







MySql技术内幕
第一章 MySql介绍和SQL基础
1.3 数据库基本术语
1.3.1 数据库的组织结构

1.3.3 MySQL的体系结构

1.4 MySQL
MySQL采用的是C/S体系结构,服务器将运行在存放数据库的主机上,而客户需要通过网络来连接到服务器。本节的重点是,mysql客户端,它负责将接受你发出的查询命令,把它们发送到服务器执行,再把执行结果显示给你看。
使用create user 和 grant 语句来创建一个用户
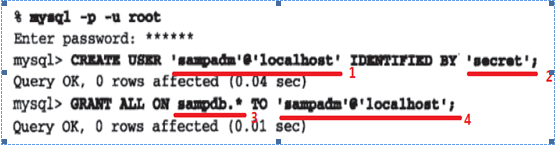
说明: 1 格式为’用户名’@’主机地址’ 2 ‘密码’
3. 数据库的所有权限 4 将权限赋给哪个用户
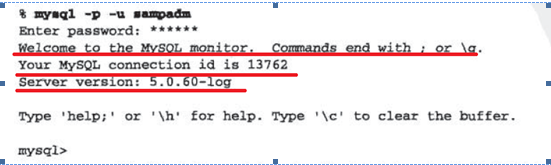
1.4.3 如何建立和断开与服务器的连接
连接的建立:

说明: -h 连接的主机名-u 用户名 -p 密码
注意:如果mysqld程序是装在了本机上,可以省略 -h 选项,-p 选项和密码之间是没有空格的,而 -h 和 -u 和输入的内容之间,是有空格的。
当出现如下的提示信息时,表明连接已经成功!
连接的退出
在连接上Mysql后,我们随时可以通过quit或exit或\q来退出
1.4.4 执行SQL语句
Mysql的语句终止符
(1); (2)\g (3)\G
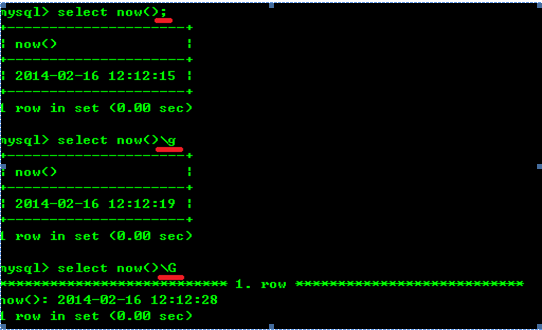
说明: \g代表语句终止符,含go的意思。\G是竖行显示结果的意思。
如果你已经输入了好几行命令,但不想执行它们,你可以输入\c(取消)它们。
1.4.5 创建数据库
数据库的创建
语法:
create database [if not exists] db_name[character set charset] [collate collation]
示例:

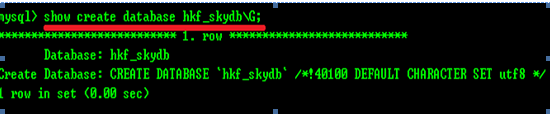
要查看所建立的数据库的信息,可以使用show create database db_name\G语句。例如:
数据库的选定
查看当前所选定的数据库: select database();
查看服务器上的所有数据库: showdatabase;
选定一个数据库: use db_name;
示例:

1.4.6 数据表的创建
语法:
drop table if existstb_name;
create table tb_name(colomn_specs) [character setcharset] [collate collation] [engine=engine_name]
示例:
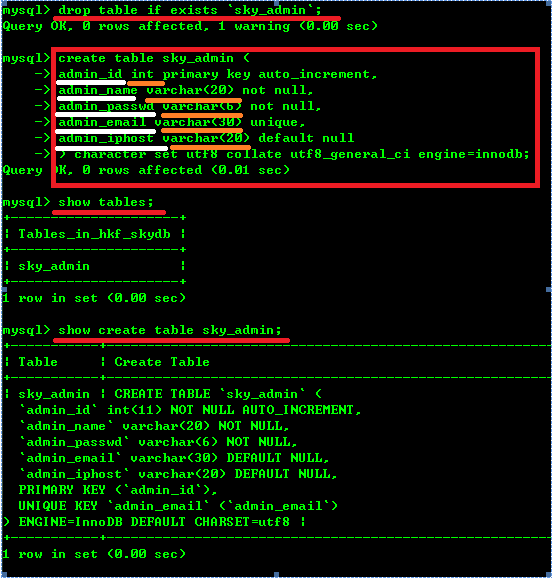
查看数据库中所有的表: showtables;
查看数据库中某一个特定的表: showcreate table tb_name;
查看数据库中某一个表各个列的完整定义:desc tb_name;
注意:
(1).上面在创建表前,加上了一句’droptable if exists sky_admin’,是为了防止在创建表时,该表在数据库中已经存在,从而报错。
(2).在创建表时,表名后的(colomn_specs)每一行应该包含6个值,分别是‘字段名’、‘类型’、‘是否为空’、‘索引’、‘默认值’、‘额外’
1.4.7 如何添加新的数据行
利用insert语句添加数据
(1).一次性的列出全部数据列的值。
语法:insert into tb_namevalues(value1,value2,...),(value1,value2...),...
示例:

