






当前PaddleDetection版本: release/2.4
以下采用PP-YOLOE为例
-
数据准备
-
将图片和标注文件保存至如下文件格式
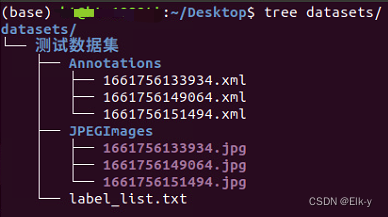
-
使用脚本切分训练集
pip install matplotlib python3 make_voc.py --dataset datasets/测试数据集import argparse import random import re from pathlib import Path from matplotlib import pyplot as plt annotations_name = 'Annotations' jpegimages_name = 'JPEGImages' trainval_name = 'trainval.txt' text_file_name = 'test.txt' val_file_name = 'val.txt' def write_file(datas, file): results = [] for data in datas: annotation = Path(annotations_name, f'{data}.xml') image = Path(jpegimages_name, f'{data}.jpg') result = f'{image} {annotation}' results.append(result) with file.open('w')as f: f.write("\n".join(results)) print(file, "success") def make_paddle_voc(dataset): dataset = Path(dataset) assert dataset.is_dir(), "Error dataset path" annotations_path = dataset / annotations_name images_path = dataset / jpegimages_name if not (annotations_path.is_dir() and images_path.is_dir()): print("Please use the following structure:") print(f"{dataset.name}") print(f'\t{annotations_name}\n\t\t|--00001.xml\n\t\t|--00002.xml') print(f'\t{jpegimages_name}\n\t\t|--00001.jpg\n\t\t|--00002.jpg') raise RuntimeError(f'Error {jpegimages_name} or {annotations_name} dir') paddle_path = dataset / 'paddle' paddle_path.mkdir(exist_ok=True, parents=True) trainval_path = paddle_path / trainval_name test_path = paddle_path / text_file_name val_path = paddle_path / val_file_name annotations = annotations_path.glob('*.xml') images = images_path.glob('*.jpg') images_list = [image.name for image in images] annotations_list = [] for annotation in annotations: image = annotation.with_suffix('.jpg').name assert image in images_list, f"{annotation.name} has no image file" annotations_list.append(annotation.stem) random.shuffle(annotations_list) per = round(len(annotations_list)/10) trainval = annotations_list[:per*7] # 此处切分比例为8:1:1 可行修改比例 test = annotations_list[per*7:per*9] val = annotations_list[per*9:] write_file(trainval, trainval_path) write_file(test, test_path) write_file(val, val_path) def check_labels(dataset): dataset = Path(dataset) annotations_path = dataset / annotations_name class_list = {} for annotation_path in annotations_path.glob('*.xml'): with annotation_path.open('r')as f: names = re.findall(r'<name>(.