







NPM —— 原理推演
《工欲善其事,必先利其器》
既然点进来了,那么就坚持看下去,希望你有不一样的收获~

(图片取自百度)
大家好,我是 vk。最近偶然察觉,发现自己对日常使用的工具竟然认知模糊??NPM 是怎么做到的呢?它又为什么能够管理依赖包?到底有什么特点让开发不得不使用它呢?
为了揭开它的神秘面纱,摆脱目前这种一知半解的状态,我决定!冲它!!!

一、npm 是怎么实现的?
为此,花了一点时间画了一张流程图,大家先看个大概,剩下的且听小弟娓娓道来~
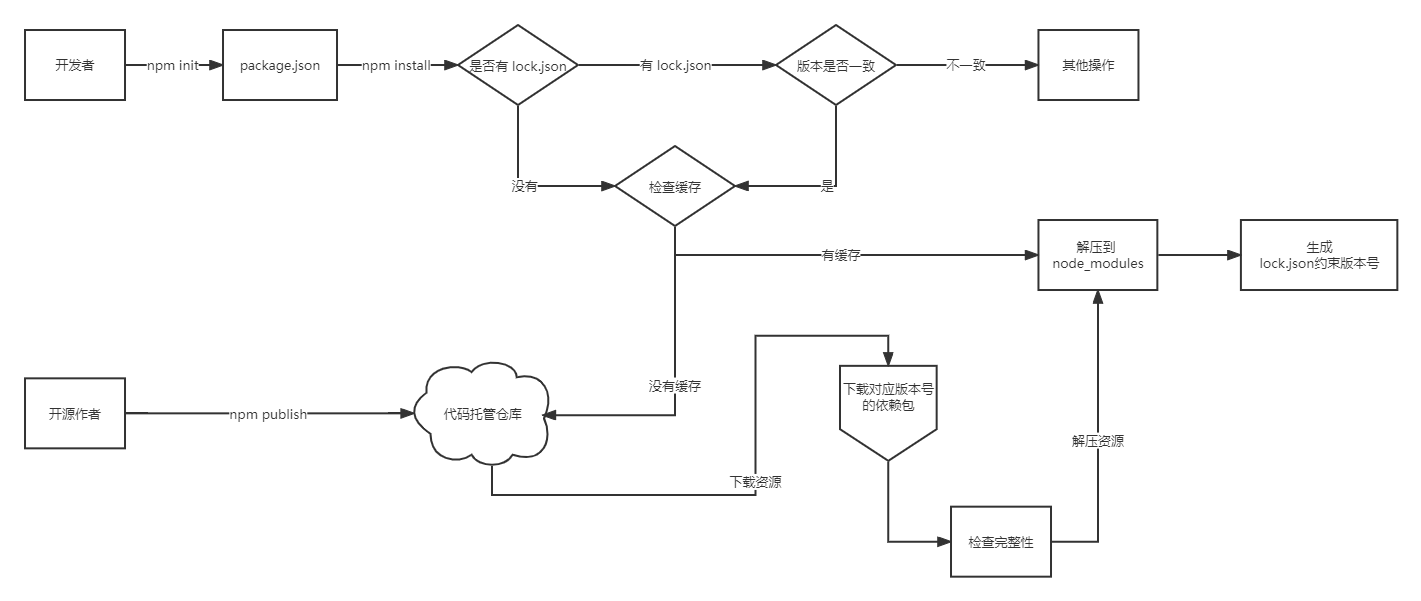
npm全称 node package manager,译为 node 包管理工具;- 需要有一台服务器,实现代码托管的功能,承载各种开源库的代码;
- 分为两个开发方向:一个是作为开源库作者的方向,另外一个是作为开发人员使用的方向;
- 开源库作者使用
npm publish命令将代码提交到平台上供他人使用; - 开发人员使用者使用
npm install命令下载开源库代码进行开发使用。
二、npm init -y 做了什么?
