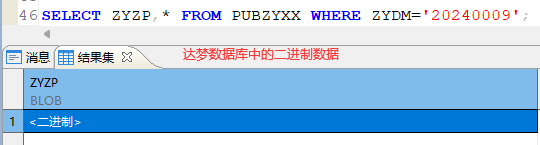
在数据库工具中查询出来三者并未区别,但是通过Mybatis 查询出来的结果就不同,这里通过人使用不同数据源进行查询后打印日志结果为:
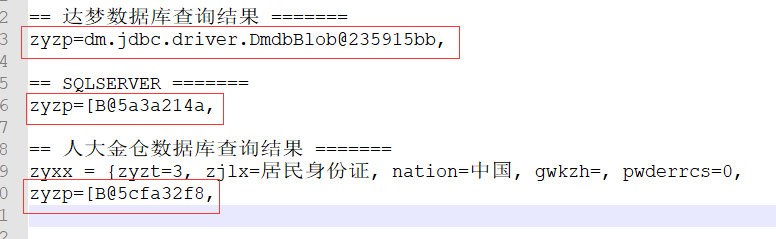
达梦数据库返回的是一个DmdbBlob对象。人大金仓和SQL Server返回的是字节数组([B表示byte数组)!
Thymeleaf在处理不同类型的对象时可能会有不同的行为。对于 二进制数据 Blob对象,它可能无法直接处理或序列化,不能被正确序列化的对象导致异常,从而导致渲染错误。Thymeleaf在渲染页面时遇到类型转换错误。
15.5.2 解决办法:
- 如果是使用JDBC驱动进行查询的二进制数据,可以直接将结果进行转换:
ResultSet rs = statement.executeQuery("SELECT * FROM your_table");
if (rs.next()) {
Blob blob = rs.getBlob("zyzp");
InputStream is = blob.getBinaryStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = is.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
is.close();
byte[] zyzpBytes = baos.toByteArray();
// 将 zyzpBytes 放入你的结果对象中
result.put("zyzp", zyzpBytes);
}
- 使用MyBatis 查询出来的结果:
/**
* 处理DM数据库 二进制对象类型 DmdbBlob
* */
if (zyxx.get("zyzp") instanceof DmdbBlob){
DmdbBlob dmdbBlob = (DmdbBlob) zyxx.get("zyzp");
// 直接赋值给 Blob 类型
Blob blob = dmdbBlob;
ByteArrayOutputStream baos = null;
InputStream is = null;
try {
is = blob.getBinaryStream();
baos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int length;
while ((length = is.read(buffer)) != -1) {
baos.write(buffer, 0, length);
}
}catch (Exception e){
try {
is.close();
} catch (IOException ex) {
throw new RuntimeException(ex);
}
}
byte[] zyzpBytes = baos.toByteArray();
// 将 Base64 编码的字符串放入结果对象中
zyxx.put("zyzp", zyzpBytes);
// 将字节数组转换为 Base64 编码的字符串
String base64Image = Base64.getEncoder().encodeToString(zyzpBytes);
}
result.put("result", "ok");
result.put("msg", "登录成功");
result.put("resultObj", zyxx);
result.put("Wxsptokenid", tokenid);
return result;
这里就是简单的将查询结果中 Thymeleaf 无法直接解析的 DmdbBlob 对象进行类型的转换操作!
应为适配了多种数据库,可以通过配置 MyBatis插件进行处理、或者在Service层中进行处理、或者在AOP 切面中进行统一处理。我这里这种情况不多就暂时先在控制层直接处理了!
15.6 达梦数据库 mapper.xml 不支持使用 临时表解决方案:
在达梦数据库中,PL/SQL 块的语法与 Oracle 数据库类似,但达梦数据库并不直接支持在 SQL 语句中混合使用 DDL(数据定义语言)和 PL/SQL 块的方式。
CREATE GLOBAL TEMPORARY TABLE 和 DROP TABLE 是 DDL 语句,而 BEGIN … END; 是 PL/SQL 块。这两者不能直接在同一个 SQL 语句中混合使用。
这就导致了 适配国产化数据库中,之前使用sqlserver数据库创建的 复杂嵌套sql语句没办法依旧使用临时表的方案来适配,需要将创建临时表、操作临时表和删除临时表分开定义。 这导致需要调整Service层接口调用的代码来调用多个接口分开执行!
