







基于Python实现的网络爬虫项目——多线程下载小说并保存为txt文件(包含完整代码及注释)
本学期由于课程的需要,对于python的网络爬虫进行了简单的学习,
然后帮助一个朋友写了一个课程作业,实现了一个简单的网络爬虫项目——多线程下载小说并保存为txt文件。
下面我将对该项目的完成进行一个详细的讲解。
一、确立预期目标
实现一个输入小说的名字后自动对该小说对应的资源进行查找,并进行小说所有章节的下载,将下载的小说按章节保存为txt文档。本次爬虫选取的网站为https://www.xbiquge.la/xiaoshuodaquan/(笔趣阁小说网站小说大全页面)
二、完成项目所需工具
环境:python3.8.5
编译器:pycharm2021
爬取网页url:https://www.xbiquge.la/xiaoshuodaquan/
所需的python库:
import requests
from bs4 import BeautifulSoup
import re
import time
import threading
import os
三、项目需要解决的问题
问题一
获取所有小说的资源库,包括拥有的小说的名字和小说所有章节对应的网页
问题二
获取要下载的小说的所有章节资源,包括章节名字和章节内容对应网页
问题三
获取章节内容后对内容中的小说文本进行提取和筛选
问题四
保存章节内容
问题五
多线程同时进行多个章节的获取和保存
问题六
下载完一本小说后可以自主选择程序结束运行或继续进行另一本小说的下载
四、对应问题解决方法
问题一解决方法及思路
本次我们选取的网站为https://www.xbiquge.la/xiaoshuodaquan/
该网站有笔趣阁中所有小说的名称和对应链接,该链接网页如下图所示

查看页面源代码我们发现所有的小说名字和其对应章节都在div id="main"这个分组下,如下图所示:

因此,我们只需要将该页面源码中
我们只要先获取对应的网页所有的html原码,然后对其进行筛选即可
获取html原码的方法我们采用requests函数,想要详细了解resqests函数的同学可以查阅相关材料进行学习,我们这里只需要简单的get方法获取html原码文本即可。
函数代码如下所示(这个函数我们会多次用到,因为我们对网页中内容的筛选和各种操作都是基于在html文本文件下进行的):
def getpage(url):
'''
输入:url种子
功能:获取html原码
返回值:html原码文本
'''
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
page = requests.get(url=url,params=headers)
page.encoding='utf-8'
return page.text
然后我们可以用以下函数提取所有小说的名字和对应链接:
def getnovels(html):
'''
输入:已经获取的html网页原码
功能:获取网站中所有资源的小说名字和对应网址
返回值:小说名称——对应网址键值对字典
'''
soup = BeautifulSoup(html,'lxml')
list = soup.find('div',id='main').find_all('a')
# 字典键值为小说名字,值为:小说对应的网址
namelist = {}
for l in list:
namelist[l.string] =l['href']
return namelist
问题二解决方法及思路
获取了所有小说的所在链接之后,我们便可以输入我们想要下载的小说的名字,然后程序便会在 namelist中检索该小说名字,获取小说所有内容对应的网页链接。这里我们以《万相之王》为例
万象之王的链接为https://www.xbiquge.la/55/55945/,网页内容如下图所示

下面我们分析网页原码,从而来讲对应每个章节内容所在的链接爬取出来,网页源码如下图所示

我们发现所有章节及其链接都存储在分组div id="list"下。用解决问题一的类似方法,我们将该小说的所有章节和对应的链接爬取出分别存储在数组chaptername和chapteraddress中,同时创建一个字典chapternameidx来存储每个章节名字对应的是第几章,键值对对应的是该章节的顺序数和名字(这里是为了方便对下载的所有章节进行排序),而我们采用两个数组的作用是为了我们后续进行多线程操作,这里不再细说,后边会提到,值得注意的是,为了方便我们进行多线程操作,这三个变量都是全局变量。在这里我们只要明白我们的主要目的是为了获取我们想要下载的小说的所有章节名字和其内容对应的链接就可以了,示范函数代码如下:
def getchapter(html):
'''
输入:html网页原码
功能:获取小说所有章节以及地址
返回值:章节名字,和对应网址
'''
soup = BeautifulSoup(html,'lxml')
try:
#章节列表
alist = soup.find('div',id='list').find_all('a')
for list in alist:
#章节名字
name=list.string
chaptername.append(name)
#章节网址
href = 'https://www.xbiquge.la'+list['href']
chapteraddress.append(href)
for i in range(0,len(chaptername)):
chapternameidx[chaptername[i]]=(i+1)
return True
except:
print('未找到章节')
return False
问题三解决方法及思路
得到了所有的章节和对应链接后我们便可以获取章节内容了,我们爬取的章节内容所在的html文本中除了我们需要的章节内容外还有其他无关的东西,我们需要做的就是将文本内容提取出来
我们可以看到html原码中文本内容所在的格式如下图所示
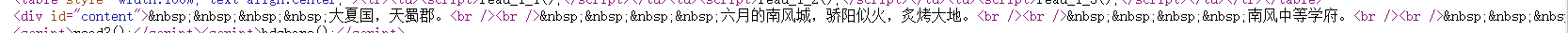
因此我们首先将id='content’中的文本提取出来,这里我们选用正则表达式来进行提取,我们获取的原始文本内容格式如下图所示

