








系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核
Linux 设备驱动程序
Linux设备驱动开发详解
深入理解Linux虚拟内存管理
Linux 内核源代码情景分析(一)
Linux 内核源代码情景分析(二)
Linux 内核源代码情景分析(三)
Linux 内核源代码情景分析(四)
5.4 文件系统的安装和拆卸
在一个块设备(见本书下册 “设备驱动” 一章)上按一定的格式建立起文件系统的时候,或者系统引导之初,设备上的文件和节点都还是不可访问的。也就是说,还不能按一定的路径名访问其中特定的节点或文件(虽然作为 “设备” 是可访问的)。只有把它 “安装” 到计算机系统的文件系统中某个节点上,才能使设备上的文件和节点成为可访问的。经过安装以后,设备上的 “文件系统” 就成为整个文件系统的一部分,或者说一个子系统。一般而言,文件系统的结构就好像一棵倒立的树,不过由于可能存在着的节点间的 “连接” 和 “符号连接” 而并不一定是严格的图论意义上的 “树” 。最初时, 整个系统中只有一个节点,那就是整个文件系统的 “根” 节点 “/” ,这个节点存在于内存中,而不在任何具体的设备上。系统在初始化时将一个 “根设备” 安装到节点 “/” 上,这个设备上的文件系统就成了整个系统中原始的、基本的文件系统(所以才称为根设备)。此后,就可以由超级用户进程通过系统调用 mount() 把其他的子系统安装到已经存在于文件系统中的空闲节点上,使整个文件系统得以扩展,当不再需要使用某个子系统时,或者在关闭系统之前,则通过系统调用 umount() 把已经安装的设备逐个 “拆卸” 下来。
系统调用 mount() 将一个可访问的块设备安装到一个可访问的节点上。所谓 “可访问” 是指该节点或文件已经存在于已安装的文件系统中,可以通过路径名寻访。Unix(以及Linux)将设备看作一种特殊的文件,并在文件系统中有代表着具体设备的节点,称为 “设备文件” ,通常都在目录 “/dev” 中。例如 IDE 硬盘上的第一个分区就是 /dev/hda1 。 每个设备文件实际上只是一个索引节点,节点中提供了设备的 “设备号” ,由 “主设备号” 和 “次设备号” 两部分构成。其中主设备号指明了设备的种类,或者更确切地说是指明了应该使用哪一组驱动程序。同一个物理的设备,如果有两组不同的驱动程序,在逻辑上就被视作两种不同的设备而在文件系统中有两个不同的 “设备文件”。次设备号则指明该设备是同种设备中的第几个。所以,只要找到代表着某个设备的索引节点,就知道该怎样读/写这个设备了。 既然是一个 “可访问” 的块设备,那为什么还要安装呢?答案是在安装之前可访问的只是这个设备, 通常是作为一个线性的无结构的字节流来访问的,称为 “原始设备” (raw device);而设备上的文件系统则是不可访问的。经过安装以后,设备上的文件系统就成为可访问的了。
读者也许已经想到了一个问题,那就是:系统调用 mount() 要求被安装的块设备在安装之前就是可访问的,那根设备怎么办?在安装根设备之前,系统中只有一个节点,根本就不存在可访问的块设备啊。是的,根设备不能通过系统调用 mount() 来安装。事实上,根据情况的不同,内核中有三个函数是用于设备安装的,那就是 sys_mount() 、mount_root() 以及 kem_mount() 。我们先来看 sys_mount(),这就是系统调用 mount() 在内核中的实现,其代码在 fs/super.c 中。
1、sys_mount
// fs/super.c
// 参数dev_name为待安装设备的路径名;dir_name则是安装点(空闲目录节点)的路径名;type是
// 表示文件系统类型(即格式)的字符串,如 “ext2"、 “iso9660” 等。此外,flags为安装模式,有关的
// 标志位定义于 include/linux/fs.h
//
// 最后,指针 data 指向用于安装的附加信息,由不同文件系统的驱动程序自行加以解释,所以其类
// 型为 void 指针
asmlinkage long sys_mount(char * dev_name, char * dir_name, char * type,
unsigned long flags, void * data)
{
int retval;
unsigned long data_page;
unsigned long type_page;
unsigned long dev_page;
char *dir_page;
// 代码中通过 getname() 和 copy_mount_options() 将字符串形式或结构形式的参数值从用户空间复制
// 到系统空间。这些参数值的长度均以一个页面为限,但是 getname() 在复制时遇到字符串结尾符 “\0”
// 就停止,并返回指向该字符串的指针;而 copy_mount_options() 则拷贝整个页面(确切地说是
// PAGE_SIZE - 1 个字节),并且返回页面的起始地址。然后,就是这个操作的主体 do_mount() 了
// 我们分段来看 (super.c)
retval = copy_mount_options (type, &type_page);
if (retval < 0)
return retval;
dir_page = getname(dir_name);
retval = PTR_ERR(dir_page);
if (IS_ERR(dir_page))
goto out1;
retval = copy_mount_options (dev_name, &dev_page);
if (retval < 0)
goto out2;
retval = copy_mount_options (data, &data_page);
if (retval < 0)
goto out3;
lock_kernel();
retval = do_mount((char*)dev_page, dir_page, (char*)type_page,
flags, (void*)data_page);
unlock_kernel();
free_page(data_page);
out3:
free_page(dev_page);
out2:
putname(dir_page);
out1:
free_page(type_page);
return retval;
}
(1)mount flags
// include/linux/fs.h
/*
* These are the fs-independent mount-flags: up to 32 flags are supported
*/
#define MS_RDONLY 1 /* Mount read-only */
#define MS_NOSUID 2 /* Ignore suid and sgid bits */
#define MS_NODEV 4 /* Disallow access to device special files */
#define MS_NOEXEC 8 /* Disallow program execution */
#define MS_SYNCHRONOUS 16 /* Writes are synced at once */
#define MS_REMOUNT 32 /* Alter flags of a mounted FS */
#define MS_MANDLOCK 64 /* Allow mandatory locks on an FS */
#define MS_NOATIME 1024 /* Do not update access times. */
#define MS_NODIRATIME 2048 /* Do not update directory access times */
#define MS_BIND 4096
例如,如果 MS_NOSUID 标志为 1,则整个系统中所有可执行文件的 suid 标志位就都不起作用了。 但是,正如原作者的注释所说,这些标志位并不是对所有文件系统都有效的。所有的标志位都在低 16 位中,而高 16 位则用作 “magic number” 。
(2)do_mount
// fs/super.c
/*
* Flags is a 16-bit value that allows up to 16 non-fs dependent flags to
* be given to the mount() call (ie: read-only, no-dev, no-suid etc).
*
* data is a (void *) that can point to any structure up to
* PAGE_SIZE-1 bytes, which can contain arbitrary fs-dependent
* information (or be NULL).
*
* NOTE! As pre-0.97 versions of mount() didn't use this setup, the
* flags used to have a special 16-bit magic number in the high word:
* 0xC0ED. If this magic number is present, the high word is discarded.
*/
// 首先是对参数的检验。例如对于安装节点名就要求指针dir_name不为0,并且字符串的第一个字
// 符不为0,即不是空字符串,并且字符串的长度不超过一个页面。这里的 memchr() 在指定长度的缓冲
// 区中寻找指定的字符(这里是0),如果找不到就返回 0。对设备名dev_name的检验很有趣:如果
// dev_name 为非 0,则字符串的长度不得长于一个页面(实际上 copy_mount_options() 保证了这一点,因
// 为它拷贝 PAGE_SIZE—1 个字节),可是 dev_name 为0却是允许的。这似乎不可思议,下面读者将会
// 看到,在特殊情况下这确实是允许的。
long do_mount(char * dev_name, char * dir_name, char *type_page,
unsigned long flags, void *data_page)
{
struct file_system_type * fstype;
struct nameidata nd;
struct vfsmount *mnt = NULL;
struct super_block *sb;
int retval = 0;
/* Discard magic */
if ((flags & MS_MGC_MSK) == MS_MGC_VAL)
flags &= ~MS_MGC_MSK;
/* Basic sanity checks */
if (!dir_name || !*dir_name || !memchr(dir_name, 0, PAGE_SIZE))
return -EINVAL;
if (dev_name && !memchr(dev_name, 0, PAGE_SIZE))
return -EINVAL;
/* OK, looks good, now let's see what do they want */
/* just change the flags? - capabilities are checked in do_remount() */
// 如果调用参数中的 MS_REMOUNT 标志位为1,就表示所要求的只是改变一个原已安装的设备的
// 安装方式。例如,原来是按 “只读” 方式来安装的,而现在要改为 “可写” 方式;或者原来的MS_NOSUID
// 标志位为0,而现在要改变成1,等等。所以这种操作称为 “重安装”。函数 do_remount() 的代码也在
// super.c 中,读者可以在阅读了 do_mount() 的 “主流” 以后回过来自己读一下这个 “支流” 的代码。
// 另一个分支是对特殊设备如 /dev/loopback 等 “回接” 设备的处理。这种设备是特殊的,其实并不
// 是一种设备,而是一种机制。从系统的角度来看,它似乎是一种设备,但实际上它只是提供了一条
// “loopback” (回接)到某个可访问普通文件或块设备的手段。举例来说,系统的管理人员可以通过实
// 用程序 losetup,实际上是系统调用 ioctl(),建立起 /dev/loop0 与一个普通文件 /blkfile
// 之间的联系,或者说将 /dev/loop0 “回接” 到 /blkfile,从而将这个文件当作一个块设备来使用:
// losetup -e des /dev/loop0 /blkfile
// 这里的可选项 -e des 表示在通过 /dev/loop0 读写作为虚拟块设备的 /blkfile 时要对内容加密,而加
// 密的算法则为DES (一种加密/解密标准)。也可以使用比较简单的加密算法XOR,此时可选项即为
// "-e xor"。如果不加密就不用 -e 可选项。回接以后,通过 /dev/loop0 访问的文件 /blkfile 就作为
// 一个 “块设备” 来使用了,所以也要加以格式化:
// mkfs -t ext2 /dev/loop0 100
// 参数 -t ext2 表示按 Ext2 格式化,也可以改用其他文件系统的格式。参数100表示该设备的大小为
// 100个记录块。当然,文件 /blkfile 原来的大小要是够,并且其原来的内容就丢失了,所以一般可以先
// 建立起一个是够大的空文件:
// dd if=/dev/zero of=/blkfile bs=lk count=100
// 回接的对象并不非得是一个普通文件,也可以是一个常规的块设备文件如/dev/hda2等。但是,以
// 普通文件为回接对象给我们提供了将它格式化成一个文件系统并加以安装的手段。我们在回接时采用
// 了加密,所以格式化以后的文件系统映象是加了密的,然后,就可以把这个虚拟的块设备安装到文件
// 系统中了:
// mount -t ext2 /dev/loop0 /mnt
// 从此以后,就跟一般己安装的子系统一样了,只是在我们这个例子中对这个子系统的读/写都加了密。
// 回接的对象还可以是一个已经安装的块设备。例如,/dev/hdal 已经安装在根节点/上,我们仍可
// 以把它作为回接的对象。此时当然不能再加密,也不能再格式化了,但是还可以通过 /dev/loop0 再安装
// 一次(在另外一个节点上),例如把它安装成 “只读” 方式。如果回忆一下,一个进程(例如某种网络
// 服务进程)可以通过系统调用设置自己的 “根” 目录,就不难想像这种 “回接” 设备对子系统安全性
// 可能有用处了。通常在/dev目录中有 /dev/loop0 和 /dev/loopl 两个回接设备文件,需要的话可以
// 通过 mknod 再创建,其上设备号为7。
// 对通过回接设备的安装,以前在mount命令行中有个 “-o loop” 可选项,现在则改成将命令行中
// 的文件类型加上一种 "bind",即 "-t bind",表示所安装的设备是个 “捆绑” 到另一个对象上的回接设
// 备。所以,如果flags中的 MS_BIND 标志位为 1 (见代码中的第1341行,),就调用 do_loopback()
// 来完成回接设备的安装。我们暂且跳过它继续往下读(super.c)。
if (flags & MS_REMOUNT)
return do_remount(dir_name, flags & ~MS_REMOUNT,
(char *) data_page);
/* "mount --bind"? Equivalent to older "mount -t bind" */
/* No capabilities? What if users do thousands of these? */
if (flags & MS_BIND)
return do_loopback(dev_name, dir_name);
/* For the rest we need the type */
if (!type_page || !memchr(type_page, 0, PAGE_SIZE))
return -EINVAL;
#if 0 /* Can be deleted again. Introduced in patch-2.3.99-pre6 */
/* loopback mount? This is special - requires fewer capabilities */
if (strcmp(type_page, "bind")==0)
return do_loopback(dev_name, dir_name);
#endif
/* for the rest we _really_ need capabilities... */
// 进一步的操作需要系统管理员的权限,所以先检查当前进程是否具有此项授权。一般超级用户进
// 程都是有这种授权的。
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
/* ... filesystem driver... */
// 系统支持的每一种文件系统都有一个file_system_type数据结构,定义于include/linux/fs.h:
fstype = get_fs_type(type_page);
if (!fstype)
return -ENODEV;
/* ... and mountpoint. Do the lookup first to force automounting. */
// 回到 do_mount() 的代码中。找到了给定文件系统类型的数据结构以后,就要寻找代表安装点的
// dentry 数据结构了。通过path_init() 和path_walk() 寻找目标节点的过程以前已经讲过,就不重复了。
// 找到了安装点的dentry结构(在nameidata结构nd中有个dentry指针)以后,要把待安装设备的 “超级
// 块” 读进来并根据超级块中的信息在内存中建立起相应的super_block数据结构。但是,这里因具体文
// 件系统的不同而有几种情形要区别对待:
// (1)有些虚拟的文件系统(如pipe、共享内存区等),要由内核通过 kern_mount() 安装,而根本
// 不允许由用户进程通过系统调用 mount() 来安装。这样的文件系统类型在其 fs_flag 中的
// FS_NOMOUNT 标志位为1。虚拟文件系统类型的 “设备” 其实没有超级块,所以只是按特
// 定的内容初始化,或者说生成一个 super_block 结构。对于这种文件系统类型,系统调用 mount()
// 时应出错返回.
