






C++11 新的计时方法——std::chrono 大法好_c++ chrono 计时-CSDN博客
一个基于protobuf的极简RPC - goyas - 博客园 (cnblogs.com)
详解 Protobuf 在 C++ 下 Message、enum、Service 的使用_proto 中的service-CSDN博客
Raft算法精读 - gatsby123 - 博客园 (cnblogs.com)
Raft 的 Figure 8 讲了什么问题?为什么需要 no-op 日志?_raft 重复提交-CSDN博客
定时器

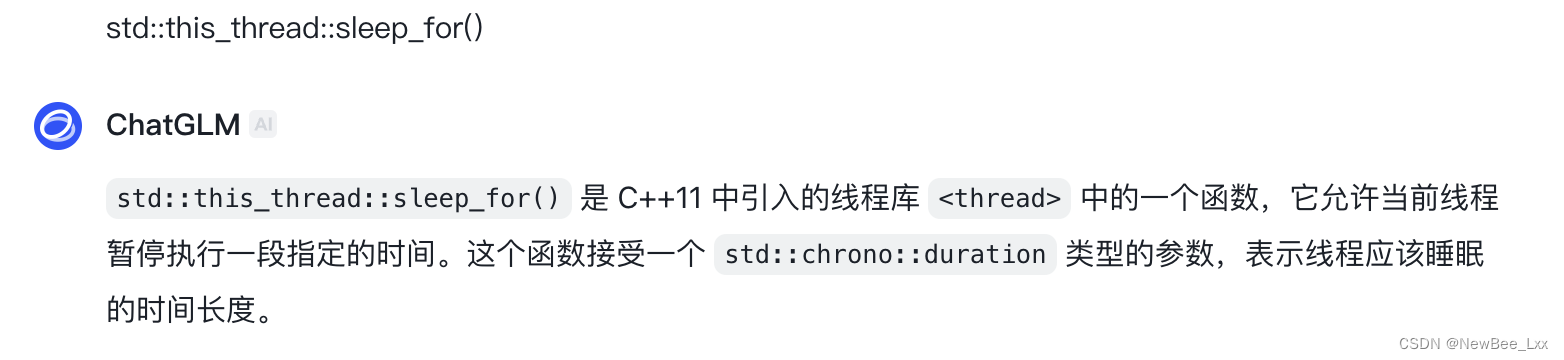
thread传参这有点mb
doHeartBeat():这块一点都没看懂


日志同步的时候为什么要考虑到快照,为什么不直接讨论prevlogindex() 和 getLastLogIndex()的三种情况
为什么不讨论args->prevlogindex() < getLastLogIndex()这种情况