我们发现除了我们需要的内容外还存在一些内容之外的符号(主要存在与段落之间),因此我们用正则表达式将这些不需要的内容删除,并替换换行符来进行分段操作来方便我们保存为txt文件后的阅读体验。初步处理结果如下图所示:

这时我们发现文本内容大体上已经满足了我们的预期目标,但是我们发现文章结尾部分的广告内容是小说内容之外的,因此我们需要将符号<p之后的内容全部删除。这样我们就能得到纯净的小说章节文本内容了
该阶段示例函数测试代码如下(这里是一个独立的在写代码时进行测试的主函数,在完整代码中该部分会被简化为一个内部函数):
import re
import requests
if __name__=='__main__':
'''
输入:章节内容所在网页的原码
功能:将源码中的章节内容提取出来
返回值:将内容文本返回
:param html:
:return:
'''
target = 'https://www.xbiquge.la/55/55945/23396080.html'
req = requests.get(url=target)
# 正则只获取正文
p = r'id="content"(.*)'
req.encoding = "utf-8"
try:
content = ''
texts = re.findall(p, req.text)
print(texts)
# text=re.findall('[\u3002\uff1b\uff0c\uff1a\u201c\u201d\uff08\uff09\u3001\uff1f\u300a\u300b\u4e00-\u9fa5]',str(texts))
# content=''.join(text)
# 删除html原码中的 、;、<br />
pattern = r'( )|(;)|(<br />)'
texts2 = re.sub(pattern, '', str(texts))
print(texts2)
pattern2 = r'(\\r\\r)'
texts3 = re.sub(pattern2, (' ' + '\n'), str(texts2))
print(texts3)
pattern3 = r'(\')|(>)'
texts4 = re.sub(pattern3, (''), str(texts3))
print(texts4)
for i in texts4:
if i == '[':
continue
elif i != '<':
content = content + i
else:
break
print(content)
except: print('出错')
问题四解决方法及思路
获取了纯净的文本内容之后,我们将纯净的文本内容保存到txt文档中之后我们便完成了一个章节的下载。这里就采用简单的文件写入就可以了,操作如下:
file = open(path, 'w')
file.write(content)
file.close()
# 保存文件
正常来说只要进行一个章节一个章节的下载我们就可以将一本小说全部下载完成了,但是如果章节过多这样下载的速度就比较慢了,因此,我们可以采用多线程下载的方法来提升下载速度
问题五解决方法及思路
多线程下载,同时进行多个章节的下载,最多同时进行多少个章节的下载取决于我们开启的线程数,这里创建线程我们采取简单的threading.Thread函数,该函数的主要参数(target是线程运行的函数,设置好创建的数量后我们只需要布置好target参数指代的函数,就能保证线程的正常运行,为了控制线程之间不产生冲突,这里便用到了我们在解决问题二时设置的两个全局变量:数组chaptername和chapteraddress。当每个线程在对这两个全局数组进行操作时,选择一个数组中的章节和对应链接后,数组便将被选中的名字和链接弹出,这样当其他线程同时操作该数组的时候便不会出现两个子线程同时进行一个章节的下载。
下面给出子线程创建和线程所操作的函数的代码
子线程创建:
threads = [threading.Thread(target=process(name,int(len(chaptername)))) for i in range(num)]
# 创建number个线程
线程操作函数:
def process(name,Length):
'''
线程运行的函数,相当于run
'''
try:
for i in range (0,len(chaptername)):
name1=str(chaptername[i])
#获取章节名字
url=chapteraddress[i]
#获取章节网址
number = chapternameidx[name1]
#获取位置
chaptername.pop(i)
chapteraddress.pop(i)
# 弹出正在下载的名字和网址
name2=str(number)+name1
# 获取该章节内容并下载
path = name + '\\'+name2+ '.txt'
# 下载路径
print(path)
getdetail(path,name1,url,Length)
#调用函数,下载并获取内容
except:
print('该子线程结束')
问题六解决方法及思路
当我们进行了一本小说的下载之后,如果我们想要再下载一本新的小说怎么办?
当然我们可以关闭程序重新运行来进行下载,但是这样的话我们会再次进行对网站中所有小说及其链接的保存,这样既浪费了运行时间,又导致该部分函数好像用处不大,毕竟这样一本一本的每次重新运行程序,还不如直接对小说所在网页进行爬取,没必要保存全部小说相关信息。因此,为了充分利用我们的字典 namelist,我们可以在一本小说下载完毕后根据我们的意愿来决定我们是否继续下载新的小说。那么,我们要怎么实现呢?我们可以写一个类似main函数的主体函数,每次下载完成一本小说后我们调用主体函数即可。
主体函数代码如下:
def Repetition():
'''
再次运行主体函数,保证可以持续运行本程序
'''
name = input('请输入想要下载小说的名字(不要有错别字哦):\n')
# 输入想要下载的小说的名字
if name in novellist:
print('已经找小说%s' % (name))
url2 = novellist[name]
# 获取该小说对应网址
html2 = getpage(url2)
# 获取对应的html原码
getchapter(html2)
# 获取小说每一个章节的名称和对应网址
print('小说共%d章节' % (int(len(chaptername))))
num = int(input('请输入要开启的线程数:'))
print('start download')
start = time.time()