// (2) 一般的文件系统类型要求有物理的设备作为其物质基础,在其 fs_flag 中的
// FS_REQUIRES_DEV 标志位为 1,这些就是 “正常” 的文件系统类型,如ext2、minix、ufs
// 等等。对于这些文件系统类型,通过 get_sb_bdev() 从待安装设备上读入其超级块。
// (3)有些虚拟文件系统在安装了同类型中的第一个 “设备” ,从而创建了超级块的 super_block 数
// 据结构以后,再安装同一类型中的其他设备时就共享已经存在的 super_block 结构,而不再有
// 其自己的超级块结构。此时相应 file_system_type 结构的 fs_flags 中的 FS_SINGLE 标志位为 1,
// 表示整个文件系统类型只有一个超级块,而不像一般的文件系统类型那样每个具体的设备上
// 都有一个超级块。
//(4)还有些文件系统类型的 fs_flags 中的 FS_NOMOUNT 标志位、FS_REQUIRE_DEV 标志位以
// 及 FS_SINGLE 标志位全都为0,所以不属于上述三种情形中的任何一种。这些所谓 “文件系
// 统” 其实也是虚拟的,通常只是用来实现某种机制或者规程,所以根本就没有 “设备” 。对
// 于这样的 “文件系统类型” 都是通过 get_sb_nodev() 来生成一个 super_block 结构的。
// 总之,每种文件系统类型都有个 file_system_type 结构,而结构中的 fs_flags 则由各种标志位组成,
// 这些标志位表明了具体文件系统类型的特性,也决定着这种文件系统的安装过程。内核代码中提供了
// 两个用来建立 file_system_type 数据结构的宏操作,其定义在 fs.h 中
if (path_init(dir_name,
LOOKUP_FOLLOW|LOOKUP_POSITIVE|LOOKUP_DIRECTORY, &nd))
retval = path_walk(dir_name, &nd);
if (retval)
goto fs_out;
/* get superblock, locks mount_sem on success */
// 以后读者会看一到,flags 中的 FS_STNGLE 标志位有着很重要的作用。我们在这里只关心常规文件
// 系统的安装,所以只阅读 get_sb_bdev() 的代码,以后我们会结合其他章节,如进程间通信和设备驱动,
// 再来阅读 get_sb_single() 等函数的代码。顺便提一下,这里 get_sb_single() 和 get_sb_nodev()
// 都不使用参数 dev_name,所以它可以是 NULL。这个函数的代码也在 fs/super.c中,我们分段阅读。
if (fstype->fs_flags & FS_NOMOUNT)
sb = ERR_PTR(-EINVAL);
else if (fstype->fs_flags & FS_REQUIRES_DEV)
sb = get_sb_bdev(fstype, dev_name, flags, data_page);
else if (fstype->fs_flags & FS_SINGLE)
sb = get_sb_single(fstype, flags, data_page);
else
sb = get_sb_nodev(fstype, flags, data_page);
retval = PTR_ERR(sb);
if (IS_ERR(sb))
goto dput_out;
/* Something was mounted here while we slept */
while(d_mountpoint(nd.dentry) && follow_down(&nd.mnt, &nd.dentry))
;
/* Refuse the same filesystem on the same mount point */
retval = -EBUSY;
if (nd.mnt && nd.mnt->mnt_sb == sb
&& nd.mnt->mnt_root == nd.dentry)
goto fail;
retval = -ENOENT;
if (!nd.dentry->d_inode)
goto fail;
down(&nd.dentry->d_inode->i_zombie);
if (!IS_DEADDIR(nd.dentry->d_inode)) {
retval = -ENOMEM;
mnt = add_vfsmnt(&nd, sb->s_root, dev_name);
}
up(&nd.dentry->d_inode->i_zombie);
if (!mnt)
goto fail;
retval = 0;
unlock_out:
up(&mount_sem);
dput_out:
path_release(&nd);
fs_out:
put_filesystem(fstype);
return retval;
fail:
if (list_empty(&sb->s_mounts))
kill_super(sb, 0);
goto unlock_out;
}
① file_system_type
// include/linux/fs.h
struct file_system_type {
const char *name;
int fs_flags;
struct super_block *(*read_super) (struct super_block *, void *, int);
struct module *owner;
struct vfsmount *kern_mnt; /* For kernel mount, if it's FS_SINGLE fs */
struct file_system_type * next;
};
结构中的 fs_flags 指明了具体文件系统的一些特性,有关的标志位定义见文件fs.h:
// include/linux/fs.h
/* public flags for file_system_type */
#define FS_REQUIRES_DEV 1
#define FS_NO_DCACHE 2 /* Only dcache the necessary things. */
#define FS_NO_PRELIM 4 /* prevent preloading of dentries, even if
* FS_NO_DCACHE is not set.
*/
#define FS_SINGLE 8 /*
* Filesystem that can have only one superblock;
* kernel-wide vfsmnt is placed in ->kern_mnt by
* kern_mount() which must be called _after_
* register_filesystem().
*/
#define FS_NOMOUNT 16 /* Never mount from userland */
#define FS_LITTER 32 /* Keeps the tree in dcache */
#define FS_ODD_RENAME 32768 /* Temporary stuff; will go away as soon
* as nfs_rename() will be cleaned up
*/
对这些标志他的意义和作用我们将随着代码解释的进展加以说明。
结构中有个函数指针 read_super,各种文件系统通过这个指针提供用来读入其超级块的函数,因为不同文件系统的超级块也是不同的。显然,这个数据结构也是从虚拟文件系统 VFS 进入具体文件系统的一个转接点。同时,每种文件系统还有个字符串形式的文件系统类型名。
安装文件系统时要说明文件系统的类型,例如系统命令 mount 就有个可选项 “-t” 用于类型名。 文件系统的类型名以字符串的形式复制到 type_page 中,现在就用来比对、寻找其 file_system_type 数据结构。
函数 get_fs_type() 根据具体文件系统的类型名在内核中找到相应的 file_system_type 结构,有关的代码在 super.c 中。
② get_fs_type
// fs/super.c
struct file_system_type *get_fs_type(const char *name)
{
struct file_system_type *fs;
read_lock(&file_systems_lock);
fs = *(find_filesystem(name));
if (fs && !try_inc_mod_count(fs->owner))
fs = NULL;
read_unlock(&file_systems_lock);
if (!fs && (request_module(name) == 0)) {
read_lock(&file_systems_lock);
fs = *(find_filesystem(name));
if (fs && !try_inc_mod_count(fs->owner))
fs = NULL;
read_unlock(&file_systems_lock);
}
return fs;
}
// =======================================================================
static struct file_system_type **find_filesystem(const char *name)
{
struct file_system_type **p;
for (p=&file_systems; *p; p=&(*p)->next)
if (strcmp((*p)->name,name) == 0)
break;
return p;
}
内核中有一个 file_system_type 结构队列,叫做 file_systems,队列中的每个数据结构都代表着一种文件系统。系统初始化时将内核支持的各种文件系统的 file_system_type 数据结构通过一个函数 register_filesystem() 挂入这个队列,这个过程称为文件系统的注册。除此之外,对有些文件系统的支持可以通过 “可安装模块” 的方式来实现。在装入这些模块时,也会将相应的数据结构注册挂入该队列中。
函数 find_filesystem() 则扫描 file_systems 队列,找到所需文件系统类型的数据结构。在 file_system_type 结构中有一个指针 owner,如果结构所代表的文件系统类型是通过可安装模块实现的, 则该指针指向代表着具体模块的 module 结构。找到了 file_system_type结构以后,要调用 try_inc_mod_count() 看看该文件系统是否由可安装模块实现,是的话就要递增相应 module 结构中的共享计数,因为现在这个模块多了一个使用者。
要是在 file_systems 队列中找不到所需的文件系统类型怎么办呢?那就通过request_module() 试试能否(在已安装的文件系统中)找到用来实现所需文件系统类型的可安装模块,并将其装入内核;如果成功的话就再去 file_systems 队列中找一遍。如果装入所需的可安装模块失败,或者装入以后还是找不到相应的 file_system_type 结构,那就说明 Linux 系统不支持所要求的文件系统类型。有关模块的装入可参考 “设备驱动” 一章。
③ 文件系统定义
// include/linux/fs.h
#define DECLARE_FSTYPE(var,type,read,flags) \
struct file_system_type var = { \
name: type, \
read_super: read, \
fs_flags: flags, \
owner: THIS_MODULE, \
}
#define DECLARE_FSTYPE_DEV(var,type,read) \
DECLARE_FSTYPE(var,type,read,FS_REQUIRES_DEV)
// =====================================================================
// fs/ext2/super.c
static DECLARE_FSTYPE_DEV(ext2_fs_type, "ext2", ext2_read_super);
// =====================================================================
// fs/umsdos/inode.c
static DECLARE_FSTYPE_DEV(umsdos_fs_type, "umsdos", UMSDOS_read_super);
// =====================================================================
// fs/pipe.c
static DECLARE_FSTYPE(pipe_fs_type, "pipefs", pipefs_read_super,
FS_NOMOUNT|FS_SINGLE);
④ get_sb_bdev
// fs/super.c
static struct super_block *get_sb_bdev(struct file_system_type *fs_type,
char *dev_name, int flags, void * data)
{
struct inode *inode;
struct block_device *bdev;
struct block_device_operations *bdops;
struct super_block * sb;
struct nameidata nd;
kdev_t dev;
int error = 0;
/* What device it is? */
// 对于常规的文件系统,参数 dev_name 必须是一个有效的路径名。同样,这里也是通过 path_init()
// 和 path_walk() 找到目标节点,即相应设备文件的 dentry 结构以及 inode 结构。当然,找到的
// inode 结构必须是代表着一个块设备,其 i_mode 中的 S_IFBLK 标志位必须为 1,否则就错了。
// 宏操作 S_ISBLK() 定义于 include/linux/stat.h:
//
// 设备文件的 inode 结构是在 path_walk() 中根据从已经安装的磁盘上(或其他已安装的文件系统中)
// 读入的索引节点建立的。对于Ext2文件系统,我们在 “从路径名到目标节点” 一节中阅读 path_walk()
// 的代码时曾在它所辗转调用的 ext2_read_inode() 中看到这么一段代码:
if (!dev_name || !*dev_name)
return ERR_PTR(-EINVAL);
if (path_init(dev_name, LOOKUP_FOLLOW|LOOKUP_POSITIVE, &nd))
error = path_walk(dev_name, &nd);
if (error)
return ERR_PTR(error);
inode = nd.dentry->d_inode;
error = -ENOTBLK;
if (!S_ISBLK(inode->i_mode))
goto out;
error = -EACCES;
if (IS_NODEV(inode))
goto out;
// 在block_device结构中有个指针bd_op,指向一个block_device_operations数据结构,这就是块设
// 备驱动程序的函数跳转表。所以,我们可以把block_device结构比喻为块设备驱动 “总线” ,而使其指
// 针bd_op指向某个具体的block_device_operations数据结构,就好像是将一块"接口卡"插入了总线的
// 插槽,这跟VFS与具体文件系统的关系是一样的。
// 那么,这里要把什么样的 “接口卡” 插到总线上去呢?原来,在Linux的设备驱动方面正在进行
// 着一项称为 “devfs” 的改革。传统的/dev目录是一种 “平面” 结构而不像其他目录那样是树状结构。
// 每一个设备都有个 “主设备号” 和一个 “次设备号” ,每当要在/dev中建立一个节点(即设备文件)时
// 就要将主、次设备号合成一个单一的 “设备号” ,再通过系统调用mknod()来建立,传统的主、次设备
// 号都是8位的,所以每种设备最多只能有255个。随着技术的发展,这个限制开始成为问题了。所以
// Linux内核已经开始使用16位的主、次设备号。可是,另有一派意见认为,/dev的这种平面结构和主、
// 次设备号的使用根本就应该改革。也就是说,把/dev改成树状结构,这样一来路径名就可以惟一地确
// 定一个设备的类型和序号,例如/dev/hda/1,这样就可以把主、次设备号隐藏在路径名的背后,不需要
// 在用户界面上用什么主设备号、次设备号了。目前这项改革正在进行中,对有些设备(如软盘、磁带
// 等)的支持已开始使用这种新的方案。但是,内核必须同时支持新、旧两种方案,这里对 devfs() 和
// devfs_get_handle_form_inode() 就是出于对devfs的考虑。目前(以及在未来相当一段时期内),对多
// 数块设备的支持还会沿用传统的模式,如果尚不支持devfs则这两个函数都返回NULL而不起作用,
// 相当于让插槽暂时空着。我们在 “设备驱动” 一章中还要回到devfs这个话题上。另一方面,由于在内
// 核中已经开始使用16位的主、次设备号,而在大多数文件系统中都还是8位的,所以要通过to_kdev_t()
// 加以转换。
// 完成了上面的这些准备以后,现在要进行实质性的工作,就是找到或建立待安装设备的 super_block
// 数据结构了。首先还是在内核中寻找,内核中维持着一个super_block数据结构的队列super_blocks,
// 所有的super_block结构,包括空闲的,都通过结构中的一个队列头s_list链入到这个队列中。寻找时
// 就通过 get_super() 从队列中寻找,其代码在 fs/super.c 中。
bdev = inode->i_bdev;
bdops = devfs_get_ops ( devfs_get_handle_from_inode (inode) );
if (bdops) bdev->bd_op = bdops;