接收快照
日志寻找匹配加速

raft初始化


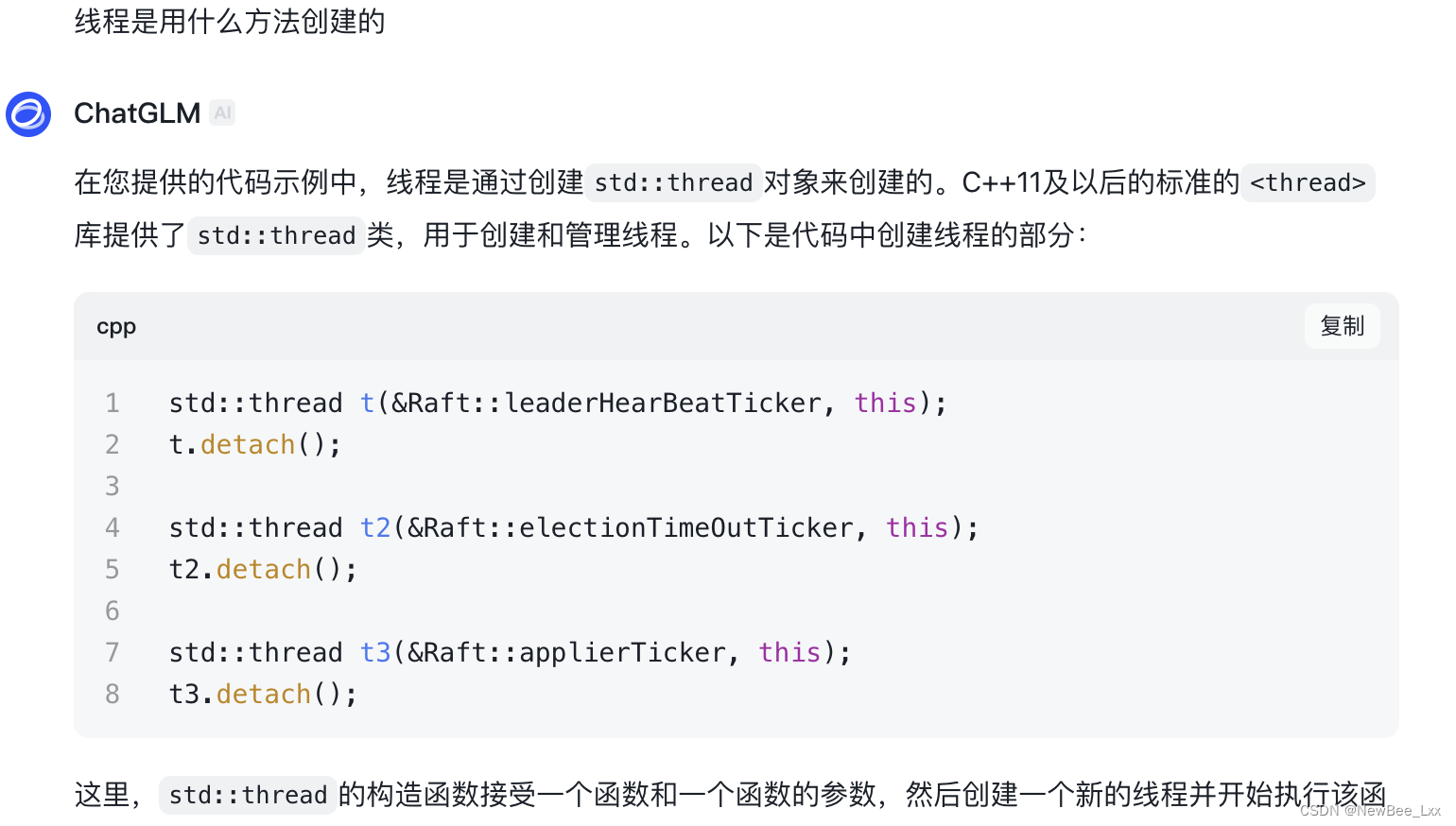
做选举
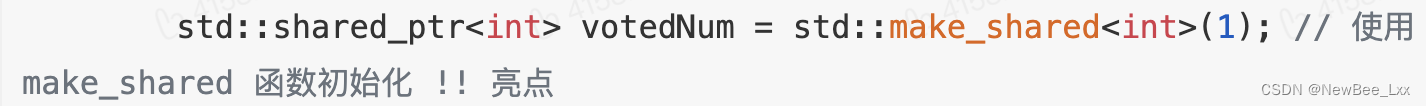
C++11 make_shared以及shared_ptr_make shared ptr-CSDN博客
term 在 Raft 中起到了逻辑时钟的作用,它可以帮助 server 检测过期信息比如过期的 leader。每一个 server 都存储有 current term 字段。