









Flume个人心得笔记之Sink安装
目录
4.编辑文件 如果误操作,可以按照Ctrl +Backspace 回退
1.报错是因为flume缺少相关hadoop的依赖jar包,
2.但是一个一个找特别麻烦,所以解决办法是将hadoop的jar包都拷贝到flume的lib目录下:
一.Logger Sink
一、概述
- 记录指定级别(比如INFO,DEBUG,ERROR等)的日志,通常用于调试
- 要求,在 --conf(-c )参数指定的目录下有log4j的配置文件
- 根据设计,logger sink将body内容限制为16字节,从而避免屏幕充斥着过多的内容。如果想要查看调试的完整内容,那么你应该使用其他的sink,也许可以使用file_roll sink,它会将日志写到本地文件系统中
二、可配置项说明
| 配置项 | 说明 |
| channel | 绑定通道 |
| type | logger |
三、示例
默认配置,就不演示了
https://blog.csdn.net/LiuY521/article/details/94721238
二.File_roll Sink
一、概述
- 在本地系统中存储事件
- 每隔指定时长生成文件保存这段时间内收集到的日志信息
二、可配置选项说明
| 配置项 | 说明 |
| channel | 绑定通道 |
| type | file_roll |
| sink.directory | 文件被存储的目录 |
| sink.rollInterval | 30 记录日志到文件里,每隔30秒生成一个新日志文件。如果设置为0,则禁止滚动,从而导致所有数据被写入到一个文件中。 |
三、示例
1.复制文本
mv basic2.conf filerollsink.txt
2.编辑配置

3.启动指令 启动不了,杀死对应进程重新启动

4.编辑文件 如果误操作,可以按照Ctrl +Backspace 回退
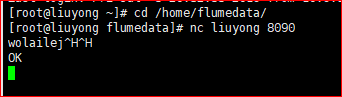
5.查询数据

三.HDFS Sink
一、概述
- 此Sink将事件写入到Hadoop分布式文件系统HDFS中
- 目前它支持创建文本文件和序列化文件,并且对这两种格式都支持压缩
- 这些文件可以分卷,按照指定的时间或数据量或事件的数量为基础
- 它还通过类似时间戳或机器属性对数据进行 buckets/partitions 操作
- HDFS的目录路径可以包含将要由HDFS替换格式的转移序列用以生成存储事件的目录/文件名
- 使用这个Sink要求haddop必须已经安装好,以便Flume可以通过hadoop提供的jar包与HDFS进行通信
二、可配置选项说明
| 配置项 | 说明 |
| channel | 绑定的通道 |
| type | hdfs |
| hdfs.path | HDFS 目录路径 (hdfs://namenode/flume/webdata/) |
| hdfs.inUseSuffix | .tmp Flume正在处理的文件所加的后缀 |
| hdfs.rollInterval | 文件生成的间隔事件,默认是30,单位是秒 |
| hdfs.rollSize | 生成的文件大小,默认是1024个字节 ,0表示不开启此项 |
| hdfs.rollCount | 每写几条数据就生成一个新文件,默认数量为10 每写几条数据就生成一个新文件, |
| hdfs.fileType | SequenceFile/DataStream/CompressedStream |
| hdfs.retryInterval | 80 Time in seconds between consecutive attempts to close a file. Each close call costs multiple RPC round-trips to the Namenode, so setting this too low can cause a lot of load on the name node. If set to 0 or less, the sink will not attempt to close the file if the first attempt fails, and may leave the file open or with a ”.tmp” extension. |
三、示例
1.备份一份文件
vim HDFS.conf
2.编辑配置

3.启动

4.确保HDFS启动
5.传输数据
报错 格式不支持

配置写错了
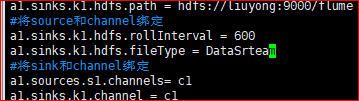
6.查询

四、存在问题
1.报错是因为flume缺少相关hadoop的依赖jar包,
找到以下的jar包,放到flume的lib目录下即可。
- commons-configuration-1.6.jar
- hadoop-auth-2.5.2.jar
- hadoop-common-2.5.2.jar
- hadoop-hdfs-2.5.2.jar
- hadoop-mapreduce-client-core-2.5.2.jar
2.但是一个一个找特别麻烦,所以解决办法是将hadoop的jar包都拷贝到flume的lib目录下:
- 执行:
- scp common/*
- common/lib/*
- hdfs/*
- hdfs/lib/*
- mapreduce/*
- mapreduce/lib/*
- tools/lib/*
- 10.42.60.249:/home/software/flume/lib/
四.Avro Sink
一、概述
- 将源数据进行利用avro进行序列化之后写到指定的节点上
- 是实现多级流动、扇出流(1到多) 扇入流(多到1) 的基础
二、可配置选项说明
| 配置项 | 说明 |
| channel | 绑定的通道 |
| type | avro |
| hostname | 要发送的主机 |
| port | 要发往的端口号 |
三、多级流动
1.概述
- 让01机的flume通过netcat source源接收数据,然后通过avro sink 发给02机
- 02机的flume利用avro source源收数据,然后通过avro sink 传给03机
- 03机通过avro source源收数据,通过logger sink 输出到控制台上
2.实现步骤
- 准备三个节点,并安装好flume(关闭每台机器的防火墙)
- 配置每台flume的配置文件
3.第一个云主机配置

4.第二个云主机配置

5.第三个云主机配置

6.启动第三个节点 往后向前启动

7.输入数据
8.接收数据

四、扇入流
1.编辑文件
vim shanru.conf
2.第一个和第二个配置相同

3.第三个节点

4.启动 从最后一个启动
../bin/flume-ng agent -n a1 -c ../conf -f 要启动的文件 -Dflume.root.logger=INFO,console

5.发送数据
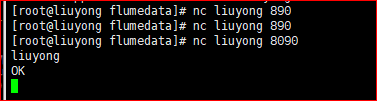
6.接收数据
五、扇出流
1.编辑文件
vim shanchu.conf
2.第一个节点配置

3.第二,第三节点配置一样

4.启动

5. 2和3节点会接收数据

出现叹号,提示有数据传输
6.查看数据
















 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