/* Done with lookups, semaphore down */
down(&mount_sem);
dev = to_kdev_t(bdev->bd_dev);
sb = get_super(dev);
if (sb) {
if (fs_type == sb->s_type &&
((flags ^ sb->s_flags) & MS_RDONLY) == 0) {
path_release(&nd);
return sb;
}
} else {
mode_t mode = FMODE_READ; /* we always need it ;-) */
if (!(flags & MS_RDONLY))
mode |= FMODE_WRITE;
error = blkdev_get(bdev, mode, 0, BDEV_FS);
if (error)
goto out;
check_disk_change(dev);
error = -EACCES;
if (!(flags & MS_RDONLY) && is_read_only(dev))
goto out1;
error = -EINVAL;
sb = read_super(dev, bdev, fs_type, flags, data, 0);
if (sb) {
get_filesystem(fs_type);
path_release(&nd);
return sb;
}
out1:
blkdev_put(bdev, BDEV_FS);
}
out:
path_release(&nd);
up(&mount_sem);
return ERR_PTR(error);
}
⑴ ext2_read_inode
// fs/ext2/inode.c
if (inode->i_ino == EXT2_ACL_IDX_INO ||
inode->i_ino == EXT2_ACL_DATA_INO)
/* Nothing to do */ ;
else if (S_ISREG(inode->i_mode)) {
inode->i_op = &ext2_file_inode_operations;
inode->i_fop = &ext2_file_operations;
inode->i_mapping->a_ops = &ext2_aops;
} else if (S_ISDIR(inode->i_mode)) {
inode->i_op = &ext2_dir_inode_operations;
inode->i_fop = &ext2_dir_operations;
} else if (S_ISLNK(inode->i_mode)) {
if (!inode->i_blocks)
inode->i_op = &ext2_fast_symlink_inode_operations;
else {
inode->i_op = &page_symlink_inode_operations;
inode->i_mapping->a_ops = &ext2_aops;
}
} else
init_special_inode(inode, inode->i_mode,
le32_to_cpu(raw_inode->i_block[0]));
由于设备文件既不是常规文件,也不是目录,更不是符号连接,所以必然会调用 init_special_inode(), 其代码在 fs/devices.c 中
⑵ init_special_inode
// fs/devices.c
void init_special_inode(struct inode *inode, umode_t mode, int rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = to_kdev_t(rdev);
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = to_kdev_t(rdev);
inode->i_bdev = bdget(rdev);
} else if (S_ISFIFO(mode))
inode->i_fop = &def_fifo_fops;
else if (S_ISSOCK(mode))
inode->i_fop = &bad_sock_fops;
else
printk(KERN_DEBUG "init_special_inode: bogus imode (%o)\n", mode);
}
以前说过,在 inode 数据结构中有两个设备号。一个是索引节点所在设备的号码i_dev,另一个是索引节点所代表的设备的号码 i_rdev 。可是,如果看一下存储在设备上的索引节点 ext2_inode 数据结构, 就可以发现里面一个专门用于设备号的字段也没有。首先,既然索引节点存储在某个设备上,当然就不需要再在里面说明存储在哪个设备上了。再说,一个索引节点如果代表着一个设备,那就不需要记录跟文件的物理信息有关的数据了,从而可以利用这些空间来记录所代表设备的设备号。事实上,当索引节点代表着设备时,其 ext2_inode 数据结构中的数组 i_block[] 空着没用,所以就将 i_block[0] 用于设备号。这个设备号在这里的 init_special_node() 中经过 to_kdev_t() 加以格式转换以后就变成 inode 结构中的 i_rdev。此外,对于块设备还要使 inode 结构中的指针 i_bdev 指向一个 block_device 结构。具体的数据结构由 bdget() 根据设备号寻找或创建,详见 “设备驱动” 一章中有关的内容。
⑶ get_super
// fs/super.c
/**
* get_super - get the superblock of a device
* @dev: device to get the superblock for
*
* Scans the superblock list and finds the superblock of the file system
* mounted on the device given. %NULL is returned if no match is found.
*/
struct super_block * get_super(kdev_t dev)
{
struct super_block * s;
if (!dev)
return NULL;
restart:
s = sb_entry(super_blocks.next);
while (s != sb_entry(&super_blocks))
if (s->s_dev == dev) {
wait_on_super(s);
if (s->s_dev == dev)
return s;
goto restart;
} else
s = sb_entry(s->s_list.next);
return NULL;
}
这里的 sb_entry() 是个宏操作,定义于 include/linux/fs.h:
#define sb_entry(list) list_entry((list), struct super_block, s_list)
读者也许会问,这是否意味着同一个块设备可以安装多次?答案是可以的,例如我们在前面曾经讲到通过 “回接设备” 进行的安装,那就是同一设备的多次安装。
然而,在大多数情况下 get_super() 实际上都会失败,因而得从设备读入其超级块并在内存中建立起该设备的 super_block 数据结构。为了这个目的,先得要 “打开” 这个设备文件,这是由 blkdev_get() 完成的,其代码在fs/block_dev,c中
⑷ blkdev_get
// fs/block_dev.c
int blkdev_get(struct block_device *bdev, mode_t mode, unsigned flags, int kind)
{
int ret = -ENODEV;
kdev_t rdev = to_kdev_t(bdev->bd_dev); /* this should become bdev */
down(&bdev->bd_sem);
if (!bdev->bd_op)
bdev->bd_op = get_blkfops(MAJOR(rdev));
if (bdev->bd_op) {
/*
* This crockload is due to bad choice of ->open() type.
* It will go away.
* For now, block device ->open() routine must _not_
* examine anything in 'inode' argument except ->i_rdev.
*/
struct file fake_file = {};
struct dentry fake_dentry = {};
struct inode *fake_inode = get_empty_inode();
ret = -ENOMEM;
if (fake_inode) {
fake_file.f_mode = mode;
fake_file.f_flags = flags;
fake_file.f_dentry = &fake_dentry;
fake_dentry.d_inode = fake_inode;
fake_inode->i_rdev = rdev;
ret = 0;
if (bdev->bd_op->open)
ret = bdev->bd_op->open(fake_inode, &fake_file);
if (!ret)
atomic_inc(&bdev->bd_openers);
else if (!atomic_read(&bdev->bd_openers))
bdev->bd_op = NULL;
iput(fake_inode);
}
}
up(&bdev->bd_sem);
return ret;
}
由于 block_device 结构中的 bd_dev 有可能还在使用 8 位的主、次设备号,或者说 16 位的设备号, 这里先通过 to_kdev_t() 将它们换成 16 位(或者说 32 位的设备号)。前面讲过,block_device 结构中的指针 bd_op 指向一个 block_device_operations 数据结构。对于 devfs 的设备这个指针已经在前面设置好了,而对于传统的块设备则这个指针尚未设置,暂时还空着,所以要通过 get_blkfops() 根据设备的主设备号来设置这个指针。函数 get_blkfops() 的代码也在 fs/block_dev.c 中。
⑤ vfsmount
// include/linux/mount.h
struct vfsmount
{
struct dentry *mnt_mountpoint; /* dentry of mountpoint */
struct dentry *mnt_root; /* root of the mounted tree */
struct vfsmount *mnt_parent; /* fs we are mounted on */
struct list_head mnt_instances; /* other vfsmounts of the same fs */
struct list_head mnt_clash; /* those who are mounted on (other */
/* instances) of the same dentry */
struct super_block *mnt_sb; /* pointer to superblock */
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
atomic_t mnt_count;
int mnt_flags;
char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
uid_t mnt_owner;
};
结构中主要成分的作用为:
- 指针 mnt_mountpoint 指向安装点的 dentry 数据结构,而指针 mount_root 则指向所安装设备上根目录的 dentry 数据结构,在二者之间搭起一座桥梁。
- 可是,在 dentry 结构中却没有直接指向 vfsmount 数据结构的指针,而是有个队列头 d_vfsmount, 这是因为安装点和设备之间是一对多的关系,在同一个安装点上可以安装多个设备。相应地, vfsmount 结构中也有个队列头 mnt_clash,通过它链入到安装点的 d_vfsmount 队列中。不过, 从所安装设备上根目录的 dentry 数据结构出发却不能直接找到其 vfsmount 结构,而得要通过其 super_block 数据结构中转。
- 指针 mnt_sb 指向所安装设备的超级块的 super_block 数据结构。反之,在所安装设备的 super_block 数据结构中却并没有直接指向 vfsmount 数据结构的指针,而是有个队列头 s_mounts,因为设备与安装点之间也是一对多的关系,同一个设备可以安装到多个安装点上。 相应地,vfsmount 结构中也有个队列头 mnt_instances,通过它链入到设备的 s_mounts 队列中。
- 指针 mnt_parent 指向安装点所在设备当初安装时的 vfsmount 数据结构,就是上一层的 vfsmount 数据结构。不过,在根设备或其他不存在上一层 vfsmount 数据结构的情况下,这个指针指向该数据结构本身。同时,vfsmount 数据结构中还有 mnt_child 和 mnt_mounts 两个队列头,只要上一层的 vfsmount 数据结构存在,就通过 mnt_child 链入上一层 vfsmount 结构的 mnt_mounts 队列中。这样,就形成一种设备安装的树形结构,从一个 vfsmount 结构的 mnt_mounts 队列开始可以找到所有直接或间接安装在这个设备上(的文件系统中)的其他设备。
- 此外,系统中还有个总的 vfsmount 结构队列 vfsmntlist,相应地 vfsmount 数据结构中还有个队列头 mnt_list。所有已安装设备的 vfsmount 结构都通过 mnt_list 链入 vfsmntlist 队列中。
⑥ 导图
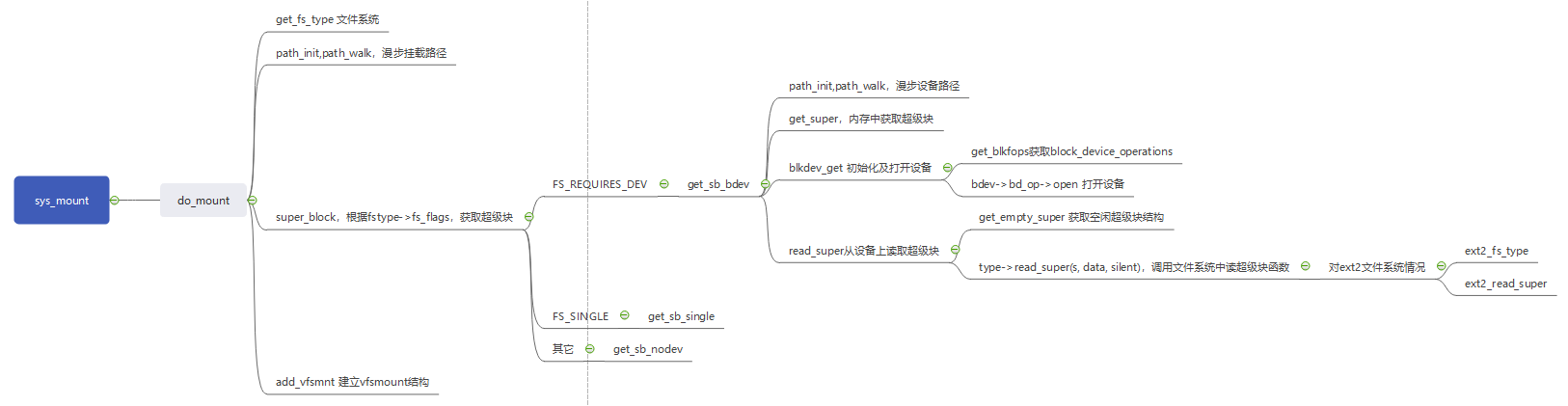
⑦ 导图
kern_mount
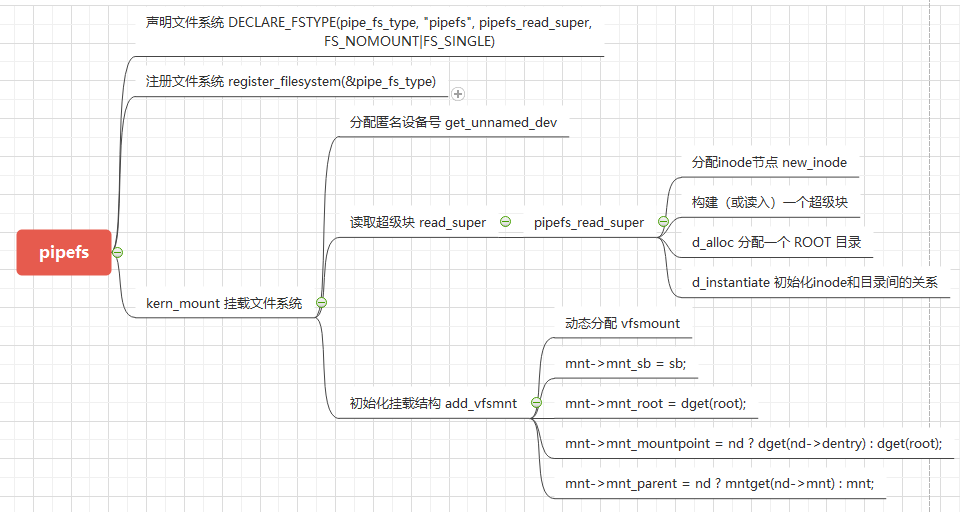
5.5 文件的打开与关闭
用户进程在能够读/写一个文件之前必须要先 “打开” 这个文件。对文件的读/写从概念上说是一种进程与文件系统之间的一种 “有连接” 通信,所谓 “打开文件” 实质上就是在进程与文件之间建 立起连接,而 “打开文件号” 就惟一地标识着这样一个连接。不过,严格意义上的 “连接” 意味着一个独立的 “上下文” ,如果一个进程与某个目标之间重复建立起多个连接,则每个连接都应该是互相独立的。在文件系统的处理中,每当一个进程重复打开同一个文件时就建立起一个由 file 数据结构代表的独立的上下文。通常,一个 file 数据结构,即一个读/写文件的上下文,都由一个 “打开文件号” 加以标识,但是通过系统调用 dup() 或 dup2() 却可以使同一个 file 结构对应到多个 “打开文件号。”
1、sys_open
打开文件的系统调用是 open() ,在内核中通过 sys_open() 实现,其代码在 fs/open.c 中。
// fs/open.c
asmlinkage long sys_open(const char * filename, int flags, int mode)
{
char * tmp;
int fd, error;
#if BITS_PER_LONG != 32
flags |= O_LARGEFILE;
#endif
tmp = getname(filename);
fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
fd = get_unused_fd();
if (fd >= 0) {
// 显然,sys_open() 的主体是filp_open() ,其代码也在fs/open.c中
struct file *f = filp_open(tmp, flags, mode);
error = PTR_ERR(f);
if (IS_ERR(f))
goto out_error;
fd_install(fd, f);
}
out:
putname(tmp);
}
return fd;
out_error:
put_unused_fd(fd);
fd = error;
goto out;
}
调用参数 filename 实际上是文件的路径名(绝对路件名或相对路径名);mode 表示打开的模式, 如 “只读” 等等;而 flags 则包含了许多标志位,用以表示打开模式以外的一些属性和要求。函数通过 getname() 从用户空间把文件的路径名拷贝到系统空间,并通过 get_unused_fd() 从当前进程的 “打开文件表” 中找到一个空闲的表项,该表项的下标即为 “打开文件号” 。然后,根据文件名通过 filp_open() 找到或创建一个 “连接” ,或者说读/写该文件的上下文。文件读写的上下文是由 file 数据结构代表和描绘的,其定义见 include/linux/fs.h:
(1)file
// include/linux/fs.h
struct file {
struct list_head f_list;
struct dentry *f_dentry;
struct vfsmount *f_vfsmnt;
struct file_operations *f_op;
atomic_t f_count;
unsigned int f_flags;
mode_t f_mode;
loff_t f_pos;
unsigned long f_reada, f_ramax, f_raend, f_ralen, f_rawin;
struct fown_struct f_owner;
unsigned int f_uid, f_gid;
int f_error;
unsigned long f_version;
/* needed for tty driver, and maybe others */
void *private_data;
};
(2)get_unused_fd
// fs/open.c
/*
* Find an empty file descriptor entry, and mark it busy.