当 server 间通信的时候,会交换 current term,如果c andidate 或者 leader 发现了自己的 term 过期了,它会立刻转为 follower 状态。如果一个节点收到了一个含有过期的 term 的请求,它会拒绝该请求。
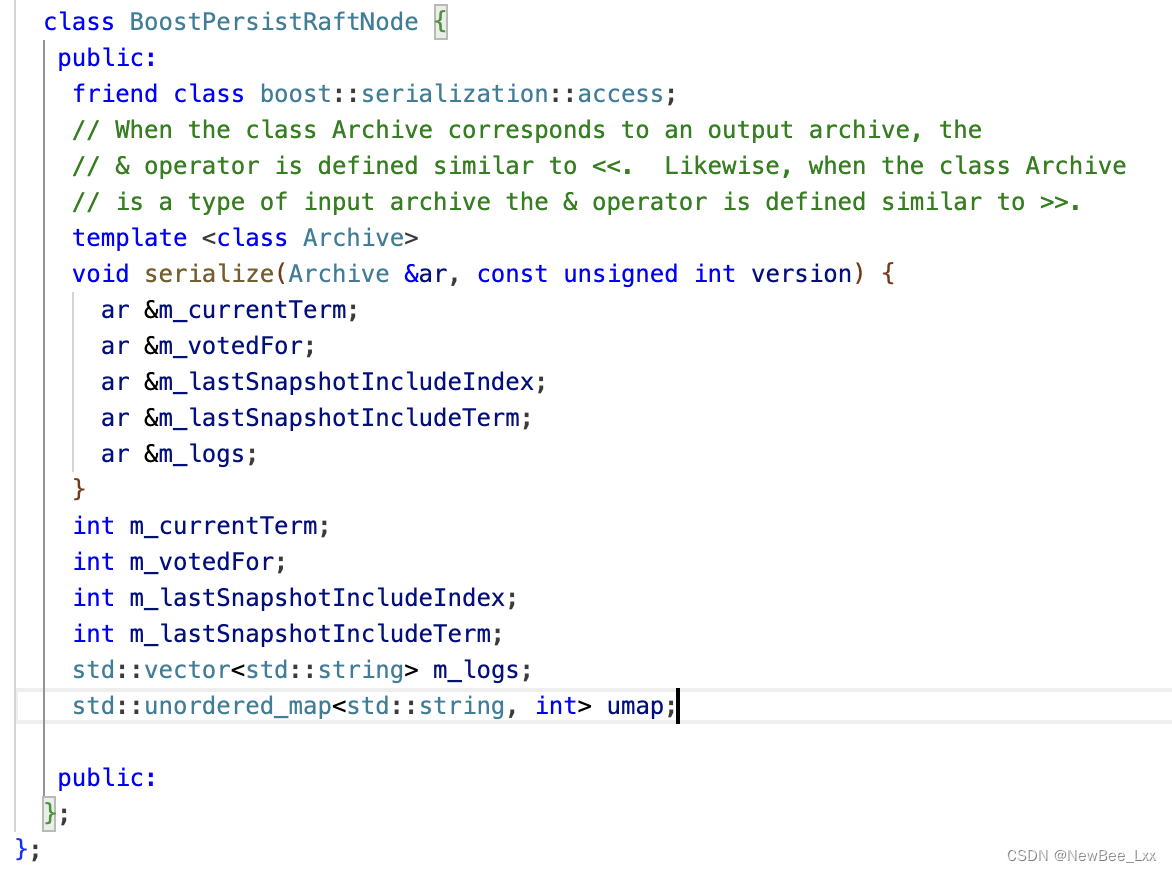
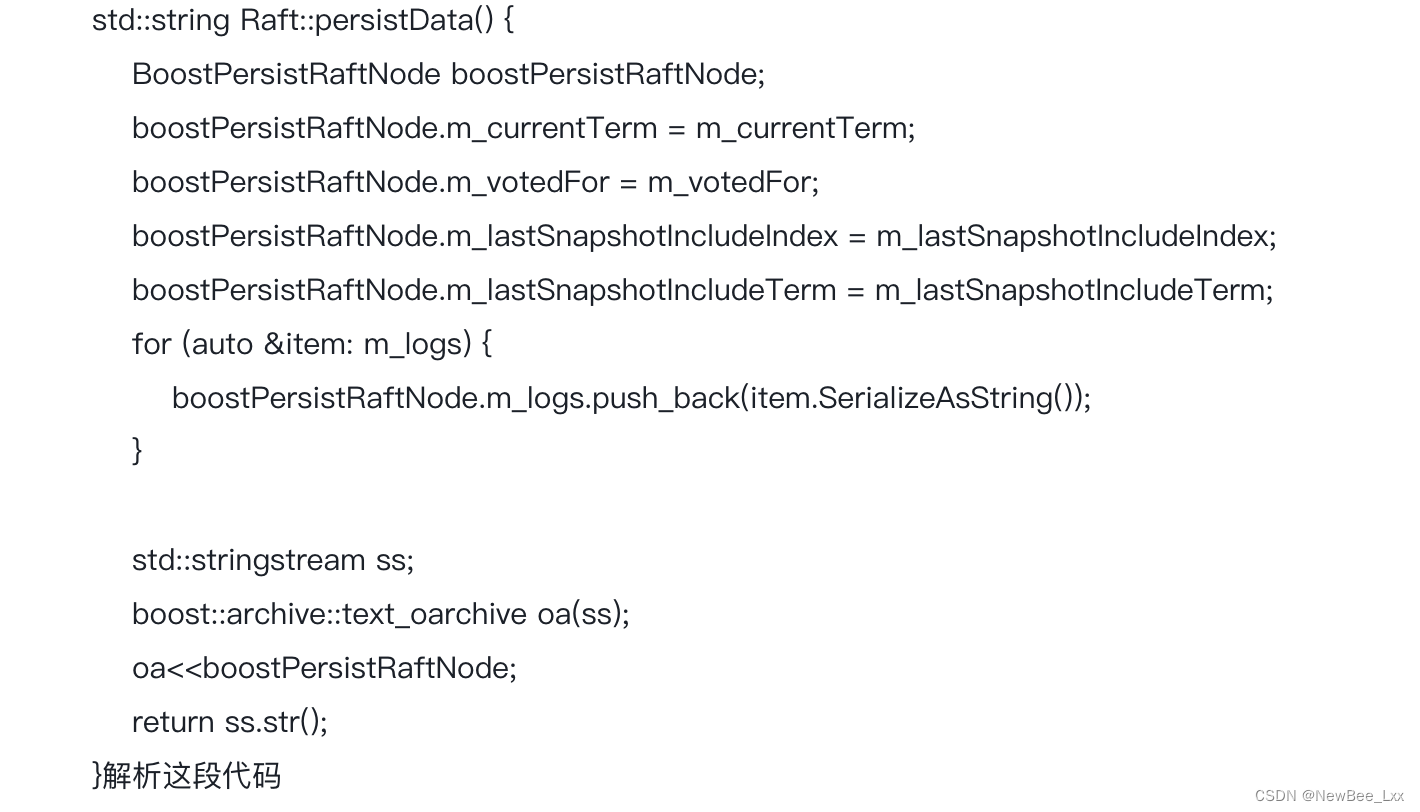
持久化
boost库
序列化有助于持久化存储和减少数据体积