threads = [threading.Thread(target=process(name, int(len(chaptername)))) for i in range(num)]
# 创建number个线程
# 创建一个专属于小说name的文件夹
try:
os.mkdir(name) # 创建保存验证码的目录
except:
print('文件夹已存在')
# 线程
for i in threads:
i.start()
for t in threads:
t.join()
print('主线程结束')
end = time.time()
print('小说下载结束,本次下载共耗时%fs' % (start - end))
chaptername.clear()
chapteraddress.clear()
chapternameidx.clear()
print(chaptername, chapteraddress, chapternameidx)
jud = int(input('是否要继续下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
else:
print('未找见该小说')
jud = int(input('是否要重新输入小说名字或下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
print('正在准备')
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
五、完整代码及项目总结
首先给出我们的完整代码(包含详细注释)
import requests
from bs4 import BeautifulSoup
import re
import time
import threading
import os
#全局变量,三个个列表分别存储章节名字和内容所在页的网址
chaptername = []
# 存放小说章节名字
chapteraddress = []
#存始章节名字和对应章节数键值对,后续由这个来改变对应的章节号便于排序
chapternameidx={}
def getnovels(html):
'''
输入:已经获取的html网页原码
功能:获取网站中所有资源的小说名字和对应网址
返回值:小说名称——对应网址键值对字典
'''
soup = BeautifulSoup(html,'lxml')
list = soup.find('div',id='main').find_all('a')
# 字典键值为小说名字,值为:小说对应的网址
namelist = {}
for l in list:
namelist[l.string] =l['href']
return namelist
def getpage(url):
'''
输入:url种子
功能:获取html原码
返回值:html原码文本
'''
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44'
}
page = requests.get(url=url,params=headers)
page.encoding='utf-8'
return page.text
def getchapter(html):
'''
输入:html网页原码
功能:获取小说所有章节以及地址
返回值:章节名字,和对应网址
'''
soup = BeautifulSoup(html,'lxml')
try:
#章节列表
alist = soup.find('div',id='list').find_all('a')
for list in alist:
#章节名字
name=list.string
chaptername.append(name)
#章节网址
href = 'https://www.xbiquge.la'+list['href']
chapteraddress.append(href)
for i in range(0,len(chaptername)):
chapternameidx[chaptername[i]]=(i+1)
return True
except:
print('未找到章节')
return False
#获取章节内容
def getdetail(path,name,url,length):
'''
输入:章节内容所在网页的原码
功能:将源码中的章节内容提取出来并保存
返回值:报错
'''
target = url
req = requests.get(url=target)
p = r'id="content"(.*)'
# 正则只获取正文
req.encoding = "utf-8"
try:
content=''
#content存储提取删选过滤完毕的正文内容
texts = re.findall(p, req.text)
pattern=r'( )|(;)|(<br />)'
# pattern 删除html原码中的 、;、<br />
texts2=re.sub(pattern,'',str(texts))
pattern2 = r'(\\r\\r)'
# pattern2 将\r\r替换为换行
texts3 = re.sub(pattern2, (' ' + '\n'), str(texts2))
pattern3 = r'(\')|(>)'
#pattern3删除符号'和>
texts4 = re.sub(pattern3, (''), str(texts3))
#print(texts4)
#输出初步过滤的正文
for i in texts4:
if i == '[':
continue
elif i != '<':
#删除<号之后的无关内容
content = content + i
else:
break
if content != ']' and content !=' ':
file = open(path, 'w')
file.write(content)
file.close()
# 保存文件
else:
#当content内容为空时,重新运行函数,直到下载下来为止
getdetail(path, name, url,length)
return True
except:
print('出错')
return False
def process(name,Length):
'''
线程运行的函数,相当于run
'''
try:
for i in range (0,len(chaptername)):
name1=str(chaptername[i])
#获取章节名字
url=chapteraddress[i]
#获取章节网址
number = chapternameidx[name1]
#获取位置
chaptername.pop(i)