*/
int get_unused_fd(void)
{
struct files_struct * files = current->files;
int fd, error;
error = -EMFILE;
write_lock(&files->file_lock);
repeat:
fd = find_next_zero_bit(files->open_fds,
files->max_fdset,
files->next_fd);
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
if (fd >= current->rlim[RLIMIT_NOFILE].rlim_cur)
goto out;
/* Do we need to expand the fdset array? */
if (fd >= files->max_fdset) {
error = expand_fdset(files, fd);
if (!error) {
error = -EMFILE;
goto repeat;
}
goto out;
}
/*
* Check whether we need to expand the fd array.
*/
if (fd >= files->max_fds) {
error = expand_fd_array(files, fd);
if (!error) {
error = -EMFILE;
goto repeat;
}
goto out;
}
FD_SET(fd, files->open_fds);
FD_CLR(fd, files->close_on_exec);
files->next_fd = fd + 1;
#if 1
/* Sanity check */
if (files->fd[fd] != NULL) {
printk("get_unused_fd: slot %d not NULL!\n", fd);
files->fd[fd] = NULL;
}
#endif
error = fd;
out:
write_unlock(&files->file_lock);
return error;
}
(3)files_struct
// include/linux/sched.h
/*
* Open file table structure
*/
struct files_struct {
atomic_t count;
rwlock_t file_lock;
int max_fds;
int max_fdset;
int next_fd;
struct file ** fd; /* current fd array */
fd_set *close_on_exec;
fd_set *open_fds;
fd_set close_on_exec_init;
fd_set open_fds_init;
struct file * fd_array[NR_OPEN_DEFAULT];
};
这个数据结构中最主要的成分是一个 file 结构指针数组 fd_array[],这个数组的大小是固定的,即 32,其下标即为 “打开文件号” 。另外,结构中还有个指针 fd ,最初时指向 fd_array[]。结构中还有两个位图 close_on_exec_init 和 open_fds_init,这些位图大致对应着 file 结构指针数组的内容,但是比 fd_array[] 的大小要大得多。同时,又有两个指针 close_on_exec 和 open_fds,最初时分别指向上述两个位图。每次打开文件分配一个打开文件号时就将由 open_fds 所指向位图中的相应位设成 1 。此外,该数据结构中还有两个参数 max_fds 和 max_fdset,分别反映着当前 file 结构指针数组与位图的容量。一个进程可以有多少个已打开文件只取决于该进程的 task_struct 结构中关于可用资源的限制(见上面代码中的第701行)。在这个限制以内,如果超出了其 file 结构指针数组的容量就通过 expand_fd_array() 扩充该数组的容量,并让指针 fd 指向新的数组;如果超出了位图的容量就通过 expand_fdset() 扩充两个位图的容量,并使两个指针也分别指向新的位图。这样,就克服了早期Unix因只采用固定大小的 file 结构指针数组而使每个进程可以同时打开文件数量受到限制的缺陷。
打开文件时,更确切地说是分配空闲打开文件号时,通过宏操作 FD_SET() 将 open_fds 所指向的位图中的相应位设成 1,表示这个打开文件号已不再空闲,这个位图代表着已经在使用中的打开文件号。 同时,还通过 FD_CLR() 将由指针 close_on_exec 所指向的位图中的相应位清 0,表示如果当前进程通过 exec() 系统调用执行一个可执行程序的话无需将这个文件关闭。这个位图的内容可以通过 ioctl() 系统调用来设置。
动态地调整可同时打开的文件数量对于现代、特别是面向对象的环境具有重要意义,因为在这些环境下常常要求同时打开数量众多(但是每个文件却很小)的文件。
(4)filp_open
// fs/open.c
/*
* Note that while the flag value (low two bits) for sys_open means:
* 00 - read-only
* 01 - write-only
* 10 - read-write
* 11 - special
* it is changed into
* 00 - no permissions needed
* 01 - read-permission
* 10 - write-permission
* 11 - read-write
* for the internal routines (ie open_namei()/follow_link() etc). 00 is
* used by symlinks.
*/
struct file *filp_open(const char * filename, int flags, int mode)
{
int namei_flags, error;
struct nameidata nd;
namei_flags = flags;
if ((namei_flags+1) & O_ACCMODE)
namei_flags++;
if (namei_flags & O_TRUNC)
namei_flags |= 2;
error = open_namei(filename, namei_flags, mode, &nd);
if (!error)
return dentry_open(nd.dentry, nd.mnt, flags);
return ERR_PTR(error);
}
这里的参数 flags 就是系统调用 open() 传下来的,它遵循 open() 界面上对 flags 的约定,但是这里调用的 open_namei() 却对这些标志位有不同的约定(见600行至613行中的注释),所以要在调用 open_namei() 前先加以变换,对 i386 处理器,用于 open() 界面上的标志位是在 include/asm-i386/fcntl.h 中定义的。
(5)open_namei
// fs/namei.c
/*
* open_namei()
*
* namei for open - this is in fact almost the whole open-routine.
*
* Note that the low bits of "flag" aren't the same as in the open
* system call - they are 00 - no permissions needed
* 01 - read permission needed
* 10 - write permission needed
* 11 - read/write permissions needed
* which is a lot more logical, and also allows the "no perm" needed
* for symlinks (where the permissions are checked later).
* SMP-safe
*/
int open_namei(const char * pathname, int flag, int mode, struct nameidata *nd)
{
int acc_mode, error = 0;
struct inode *inode;
struct dentry *dentry;
struct dentry *dir;
int count = 0;
acc_mode = ACC_MODE(flag);
/*
* The simplest case - just a plain lookup.
*/
// 调用参数 flag 中的 O_CREAT 标志位表示如果要打开的文件不存在就创建这个文件。所以,如果
// 这个标志位为0,就仅仅是在文件系统中寻找目标节点,这就是通过 path_init() 和path_walk() 根据目
// 标节点的路径名找到该节点的dentry结构(以及inode结构)的过程,那一经在前面介绍过了。这里
// 惟一值得一提的是在调用path_init() 时的参数flag还要通过lookup_flags() 进行一些处埋,其代码也在
// fs/namei.c 中
if (!(flag & O_CREAT)) {
if (path_init(pathname, lookup_flags(flag), nd))
error = path_walk(pathname, nd);
if (error)
return error;
dentry = nd->dentry;
goto ok;
}
/*
* Create - we need to know the parent.
*/
if (path_init(pathname, LOOKUP_PARENT, nd))
error = path_walk(pathname, nd);
if (error)
return error;
/*
* We have the parent and last component. First of all, check
* that we are not asked to creat(2) an obvious directory - that
* will not do.
*/
error = -EISDIR;
if (nd->last_type != LAST_NORM || nd->last.name[nd->last.len])
goto exit;
// 我们已经找到了目标文件所在目录的 dentry 结构,并让指针 dir 指向这个数据结构,下一步就
// 是通过 lookup_hash() 寻找目标文件的 dentry 结构了(980行)。函数 lookup_hash() 的代码也在
// fs/namei.c 中。
dir = nd->dentry;
down(&dir->d_inode->i_sem);
dentry = lookup_hash(&nd->last, nd->dentry);
do_last:
error = PTR_ERR(dentry);
if (IS_ERR(dentry)) {
up(&dir->d_inode->i_sem);
goto exit;
}
/* Negative dentry, just create the file */
if (!dentry->d_inode) {
error = vfs_create(dir->d_inode, dentry, mode);
up(&dir->d_inode->i_sem);
dput(nd->dentry);
nd->dentry = dentry;
if (error)
goto exit;
/* Don't check for write permission, don't truncate */
acc_mode = 0;
flag &= ~O_TRUNC;
goto ok;
}
/*
* It already exists.
*/
up(&dir->d_inode->i_sem);
error = -EEXIST;
if (flag & O_EXCL)
goto exit_dput;
if (d_mountpoint(dentry)) {
error = -ELOOP;
if (flag & O_NOFOLLOW)
goto exit_dput;
do __follow_down(&nd->mnt,&dentry); while(d_mountpoint(dentry));
}
error = -ENOENT;
if (!dentry->d_inode)
goto exit_dput;
if (dentry->d_inode->i_op && dentry->d_inode->i_op->follow_link)
goto do_link;
dput(nd->dentry);
nd->dentry = dentry;
error = -EISDIR;
if (dentry->d_inode && S_ISDIR(dentry->d_inode->i_mode))
goto exit;
ok:
error = -ENOENT;
inode = dentry->d_inode;
if (!inode)
goto exit;
error = -ELOOP;
if (S_ISLNK(inode->i_mode))
goto exit;
error = -EISDIR;
if (S_ISDIR(inode->i_mode) && (flag & FMODE_WRITE))
goto exit;
error = permission(inode,acc_mode);
if (error)
goto exit;
/*
* FIFO's, sockets and device files are special: they don't
* actually live on the filesystem itself, and as such you
* can write to them even if the filesystem is read-only.
*/
if (S_ISFIFO(inode->i_mode) || S_ISSOCK(inode->i_mode)) {
flag &= ~O_TRUNC;
} else if (S_ISBLK(inode->i_mode) || S_ISCHR(inode->i_mode)) {
error = -EACCES;
if (IS_NODEV(inode))
goto exit;
flag &= ~O_TRUNC;
} else {
error = -EROFS;
if (IS_RDONLY(inode) && (flag & 2))
goto exit;
}
/*
* An append-only file must be opened in append mode for writing.
*/
error = -EPERM;
if (IS_APPEND(inode)) {
if ((flag & FMODE_WRITE) && !(flag & O_APPEND))
goto exit;
if (flag & O_TRUNC)
goto exit;
}
/*
* Ensure there are no outstanding leases on the file.
*/
error = get_lease(inode, flag);
if (error)
goto exit;
if (flag & O_TRUNC) {
error = get_write_access(inode);
if (error)
goto exit;
/*
* Refuse to truncate files with mandatory locks held on them.