这条命令相信大家基本上都耳熟能详了,它的作用就是生成 package.json 配置文件。-y 代表 yes。意味着生成默认模板的配置文件,省去了多次敲回车确认的步骤。
这个配置文件它里面记录着有,项目的基本配置信息,还有各个依赖包的包名和版本号。除此之外还有一些非常用配置也记录在内,所以我个人觉得有必要了解一下 package.json 中各个配置项的含义以及使用方法:
| 字段名称 | 字段含义 |
|---|---|
| name | 项目/模块的名称。长度必须小于等于214个字符,不能以点或下划线开头,不能包含大写字母 |
| version | 项目版本号 |
| author | 项目开发者。它的值是你在 npmjs.org 网站的有效账户名 |
| description | 项目描述。是一个字符串,便于 npm search 时找到这个包 |
| keywords | 项目关键字。是一个字符串数组,便于 npm search 时找到这个包 |
| privite | 是否私有。设置为 true 时,拒绝发布 |
| license | 软件授权条款。让用户知道他们的使用权力和限制,例如 MIT 条款属于是 “麻省理工条例”,只维护版权,其他无限制 |
| bugs | bug 的提交地址 |
| contributors | 项目贡献者 |
| repository | 项目仓库地址。可以是 Git 或者 SVN |
| homepage | 项目包的官网 URL |
| dependencies | 生产环境下,项目运行所需的依赖包 |
| devDependencies | 开发环境下,项目所需的依赖包 |
| scripts | 执行 npm 的脚本命令 |
| bin | 内部命令对应的可执行文件路径。这个后面会讲到 |
| main | 项目默认的执行文件。默认加载项目根目录下的 index.js 文件 |
| module | 以模块化方式加载。早期没有模块化方案时,遵循 cjs 规范。而 cjs 规范的包以 main 字段设置入口文件,因此就新增该字段以供区分。因此项目启动时优先检查是否有该字段,没有则检查使用 main 字段。 |
| eslintConfig | ESLint 检查文件配置,自动读取验证 |
| engines | 项目运行的平台/环境 |
| browserlist | 供浏览器使用的版本列表 |
| style | 供浏览器使用时,样式文件所在的位置 |
| files | 打包是被项目包含的文件名数组 |
除此之外,还有其他诸如 typings、exports、sideEffects、gitHooks 和 lint-staged 等配置字段,基本上都是看项目的需求,有使用到的东西就需要配置。—— 《详见官方文档》
