






Shell正则表达式—awk
一、awk命令
1、awk概述
AWK是一个优良的文本处理工具,Linux及Unix环境中现有的功能最强大的数据处理引擎之一。这种编程及数据操作语言(其名称得自于它的创始人阿尔佛雷德·艾侯、彼得·温伯格和布莱恩·柯林汉姓氏的首个字母)的最大功能取决于一个人所拥有的知识。awk经过改进生成的新的版本nawk,gawk,现在默认linux系统下日常使用的是gawk,用命令可以查看正在应用的awk的来源(ls -l /bin/awk )。
2、awk工作原理
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出。
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次。
3、awk优势
支持if for 函数 数组
筛选,过滤,统计总结
4、三剑客的区别
sed—无交互式替换修改文件
awk grep—筛选过滤匹配
awk—可以切分整行内容,不会默认输出
5、awk格式
awk 选项 命令部分---用'{}'引起来 文件名
6、内置变量
-F //指定分隔符 [:x]以冒号和x为分隔符
$0 //打印整行
$1 //过滤第一列,以此类推(默认以空格或TAB为分割)
$n //过滤第N列
NF //打印列数
NR //打印行号
FS //指定字段分隔符
OFS //输出时以什么分隔
RS ORS //RS和ORS设置为“\n”,表示输入数据流中的每一行作为一条记录,输出时每条记录之间也以“\n”进行分割
二、实例

[root@localhost ~]# awk '{print}' zz //打印这个文件所有行,等同于awk '{print $0}' zz
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# awk '{print $1}' zz //过滤第一列
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
问题:应该是过滤第一列,但是依旧全部输出了。
解决:因为默认以空格作为列分隔,在这个文件中没有。现在我们加一个空格。
[root@localhost ~]# awk '{print $1}' zz
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
完美解决。
亦或者可以通过指定分割符来解决。
[root@localhost ~]# awk -F: '{print $1}' zz //指定分隔符为:
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
注:打印第几列就$几,以此类推。
[root@localhost ~]# awk -F: '{print $1,$2}' zz //以冒号为分隔打印第一第二列
root x
bin x
daemon x
adm x
lp x
sync x
shutdown x
halt x
mail x
operator x
注:$1,$2不能直接用空格,要用双引号引起来。
原因:awk自动把内容当变量,输出常量用引号引起来。
[root@localhost ~]# awk -F: '{print $1" "$2}' zz
root x
bin x
daemon x
adm x
lp x
sync x
shutdown x
halt x
mail x
operator x
awk可以输出中文,比较友好
[root@localhost ~]# awk -F: '{print "用户名"$1"的uid是"$3 }' zz
用户名root的uid是0
用户名bin的uid是1
用户名daemon的uid是2
用户名adm的uid是3
用户名lp的uid是4
用户名sync的uid是5
用户名shutdown的uid是6
用户名halt的uid是7
用户名mail的uid是8
用户名operator的uid是11
注:中午要用双引号引起来
NF:打印列数
[root@localhost ~]# awk -F: '{print NF}' zz
7
7
7
7
7
7
7
7
7
7
[root@localhost ~]# awk -Fx '{print NF}' zz
2
2
2
2
2
2
2
2
2
2
不同的分隔符列数也有不同
打印最后一列:
[root@localhost ~]# awk -F: '{print $NF}' zz
/bin/bash
/sbin/nologin
/sbin/nologin
/sbin/nologin
/sbin/nologin
/bin/sync
/sbin/shutdown
/sbin/halt
/sbin/nologin
/sbin/nologin
注:NF=7,$7是最后一行
打印行号:
[root@localhost ~]# awk -F: '{print NR}' zz
1
2
3
4
5
6
7
8
9
10
打印行号和内容:
[root@localhost ~]# awk -F: '{print NR,$0}' zz
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
友好显示:
[root@localhost ~]# awk -F: '{print NR"\t"$0}' zz
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
模式匹配:
[root@localhost ~]# awk -F: '/root/{print}' zz
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# awk -F: '/^root/{print}' zz
root:x:0:0:root:/root:/bin/bash
匹配有root字符的,和以root开头的
结尾同理
模糊匹配



打印第二列有感叹号的列的第一列内容
NR==1 //第一行
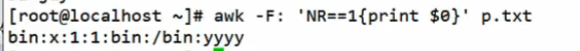
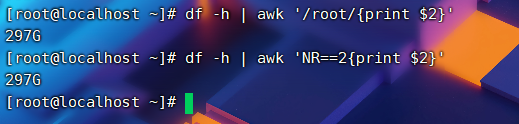
运算
BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
END一般用来做汇总操作,仅在读取完数据记录之后执行一次
















 199
199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









