







近期在一直学习《Java编程理想》一书,作为Java工程师必读的书目之一,确实引人入胜,语言深入浅出。今天在看持有对象一节的时候,发现了一个很奇怪的问题。话不多说,直接上代码。
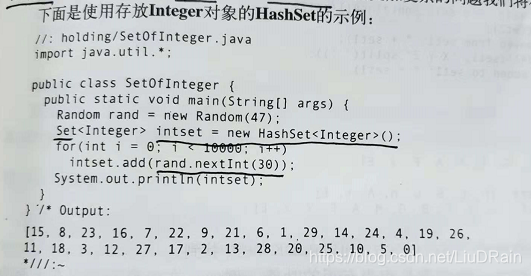
这是书中第231页的例子。
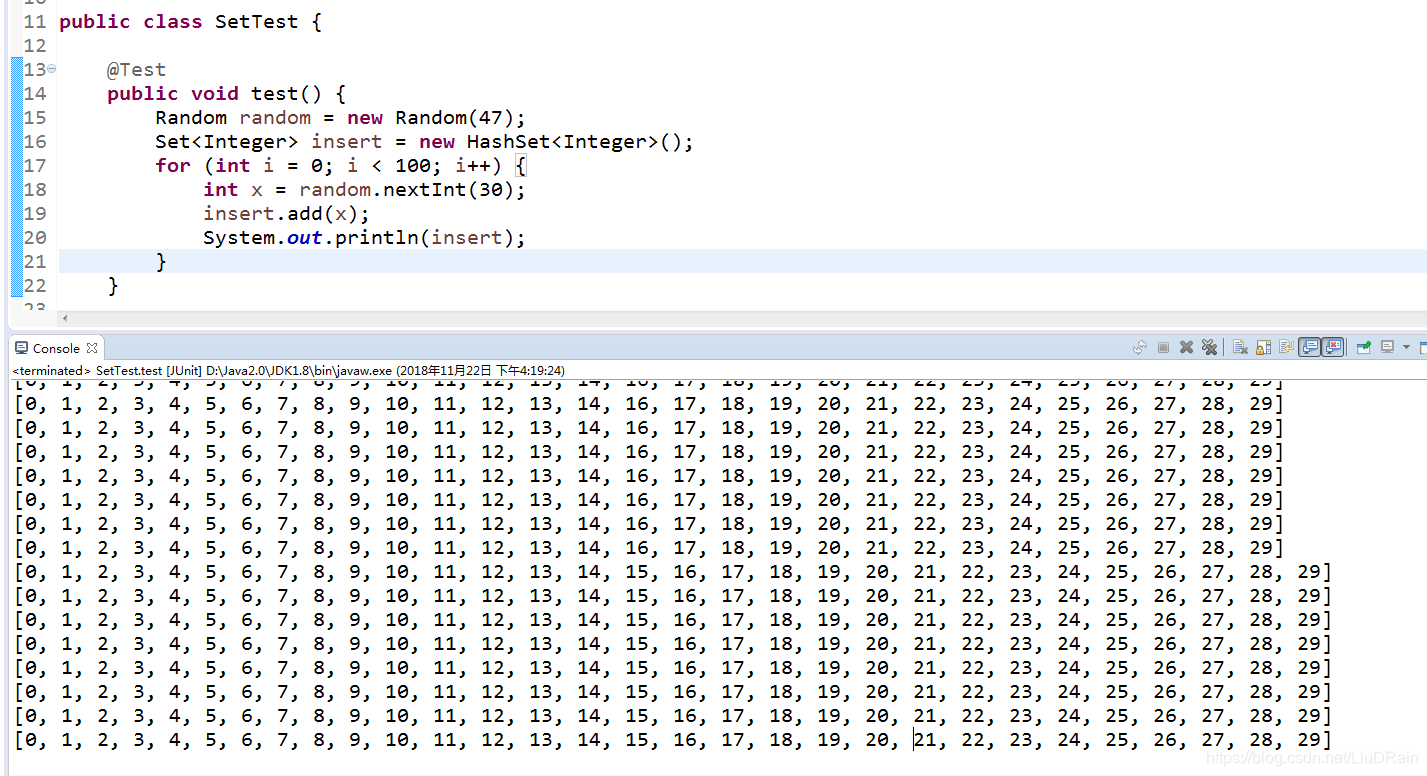
这是我电脑里运行的结果,很明显,HashSet不负责排序的,但是输出的确实有顺序的。
网上搜索了一些原因,比较中肯的一个说法。
通常插入HashSet的是Integer,其hashCode()实现就返回int值本身。所以在对象hashCode这一步引入了巧合的“按大小排序”。然后HashMap.hash(Object)获取了对象的hashCode()之后会尝试进一步混淆。JDK8版java.util.HashMap内的hash算法比JDK7版的混淆程度低;在[0,> 2^32-1]范围内经过HashMap.hash()之后还是得到自己。单纯插入数字则正好落入这个范围内。外加load factor正好在此例中让这个HashMap没有hash冲突,这就导致例中元素正好按大小顺序插入在HashMap的开放式哈希表里。
--------------------- 作者:花小胖
来源:CSDN 原文:https://blog.csdn.net/qq_23835497/article/details/77600609
版权声明:本文为博主原创文章,转载请附上博文链接!