*/
error = locks_verify_locked(inode);
if (!error) {
DQUOT_INIT(inode);
error = do_truncate(dentry, 0);
}
put_write_access(inode);
if (error)
goto exit;
} else
if (flag & FMODE_WRITE)
DQUOT_INIT(inode);
return 0;
exit_dput:
dput(dentry);
exit:
path_release(nd);
return error;
do_link:
error = -ELOOP;
if (flag & O_NOFOLLOW)
goto exit_dput;
/*
* This is subtle. Instead of calling do_follow_link() we do the
* thing by hands. The reason is that this way we have zero link_count
* and path_walk() (called from ->follow_link) honoring LOOKUP_PARENT.
* After that we have the parent and last component, i.e.
* we are in the same situation as after the first path_walk().
* Well, almost - if the last component is normal we get its copy
* stored in nd->last.name and we will have to putname() it when we
* are done. Procfs-like symlinks just set LAST_BIND.
*/
UPDATE_ATIME(dentry->d_inode);
// 读过 path_walk() 的读者对这段代码不应该感到陌生。找到连接目标的操作主要是由具体文件系
// 统在其 inode_operations 结构中的函数指针如 follow_link 提供的。对于 Ext2 这个函数为
// ext2_follow_link() ,而最后这个函数又会通过 vfs_follow_link() 调用 path_walk() ,
// 这读者已经看到过了。注意前面通过 path_init() 设置在 nameidata 数据结构中的标志位并未改变,
// 仍是 LOOKUP_PARENT 。
// 对于目标节点是符号连接的情况,如果说在 follow_link 之前的“目标节点”是“视在目标节点”, 那么
// follow_link 以后的nd->last就是“真实目标节点”的节点名了,而nd->dentry则仍旧指向其父
// 节点的dentry结构。
error = dentry->d_inode->i_op->follow_link(dentry, nd);
dput(dentry);
if (error)
return error;
if (nd->last_type == LAST_BIND) {
dentry = nd->dentry;
goto ok;
}
error = -EISDIR;
if (nd->last_type != LAST_NORM)
goto exit;
if (nd->last.name[nd->last.len]) {
putname(nd->last.name);
goto exit;
}
if (count++==32) {
dentry = nd->dentry;
putname(nd->last.name);
goto ok;
}
dir = nd->dentry;
down(&dir->d_inode->i_sem);
dentry = lookup_hash(&nd->last, nd->dentry);
putname(nd->last.name);
goto do_last;
}
(6)导图
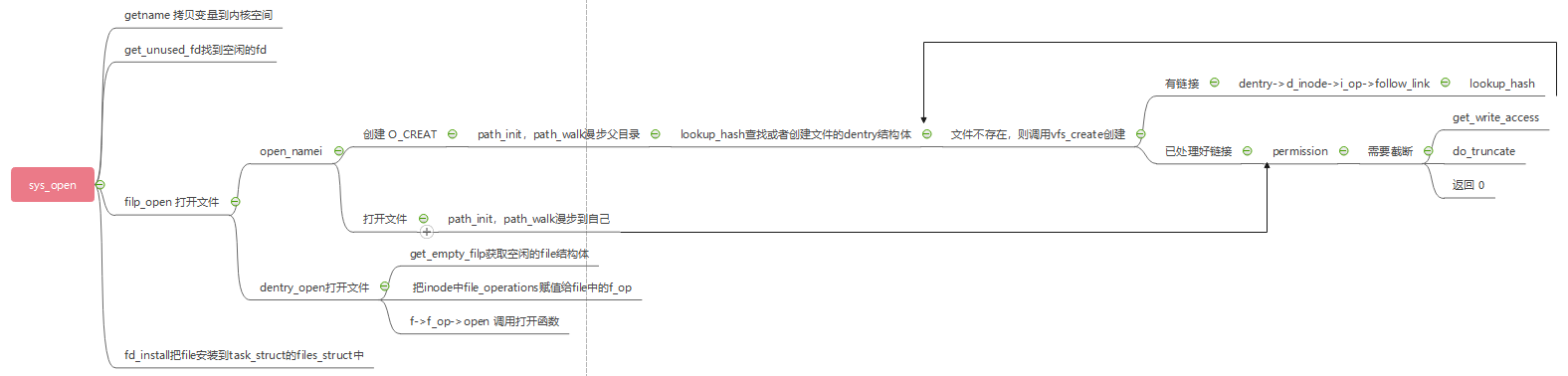
5.6 文件的写与读
只有在 “打开” 了文件以后,或者说建立起进程与文件之间的 “连接” 之后,才能对文件进行读 /写。文件的读/写主要是通过系统调用 read() 和 write() 完成的,对于读/写文件的进程,目标文件由一个 “打开文件号” 代表。
为了提高效率,稍为复杂一些的操作系统对文件的读/写都是带缓冲的,Linux 当然也不例外。像 VFS 一样,Linux文件系统的缓冲机制也是它的一大特色。所谓缓冲,是指系统为最近刚读/写过的文件内容在内核中保留一份副本,以便当再次需要已经缓冲存储在副本中的内容时就不必再临时从设备上读入,而需要写的时候则可以先写到副本中,待系统较为空闲时再从副本写入设备。在多进程的系统中,由于同一文件可能为多个进程所共享,缓冲的作用就更显著了。
然而,怎样实现缓冲,在哪一个层次上实现缓冲,却是一个值得仔细加以考虑的问题。回顾一下本章开头处的文件系统层次图(图5.3和图5.1),在系统中处于最高层的是进程,这一层可以称为 “应用层” ,是在用户空间运行的,在这里代表着目标文件的是 “打开文件号” 。在这一层中提供缓冲似乎最贴近文件内容的使用者,但是那样就需要用户进程的介入,从而不能做到对使用者 “透明” ,并且缓冲的内容不能为其他进程所共享,所以显然是不妥当的。在应用层以下是 “文件层’',又可细分为VFS 层和具体的文件系统层,再下面就是 “设备层” 了。这些层次都在内核中,所以在这些层次上实现缓冲都可以达到对用户透明的目标。设备层是最贴近设备,即文件内容的 “源头” 的地方,在这里实现缓冲显然是可行的。事实上,早期Unix内核中的文件缓冲就是以数据块缓冲的形式在这一层上实现的。 但是,设备层上的缓冲离使用者的距离太远了一点,特别是当文件层又分为 VFS 和具体文件系统两个子层时,每次读/写都要穿越这么多界面深入到设备层就难免使人有一种 “长途跋涉” 之感。很自然地,设计人员把眼光投向了文件层。
在文件层中有三种主要的数据结构,就是 file 结构、dentry 结构以及 inode 结构。
先看 file 结构。前面讲过,一个 file 结构代表着目标文件的一个上下文,不但不同的进程可以在同 一个文件上建立不同的上下文,就是同一个进程也可以通过打开同一个文件多次而建立起多个上下文。 如果在 file 结构中设置一个缓冲区队列,那么缓冲区中的内容虽然贴近这个特定上下文的使用者,却不便于为多个进程共享,甚至不便于同一个进程打开的不同上下文 “共享” 。这显然是不合适的,需要把这些缓冲区像数学上的 “提取公因子” 那样放到一个公共的地方。
那么 dentry 结构怎么样?这个数据结构并不属于某一个上下文,也不属于某一个进程,可以为所有的进程和上下文共享。可是,dentry 结构与目标文件并不是一对一的关系,通过文件连接,我们可以为已经存在的文件建立 “别名” 。一个 dentry 结构只是惟一地代表着文件系统中的一个节点,也就是一个路径名,但是多个节点可以同时代表着同一个文件,所以,还应该再来一次 “提取公因子” 。
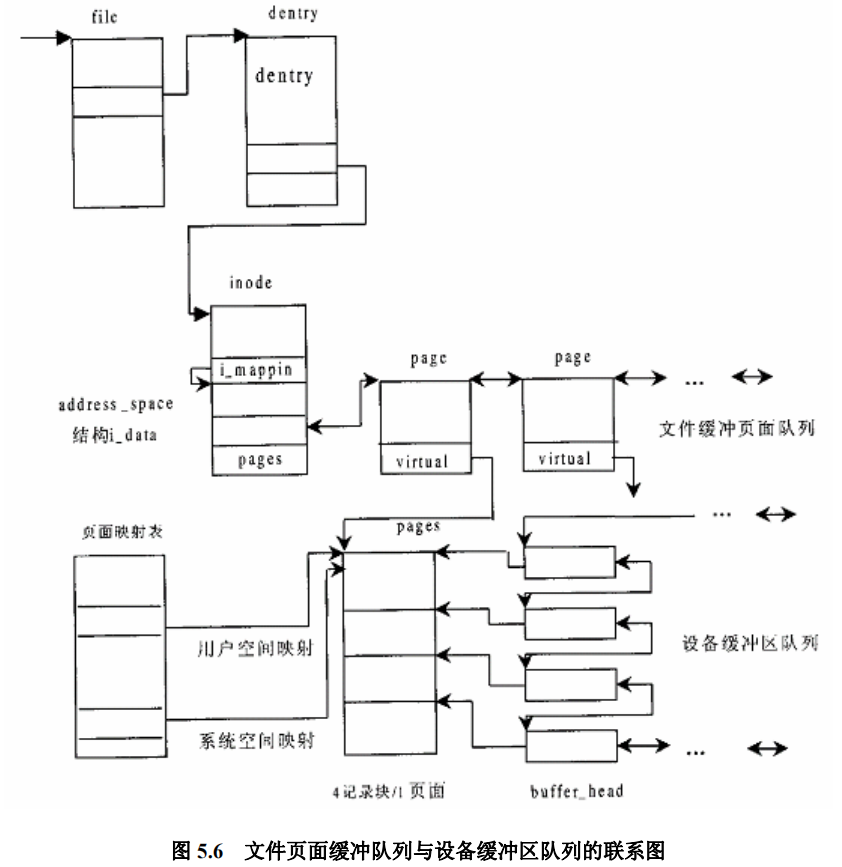
显然,在 inode 数据结构中设置一个缓冲区队列是最合适不过的了,首先,inode 结构与文件是一对一的关系,即使一个文件有多个路径名,最后也归结到同一个 inode 结构上。再说,一个文件中的内容是不能由其他文件共享的,在同一时间里,设备上的每一个记录块都只能属于至多一个文件(或者就是空闲),将载有同一个文件内容的缓冲区都放在其所属文件的 inode 结构中是很自然的事。因此,在 inode 数据结构中设置了一个指针 i_mapping,它指向一个 address_space 数据结构(通常这个数据结构就是 inode 结构中的 i_data ),缓冲区队列就在这个数据结构中。
不过,挂在缓冲区队列中的并不是记录块而是内存页面。也就是说,文件的内容并不是以记录块为单位,而是以页面为单位进行缓冲的。如果记录块的大小为 1K 字节,那么一个页面就相当于 4 个记录块。为什么要这样做呢?这是为了将文件内容的缓冲与文件的内存映射结合在一起。我们在第2章中提到过,一个进程可以通过系统调用 mmap() 将一个文件映射到它的用户空间。建立了这样的映射以后,就可以像访问内存一样地访问这个文件。如果将文件的内容以页面为单位缓冲,放在附属于该文件的 inode 结构的缓冲队列中,那么只要相应地设置进程的内存映射表,就可以很自然地将这些缓冲页面映射到进程的用户空间中。这样,在按常规的文件操作访问一个文件时,可以通过 read() 和 write() 系统调用目标文件的 inode 结构访问这些缓冲页面;而通过内存映射机制访问这个文件时,就可以经由页面映射表直接读写这些缓冲着的页面。当目标页面不在内存中时,常规的文件操作通过系统调用 read() 、write() 的底层将其从设备上读入,而通过内存映射机制访问这个文件时则由 “缺页异常” 的服务程序将目标页面从设备上读入。也就是说,同一个缓冲页面可以满足两方面的要求,文件系统的缓 冲机制和文件的内存映射机制巧妙地结合在一起了。明白了这个背景,对于上述的指针为什么叫 i_mapping,它所指向的数据结构为什么叫 address_space,就不会感到奇怪了。
可是,尽管以页面为单位的缓冲对于文件层确实是很好的选择,对于设备层则不那么合适了。对设备层而言,最自然的当然还是以记录块为单位的缓冲,因为设备的读/写都是以记录块为单位的。 不过,从磁盘上读/写时主要的时间都花在准备工作(如磁头组的定位)上,一旦准备好了以后读一个记录块与接连读几个记录块相差不大,而且每次只读写一个记录块倒反而是不经济的。所以每次读写若干连续的记录块、以页面为单位来缓冲也并不成为问题。另一方面,如果以页面为单位缓冲,而一个页面相当于若干个记录块,那么无论是对于缓冲页面还是对于记录块缓冲区,其控制和附加信息(如链接指针等)显然应该游离于该页面之外,这些信息不应该映射到进程的用户空间。这个问题也不难解决。读者不妨回顾一下,第2章中讲过的 page 数据结构就是这样。在 page 数据结构中有个指针 virtual 指向其所代表的页面,但是 page 结构本身则不在这个页面中。同样地,在 “缓冲区头部” 即 buffer_head 数据结构中有一个指针 b_data 指向缓冲区,而 buffer_head 结构本身则不在缓冲区中。所以,在设备层中只要保持一些 buffer_head 结构,让它们的 b_data 指针分别指向缓冲页面中的相应位置上就可以了。 以一个缓冲页面为例,在文件层它通过一个 page 数据结构挂入所属 inode 结构的缓冲页面队列,并且同时又可以通过各个进程的页面映射表映射到这些进程的内存空间;而在设备层则又通过若干(通常是四个,因为页面的大小为 4KB,而缓冲区的大小为 1KB) buffer_head 结构挂入其所在设备的缓冲区队列。这样,以页面为单位为文件内容建立缓冲真是 “一箭三雕” 。下页的示意图(图5.6)也许有助于读者对缓冲机制的理解。
在这样一个结构框架中,一旦所欲访问的内容已经在缓冲页面队列中,读文件的效率就很高了, 只要找到文件的 inode 结构( file 结构中有指针指向 dentry 结构,而 dentry 结构中有指针指向 inode 结构)就找到了缓冲页面队列,从队列中找到相应的页面就可以读出了。缓冲页面的 page 结构除链入附属于 inode 结构的缓冲页面队列外,同时也链入到一个杂凑表 page_hash_table 中的杂凑队列中(图中没有画出),所以寻找目标页面的操作也是效率很高的,并不需要在整个缓冲页面队列中线性搜索。
那么,写操作又如何呢?如前所述,一旦目标记录块已经存在于缓冲页面中,写操作只是把内容写到该缓冲页面中,所以从发动写操作的进程的角度来看速度也是很快的。至于改变了内容的缓冲页面,则由系统负责在 CPU 较为空闲时写入设备。为了这个目的,内核中设置了一个内核线程 kflushd。 平时这个线程总是在睡眠,有需要时(例如写操作以后)就将其唤醒,然后当 CPU 较为空闲时就会调度其运行,将已经改变了内容的缓冲页面写回设备上。这样,启动写操作的进程和 kflushd 就好像是一条流水作业线上的上下两个工位上的操作工,而改变缓冲页面的内容(写操作)与将改变了内容的缓冲页面写回设备上(称为 “同步” )则好像是上下两道工序。除这样的 “分工合作” 以外,每个打开了某个文件的进程还可以直接通过系统调用 sync() 强行将缓冲页面写回设备上。此外,缓冲页面的 page 结构还链入到一个 LRU 队列中,要是一个页面很久没有受到访问,内存空间又比较短缺,就可以把它释放而另作他用。
除通过缓冲来提高文件读/写的效率外,还有个措施是 “预读” 。就是说,如果一个进程发动了对某一个缓冲页面的读(或写)操作,并且该页面尚不在内存中而需要从设备上读入,那么就可以预测, 通常情况下它接下去可能会继续往下读写,因此不妨预先将后面几个页面也一起读进来。如前所述, 对于磁盘一类的 “块设备” ,读操作中最费时间的是磁头组定位,一旦到了位,从设备多读几个记录块并不相差多少时间。一般而言,对文件的访问有两种形式。一种是 “随机访问” ,其访问的位置并无规律;另一种是 “顺序访问” 。预读之所以可能提高效率就是因为大量的文件操作都是顺序访问。其实, 以页面(而不是记录块)为单位的缓冲本身就隐含着预读,因为通常一个页面包含着 4 个记录块,只要访问的位置不在其最后一个记录块中,就多少要预读几个记录块,只不过预读的量很小面已。
在早期的 Unix 系统中,由于当时的磁盘容量小,速度慢,内存也小,一般只预读一个记录块。而现在的预读,则动辍就是几十K字节,甚至上百K字节。当然,那也要视具体情况而定,所以在 include/linux/blkdev.h 中定义了 一个常数 MAX_READAHEAD,其定义为:
// include/linux/blkdev.h
/* read-ahead in pages.. */
#define MAX_READAHEAD 31
#define MIN_READAHEAD 3
这里的数值 31 表示 31 个页面,即 124K 字节。从这里也可以看出,许多比较小的文件其实都是一次就全部预读入内存的。当然,这里说的是最大预读量,实际运行时还要看其他条件,未必真的预读那么多。
由于预读的提前量已经不再限于一个记录块,现在 file 结构中实际上要维持两个上下文了。一个就是由 “当前位置” f_pos 代表的真正的读/写上下文,而另一个则是预读的上下文。为此目的,在 file 结构中增设了 f_reada、f_ramax、f_raend、f_rawin 等几个字段。这几个字段的名称反映了它们的用途( ra 表示 “read ahead"),具体的含义在下面的代码中就可看到。
另一方面,预读虽然并不花费很多时间,但毕竟还是需要一点时间。当一个进程启动一次对文件内容的访问,而访问的目标又恰好不在内存中因而需要从设备上读入时,该进程只好暂时交出运行权, 进入睡眠中等待,称之为 “受阻” (blocked)。可是等待多久呢? 一旦本次访问的目标页面进入了内存, 等待中的进程就可以而且应该恢复运行了,而没有理由等待到所有预读的页面也全部进入内存。从设备上读/写一般都是通过 DMA 进行的,它固然需要一定的时间,但是并不需要 CPU 太多的干预,CPU 完全可以忙自己的事。所以,从设备上读入的操作可以分成两部分。第一部分是必须要等待的,在此期间启动本次操作的进程只好暂时停下来,这一部分操作是 “同步” 的。第二部分则无须等待,在此期间启动本次操作的进程可以继续运行,所以这一部分操作是异步的。至于写操作,则如前所述在大多数情况下是留给内核线程 kflushd 完成的,那当然是异步的。
读完了面这一大段的概述,现在可以开始读代码了。先看 sys_write() ,这是系统调用 write() 在内核中的实现,其代码在 fs/read_write.c 中:
1、sys_write
// fs/read_write.c
asmlinkage ssize_t sys_write(unsigned int fd, const char * buf, size_t count)
{
ssize_t ret;
struct file * file;
ret = -EBADF;
file = fget(fd);
if (file) {
if (file->f_mode & FMODE_WRITE) {
struct inode *inode = file->f_dentry->d_inode;
ret = locks_verify_area(FLOCK_VERIFY_WRITE, inode, file,
file->f_pos, count);
if (!ret) {
ssize_t (*write)(struct file *, const char *, size_t, loff_t *);
ret = -EINVAL;
if (file->f_op && (write = file->f_op->write) != NULL)
ret = write(file, buf, count, &file->f_pos);
}
}
if (ret > 0)
inode_dir_notify(file->f_dentry->d_parent->d_inode,
DN_MODIFY);
fput(file);
}
return ret;
}
先检查该文件究竟是否加了锁,以及足否允许使用强制锁。如果确实加了锁,并且可能是强制锁, 就进一步通过 locks_mandatory_area() 检查所要求的区域是否也被强制锁住了。这个函数的代码在 fs/locks.c 中,我们在这里就不看了。它的算法是很简单的,无非就是扫描该文件的 inode 结构中的 i_flock 队列里面每一个 file_lock 数据结构并进行比对。从这里读者可以看出为什么强制锁并不总是比协调锁优越,因为对每次读/写操作它都要扫描这个队列进行比对,这显然会降低文件读写的速度。特别是如果每次读/写的长度都很小,那样花在强制锁检查上的开销所占比例就相当大了。