想要提一嘴的是,大家一定要尊重各大开源库的 知识产权,
license字段不是虚设的,进行二次商用或者发布时,一定要查看源代码的授权许可条款,在其允许的范围内做事,一起建设美好的国内编程环境。各种授权许可条例细则可以戳这里看 —— 《权威认证说明》。
三、npm install 都做了哪些工作?
在我们上面的流程图中概括了用户执行 npm install 命令行之后其工作流程,不过实际上其实没那么简单,详细的执行步骤还得看下面这张图:
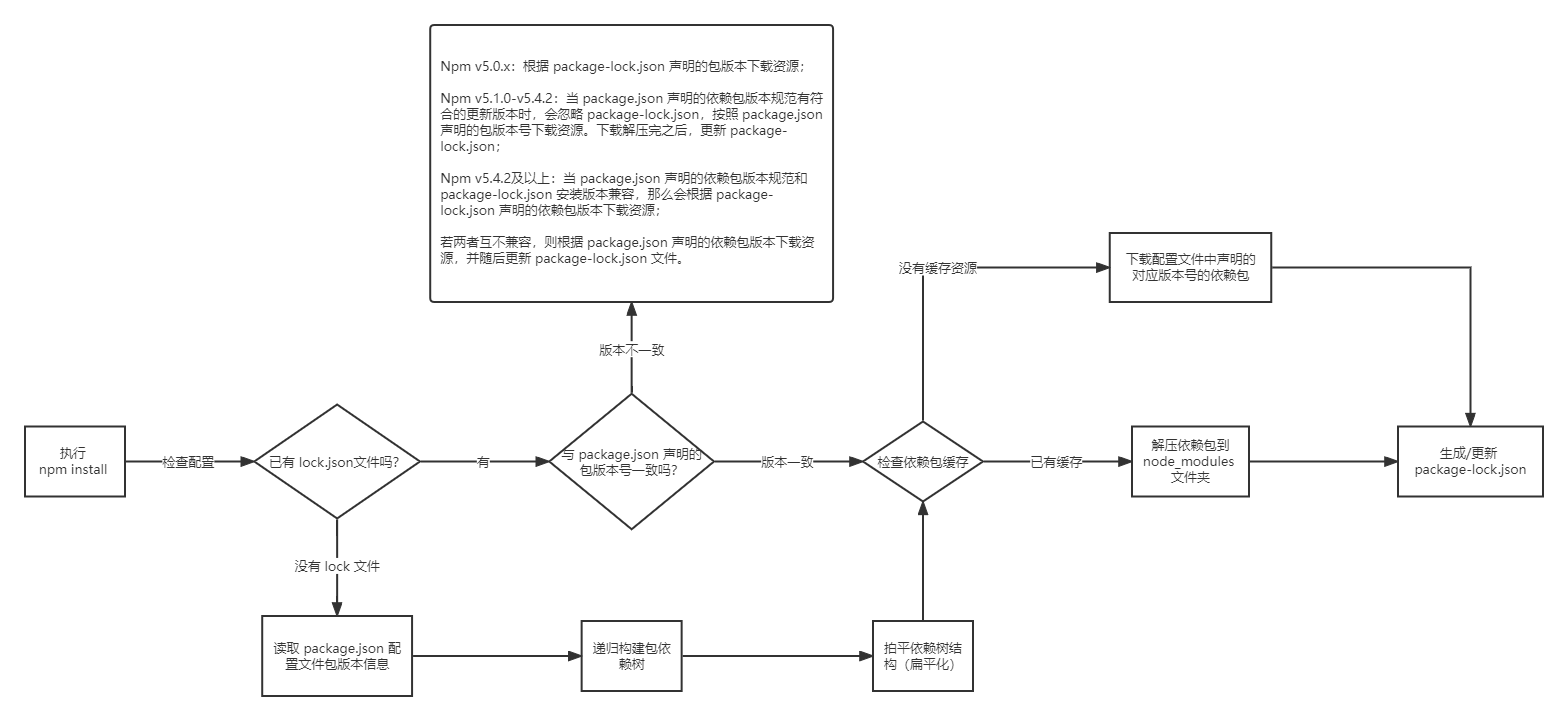
npm install会下载依赖包,生成node_modules文件夹,可以简写为npm i;npm首先会检索配置,此处分为3个步骤:-
- 检索
.npmrc配置文件,根据检索到的配置继续去执行命令。该文件的内容一般是设置镜像源、缓存路径以及前置路径。如下图;该文件的检索优先级如下:项目级 > 用户级 > 全局级 > npm 内置。
- 检索
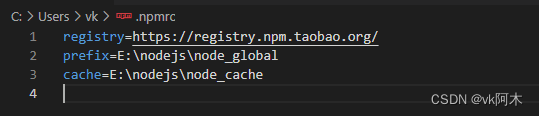
-
- 检索项目中是否有
package.json配置文件。如果没有则报 Error ,提示开发者未初始化项目;
- 检索项目中是否有
-
- 若有
package.json配置文件,继续检索是否有package-lock.json配置文件,根据上面流程图的判断步骤执行(不想写第二遍~)。
- 若有
- 根据检索得出的结果,决定根据哪一个配置文件中声明的依赖包信息去处理资源;
- 有统一的依赖包信息之后,开始处理资源。处理资源时需要检查依赖包的缓存,来判断是否需要下载依赖包资源;
- 处理完依赖包资源之后,生成或更新
package-lock.json配置文件。
注意,由于
npm版本不同,有些配置文件的选择标准有可能也不同,因此团队开发过程中需要统一npm的版本(不管使用哪种包管理工具都要这么做),避免出现各种玄学的错误。
四、package-lock.json 的作用
相信在刚接触模块化开发的时候,很多人一上来就把 package-lock.json 给删了,我也不例外。我记得那时候那时候还被组长说了一顿(捂脸)。

实际上,在版本 v5 之前, npm 是没有 lockfile 的概念的。当你执行 npm install 的时候,npm 会先从 package.json 配置文件中读取你声明的所有依赖包信息。然后根据读取到的信息与 node_modules 文件夹里面的模块进行对比,没有的就直接下载解压,已有的检查版本号进行更新。
这会造成什么后果呢?
