









一、基本介绍
Apriori算法是经典的挖掘频繁项目集和关联规则的数据挖掘算法。当定义问题时,通常会使用先验知识或者假设,这被称作"一个先验"。算法使用频繁项目集的先验性质,即频繁项目集的所有非空子集也一定是频繁的。Apriori算法使用一种称为逐层搜索的迭代方法,其中k项集用于探索(k+1)项集。首先通过扫描数据库,累计每个项的计数,并收集满足最小支持度的项,找出频繁1项集的集合。该集合记为L1。然后,使用L1找出频繁2项集的集合L2,使用L2找出L3……如此下去,直到不能再找到频繁k项集。每找出一个Lk需要一次数据库的完整扫描。Apriori算法利用频繁项目集的先验性质来压缩搜索空间。
二、核心思想
项目空间集理论:
定理1:若项目集X是频繁项目集,则它的所有非空子集都是频繁项目集。
定理2:如项目集X是非频繁项目集,则它的所有超集都是非频繁项目集。
三、原理演示

红色部分为不小于最小支持度的项,被添加到频繁项目集中;
黄色部分为小于最小支持度的项,它及它的超集不会添加到频繁项目集中;
蓝色部分为最大频繁项目集,本身是频繁项集,且其中任何一项的超集都是非频繁的。
四、算法流程图