通过了对强制锁的检查以后,就是写操作本身了。可想而知,不同的文件系统有不同的写操作, 具体的文件系统通过其 file_operations 数据结构提供用于写操作的函数指针,就 Ext2 文件系统而言, 它有两个这样的数据结构,一个是 ext2_file_operations,另一个是 ext2_dir_operations,视操作的目标为文件或目录而选择其一,在打开该文件时 “安装” 在其 file 结构中。对于普通的文件,这个函数指针指向 generic_file_write() ,其代码在 mm/filemap.c 中。
(1)generic_file_write
// fs/ext2/file.c
struct file_operations ext2_file_operations = {
llseek: ext2_file_lseek,
read: generic_file_read,
write: generic_file_write,
ioctl: ext2_ioctl,
mmap: generic_file_mmap,
open: ext2_open_file,
release: ext2_release_file,
fsync: ext2_sync_file,
};
// =================================================================================
// mm/filemap.c
/*
* Write to a file through the page cache.
*
* We currently put everything into the page cache prior to writing it.
* This is not a problem when writing full pages. With partial pages,
* however, we first have to read the data into the cache, then
* dirty the page, and finally schedule it for writing. Alternatively, we
* could write-through just the portion of data that would go into that
* page, but that would kill performance for applications that write data
* line by line, and it's prone to race conditions.
*
* Note that this routine doesn't try to keep track of dirty pages. Each
* file system has to do this all by itself, unfortunately.
* okir@monad.swb.de
*/
ssize_t
generic_file_write(struct file *file,const char *buf,size_t count,loff_t *ppos)
{
struct inode *inode = file->f_dentry->d_inode;
struct address_space *mapping = inode->i_mapping;
unsigned long limit = current->rlim[RLIMIT_FSIZE].rlim_cur;
loff_t pos;
struct page *page, *cached_page;
unsigned long written;
long status;
int err;
cached_page = NULL;
down(&inode->i_sem);
pos = *ppos;
err = -EINVAL;
if (pos < 0)
goto out;
err = file->f_error;
if (err) {
file->f_error = 0;
goto out;
}
written = 0;
if (file->f_flags & O_APPEND)
pos = inode->i_size;
/*
* Check whether we've reached the file size limit.
*/
err = -EFBIG;
if (limit != RLIM_INFINITY) {
if (pos >= limit) {
send_sig(SIGXFSZ, current, 0);
goto out;
}
if (count > limit - pos) {
send_sig(SIGXFSZ, current, 0);
count = limit - pos;
}
}
status = 0;
if (count) {
remove_suid(inode);
inode->i_ctime = inode->i_mtime = CURRENT_TIME;
mark_inode_dirty_sync(inode);
}
while (count) {
unsigned long bytes, index, offset;
char *kaddr;
int deactivate = 1;
/*
* Try to find the page in the cache. If it isn't there,
* allocate a free page.
*/
offset = (pos & (PAGE_CACHE_SIZE -1)); /* Within page */
index = pos >> PAGE_CACHE_SHIFT;
bytes = PAGE_CACHE_SIZE - offset;
if (bytes > count) {
bytes = count;
deactivate = 0;
}
/*
* Bring in the user page that we will copy from _first_.
* Otherwise there's a nasty deadlock on copying from the
* same page as we're writing to, without it being marked
* up-to-date.
*/
{ volatile unsigned char dummy;
__get_user(dummy, buf);
__get_user(dummy, buf+bytes-1);
}
status = -ENOMEM; /* we'll assign it later anyway */
page = __grab_cache_page(mapping, index, &cached_page);
if (!page)
break;
/* We have exclusive IO access to the page.. */
if (!PageLocked(page)) {
PAGE_BUG(page);
}
status = mapping->a_ops->prepare_write(file, page, offset, offset+bytes);
if (status)
goto unlock;
kaddr = page_address(page);
status = copy_from_user(kaddr+offset, buf, bytes);
flush_dcache_page(page);
if (status)
goto fail_write;
status = mapping->a_ops->commit_write(file, page, offset, offset+bytes);
if (!status)
status = bytes;
if (status >= 0) {
written += status;
count -= status;
pos += status;
buf += status;
}
unlock:
/* Mark it unlocked again and drop the page.. */
UnlockPage(page);
if (deactivate)
deactivate_page(page);
page_cache_release(page);
if (status < 0)
break;
}
*ppos = pos;
if (cached_page)
page_cache_free(cached_page);
/* For now, when the user asks for O_SYNC, we'll actually
* provide O_DSYNC. */
if ((status >= 0) && (file->f_flags & O_SYNC))
status = generic_osync_inode(inode, 1); /* 1 means datasync */
err = written ? written : status;
out:
up(&inode->i_sem);
return err;
fail_write:
status = -EFAULT;
ClearPageUptodate(page);
kunmap(page);
goto unlock;
}
(2)address_space
// include/linux/fs.h
struct address_space {
struct list_head clean_pages; /* list of clean pages */
struct list_head dirty_pages; /* list of dirty pages */
struct list_head locked_pages; /* list of locked pages */
unsigned long nrpages; /* number of total pages */
struct address_space_operations *a_ops; /* methods */
struct inode *host; /* owner: inode, block_device */
struct vm_area_struct *i_mmap; /* list of private mappings */
struct vm_area_struct *i_mmap_shared; /* list of shared mappings */
spinlock_t i_shared_lock; /* and spinlock protecting it */
};
struct address_space_operations {
int (*writepage)(struct page *);
int (*readpage)(struct file *, struct page *);
int (*sync_page)(struct page *);
int (*prepare_write)(struct file *, struct page *, unsigned, unsigned);
int (*commit_write)(struct file *, struct page *, unsigned, unsigned);
/* Unfortunately this kludge is needed for FIBMAP. Don't use it */
int (*bmap)(struct address_space *, long);
};
通常这个数据结构就在 inode 结构中,成为 inode 结构的一部分,那就是 i_data (注意切莫与 ext2_inode_info 结构中的数组 i_data[]相混淆)。结构中的队列头 pages 就是用来维持缓冲页面队列的。 如果将文件映射到某些进程的用户空间,则指针 i_mmap 指向一串虚存区间,即 vm_area_struct 结构, 其中的每一个数据结构都代表着该文件在某一个进程中的空间映射。还有个指针 a_ops 也是很重要的, 它指向一个 address_space_operations 数据结构。这个结构中的函数指针给出了缓冲页面与具体文件系统的设备层之间的关系和操作,例如怎样从具体文件系统的设备上读或写一个缓冲页面等等。就 Ext2 文件系统来说,这个数据结构为 ext2_aops,是在 fs/ext2/inode.c 中定义的:
// fs/ext2/inode.c
struct address_space_operations ext2_aops = {
readpage: ext2_readpage,
writepage: ext2_writepage,
sync_page: block_sync_page,
prepare_write: ext2_prepare_write,
commit_write: generic_commit_write,
bmap: ext2_bmap
};
(3)ext2_prepare_write
// fs/ext2/inode.c
static int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page,from,to,ext2_get_block);
}
① block_prepare_write
// =================================================================================
// fs/buffer.c
int block_prepare_write(struct page *page, unsigned from, unsigned to,
get_block_t *get_block)
{
struct inode *inode = page->mapping->host;
int err = __block_prepare_write(inode, page, from, to, get_block);
if (err) {
ClearPageUptodate(page);
kunmap(page);
}
return err;
}
static int __block_prepare_write(struct inode *inode, struct page *page,
unsigned from, unsigned to, get_block_t *get_block)
{
unsigned block_start, block_end;
unsigned long block;
int err = 0;
unsigned blocksize, bbits;
struct buffer_head *bh, *head, *wait[2], **wait_bh=wait;
char *kaddr = kmap(page);
blocksize = inode->i_sb->s_blocksize;
if (!page->buffers)
create_empty_buffers(page, inode->i_dev, blocksize);
head = page->buffers;
bbits = inode->i_sb->s_blocksize_bits;
block = page->index << (PAGE_CACHE_SHIFT - bbits);
for(bh = head, block_start = 0; bh != head || !block_start;
block++, block_start=block_end, bh = bh->b_this_page) {
if (!bh)
BUG();
block_end = block_start+blocksize;
if (block_end <= from)
continue;
if (block_start >= to)
break;
if (!buffer_mapped(bh)) {
err = get_block(inode, block, bh, 1);
if (err)
goto out;
if (buffer_new(bh)) {
unmap_underlying_metadata(bh);
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (block_end > to)
memset(kaddr+to, 0, block_end-to);
if (block_start < from)
memset(kaddr+block_start, 0, from-block_start);
if (block_end > to || block_start < from)
flush_dcache_page(page);
continue;
}
}
if (Page_Uptodate(page)) {
set_bit(BH_Uptodate, &bh->b_state);
continue;
}
if (!buffer_uptodate(bh) &&
(block_start < from || block_end > to)) {
ll_rw_block(READ, 1, &bh);
*wait_bh++=bh;
}
}
/*
* If we issued read requests - let them complete.