我有尝试了一下是不是JDK的原因,下面是JDK7的代码:
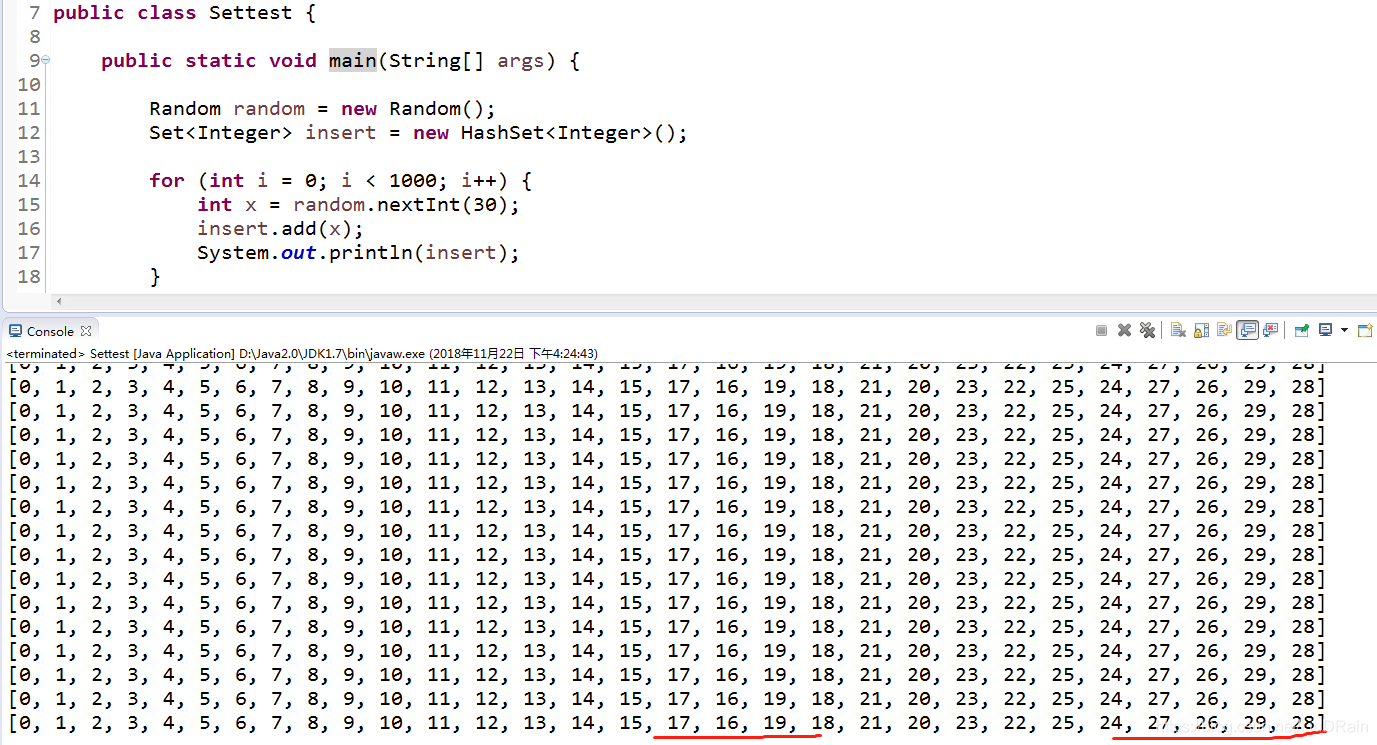
很明显,JDK8比JDK7的对于hashset存储算法是不一样的。但是并不一定意味着HashSet跟TreeSet有同样的功能。上文@花小胖中也说到了。
书中原文说:
Set不接受重复元素。HashSet提供最快的查询速度,TreeSet保持元素出于排序状态。LinkedHashset以插入顺序保存元素。
换句话说,可以理解是HashSet的功能是提供最快查询速度的,恰巧因为存的Integer,hashCode巧合了按排序。并不是意味HashSet保持排序。需要保持排序还是用TreeSet。














 1299
1299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