chapteraddress.pop(i)
# 弹出正在下载的名字和网址
name2=str(number)+name1
# 获取该章节内容并下载
path = name + '\\'+name2+ '.txt'
# 下载路径
print(path)
getdetail(path,name1,url,Length)
#调用函数,下载并获取内容
except:
print('该子线程结束')
def Repetition():
'''
再次运行主体函数,保证可以持续运行本程序
'''
name = input('请输入想要下载小说的名字(不要有错别字哦):\n')
# 输入想要下载的小说的名字
if name in novellist:
print('已经找小说%s' % (name))
url2 = novellist[name]
# 获取该小说对应网址
html2 = getpage(url2)
# 获取对应的html原码
getchapter(html2)
# 获取小说每一个章节的名称和对应网址
print('小说共%d章节' % (int(len(chaptername))))
num = int(input('请输入要开启的线程数:'))
print('start download')
start = time.time()
threads = [threading.Thread(target=process(name, int(len(chaptername)))) for i in range(num)]
# 创建number个线程
# 创建一个专属于小说name的文件夹
try:
os.mkdir(name) # 创建保存验证码的目录
except:
print('文件夹已存在')
# 线程
for i in threads:
i.start()
for t in threads:
t.join()
print('主线程结束')
end = time.time()
print('小说下载结束,本次下载共耗时%fs' % (start - end))
chaptername.clear()
chapteraddress.clear()
chapternameidx.clear()
print(chaptername, chapteraddress, chapternameidx)
jud = int(input('是否要继续下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
else:
print('未找见该小说')
jud = int(input('是否要重新输入小说名字或下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
print('正在准备')
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
if __name__=='__main__':
url = 'https://www.xbiquge.la/xiaoshuodaquan/'
# 小说大全网址
html = getpage(url)
novellist=getnovels(html)
# 获取所有小说的名单 以及信息,存储在字典novellist中,
name = input('请输入想要下载小说的名字(不要有错别字哦):\n')
# 输入想要下载的小说的名字
if name in novellist:
print('已经找小说%s'%(name))
url2=novellist[name]
# 获取该小说对应网址
html2=getpage(url2)
# 获取对应的html原码
getchapter(html2)
# 获取小说每一个章节的名称和对应网址
print('小说共%d章节' % (int(len(chaptername))))
num=int(input('请输入要开启的线程数:'))
print('start download')
start=time.time()
threads = [threading.Thread(target=process(name,int(len(chaptername)))) for i in range(num)]
# 创建number个线程
#创建一个专属于小说name的文件夹
try:
os.mkdir(name) # 创建保存验证码的目录
except:
print('文件夹已存在')
#线程
for i in threads:
i.start()
for t in threads:
t.join()
print('主线程结束')
end=time.time()
print('小说下载结束,本次下载共耗时%fs'%(start-end))
chaptername.clear()
chapteraddress.clear()
chapternameidx.clear()
print(chaptername,chapteraddress,chapternameidx)
jud=int(input('是否要继续下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
else:
print('未找见该小说')
jud = int(input('是否要重新输入小说名字或下载新的小说?是请输入1,否请输入2'))
if jud == int(1):
print('正在准备')
Repetition()
elif jud == int(2):
print('本次小说下载到此为止,感谢您的使用')
else:
print('出错,本次下载结束')
代码运行后小说保存在代码所在路径下,结果如图所示:


上面便是本次项目的全部内容及代码
接下来对于本次完成该项目进行一个简单的总结和回顾:
1、这是自己第一次写这么长的博客,因此文章中如果有不合规范的语法或者错误欢迎大家指正
2、自己对与爬虫的学习不是很多,本文只是自己对于所学知识的一个简单运用,代码中也有许多需要优化的地方,欢迎大家一起交流讨论
3、本文中代码在下载某些小说的某些章节过程中,可能会出现部分章节下载失败的现象,下载过程中会反馈出错。但不会影响整体代码的运行。当前只在下载《深空彼岸》时出现过这样的错误,下载万相之王的过程中没有出现。
错误反馈如下图所示:

我暂时还没有找到该问题的原因(可能是由于在文章内容提取过程中是按照万相的html原码分析的,而深空中部分地方和它有细微差别)。如果大家找到了问题所在还请能够告知交流一下,万分感谢。
好了,这篇博客的分享到这里就结束了,谢谢您的阅读!欢迎大家来交流指正!















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