+?)</name>', f.read()) for name in names: if name not in class_list.keys(): class_list[name] = 0 class_list[name] += 1 class_list = dict(sorted(class_list.items())) label_list = dataset / 'label_list.txt' with label_list.open('w')as f: f.write('\n'.join(class_list.keys())) fig, ax = plt.subplots() [ax.text(a, b + 1, b, ha='center', va='bottom') for a, b in class_list.items()] plt.bar(*zip(*class_list.items())) plt.xticks(rotation=270) plt.title('Detection category distribution') plt.xlabel('Class') plt.ylabel('Number') plt.tight_layout() plt.savefig(f"{dataset / '类别分布.jpg'}", format="jpg") print(f"Save as {dataset / '类别分布.jpg'}") print(f"共{len(class_list)}类") if __name__=='__main__': parser = argparse.ArgumentParser() parser.add_argument('--dataset', required=True, help='input dataset path, necessary parameter') opt = parser.parse_args() check_dataset(opt.dataset) make_paddle_voc(opt.dataset) check_labels(opt.dataset)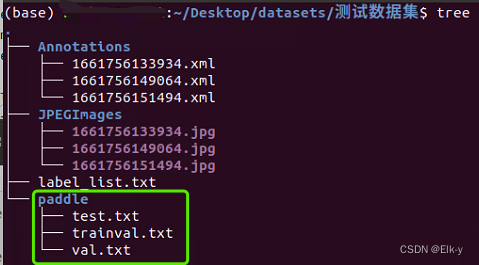
-
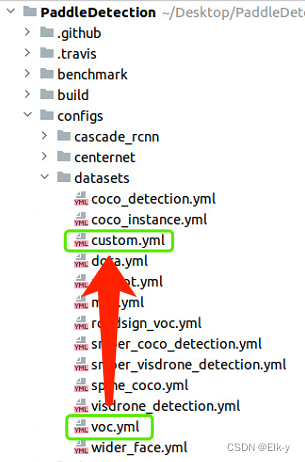
创建数据集配置文件
- 将configs/datasets/voc.yml复制为custom.yml
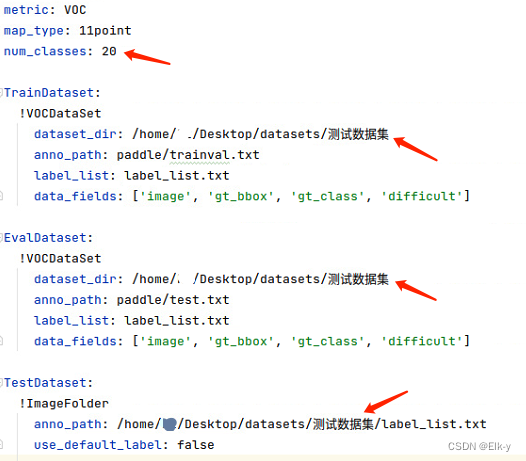
- 修改配置,红色标记处,根据自己的数据集修改
- 将configs/datasets/voc.yml复制为custom.yml
-
-
修改参数
-
在configs中选择你要训练的配置,复制一份并将coco后缀改为voc
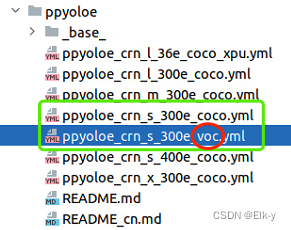
-
修改配置
第一处标记为自定义VOC数据集,第二、三处根据自己电脑配置,参照官方说明修改。
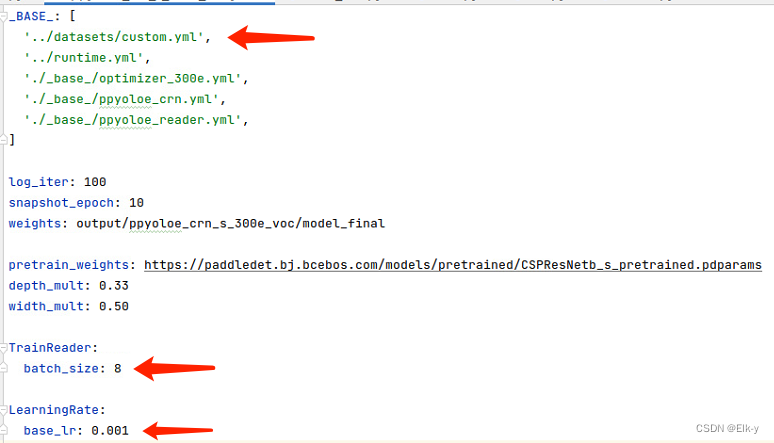
-
-
开启训练
python3 tools/train.py -c configs/ppyoloe/ppyoloe_crn_s_300e_voc.yml -
模型评估
python3 -u tools/eval.py -c configs/ppyoloe/ppyoloe_crn_s_300e_voc.yml -
模型测试
python3 -u tools/infer.py -c configs/ppyoloe/ppyoloe_crn_s_300e_voc.yml --infer_img=test.jpg --draw_threshold=0.5 -
模型导出
python3 tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_s_300e_voc.yml --output_dir=output/ppyoloe_crn_s_300e_voc/ -o weights=output/ppyoloe_crn_s_300e_voc/best_model















 2169
2169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