如果不想改变原本Server层的代码结构,或者必须在 mybatis 的一个SELECT 标签中执行插入和查询。也可以在达梦中创建存储过程来解决上面问题,在数据库层面通过存储过程来实现,然后在 MyBatis 中调用这个存储过程。
- 关键字UNION ALL:UNION ALL 关键字可以解决 mapping.xml 文件中无法创建使用临时表的问题,采用 UNION ALL 关键字方案解决!!!
UNION ALL会返回所有查询结果的简单组合,包括重复的行。如果不希望包含重复行,则应使用UNION(它会自动去除重复行)!
-- 示例1:
SELECT column1 [, column2 ] FROM table1
UNION ALL
SELECT column1 [, column2 ] FROM table2;
-- 示例2: 汇总所有结果后在做 where 筛查
SELECT * FROM (
(SELECT column1 [, column2 ] FROM table1)
UNION ALL
(SELECT column1 [, column2 ] FROM table2)
) WHERE ....;
所有SELECT语句中列的数量和顺序必须相同。列的数据类型也应当兼容。
- WITH 表名 AS 关键字
WITH 表名 AS 关键字用于定义公用表表达式(Common Table Expressions, CTE)。它提供了一种简洁的方式来定义临时结果集,并可以在查询中多次引用这些结果集。
-- 示例代码1:
WITH XX AS (
SELECT column1, column2, ...
FROM table_name
WHERE condition
)
SELECT *
FROM XX;
-- 示例代码2:
WITH
CTE1 AS (SELECT ...),
CTE2 AS (SELECT ...)
SELECT ...
FROM CTE1, CTE2;
-- 示例代码3:
WITH RECURSIVE XX AS (
-- 初始查询部分
SELECT ...
UNION ALL
-- 递归查询部分
SELECT ...
FROM XX
JOIN ...
)
SELECT * FROM XX;
在实际运用中,一般需要上诉两种关键字进行配合使用,才能达到最终查询目的!
- 分别使用 <update> 和 <select> 标签 来完成临时表的使用
在项目中进行多数据库适配时,当mapper.xml 层代码用上述的关键字都无法满足时(比如 当使用了游标遍历后插入数据到临时表的情况),且只能采用创建临时表的方式来实现时!就只有采取将几个操作分开,分别使用 <update> 和 <select> 标签! 或者使用存储过程创建,这里举例前一种方式:
- 在mapper.xml文件中构建 临时表的创建、删除、使用 等 SQL 映射语句标签
<!-- 创建临时表 (必须独立出select中)-->
<update id="createTemporaryTable" databaseId="dm">
CREATE GLOBAL TEMPORARY TABLE FLDTABLE(
XH INTEGER,
XH2 INTEGER,
YQ VARCHAR(400),
FLD VARCHAR(400),
VALUE VARCHAR(200),
FLDTYPE VARCHAR(12)
) ON COMMIT PRESERVE ROWS ;
</update>
<!-- 删除临时表 (必须独立出select中)-->
<update id="dropTemporaryTable" databaseId="dm">
DROP TABLE FLDTABLE;
</update>
<!-- 临时表的使用操作 -->
<select id="userTemporaryTable" resultType="java.util.Map" databaseId="dm">
INSERT INTO FLDTABLE
VALUES
(1,1,'111','111',111,'111'),
(2,2,'222','222',222,'222'),
(3,3,'333','333',333,'333');
SELECT * FROM FLDTABLE;
</select>
- mapper层对应接口示例
package com.wxxssf.wxsp.testpackage.DataBaseTest.mapper;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
import java.util.Map;
/**
* @ClassName : DmDatabaseMapper
* @Description : 达梦数据库Mapper层
* @Author : AD
* @Date: 2024-12-26 下午 05:07
*/
@Mapper
public interface DmDatabaseMapper {
/**
* Description: 创建临时表测试
* @date 2024-12-31
*/
void createTemporaryTable();
/**
* Description: 删除临时表测试
* @date 2024-12-31
*/
void dropTemporaryTable();
/**
* Description: 临时表的使用测试
* @date 2024-12-31
*/
List<Map> userTemporaryTable();
}
mapper层接口中,对应xml映射文件,将需要使用到临时表的 映射SQL 进行拆分为三个接口(创建临时表、使用临时表、删除临时表)
- service层代码示例
在service层中,我们首先要根据配置文件中的配置 判断当前使用的是哪种类型的数据库,当使用到达梦数据库调用才分过的接口时,就需要调整调用的mapper层接口!
