







**Spark 中Accumulators 和 Broadcast Variables的使用**
一:Accumulators
重点说一下Accumulators 的使用,首先先描述下的经历过程,我遇到这样一个问题,需要获取RDD中某个字段的值,放入HashSet中,为后续操作做准备。但是会发现在RDD的foreach中直接把这个字段的值放入HashSet中,并且,我在foreach做了println操作,然后结果并不是我想要的,HashSet的值是空的,也没有进行看到任何println,显然Spark不支持这么做,如果对RDD执行foreach,只会在Executor端有效,并不是Driver端,因此Driver端是看不到任何输出的。(在RDD的map中可以这么做)
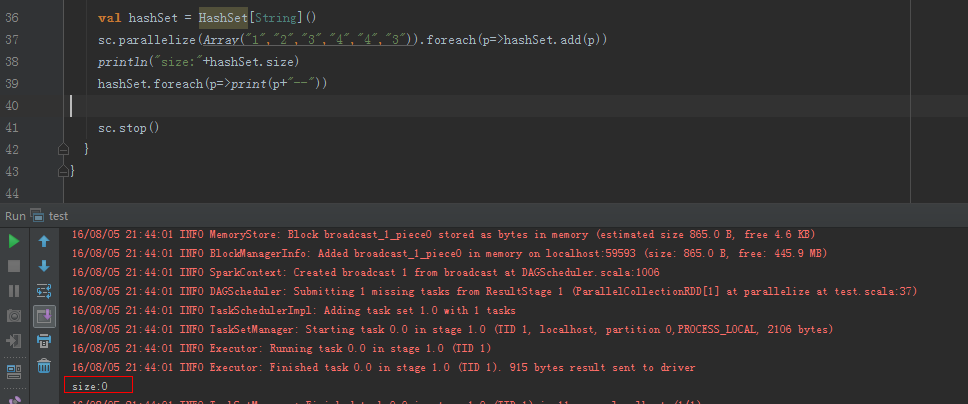
图:foreach遍历,hashSet的大小为0
于是尝试了其他的办法,比如放入一个可序列化的对象中,依然得不到想要的结果,又想到了使用广播变量,但是广播变量是不可变的。最终在Spark官网上看到了Accumulators ,并且Accumulators 是可以改变的,于是经过一番折腾,直接上代码,看结果,一切都在代码中。
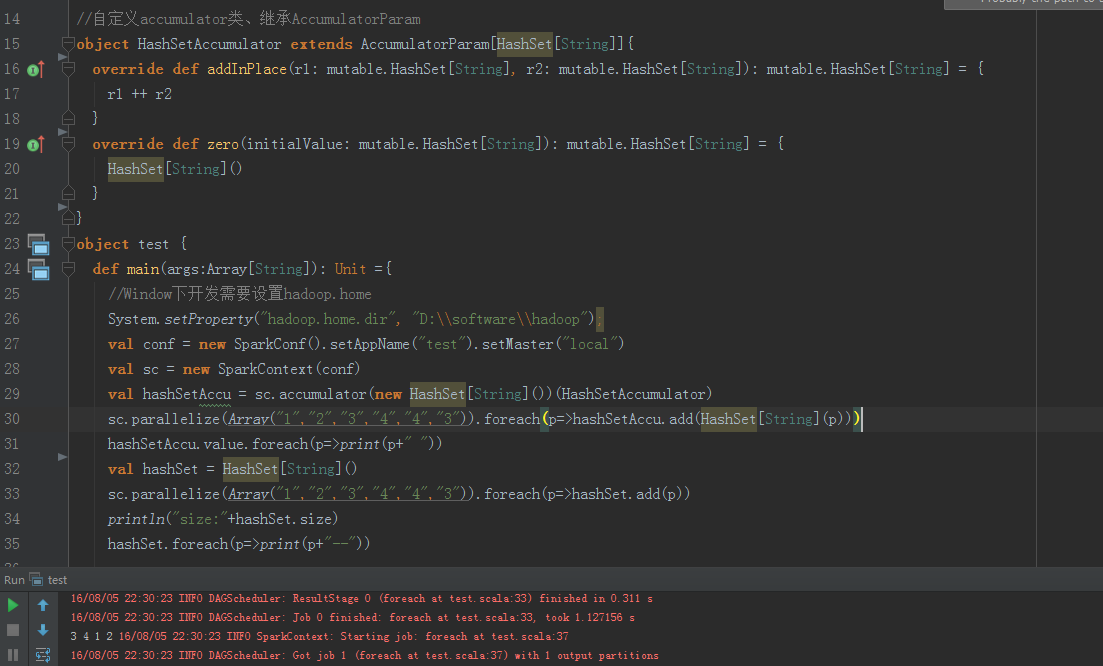
图:使用Accumulators 后,hashSet是有值的
二:Broadcast Variables
SPARK-5063 in spark,Spark does not support nested RDDs or performing Spark actions inside of transformations; this usually leads to NullPointerExceptions (seeSPARK-718 as one example). The confusing NPE is one of the most common sources of Spark questions on StackOverflow:
上文意思是Spark不支持嵌套RDD,那么可以用广播变量解决这个问题,把其中一个RDD进行广播,广播变量可以进行共享,但是不可以进行修改。下边给出两个例子:
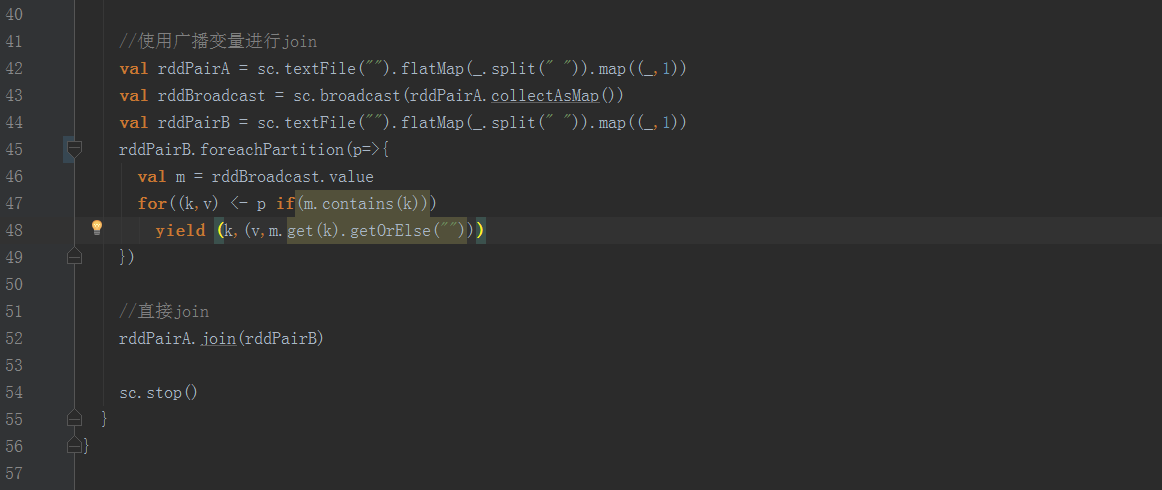

显然使用广播变量进行操作,会提高效率,因为广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。
参考资料:
Spark官方文档:http://spark.apache.org/docs/latest/programming-guide.html















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