五、关键源码展示
1、导入数据

2、数据预处理
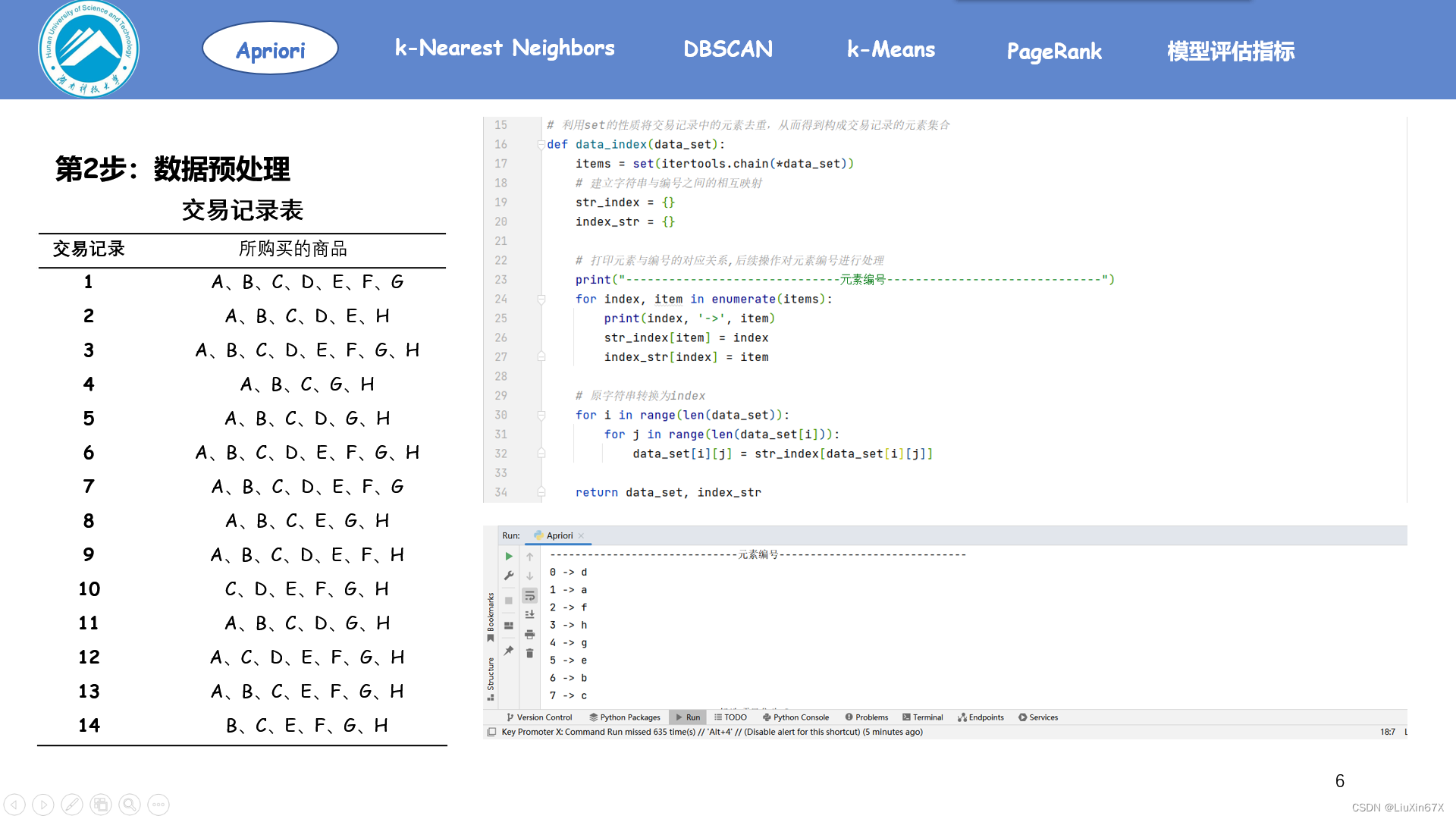
3、生成候选/频繁项目集



4、关联规则生成


六、完整代码与数据集
1、完整代码
import itertools
def loadData():
try:
with open("Apriori.txt", "r") as f:
data = []
for line in f:
data.append(line.strip().split(','))
return data
except Exception as e:
print(e)
# 利用set的性质将交易记录中的元素去重,从而得到构成交易记录的元素集合
def data_index(data_set):
items = set(itertools.chain(*data_set))
# 建立字符串与编号之间的相互映射
str_index = {}
index_str = {}
# 打印元素与编号的对应关系,后续操作对元素编号进行处理
print("------------------------------元素编号------------------------------")
for index, item in enumerate(items):
print(index, '->', item)
str_index[item] = index
index_str[index] = item
# 原字符串转换为index
for i in range(len(data_set)):
for j in range(len(data_set[i])):
data_set[i][j] = str_index[data_set[i][j]]
return data_set, index_str
# 根据支持数筛选频繁项目集
def Ck_Lk(data_set, Ck, min_support):
global item
support = {}
# 用数据集的每一行跟候选项目集的每个项对比,若该项目集是其中的子集,则自增1,否则为0
for row in data_set:
for item in Ck:
# 判断集合item是否为集合row的子集
if item.issubset(row):
# key -- 字典中要查找的键
# value -- 可选,如果指定键的值不存在时,返回该默认值
support[item] = support.get(item, 0) + 1
# k-频繁项目集输出
print('L{}:{}'.format(len(item), support))
# 计算频率需要用到长度
length = len(data_set)
Lk = {}
for key, value in support.items():
sup = value / length
# 频率大于最小支持度才能进入频繁项目集
if sup >= min_support:
Lk[key] = sup
return Lk
def Lk_Ck_plus1(Lk):
Lk_list = list(Lk)
# 保存组合后的k+1项集
Ck_plus1 = set()
Lk_size = len(Lk)
if Lk_size > 1:
# 获取频繁项集的长度
k = len(Lk_list[0])
for i, j in itertools.combinations(range(Lk_size), 2):
t = Lk_list[i] | Lk_list[j]
if len(t) == k + 1:
Ck_plus1.add(t)
return Ck_plus1
def get_all_L(data_set, min_support):
print("---------------------------候选项目集生成----------------------------")
# 首先创建候选1项集
# 把data_set中的元素(已转化为index)去重
items = set(itertools.chain(*data_set))
# 用frozenset把项集装进新列表里
C1 = [frozenset(i) for i in enumerate(items)]
# 从1-候选项集目到1-频繁项目集(第一次生成频繁项目集不需要对元素进行两两组合)
L1 = Ck_Lk(data_set, Ck=C1, min_support=min_support)
L = L1
Lk = L1
while len(Lk) > 0:
lk_key_list = list(Lk.keys())
# k-频繁项目集 到 k+1-候选项目集 进行了两两组合
Ck_plus1 = Lk_Ck_plus1(lk_key_list)
# k-候选项目集 到 k-频繁项目集
Lk = Ck_Lk(data_set, Ck_plus1, min_support)
if len(Lk) > 0:
# 把字典Lk的键值对更新到L
L.update(Lk)
else:
break
return L
# 关联规则左侧表达式
def rules_from_item(item):
left = []
for i in range(1, len(item)):
left.extend(itertools.combinations(item, i))