@Value("${mybatis-plus.configuration.database-id}")
private String databaseType;
/**
* Description: 测试在达梦数据库中 临时表格 TemporaryTable 的分步创建使用与删除!!!
*
* @param
* @return void
* @date 2024-12-31
*/
@Test
public void testDmTemporaryTableUseTest(){
/* 如果当前数据库类型是采用dm 就需要重新独立处理! */
if (!databaseType.equalsIgnoreCase(" dm")){
// 1. 创建临时表
dmDatabaseMapper.createTemporaryTable();
// 2. 使用临时表
List<Map> list = dmDatabaseMapper.userTemporaryTable();
System.out.println("临时表格使用查询结果展示: list.toString() = " + list.toString());
// 3.删除临时表 (gai)
dmDatabaseMapper.dropTemporaryTable();
}
/* 其它类型数据库使用时,就调用原接口适配的标签即可 */
System.out.println(" 数据库类型不是达梦数据库, 就使用其它查询接口进行数据查询!");
}
ps: 此处的 dm 根据自己的配置文件选择的数据库类型简写对应,多数据库配置文件示例如下:
spring:
servlet:
multipart:
max-request-size: 35MB
max-file-size: 30MB
thymeleaf:
prefix: classpath:/templates/
suffix: .html
mode: HTML # mode: LEGACYHTML5 去除thymeleaf严格校验
encoding: UTF-8
servlet:
content-type: text/html; charset=utf-8
cache: false
cache:
ehcache:
config: classpath:ehcache.xml
datasource:
# 项目启动需要使用哪种数据库就解除哪种数据库的注释
# ###############本地SQLServerJDBC驱动包\数据源配置:###############
# driver-class-name: com.microsoft.sqlserver.jdbc.SQLServerDriver
# url: 50FC06715AE349C3FE16C67AA142499E22430E37D0C775A666D0AD189A5024BF7036C811C25BBD34E6AE3A577FF1F3C5A0A6747BB51BA36A
# username: CD1B969004329956
# password: BC55CD215C39DFD37B5FF6B74F477B642E0EEC984593EC63
# ###############本地MysqlJDBC驱动包\数据源配置:###############
# driverClassName: com.mysql.cj.jdbc.Driver
# url: jdbc:mysql://127.0.0.1:3306/pisp?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&allowMultiQueries=true&useSSL=false&serverTimezone=Asia/Shanghai
# username: xxxxx
# password: xxxx..
# ###############本地人大金仓KingBase8驱动包\数据源配置:###############
# driverClassName: com.kingbase8.Driver
# url: 437A064F7A18790C98EAFBB90A7BA6544D9F874327A051F75FC387052C225E3BC8EA61D00413512119B8056445D876CD
# username: F407C1041FF1360A
# password: 00C2459109F6EA6FA338FD428E6F29E4
# ###############本地达梦数据库DM8驱动包\数据源配置:###############
driver-class-name: dm.jdbc.driver.DmDriver
url: DEBC4FDF08D163353A5C7B280F94DA370E3EA926927CA610CE2CE8B374B184F53D812F7BEB3DB11F
username: 17735606C89B55C0
password: 64CFB38713E3CC5AB19441F291B440AB
# 多数据库适配配置
mybatis-plus:
mapper-locations: classpath*:/mapping/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
database-id: dm #目前仅支持 sqlserver/mysql/kes/dm [oracle]
15.7 空字符串与字符串的比较行为
ps: 在做数据库适配时,项目中的SQL语法需要注意! 涉及到与空字符串比较的条件根据数据库类型,一定要进行特殊处理!否则查询结果会有所差异!