*/
while(wait_bh > wait) {
wait_on_buffer(*--wait_bh);
err = -EIO;
if (!buffer_uptodate(*wait_bh))
goto out;
}
return 0;
out:
return err;
}
如前所述,虽然在文件系统层次上是以页面为单位缓冲的, 在设备层次上却是以记录块为单位缓冲的。所以,如果一个缓冲页面的内容是一致的,就意味着构成这个页面的所有记录块的内容都一致,反过来,如果一个缓冲页面不一致,则未必每个记录块都不一致。因此,要根据写入的位置和长度找到具体涉及的记录块,针对这些记录块做写入的准备。
做些什么准备呢?简而言之就是使有关记录块缓冲区的内容与设备上相关记录块的内容相一致。 如果缓冲页面已经建立起对物理记录块的映射,则需要做的只是检查一下目录记录块的内容是否一致 (见第1607行利1608行),如果不一致就通过 ll_rw_block() 将设备上的记录块读到缓冲区中。由此可见,对文件的写操作实际上往往是 “写中有读” 、 “欲写先读” 。
可是,如果缓冲页面是新的,尚未映射到物理记录块呢?那就比较复杂一些了,因为根据页面号、 页面大小、记录块大小计算所得的记录块号(见1585行)只是文件内部的逻辑块号,这是在假定文件的内容为连续的线性空间这么一个前提下计算出来的,而实际的记录块在设备上的位置则是动态地分配和回收的。另一方面,在设备层也根本没有文件的概念,而只能按设备上的记录块号读写。设备上的记录块号也是逻辑块号,与设备上的记录块位图相对应。而设备上的逻辑块号与物理记录块有着一一对应的关系,所以在文件层也可以认为是 “物理块号” 。总而言之,这里有一个从文件内的逻辑记录块号到设备上的记录块号之间的映射问题。缺少了对这种映射关系的描述,就无法根据文件内的逻辑块号在设备上找到相应的记录块。可想而知,不同的文件系统可能有不同的映射关系或过程,这就是要由作为参数传给 __block_prepare_write() 的函数指针 get_block 来完成这种映射的原因。对于 Ext2 文件系统这个函数是 ext2_get_block() ,在 fs/ext2/inode.c 中。
② ext2_get_block
// fs/ext2/inode.c
/*
* Allocation strategy is simple: if we have to allocate something, we will
* have to go the whole way to leaf. So let's do it before attaching anything
* to tree, set linkage between the newborn blocks, write them if sync is
* required, recheck the path, free and repeat if check fails, otherwise
* set the last missing link (that will protect us from any truncate-generated
* removals - all blocks on the path are immune now) and possibly force the
* write on the parent block.
* That has a nice additional property: no special recovery from the failed
* allocations is needed - we simply release blocks and do not touch anything
* reachable from inode.
*/
static int ext2_get_block(struct inode *inode, long iblock, struct buffer_head *bh_result, int create)
{
int err = -EIO;
int offsets[4];
Indirect chain[4];
Indirect *partial;
unsigned long goal;
int left;
int depth = ext2_block_to_path(inode, iblock, offsets);
if (depth == 0)
goto out;
lock_kernel();
reread:
partial = ext2_get_branch(inode, depth, offsets, chain, &err);
/* Simplest case - block found, no allocation needed */
if (!partial) {
got_it:
bh_result->b_dev = inode->i_dev;
bh_result->b_blocknr = le32_to_cpu(chain[depth-1].key);
bh_result->b_state |= (1UL << BH_Mapped);
/* Clean up and exit */
partial = chain+depth-1; /* the whole chain */
goto cleanup;
}
/* Next simple case - plain lookup or failed read of indirect block */
if (!create || err == -EIO) {
cleanup:
while (partial > chain) {
brelse(partial->bh);
partial--;
}
unlock_kernel();
out:
return err;
}
/*
* Indirect block might be removed by truncate while we were
* reading it. Handling of that case (forget what we've got and
* reread) is taken out of the main path.
*/
if (err == -EAGAIN)
goto changed;
if (ext2_find_goal(inode, iblock, chain, partial, &goal) < 0)
goto changed;
left = (chain + depth) - partial;
err = ext2_alloc_branch(inode, left, goal,
offsets+(partial-chain), partial);
if (err)
goto cleanup;
if (ext2_splice_branch(inode, iblock, chain, partial, left) < 0)
goto changed;
bh_result->b_state |= (1UL << BH_New);
goto got_it;
changed:
while (partial > chain) {
bforget(partial->bh);
partial--;
}
goto reread;
}
参数 iblock 表示所处理的记录块在文件中的逻辑块号,inode 则指向文件的 inode 结构;参数 create 表示是否需要创建。从 __block_prepare_write() 中传下的实际参数值为 1,所以我们在这里只关心 create 为 1 的情景。从文件内块号到设备上块号的映射,最简单最迅速的当然莫过于使用一个以文件内块号为下标的线性数组,并且将这个数组置于索引节点 inode 结构中。可是,那样就需要很大的数组,从而使索引节点和 inode 结构也变得很大,或者就得使用可变长度的索引节点而使文件系统的结构更加复杂。
另一种方法是采用间接寻址,也就是将上述的数组分块放在设备上本来可用于存储数据的若干记录块中,而将这些记录块的块号放在索引节点和 inode 结构中。这些记录块虽然在设备上的数据区(而不是索引节点区)中,却并不构成文件本身的内容,而只是一些管理信息。由于索引节点(和 inode 结构)应该是固定大小的,所以当文件较大时还要将这种间接寻址的结构框架做成树状或链状,这样才能随着文件本身的大小而扩展其容量,显然,这种方法解决了容量的问题,但是降低了运行时的效率。
基于这些考虑,从 Unix 早期就采用了一种折衷的方法,可以说是直接与间接相结合。其方法是把整个文件的记录块寻址分成几个部分来实现。第一部分是以文件内块号为下标的数组,这是采用直接映射的部分,对于较小的文件这一部分就够用了。由于根据文件内块号就可以在 inode 结构里的数组中直接找到相应的设备上块号,所以效率很高。至于比较大的文件,其开头那一部分记录块号也同样直接就可以找到,但是当文件的大小超出这一部分的容量时,超出的那一部分就要采用间接寻址了。 Ext2 文件系统的这一部分的大小为 12 个记录块,即数组的大小为 12。当记录块大小为 1K 字节时,相应的文件大小为 12K 字节。在 Ext2 文件系统的 ext2_inode_info 结构中,有个大小为 15 的整型数组 i_data[],其开头 12 个元素即用于此项目。当文件大小超过这一部分的容量时,该数组中的第 13 个元素指向一个记录块,这个记录块的内容也是一个整型数组,其中的每个元素都指向一个设备上记录块。 如果记录块大小为 1K 字节,则该数组的大小为 256,也就是说间接寻址的容量为 256 个记录块,即 256K 字节。这样,两个部分的总容量为 12K + 256K=268K 字节。可是,更大的文件还是容纳不下,所以超过此容量的部分要进一步采用双重(二层)间接在址。此时 inode 结构里 i_data[] 数组中的第 14 个元素指向另一个记录块,该记录块的内容也是个数组,但是每个元素都指向另一个记录块中的数组, 那才是文件内块号至设备上块号的映射表。这么一来,双重间接寻址部分的能力为 256X256=64K 个记录块,即 64M 字节。依此类推,数组 i_data[] 中的第 15 个元素用于三重(三层)间接导址,这一部分的容量可达 256X256X256=16M 个记录块,也就是 16G 字节,所以,对于 32 位结构的系统,当记录块大小为 1K 字节时,文件的最大容量为 16G+64M+256K+12K。如果设备的容量大于这个数值,就得采用更大的记录块大小了。图5.7是一个关于直接和间接映射的示意图。
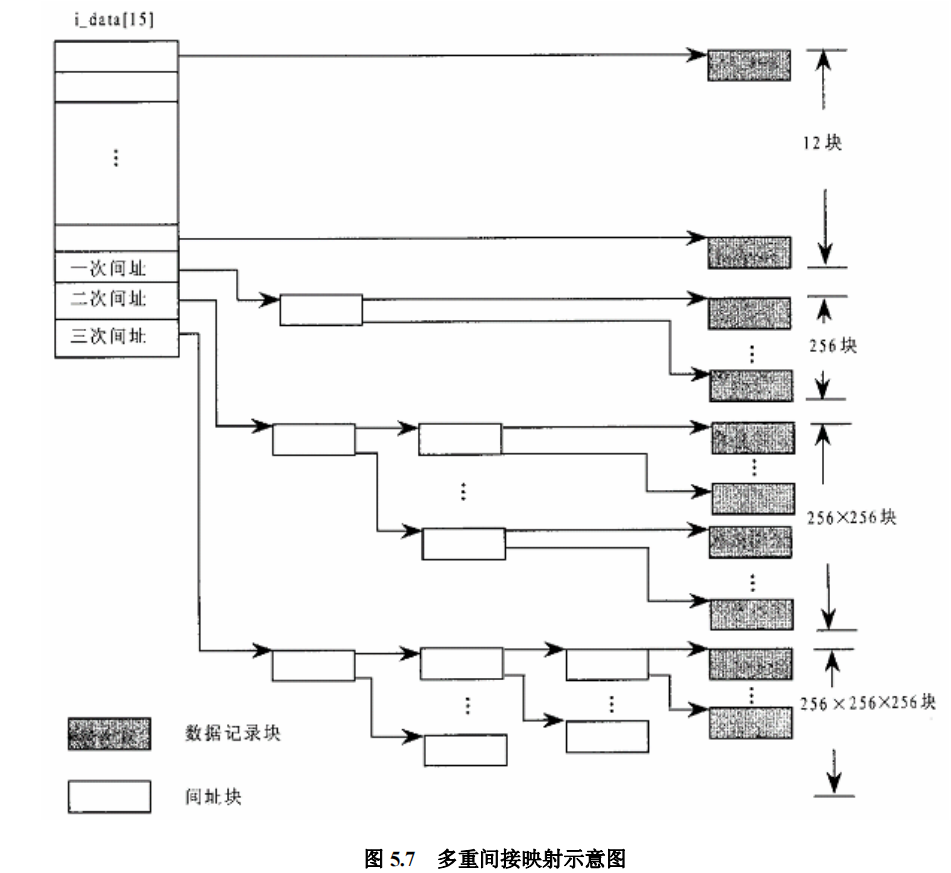
从严格意义上说,i_data[] 其实不能说是一个数组,因为它的元素并不都是同一类型的。但是,从另一个角度说,则这些元素毕竟都是长整数,都代表着设备上个记录块,只是这些记录块的用途不同而已。
这里还要注意,在 inode 结构中有个成分名为 i_data,这是一个 address_space 数据结构。而作为 inode 结构一部分的 ext2_inode_info 结构中,也有个名为 i_data 的数组,实际上就是记录块映射表,二者毫无关系。从概念上说,inode 结构是设备上的索引节点即 ext2_inode 结构的对应物,但实际上 inode 结构中的很多内容并非来自 ext2_inode 结构。相比之下,ext2_inode_info 结构中的信息才是基本上与设备上的索引节点相对应的。例如,与ext2_inode_info 中的数组 i_data[] 相对应,在 ext2_inode 结构中也有个数组 i_block[],两个数组的大小也相同。而 ext2_inode_info 中的数组 i_data[] 之所以不能再大一些, 就是因为索引节点中的数组 i_block[] 只能这么大了。那么内存中的 inode 结构为什么与设备上的索引节点有相当大的不同呢?原因在于设备上索引节点的大小受到更多的限制,所以在索引节点中只能存储必需的信息,而且是相对静态的信息。而内存中的 inode 结构就不同了,它受的限制比较小,除了来自索引节点的必需信息外还可以用来保存一些为方便和提高运行效率所需的信息,还有一些运行时需要的更为动态的信息,如各种指针,以及为实现某些功能所需的信息,如 i_sock, i_pipe, i_wait 和 i_flock 等等。还应提醒读者,设备上的索引节点数量与设备的大小以及文件系统格式的设计有直接的关系, 设备上的每一个文件都有一个索引节点,但是内存中的 inode 结构则主要是缓冲性质的,实际上只有很小一部分文件在内存中建立并保持 inode 结构。
⑴ ext2_block_to_path
// fs/ext2/inode.c
static int ext2_block_to_path(struct inode *inode, long i_block, int offsets[4])
{
int ptrs = EXT2_ADDR_PER_BLOCK(inode->i_sb);
int ptrs_bits = EXT2_ADDR_PER_BLOCK_BITS(inode->i_sb);
const long direct_blocks = EXT2_NDIR_BLOCKS,
indirect_blocks = ptrs,
double_blocks = (1 << (ptrs_bits * 2));
int n = 0;
if (i_block < 0) {
ext2_warning (inode->i_sb, "ext2_block_to_path", "block < 0");
} else if (i_block < direct_blocks) {
offsets[n++] = i_block;
} else if ( (i_block -= direct_blocks) < indirect_blocks) {
offsets[n++] = EXT2_IND_BLOCK;
offsets[n++] = i_block;
} else if ((i_block -= indirect_blocks) < double_blocks) {
offsets[n++] = EXT2_DIND_BLOCK;
offsets[n++] = i_block >> ptrs_bits;
offsets[n++] = i_block & (ptrs - 1);
} else if (((i_block -= double_blocks) >> (ptrs_bits * 2)) < ptrs) {
offsets[n++] = EXT2_TIND_BLOCK;
offsets[n++] = i_block >> (ptrs_bits * 2);
offsets[n++] = (i_block >> ptrs_bits) & (ptrs - 1);
offsets[n++] = i_block & (ptrs - 1);
} else {
ext2_warning (inode->i_sb, "ext2_block_to_path", "block > big");
}
return n;
}
在记录块大小为 1K 字节时,代码中的局部量 ptrs 赋值为 256,从向 indirect_blocks 也是 256。与 ptrs 相对应的 ptrs_bits 则为 8,因为 256 是由 1左移 8 位而成的。同样地, 二次间接的容量 double_blocks 就是由 1 左移 16 位,即 64K 。而二次间接的容量为由 1 左移 24 位,即 16M。
除映射 “深度” 外,还要算出在每一层映射中使用的位移量,即数组中的下标,并将计算的结果放在一个数组 offset[] 中备用。例如,文件内块号 10 不需要间接映射,一步就能到位,所以返回值为 1, 并于 offsets[0] 中返回在第一个数组,即 i_data[] 中的位移 10。可是,假若文件内块号为 20,则返回值为 2,而 offset[0] 为 12, offset[1] 为 8。这样,就在数组 offset[] 中为各层映射提供了一条路线。数组的大小是 4,因为最多就是二重间接。参数 offset 实际上是一个指针,在C语言里数组名与指针是等价的。
如果 ext2_block_to_path() 的返回值为 0 表示出了错,因为文件内块号与设备上块号之间至少也得映射一次。出错的原因可能是文件内块号太大或为负值,或是下面要讲到的冲突。否则,就进一步从磁盘上逐层读入用于间接映射的记录块,这是由 ext2_get_branch() 完成的。
⑵ ext2_get_branch
// fs/ext2/inode.c
/**
* ext2_get_branch - read the chain of indirect blocks leading to data
* @inode: inode in question
* @depth: depth of the chain (1 - direct pointer, etc.)