注意:(1).当一次性为全部列填入值(即没有指定为某些列)时,关键字values后面的括号里必须为数据表的全体数据列准备好对应的值,这些值的先后顺序也必须与各个列在数据表里的存储顺序一致。
(2).MySQL里的字符串和日期必须放在单引号(‘’)里或双引号(“”)里才能被引用,且放在单引号(‘’)里更加规范。
当某一数据列定义时为int类型,主键,自增,当你没有为该数据列插入数据(或插入了null)时,该字段默认是从0开始自增的。
(2).直接对数据列赋值,先给出数据列的名字,再给出它们的值。
语法:insert into tb_name(col_name1,col_name2,...) values(value1,value2,...),(value1,value2,...)...;
示例:

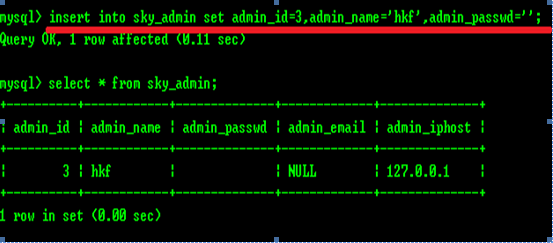
NULL与’’的区别:
空(NULL)值表示数值未知。空值不同于空白或零值。没有两个相等的空值,比较两个空值或将空值与任何其他的数值比较均返回未知,这是因为每个空值均为未知。
在写入数据的时候,空字符串’’也是一个确定的值,所以就算你定义了notnull也是可以被写入的。
(3)还可以用col_name=value(而非values列表)的SET子句对数据列赋值。
语法:insert into tb_name setcol_name1=value1,col_name2=value2,…
示例:
不过这种方法,只能增加一行数据,不能一次性添加多行数据。
1.4.9 检索信息
select语句的通用形式:
NULL值
如果需要对null值进行查找,就必须使用一种特殊的语法。你不能使用=、<>或!=来测试它们是相等还是不相等,你必须使用is null或is not null来判断。
示例:
3.如何对查询结果进行排序
语法:order by column_name asc(或desc)
order by语句可以对查询结果按多个数据列排序,而每一个数据列又都可以互不影响的分别按升序或降序进行排序。
asc(升序) 小的在前
desc(降序) 大的在前
说明:上述例子中,先按’admin_iphost’进行升序(asc)排序,而admin_iphost相同的数据行,再按’admin_name’进行降序(desc)排序。
对于包含null的数据行,如果按升序排序,它们将出现在查询结果的开头;如果按降序排序,它们将出现在查询结果的末尾。如果你想让包含null值的数据行必须出现在查询结果的开头或末尾,就必须额外增加一个排序数据列以区分null和非null值。
4 如何限制查询结果中的数据行个数
limit 6:限制6行,从查询结果中取前6行
limit 1,6:跳过前1个数据行,再返回6行
5.对输出列求值和命名
我们可以利用as name短语给输出列另外取一个名字,我们把它称为列的别名(alias)。
示例:
6.与日期有关的问题
日期中的年、月、日可分别用YEAR()、MONTH()、DAYOFMONTH()分别分离出来。
今天生日的人
TIMESTAMPDIFF
如果你想知道两个日期的时间间隔,拿它们相减就可以了。timestampdiff()函数的第一个参数,用以指定计算结果的单位。
DATE_ADD()或DATE_SUB()
这两个函数的输入参数,一个是日期值,一个是时间间隔值,返回结果则是一个新的日期值。
7.模式匹配
模式匹配需要使用特殊操作符(like或 not like),还需要你提供一个包含通配字符的字符串。‘_’只能匹配一个字符,‘%’匹配任何一个字符序列(包括空序列在内)。
示例:
9.如何生成统计信息
distinct:将查询结果中重复的数据行去除掉。
示例:
count(*):统计被选中的数据行的总数
count(数据列名称):统计满足条件的字段中非null数据行的总数
count()和distinct联合起来,可以统计出查询结果里到底有多少不同的非null值。
group by:分门别类的统计数据
Having子句
Having子句与where语句的相似之处就是它们都是用来设定查询条件的;不同之处就是where子句后不能使用表达式,而Having子句可以。
1.4.10 如何删除或更新现有的数据行
Delete语句的基本格式:
delete from tb_namewhere which rows to delete;
示例:
Update语句的基本格式
语法:update tb_name set which columns to change
where which rows to update
示例:
用一条语句修改多个数据列
如果,某一个字段允许设置为null,那么使用update语句将其设置为null,就能将其变为未设置的状态。
第二章 使用SQL管理数据库
2.1 MySQL服务器的SQL模式
SQL模式简介
SQL模式的设置
查看当前的SQL模式
示例:
2.2 MySQL标识符的语法和命令规则
加反引号(``)的标识符
示例:
标识符的长度
标识限定符(.)
2.3 SQL语句中字母大小写的问题
2.4 字符集的支持
2.4.1 字符集的设定
2.4.2 确定可供选用的字符集和当前设置
示例:
查看MySQL当前的字符集和排序方式的设置状态
示例:
2.5 数据库的选定、创建、删除和变更
2.5.1 数据库的选定
选定的方式
注意:当与数据库的连接断开时,该服务器上的默认数据库的概念也就不复存在了。也就是说,当你下次再打开连接时,它并不会记得你上次选的默认数据库。
2.5.2 数据库的创建
示例:
要查看现有数据库的定义可以使用show create database db_name;
示例:
2.5.3 数据库的删除
只要你有足够的权限,删除一个数据库和创建一样简单。
语法:dropdatabase db_name;
示例:
2.5.4 数据库的变更
使用alter database语句可以改变数据库的全局特性。就目前而言,数据库的全局特性还只有默认字符集和排序规则。
语法:alter database db_name character setcharset collate collation
示例:
2.6 数据表的创建、删除、索引和变更
2.6.1 存储引擎的特征
可用show engines;来查看数据库现有的存储引擎。
数据表在硬盘上的存储方式
InnoDB存储引擎的特性
2.6.2 创建数据表
数据表的定义:
createtabale tb_name (col_pecs5项) character set charset collate collationengine=innodb
我们在这里重点介绍创建表的几种变体
改变存储特性的数据表选项
只在数据表不存在时才创建
临时数据表,服务器会在客户会话结束时自动删除它们
从一个数据表或是从一次select查询的结果来创建数据表
使用merge数据表,分区数据表,federated数据表
1. 数据表选项
2. 只创建原本没有的数据表
要想创建一个原本没有的数据表
drop table if existstb_name;
create table tb_name(col_pecs5项) characterset charset collate collation engine=innodb;
3. 临时数据表
如果,你在数据表的创建语句里加上temporary关键字,服务器将创建出一个临时的数据表,它在你与服务器的连接断开时自动消失:
create temporarytable tb_name()…
4 从其他数据表或查询结果创建数据表
2.6.3 删除数据表
语法: drop (temporary) table if exists tb_name
示例:
2.6.4 为数据表编制索引
索引是加快对数据表访问内容的基本方法,尤其是在涉及多个数据表的关联查询里。
2. 创建索引
索引的类型
alter table语句比create index语句更加灵活,因为它能用来创建MySQL所能支持任何一种索引。
alter table tb_name add index index_name(index_columns);
alter table tb_name add unique index_name(index_columns);
alter table tb_name add primary key (index_columns);
示例:
一次性添加多个索引
示例:
3 删除索引
删除索引的工作,可以使用drop index或alter table语句来完成,但删除索引时,drop index都必须给出要删除索引的名称。
语法: alter table tb_name drop indexindex_name;
altertable tb_name drop index index_name;
altertable tb-name drop primary key;
注意:当删除主键索引时,使用的语法为altertable tb_name drop primary key;而当删除其他类型的索引时(不论是index还是unique类型),使用的语法为alter tabletb_name drop index index_name;
当你不知道索引的名字的时候,可以使用showcreate table tb_name\G便可以看到完整的数据表的定义。
当你从数据表删除数据列时,索引也会隐式的受到影响。当删除的列是索引的组成部分时,MySQL将在索引的定义里删除那个列。当索引的全部列都被删除时,索引也会被删除。
2.6.5 改变数据表的结构
1.改变数据列的数据类型
语法:alter table tb_name modify col_nametype [null 或not null indexdefault extra];
在改变数据类型时,重新为该列命名。
alter table tb_name change col_oldName col_newName type […]
示例:
2 添加与删除一个数据列
语法:
添加:alter table tb_name add column_name type[[null or not null] index default extra];
删除:alter tb_name drop column column_name;
示例:添加和删除数据列
2 让数据表改用另一种数据引擎