- 数值类型字符串与空字符串的比较
| SqlServer数据库 | 达梦数据库 | 人大金仓数据库 | ||
|---|---|---|---|---|
| 1 | ‘123’与’'(空字符串) | 字符串(中文、英文、数字)始终大于空字符串 | 无法比较,走ELSE | 无法比较,走ELSE |
| 2 | ‘123’ 与 null 比较 | 无法比较,走ELSE | 无法比较,走ELSE | 无法比较,走ELSE |
| 3 | ‘123’ 与 ‘-321’ | 按实际数值大小比较 | 按实际数值大小比较 | 按实际数值大小比较 |
在达梦、人大金仓数据库中 字符串与空字符串无法比较。 但是在 SqlServer 中 非空字符串(中文、英文、数字) 均大于空字符串!
其它类型的比较就不做扩展了可以通过下面代码自行测试!
-- 在 达梦/人大金仓 数据库中的测试:
DECLARE
P1 VARCHAR(10) := '中文';
BEGIN
IF ('123'>P1) THEN
SELECT '字符串大';
ELSEIF ('123' < P1) THEN
SELECT '字符串小';
ELSEIF ('123' = P1) THEN
SELECT '字符串与之相等';
ELSE
SELECT '字符串与空字符串无法比较';
END IF;
END
-- Sqlserver数据库中
DECLARE
@P1 VARCHAR(10) = '一';