- 每次执行安装都非常的慢!
- 只锁定依赖包的大版本号(版本号第一位),版本号不明确!导致安装版本不一致!
- 依赖包的子依赖信息不会被记录!
在
v3版本时,yarn诞生了。它拥有lockfile的机制,并且优化了依赖包的管理方式(扁平化)和网络性能(类似于并发池),更是新增了缓存机制,实现了离线模式!可谓是处处碾压npm!
后来,npm 在 v5 之后,也开始支持 lockfile 机制。它的作用就是对整个依赖树进行版本固定的(锁死版本号)。
随之优化的特性有哪些呢?有如下几点:
- 速度。由于固定版本号的信息,下载依赖包不需要再去做比较,一定程度上优化了安装速度;
- 唯一。依赖树锁定,版本号明确!即使在不同环境下依旧可以安装原来的依赖包,不会导致版本错乱;
- 扁平。依赖包和它的子依赖包信息会被拍平记录!
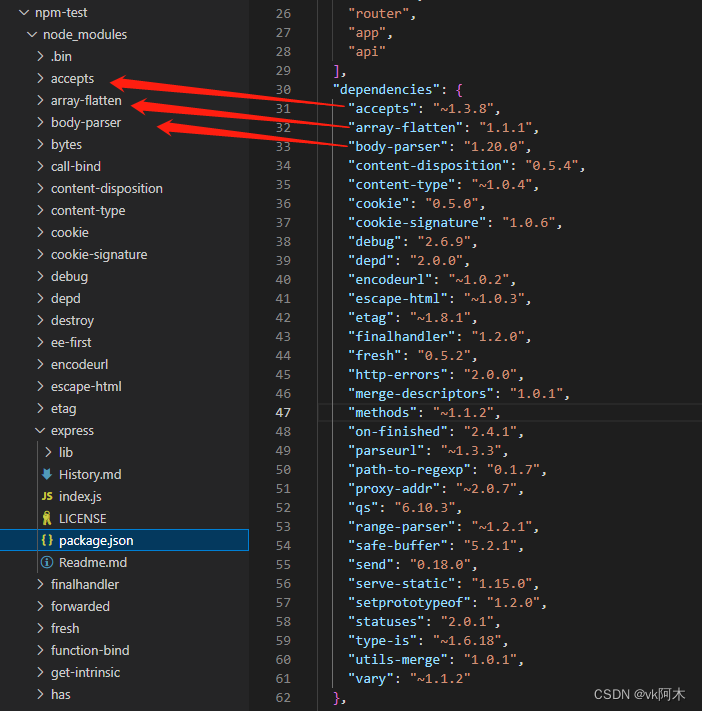
如上图:我只安装了一个 express 依赖,但是它的 package.json 里面的 dependencies ,也就是子依赖,都全部被拍平到 express 的同级目录下,其他依赖以此类推。
五、dependencies 和 devDependencies 有什么区别?
dependencies:里面的内容是生产环境所需的依赖信息,通过npm install -S命令产生;devDependencies:里面是开发环境所需的依赖信息,通过npm install -D命令产生。
1、在
SPA项目中并没有实质性上的区别
我们在使用 vue 或者 react 框架时,往往都是使用 webpack 进行打包的。正是因为这个,webpack 并不会因为你把依赖区分开了,就选择性打包。相反,是全部都会被打包到静态文件之中。
所以你说讨论这个有意义吗?还真有。
它们俩个唯一区别是当项目被作为依赖使用时,可以选择不安装其 devDependencies 的依赖,仅此而已。
另外,现在前端发展的脚步这么快,不排除以后有其他打包构建工具,会对这方面进行优化。个人建议还是按照规范区分安装依赖。
2、在
Nodejs项目中有区别的意义
由于 Nodejs 项目上线是不需要经过打包这个步骤的,部署之后会重新 npm install 一次。上线之后执行下载命令是不会安装 devDependencies 的依赖包的,所以需要区分。
六、npm run xxx 输入到执行都发生了什么?
npm 运行 scripts 脚本时,会自动给脚本路径都加上 node_modules/.bin 的前缀。这也就意味着:你实际上是运行 node_modules/.bin 文件夹下的可执行文件。
不对呀?我们前面学习的过程中可没有提到这些文件的生成呀,那它到底是怎么来的呢?