将需要持久化的数据序列化转成字符串类型再写入磁盘。





能当上领导者日志已经是最新的了,要不然也当不上领导者


大概就是启动多个raft类,通过控制节点宕机并记录提交的命令的返回值来判断是否正确。

定时器

用一个random_device生成的种子初始化随机数生成器

设定最小时间和最大时间。。在这个时间区间内生成
网上找的。。。

选举超时的随机时间300到500毫秒
心跳超时时间25毫秒 需要小一个量级。。
protobuf

message 为消息类型,这是 protobuf 中最常用的类型。任意 message 都会在 protoc 编译后生成同名的类

详解 Protobuf 在 C++ 下 Message、enum、Service 的使用_proto 中的service-CSDN博客









创建一个TCP连接到指定的IP地址和端口上,用于实现RPC(远程过程调用)通信

分布式网络通信框架(十五)——Mprpc项目总结-CSDN博客
ckerk
介绍
背景




分布式式的共识算法实现本身是一个比较严谨的过程,因为其本身的存在是为了多个服务器之间通过共识算法达成一致性的状态,从而避免单个节点不可用而导致整个集群不可用


- 领导者选举(Leader Election):在系统启动时或者当前领导者失效时,节点会发起选举过程。节点会在一个随机的超时时间内等待收到来自其他节点的心跳消息。如果在超时时间内没有收到心跳消息,节点就会成为候选人并发起选举。候选人向其他节点发送投票请求,并在得到大多数节点的投票后成为新的领导者。然后定时向其它节点发起心跳,告知其它节点集群中已经有领导者,保持自己的领导者地位。当leader宕机或产生网络分区,其它节点没有收到心跳,就会选举超时,发起新一轮选举。
- 日志复制(Log Replication):raft的主要功能就是保证各个节点日志的一致性。一旦领导者选举完成,新的领导者就会接收客户端的请求,并将更新的日志条目复制到其他节点。当大多数节点都成功复制了这些日志条目时,更新被认为是提交的,并且可以应用到节点的状态机中。
- 安全性(Safety):安全性是确保系统在面临各种异常情况时仍能保持一致性的保障。Raft算法通过确保在选举中只有一个领导者(单一领导者)、大多数节点的一致性以及只有领导者可以处理客户端请求等方式保证分布式系统的安全性。
使用场景:
etcd 是一个分布式键值存储数据库,etcd 使用 Raft 在多节点间进行数据同步,每个节点都拥有状态机数据。TiKV 是一个分布式的键值数据库,并且通过 Raft 协议保证了多副本数据一致性以及高可用。TiKV 底层使用 Multi Raft,将数据划分为多个 region(切片),每个 region 其实还是一个标准的 Raft 集群,对每个分区的数据实现了多副本高可用。







剩下的在文章看。。















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