语法:alter table tb_name engine=enginses;
3重命名一个数据表
语法:alter table tb_name1 rename to tb_name2;
rename table tb_name1 to tb_name2;
示例:重命名数据表
2.8 利用联结对多个数据表进行检索
2.8.1 内联结
语法:
select tb1.*,tb2.* from tb1 inner join tb2 on tb1.id=tb2.id where …
2.8.2 外联结
语法:
select tb1.*,tb2.* from tb1 left join tb2 on tb1.id=tb2.id where …(来自tb1表中的每一个数据行在结果集中都会显示,不管它有没有匹配)
select tb1.*,tb2.* from tb1 right join tb2 on tb1.id=tb2.id where …(同上left join)
2.11 视图
视图是一种虚拟的数据表,它的行为和数据表一样,但并不包含真正的数据。它们是用底层数据表或其他视图定义出来的“假”数据表,用来提供查看数据表数据的一种方法。这通常会简化应用程序。
在使用视图时,你只能使用它所定义的列。也就是说,如果底层数据表中的列没有在视图中定义时,你是不能使用的。
在默认的情况下,视图里的数据列的名字与select查询出来数据列的名字是相同的。如果你想使用别名,需要在定义视图后面的括号内列出那些新名字。
视图可以用来自动完成数学运算。例如:
视图是否可更新
2.13 事务处理
示例:
执行事务的另一种方法(set autocommit)
示例:
2.13.2 使用事务保存点
2.14 外键和引用完整性
2.14.1 外键的创建和使用
在子表里创建外键的定义如下
第四章 存储程序
4.1 复合语句与语句分隔符
复合语句
创建存储过程的示例
存储过程的调用
4.2.2 存储过程的参数类型
带in类型的存储过程
带out类型的存储过程
4.3 变量
1.对于本地变量,使用declare来声明
2.可以用default子句给变量赋一个默认值,也可以使用set子句重新给变量赋值。
示例:变量的定义与赋值。
带输入、输出参数的变量的定义
4.4 条件的执行
if () then
…;
elseif() then
…;
else
…;
end if;
if…else示例
4.5 循环
4.6 与数据库的交互
4.6.1 对本地变量使用selectinto
4.6.2 使用游标
4.6.3 返回结果集的存储过程
注意:变量的命名与数据表中字段的名字,最好不要取一样。否则,存储过程在执行时会产生疑惑,运行出错。
4.6.4 内嵌不返回结果集的SQL语句
即在存储过程中,使用insert、update、delete和DDL语言。
4.7 存储函数
存储函数和存储过程很像:它们都是包含一个或多个MySQL语句的被命名的存储单元。和存储过程不同的有以下几点:
(1).函数的参数列表中参数的类型只能为IN类型。OUT和INOUT类型都是不被允许的。制定IN类型是被允许也是缺省的。
(2).函数必须返回一个值。它的类型被定义于函数的头部。
(3).函数能被SQL语句所调用。
(4).函数不能返回任何结果集。
5 语言基础
5.1.1 变量的赋值
你可以使用,set语句进行变量的赋值。基础语法为:
setvariable1=value1[,variable2=value2,variable3=value3,...];
5.1.2 参数
参数的类型
IN
除非显示指定,否则所有参数的类型默认为IN类型。由主叫程序传入,在内部可以做任何的修改,但对在主叫程序中不起作用。
OUT
一个out参数可以被存储程序所修改,并且这个被修改的值可以在主叫程序中生效,主叫程序必须提供一个变量来接收out参数所传出的值,当存储程序开始时,任何OUT变量的值都被赋予NULL,不管这个值在主叫程序中是否被赋予其他值。
INOUT
INOUT参数同时扮演者IN和OUT参数的角色。那意味着,主叫程序可以提供一个值,而被叫程序自身可以修改这个参数的值,并且当存储程序结束时主叫程序对该修改后的值具有访问权限。
5.2 操作符
5.2.1 数字操作符
5.2.2 比较操作符
5.2.3 逻辑操作符
5.2.4 位操作符
5.2.5 表达式
5.2.6 内建函数
5.3 数据类型
5.3.1 字符串数据类型
5.3.2 枚举数据类型
5.4 程序块、条件控制、迭代循环
5.4.1 程序块的结构
4个要点:
[1]在块中定义的变量在块外部不可见
[2]内部块的变量可以覆盖外部块定义的变量(相当于重新赋值)
[3]在内部块中重载的变量的修改对于块的外部并不可见
[4]使用leave语句来离开(终止)一个标签块
5.4.2 条件控制
(1)if语句
(2)if-then-else语句
(3)if-then-elseif-else语句
(4) 简单case语句
(5) 查询case语句
5.4.3 循环中的迭代处理
while循环

















 1136
1136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