其实 npm 在执行 install 命令时,会根据第三方依赖包的 package.json 里面的 bin 配置项,在项目根目录的 node_modules 的 .bin 文件夹内创建好它的可执行文件(其实是软链接)。
这里面的可执行文件实际上指向自己依赖包里面的 bin 文件夹下的启动文件,例如 webpack-dev-server :
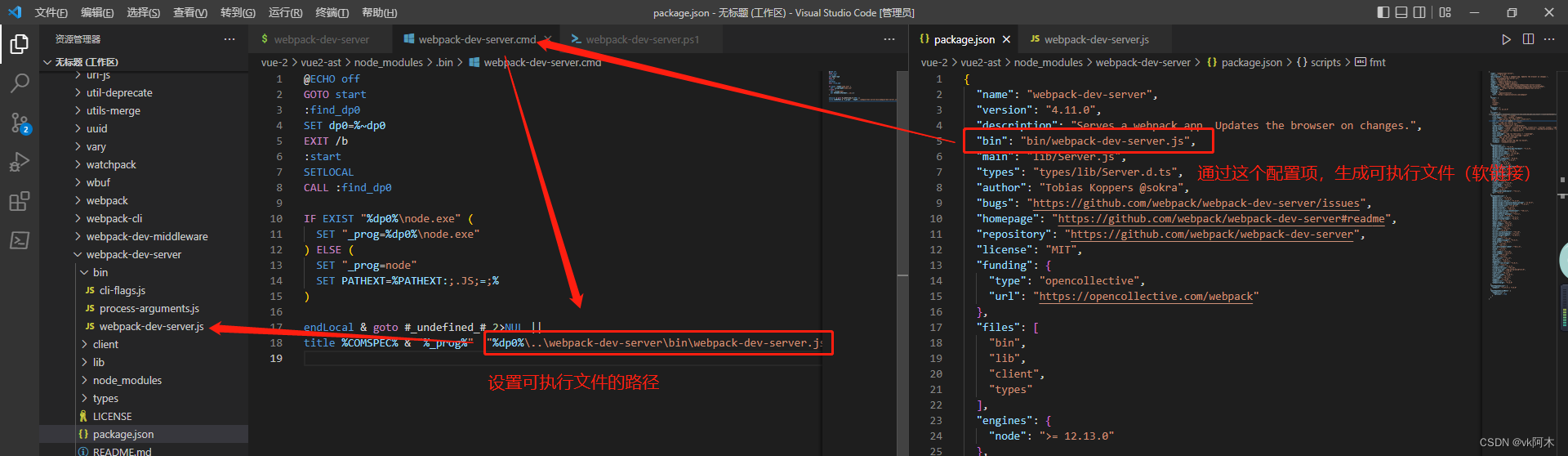
因此,当我们运行 npm run dev(webpack-dev-server) 命令时,实际上会通过软连接去执行依赖包内的 bin 执行文件。执行顺序如下图所示:
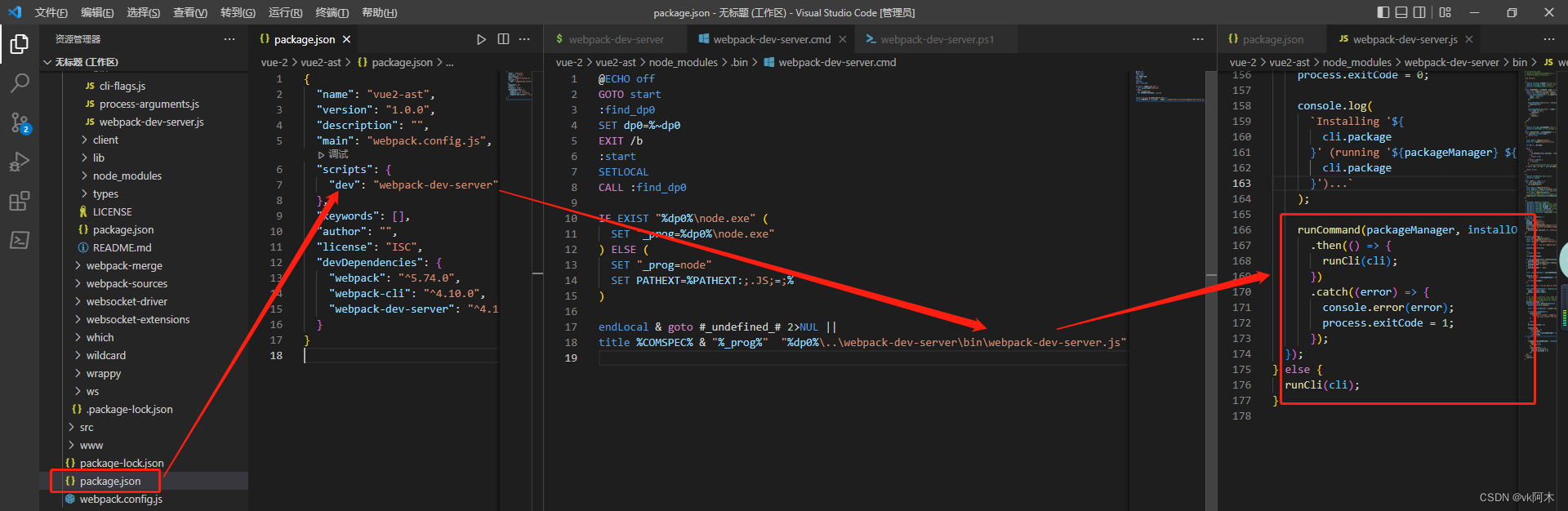
- 执行
npm run dev命令,首先去package.json查找对应的scripts脚本,并自动加上node_modules/.bin前缀; - 利用