* @offsets: offsets of pointers in inode/indirect blocks
* @chain: place to store the result
* @err: here we store the error value
*
* Function fills the array of triples <key, p, bh> and returns %NULL
* if everything went OK or the pointer to the last filled triple
* (incomplete one) otherwise. Upon the return chain[i].key contains
* the number of (i+1)-th block in the chain (as it is stored in memory,
* i.e. little-endian 32-bit), chain[i].p contains the address of that
* number (it points into struct inode for i==0 and into the bh->b_data
* for i>0) and chain[i].bh points to the buffer_head of i-th indirect
* block for i>0 and NULL for i==0. In other words, it holds the block
* numbers of the chain, addresses they were taken from (and where we can
* verify that chain did not change) and buffer_heads hosting these
* numbers.
*
* Function stops when it stumbles upon zero pointer (absent block)
* (pointer to last triple returned, *@err == 0)
* or when it gets an IO error reading an indirect block
* (ditto, *@err == -EIO)
* or when it notices that chain had been changed while it was reading
* (ditto, *@err == -EAGAIN)
* or when it reads all @depth-1 indirect blocks successfully and finds
* the whole chain, all way to the data (returns %NULL, *err == 0).
*/
static inline Indirect *ext2_get_branch(struct inode *inode,
int depth,
int *offsets,
Indirect chain[4],
int *err)
{
kdev_t dev = inode->i_dev;
int size = inode->i_sb->s_blocksize;
Indirect *p = chain;
struct buffer_head *bh;
*err = 0;
/* i_data is not going away, no lock needed */
add_chain (chain, NULL, inode->u.ext2_i.i_data + *offsets);
if (!p->key)
goto no_block;
while (--depth) {
bh = bread(dev, le32_to_cpu(p->key), size);
if (!bh)
goto failure;
/* Reader: pointers */
if (!verify_chain(chain, p))
goto changed;
add_chain(++p, bh, (u32*)bh->b_data + *++offsets);
/* Reader: end */
if (!p->key)
goto no_block;
}
return NULL;
changed:
*err = -EAGAIN;
goto no_block;
failure:
*err = -EIO;
no_block:
return p;
}
从设备上逐层读入用于间接映射的记录块时,每通过 bread() 读入一个记录块以后都要调用 verify_chain() 再检查一下映射链的有效性,实质上是检查各层映射表中有关的内容是否改变了(见代码中的条件 from->key == *from->p)。为什么有可能改变呢?这是因为从设备上读入一个记录块是费时间的操作,当前进程会进入睡眠而系统会调度其他进程运行。这样,就行可能发生冲突了。例如,被调度运行的进程可能会打开这个文件并加以截尾,即把文件原有的内容删除。所以,当因等待读入中间记录块而进入睡眠的进程恢复运行的时候,可能会发现原来有效的映射链已经变成无效了,此时 ext2_get_branch() 返回一个出错代码 -EAGAIN。当然,发生这种情况的概率是很小的,但是一个软件是否 “健壮” 就在于是否考虑到了所有的可能。至于 bread() ,那已是属于设备驱动的范畴,读者可参阅块设备驱动一章中的有关内容。
这样,ext2_get_branch() 深化了 ext2_block_to_path() 所取得的结果,二者合在一起基本完成了从文件内块号到设备上块号的映射。
从 ext2_get_branch() 返回的值有两种可能。首先,如果顺利完成了映射则返回值为 NULL。其次, 如果在某层上发现映射表内的相应表项为 0,则说明这个表项(记录块)原来并不存在,现在因为写操作而需要扩充文件的大小。此时返回指向该层 Indirect 结构的指针,表示映射在此 “断裂” 了。此外, 如果映射的过程中出了错,例如读记录块失败,则通过参数 err 返回一个出错代码。
回到 ext2_get_block() 的代码中。如果顺利完成了映射,就把所得的结果填入作为参数传下来的缓冲区结构 bh_result 中,然后把映射过程中读入的缓冲区(用于间接映射)全都释放,就最后完成了记录块号的映射。
可是,要是 ext2_get_branch() 返回了一个非 0 指针(代码中的局部量 partial ),那就说明映射在某一层上断裂了。根据映射的深度和断裂的位置(层次),这个记录块也许还只是个中间的、用于间接映射的记录块,也许就是最终的目标记录块。总之,在这种情况下,要在设备上为目标记录块以及可能 需要的中间记录块分配空间。
(4)generic_commit_write
为写操作作好了准备以后,从缓冲区(缓冲页面)到设备上的记录块这条路就畅通了。这样才可以从用户空间把待写的内容复制过来。
// // fs/ext2/file.c
ssize_t
generic_file_write(struct file *file,const char *buf,size_t count,loff_t *ppos)
{
// ...
status = mapping->a_ops->prepare_write(file, page, offset, offset+bytes);
if (status)
goto unlock;
kaddr = page_address(page);
status = copy_from_user(kaddr+offset, buf, bytes);
flush_dcache_page(page);
if (status)
goto fail_write;
status = mapping->a_ops->commit_write(file, page, offset, offset+bytes);
// ...
}
如前所述,目标记录块的缓冲区在文件层是作为缓冲页面的部分而存在的,所以这是从用户空 间到缓冲页面的拷贝,具体通过 copy_from_user() 完成。这里 buf 指向用户空间的缓冲区,而(kaddr + offset)为缓冲页面中的起始地址,bytes 则为该页面中待拷贝的长度,这些都是在 while 循环的开头计算好了的。对于 i386 结构的处理器,flush_dcache_page() 是空操作。
写入缓冲页面以后,还要把这些缓冲页面提交给内核线程 kflushd,这样写操作才算完成。至于 kflushd 是否来得及马上将这些记录块写回设备上,那是另一回事了。这个将缓冲页面提交给 kflushd 的操作也是因文件系统而异的,由具体文件系统通过其 address_space_operations 结构中的函数指针 commit_write 提供,对于 Ext2 文件系统,这个函数是 generic_commit_write() ,其代码在 fs/buffer.c 中。
// fs/buffer.c
int generic_commit_write(struct file *file, struct page *page,
unsigned from, unsigned to)
{
struct inode *inode = page->mapping->host;
loff_t pos = ((loff_t)page->index << PAGE_CACHE_SHIFT) + to;
__block_commit_write(inode,page,from,to);
kunmap(page);
if (pos > inode->i_size) {
inode->i_size = pos;
mark_inode_dirty(inode);
}
return 0;
}
static int __block_commit_write(struct inode *inode, struct page *page,
unsigned from, unsigned to)
{
unsigned block_start, block_end;
int partial = 0, need_balance_dirty = 0;
unsigned blocksize;
struct buffer_head *bh, *head;
blocksize = inode->i_sb->s_blocksize;
for(bh = head = page->buffers, block_start = 0;
bh != head || !block_start;
block_start=block_end, bh = bh->b_this_page) {
block_end = block_start + blocksize;
if (block_end <= from || block_start >= to) {
if (!buffer_uptodate(bh))
partial = 1;
} else {
set_bit(BH_Uptodate, &bh->b_state);
if (!atomic_set_buffer_dirty(bh)) {
__mark_dirty(bh);
buffer_insert_inode_queue(bh, inode);
need_balance_dirty = 1;
}
}
}
if (need_balance_dirty)
balance_dirty(bh->b_dev);
/*
* is this a partial write that happened to make all buffers
* uptodate then we can optimize away a bogus readpage() for
* the next read(). Here we 'discover' wether the page went
* uptodate as a result of this (potentially partial) write.
*/
if (!partial)
SetPageUptodate(page);
return 0;
}
总结对一个缓冲页面的写文件操作,大致可以分为三个阶段。第一是准备阶段,第二是缓冲页面的写入阶段,最后是提交阶段。完成了对所涉及的所有页面的循环,整个写文件操作的主体 generic_file_write() 就告结束,并且 sys_write() 也随着结束了。
(5)导图
6.4 信号

To be continued
⇐ ⇒ ⇔ ⇆ ⇒ ⟺
①②③④⑤⑥⑦⑧⑨⑩⑪⑫⑬⑭⑮⑯⑰⑱⑲⑳㉑㉒㉓㉔㉕㉖㉗㉘㉙㉚㉛㉜㉝㉞㉟㊱㊲㊳㊴㊵㊶㊷㊸㊹㊺㊻㊼㊽㊾㊿
⑴⑵⑶⑷⑸⑹⑺⑻⑼⑽⑿⒀⒁⒂⒃⒄⒅⒆⒇
➊➋➌➍➎➏➐➑➒➓⓫⓬⓭⓮⓯⓰⓱⓲⓳⓴
⒜⒝⒞⒟⒠⒡⒢⒣⒤⒥⒦⒧⒨⒩⒪⒫⒬⒭⒮⒯⒰⒱⒲⒳⒴⒵
ⓐⓑⓒⓓⓔⓕⓖⓗⓘⓙⓚⓛⓜⓝⓞⓟⓠⓡⓢⓣⓤⓥⓦⓧⓨⓩ
ⒶⒷⒸⒹⒺⒻⒼⒽⒾⒿⓀⓁⓂⓃⓄⓅⓆⓇⓈⓉⓊⓋⓌⓍⓎⓏ
🅐🅑🅒🅓🅔🅕🅖🅗🅘🅙🅚🅛🅜🅝🅞🅟🅠🅡🅢🅣🅤🅥🅦🅧🅨🅩
123
y = x 2 + z 3 y = x^2 + z_3 y=x2+z3
y = x 2 + z 3 + a b + b a y = x^2 + z_3 + \frac {a}{b} + \sqrt[a]{b} y=x2+z3+ba+ab
y = x 2 + z 3 (1) y = x^2 + z^3 \tag{1} y=x2+z3(1)














 388
388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