IF ('123'>@P1)
BEGIN
SELECT '大于';
END
ELSE IF ('123' < @P1)
BEGIN
SELECT '小于';
END
ELSE IF ('123' = @P1)
BEGIN
SELECT '相等!';
END
ELSE
BEGIN
SELECT '字符串与空字符串无法比较';
END ;
特别需要注意的是 : 在达梦数据库和人大金仓数据库中,即使是使用 != 符号进行比较,也是不成立的!
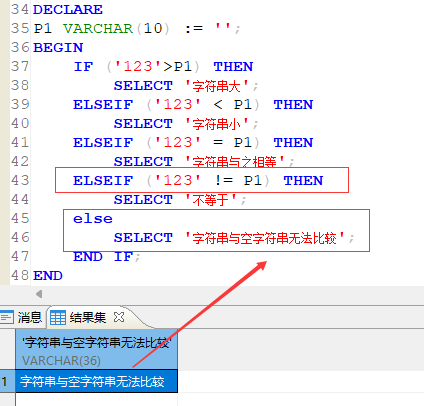
在适配SQL语句时一定要注意此处区别!
[Other tag:]
- ps:
注意达梦数据库管理工具中,查询数据结果较多时,是以分页查询的方式展示的!!
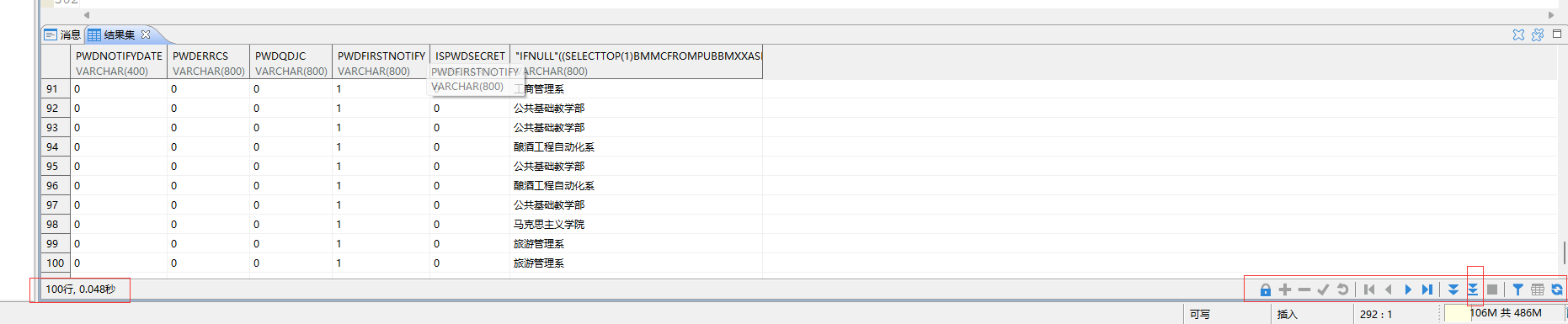
● ps:
达梦数据迁移工具bug,当迁移表格字段数量过多时,可能会出现迁移过去的表格字段数量与数据源中表格的字段数量不一致! 在进行迁移配置的时候需要注意 目标迁移数据表格 迁移的字段数量:
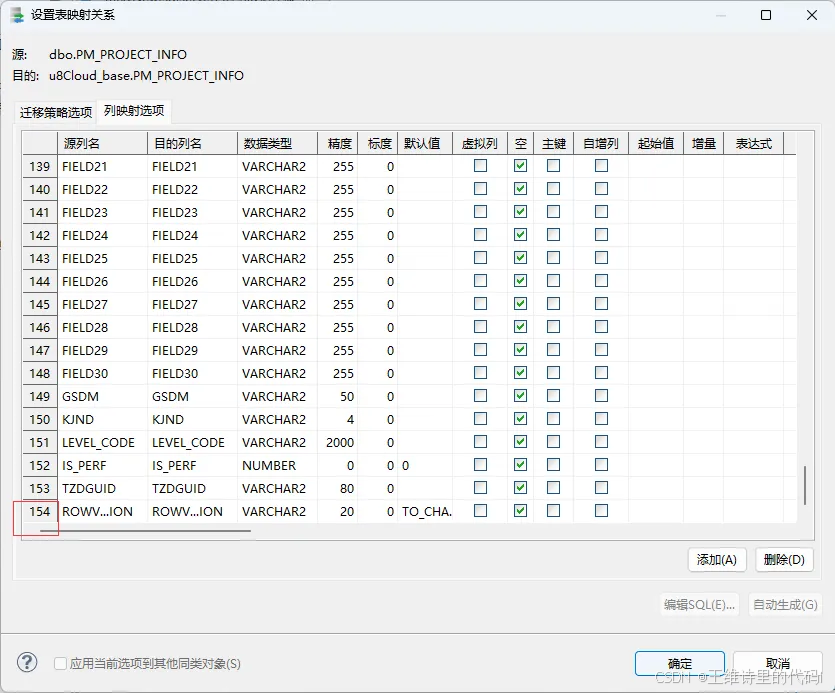
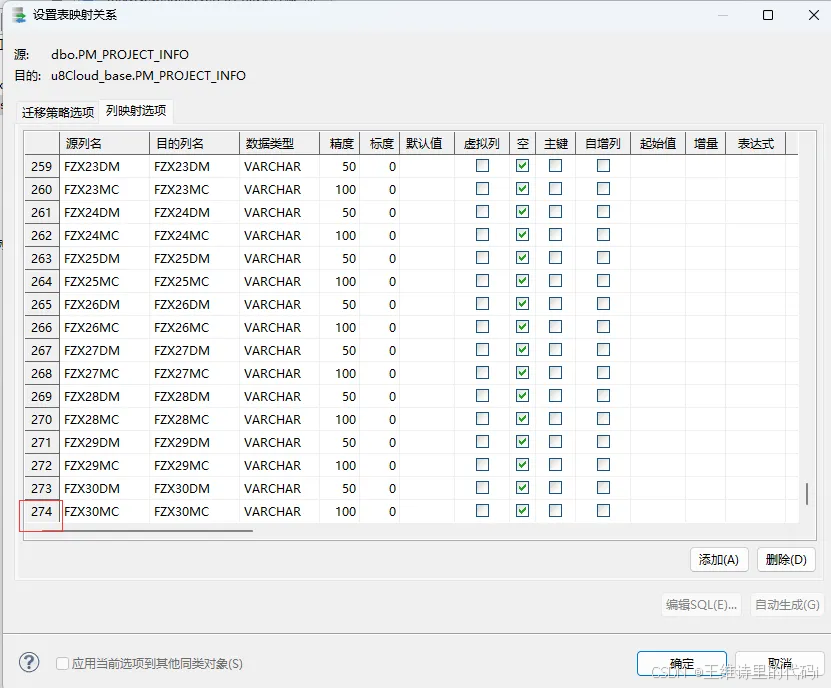
重新打开迁移任务,字段重新加载后 数量正常:

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