node,运行不同环境下的可执行文件,unix环境运行webpack-dev-server脚本;cmd窗口运行webpack-dev-server.cmd文件;powerShell窗口运行webpack-dev-server.ps1文件。这三种可执行文件最后都会运行,依赖包bin目录下的webpack-dev.server.js文件。
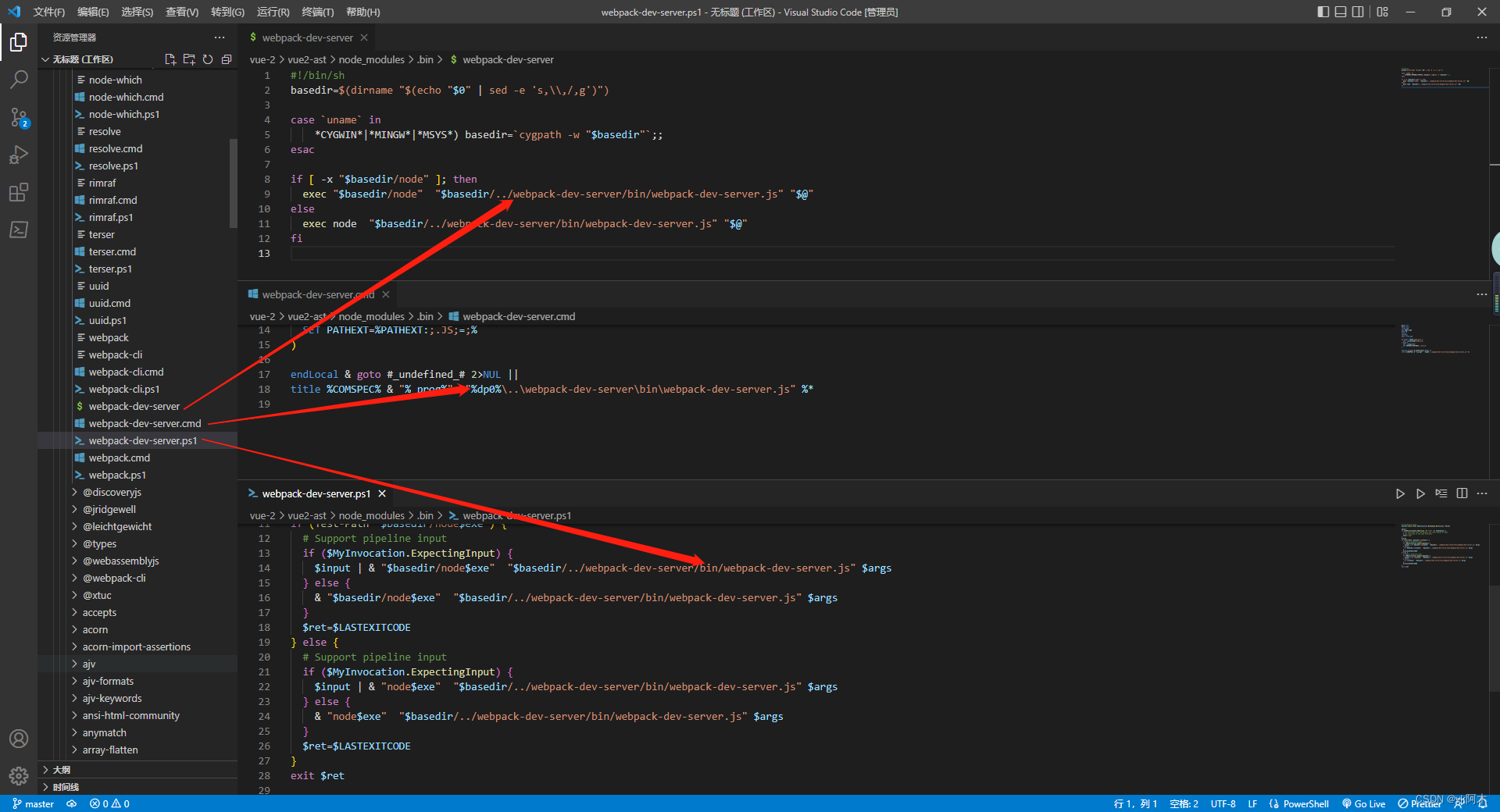
- 最后由依赖包自己执行
runCli函数。
提示: 执行
npm run dev时,若当前目录的node_modules/.bin查找不到可执行文件,则会返回上一级,去全局的node_modules/.bin中查找。如果全局目录还找不到,那么npm就会从系统环境变量path中查找,找得到就会运行,否则报错。
七、npm 的缓存策略是怎样的?
理解就好,不必强记,有兴趣的也可以深入研究。戳这里看解析 —— 《跳转》
八、npm 有什么缺点?
- 幽灵依赖
早在 v3 版本,npm 为解决 node_modules 嵌套地狱的问题,实现了扁平化管理 node_modules 包的结构。所有的子依赖都被提升平铺到主依赖项所在的目录中,这很容易就造成 “意外的被正确引用” 的现象,这种现象称之为 —— 《幽灵依赖》。
幽灵依赖是指,未在 package.json 中声明的依赖,但在项目中依然可以意外的被正确引用,这是极其不符合常规逻辑的。
- 依赖分身
虽然实现了扁平化包管理机制,但如果不同的两个主包同时依赖于相同版本号的子包,那么这个子包将会被重复安装两次,以此类推。这就是依赖分身。
- 不支持
Monorepo
npm 表示未来会支持 Monorepo ,但至少今天为止,我还是不能用 npm 去创建 Monorepo 项目~
九、npm 周边工具有哪些?
nvm:全称 Node Version Manager,是Nodejs版本管理器 ,用来管理node的版本;nrm:全称 Node Registry Manager,是npm的镜像源管理工具,可以使用这个来切换镜像源。- 附安装和使用方法 —— 《戳这里》
参考文章:
到此完结,感谢你的阅读,希望你的未来一片光明~















 2137
2137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