# difference()方法返回集合的差集
ans = [(frozenset(i), frozenset(item.difference(i))) for i in left]
return ans
# 保存所有候选的关联规则
def rules_from_L(L, min_confidence):
rules = []
for Lk in L:
# 首先频繁项目集长度需要大于1才能生成关联规则
if len(Lk) > 1:
# 在列表末尾一次性追加另一个序列中的多个值
rules.extend(rules_from_item(Lk))
result = []
for left, right in rules:
# left和right都是frozenset类型,二者可以取并集(分子 Ik),然后L里去查询支持度
support = L[left | right]
# 置信度公式
confidence = support / L[left]
if confidence >= min_confidence:
result.append({"left": left, "right": right, "support": support, "confidence": confidence})
return result
# 关联规则的左表达式和右表达式获取
def return_str(index_str, result):
for item in result:
true_left = []
true_right = []
left = list(item['left'])
for tem in left:
true_left.append(index_str[tem])
right = list(item['right'])
for tem in right:
true_right.append(index_str[tem])
item['left'] = frozenset(true_left)
item['right'] = frozenset(true_right)
return result
# 打印集合
def print_frozenset(fs):
ans = ''
for i in fs:
ans += i
return ans
def main():
# 加载数据
data_set = loadData()
# 设置参数
min_support = 0.5
min_confidence = 0.5
print("-------------------------导入事务数据库数据--------------------------")
for i in range(0, len(data_set)):
print(data_set[i])
# 把数据转为数字(便于计算)
data_set, index_str = data_index(data_set)
# 生成频繁项目集
L = get_all_L(data_set, min_support=min_support)
# 生成关联规则
result = rules_from_L(L, min_confidence=min_confidence)
result = return_str(index_str, result)
print("-----------------------------关联规则生成------------------------------")
print("\t\t", " min_support:", min_support, "\t\t\t\t", "min_confidence:", min_confidence)
print("---------------------------------------------------------------------")
print("", "No.", "\t\t", "Lk", "\t", "Xm-1", "\t\t", "Confidence", "\t", "Support", "\t\t", "Rule")
index = 1
for item in result:
print("", str(index).zfill(3), "\t\t", print_frozenset(item["left"] | item["right"]), "\t ",
print_frozenset(item["left"]), "\t\t ",
round(item["confidence"] * 100), "%\t\t ",
round(item["support"] * 100), "%\t\t ",
print_frozenset(item["left"]), "->", print_frozenset(item["right"]))
index += 1
if __name__ == "__main__":
main()2、数据集
a,c,d,e,f,g
a,b,c,d,e,h
a,b,c,d,e,f,g,h
a,b,c,g,h
a,b,c,d,g,h
a,b,c,d,e,f,g,h
a,b,c,d,e,f,g
a,b,c,e,g,h
a,b,c,d,e,f,h
c,d,e,f,g,h
a,b,c,d,g,h
a,c,d,e,f,g,h
a,b,c,e,f,g,h
b,c,e,f,g,h















 1586
1586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











